文章目录
- 【半监督图像分割 2022 CVPR】UCC
- 摘要
- 1. 简介
- 2. 相关工作
- 2.1 半监督分类
- 2.2 半监督语义分割。
- 3. 交叉头协同训练的半监督学习
- 3.1 整体预览
- 3.2 弱增强和强增强
- 3.3 动态交叉集复制粘贴策略
- 3.4 不确定度估计
- 4. 实验
- 4.1 实验设置
- 4.2 对比sota
- 4.3 消融实验
- 5. 总结
【半监督图像分割 2022 CVPR】UCC
论文题目:UCC: Uncertainty guided Cross-head Co-training for Semi-Supervised Semantic Segmentation
中文题目:UCC:用于半监督语义分割的不确定性引导交叉头协同训练
论文链接:https://arxiv.org/abs/2205.10334
论文代码:
论文团队:清华大学
发表时间:
DOI:
引用:
引用数:
摘要
深度神经网络(DNNs)在语义分割方面取得了巨大的成功,这需要大量的标记数据进行训练。我们提出了一个新颖的学习框架,称为不确定性引导的交叉头协同训练(UCC),用于半监督的语义分割。我们的框架在一个共享编码器中引入了弱增强和强增强,以实现协同训练,这自然结合了一致性和自我训练的好处。每个分割头都与它的同伴互动,弱增强的结果被用来监督强增强。一致性训练样本的多样性可以通过动态交叉集复制粘贴(DCSCP)来提高,这也缓解了分布不匹配和类不平衡的问题。此外,我们提出的不确定性引导的再加权模块(UGRM)通过建模的不确定性,抑制来自同行的低质量的伪标签的影响,从而增强了自我训练的伪标签。在Cityscapes和PASCAL VOC 2012上进行的大量实验证明了我们的UCC的有效性。我们的方法明显优于其他先进的半监督式语义分割方法。在1/16协议下,它在Cityscapes和PASCAL VOC 2012数据集上分别实现了77.17%和76.49%的mIoU,比有监督的基线好+10.1%和+7.91%。
1. 简介
图像语义分割是计算机视觉领域的一个重要和热点话题,可以应用于自动驾驶[24]、医学图像处理和智能城市。在过去的几年里,基于深度神经网络(DNN)的语义分割方法取得了巨大的进展,如[3, 5, 20, 29]。然而,这些方法大多涉及像素级的人工标注,相当昂贵且耗时。
为了有效利用未标记的图像,基于一致性正则化的方法被广泛用于半监督学习[11, 18, 27]。它通过计算输出的差异作为损失函数,促进网络对同一未标记的图像产生类似的预测,并对其进行不同的增强。其中,数据增强常用于一致性正则化,通过设计搜索空间为数据增强策略库服务。此外,FixMatch[26]通过对弱扩增和强扩增产生的预测强制执行一致性约束,显示了其有效性。尽管一致性正则化取得了成功,但我们发现网络性能在高数据量的情况下往往会达到瓶颈。
另一种半监督学习方法,即自我训练,可以充分使用海量数据。它结合了从分割模型中获得的未标记图像上的伪标签来指导其学习过程,然后用标记的和未标记的数据重新训练分割模型。然而,传统的自我训练程序有其固有的缺点:伪标签的噪声可能会累积起来,影响整个训练过程。作为自我训练的延伸,共同训练[23, 40]让多个单独的学习者相互学习,而不是塌下身子来学习。为了充分利用一致性正则化和联合训练的优点,我们提出了一个结合了弱增强和强增强的交叉头联合训练学习框架。比较多个模型,我们可以通过共享编码器以最小的额外参数实现协同训练,它对不同的学习者实施约束,避免他们向相反方向收敛。
我们的方法也得益于学习者的多样性。如果没有多样性,联合训练就会变成自我训练,而且对同一预测的一致性训练也将是因为缺乏多样性而毫无意义。多样性的内在…多样性通常来自于强增强函数中的随机性。的随机性(两个头的未标记的例子被不同的不同的增强和伪标签)和不同的学习者初始化。者的初始化。复制-粘贴(CP)也是一种提高训练样本多样性的替代方法。也是提高训练样本多样性的另一种方法,最近的工作[40]已经证明了其有效性。然而,普通的CP有其固有的缺点,由两个问题引起。第一个问题是第一个问题是标签数据和数据之间的分布不匹配。
通过结合数据增强策略和不确定性重新加权模块,我们开发了不确定性引导的交叉头协同训练,它自然地结合了一致性和协同训练。在Cityscapes和PASCAL VOC 2012两个基准上进行各种设置的实验结果表明,所提出的方法实现了最先进的半监督分割性能。
我们的贡献可以概括如下:
- 我们提出了一个新的框架UCC,它将弱增强和强增强引入到交叉头协同训练框架中。 通过共享模块,可以进一步提高泛化能力,从两个不同的视图学习更紧凑的特征表示。
- 提出了一种提高一致性训练样本多样性的方法DCSCP,同时减少了分布失调,解决了类不平衡问题。 此外,我们提出了UGRM来解决自训练带来的伪标签噪声。
- 我们在Cityscapes和Pascal VOC 2012数据集上验证了所提出的方法,该方法在所有标记数据比率方面都显著优于其他最先进的方法。
2. 相关工作
2.1 半监督分类
半监督分类方法主要关注一致性训练,将标准监督损失和无监督一致性损失相结合,使未标记样本的预测在不同扰动下保持一致。例如,时态镶嵌[18]期望当前和过去的时期预测尽可能一致。均值教师[27]通过在训练步骤中使用指数移动平均(EMA)的模型权重平均值来修改时态镶嵌,并倾向于生成更准确的模型,而不是直接使用输出预测。双重学生[17]通过用另一个学生取代教师,进一步扩展了平均教师模型。
其他的研究,如S4L[36]探索了一个自我监督的辅助任务(例如,预测旋转)在无标记图像上与一个有监督的任务联合进行。 MIXMatch[1]产生使用MIXUP[37]生成的增强的标记和未标记样本。 FixMatch[26]在单阶段训练管道中利用相同未标记图像的弱增强视图和强增强视图之间的一致性正则化。
2.2 半监督语义分割。
受SSL方法在图像分类领域的最新进展的启发,一些研究将半监督学习应用于语义分割,并取得了很好的效果。 半监督语义分割的初步工作[15,21]倾向于利用生成对抗网络[8]作为未标记数据的辅助监督信号,其方式是鉴别器判断产生的预测,以模仿真实分割掩码的常见结构和语义信息。 对比学习等替代方法也很突出。 Reco[19]转向为对比框架下的语义类提供关联。 PC2SEG[38]利用了图像增强之间的标记空间一致性特性和不同像素之间的特征空间对比特性。 C3-Semiseg[39]通过计算像素特征损失来实现对比学习,并采用样本策略通过类域EMA阈值来处理噪声标签。
一致性正则化方法也常用于半监督的语义分割中。CCT[22]引入了一个特征级的扰动,并在不同解码器的预测中强制执行一致性。GCT[16]通过使用两个不同的初始化分割模型进行网络扰动,并鼓励两个模型的预测之间的一致性。GuidedMix-Net[28]建立在[11, 37]的基础上,强制要求混合预测和混合输入的预测相互一致。
伪标记自训练是一种起源于十年前的经典方法,它以最可能的类作为伪标记,在未标记的数据上训练模型,是一种常用的实现最小熵的方法。 它首次用于分类任务[2,25,32,34]。 近年来,它被广泛应用于半语义分割任务中,如[10,35,36]。 [10]基于两个不同初始化模型的不一致,对不同区域的损失重新加权。 [36]在再训练阶段选择容易或可靠的图像并对其进行优先级排序,以利用未标记的图像。 [35]采用重型增强以实现高性能。
虽然有很多策略旨在利用有标签和无标签的数据来提高模型的性能[12],但有标签和无标签的数据分布不匹配的问题却很少被讨论。事实上,标注数据的经验分布经常偏离真实样本的分布[30],当存在相当大的分布不匹配时,模型的性能将明显下降。除此之外,长尾类分布也是半监督语义分割中的一个常见问题。在半监督语义分割中,关于这个问题的研究很少[14, 31],而[31]介绍了一个针对不平衡类的自我训练框架。[14]提出了一个框架,通过使用动态信心库鼓励表现不佳的类别进行充分的训练。
3. 交叉头协同训练的半监督学习
在本节中,我们将概述3.1节中提出的框架UCC。 然后我们在第3.2节中描述了我们的弱数据和强数据增强策略。 另外,在3.3节中,我们提出了一种基于交叉集数据混合的动态复制粘贴策略。 最后,在3.4节中进一步介绍了一个不确定性引导的损失重权模块。
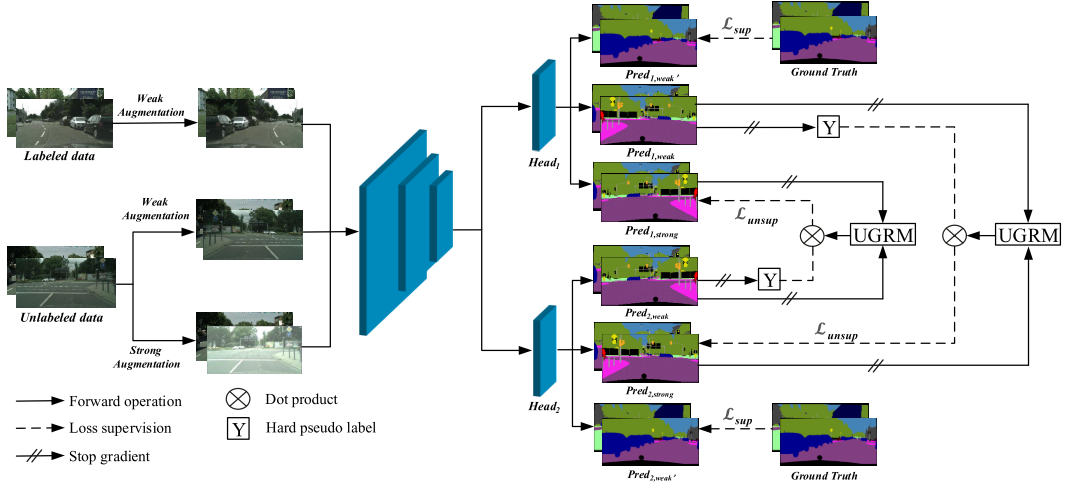
图1。我们以不确定性为导向的跨部门联合培训概述。在我们的方案中,我们以head1为例,弱增强标签数据将流经共享模块和相应的分割head1来生成Pred1,那么它将由Ground Truth(GT)监督。对于未标记的数据,将弱增强图像馈送到共享模块和相应的分割头1中,以生成Pred1,弱。与Pred1、weak、Pred1不同的是,weak是用于监控信号的强图像预测,来自另一个头部Pred2、weak,反之亦然。此外,为了进一步减少噪声标签的影响,UGRM参与了处理伪标签噪声的训练过程。
3.1 整体预览
图1是我们交叉头架构的可视化。
-
图像被送入一个共享的CNN主干,然后是两个相同的分割头。与使用单独的个体模型相比,交叉头可以学习一个紧凑的特征,并进一步提高泛化能力。
-
对于有标签的图像,我们计算GT和相应的弱化版本的预测之间的监督损失 L s u p L_{s u p} Lsup。
-
对于无标签的图像,伪标签是由弱增强的图像预测产生的。然后,该伪标签被用来监督来自另一个头的强增强图像预测。一方面,伪标签在扩大训练数据方面发挥了作用。另一方面,对弱、强图像预测实施约束可以享受一致性训练的优点。
-
此外,如图所示,UGRM是在得到无监督损失 L u n s u p L_{u n s u p} Lunsup后加入的。UGRM鼓励更多可靠的样本参与到我们的训练过程中,而自我训练带来的高不确定性样本在训练中会被降低权重。
-
另一个模块,DCSCP提高了一致性训练样本的多样性,同时处理了长尾和分布不一致的问题。进一步的细节见第3.3节。
-
该方案由一个共享主干 f f f和两个分割头 g m ( m ∈ { 1 , 2 } ) g_{m}(m\in\{1,2\}) gm(m∈{1,2})组成,其中两个分割头的结构是相同的。 在这里,我们的伪标记是由 g m ( m ∈ { 1 , 2 } ) g_{m}(m\in\{1,2\}) gm(m∈{1,2})生成的,它是由 f f f和 g m g_{m} gm生成的。 该伪标签随后将用作另一磁头的监督信号。
按照半监督语义分割的设定,我们在每次迭代中都会得到一批有标签的例子
D
l
=
{
(
x
b
,
y
b
)
;
b
∈
(
1
,
…
,
B
l
)
}
D_{l}=\{(x_{b},y_{b});b\in(1,\ldots,B_{l})\}
Dl={(xb,yb);b∈(1,…,Bl)}和一批无标签的例子
D
u
=
{
(
u
b
)
;
b
∈
(
1
,
…
,
B
u
)
}
\mathcal{D}_u=\{(u_b);b\in(1,\ldots,B_u)\}
Du={(ub);b∈(1,…,Bu)}。我们初步定义
ℓ
c
e
\ell_{ce}
ℓce为标准的像素级交叉熵损失,
W
\mathcal{W}
W和
S
\mathcal{S}
S代表应用于图像的相应的弱增强和强增强函数。与之前的半监督方法[39]类似,对于标注部分,监督损失
L
s
{\mathcal{L}}_{s}
Ls是使用标准的像素级交叉熵损失对两个头的标注图像进行计算的:
L
s
=
1
N
t
∑
i
=
1
N
t
1
W
H
∑
j
=
1
W
H
(
ℓ
c
e
(
y
i
j
,
p
1
,
i
j
W
)
+
ℓ
c
e
(
y
i
j
,
p
2
,
i
j
W
)
)
\mathcal{L}_s=\frac{1}{N_t}\sum_{i=1}^{N_t}\frac{1}{WH}\sum_{j=1}^{WH}(\ell_{ce}(\boldsymbol{y}_{ij},p_{1,ij}^W)+\ell_{ce}(\boldsymbol{y}_{ij},p_{2,ij}^W))
Ls=Nt1i=1∑NtWH1j=1∑WH(ℓce(yij,p1,ijW)+ℓce(yij,p2,ijW))
其中,
p
m
,
i
j
W
=
g
m
(
f
(
W
∘
x
i
j
)
)
p_{m,i j}^{\mathcal{W}}=g_m(f(\mathcal{W}\circ\boldsymbol{x}_{i j}))
pm,ijW=gm(f(W∘xij))表示由head-m生成的第
i
i
i个弱增广标记图像预测中的第j个像素,
y
i
j
∈
R
y_{i j}\in R
yij∈R是第
i
i
i个标记(或未标记)图像中第j个像素对应的真实标签,
N
l
N_{l}
Nl是标记训练集中的样本总数。
KaTeX parse error: Unknown column alignment: q at position 16: \begin{array} q̲^W_{m,ij}=\arg\…
对于未标记的数据,采用无监督损失结合一致性和自训练的方法来鼓励对一幅具有不同扰动的图像进行一致的伪标记预测。 Argmax函数以最大概率选择相应的类
c
∈
{
1
,
…
,
C
}
c\in\{1,\ldots,C\}
c∈{1,…,C}。
p
m
,
i
j
S
=
g
m
(
f
(
S
∘
x
i
j
)
)
p_{m,i j}^{\mathcal{S}}=g_{m}(f(\mathcal{S}\circ\boldsymbol{x}_{i j}))
pm,ijS=gm(f(S∘xij))表示由head-m生成的第i个强增广无标记图像预测中的第j个像素,
N
u
N_{u}
Nu表示训练集中的总无标记样本数。
最后,将整个损失写成:
L
=
L
s
+
λ
L
u
,
\mathcal{L}=\mathcal{L}_s+\lambda\mathcal{L}_u,
L=Ls+λLu,
3.2 弱增强和强增强
为了充分享受一致性训练的优点,我们利用弱增强和强增强在我们的框架中引入额外的信息。 在我们的实验中,弱增强是标准翻转和移位、随机尺度和裁剪策略的结合。 具体来说,我们以50%的概率随机翻转和缩放图像。
我们的方法使用一致性正则化和自训练伪标签生成伪标签。 具体地说,基于弱增强的未标记图像产生伪标记,然后当模型被馈入相同图像的强增强版本时,该伪标记被用作监督信号。 与Randaugment类似,如图2所示,我们构建了一个包含九个图像转换的操作池。 在每个训练迭代中,我们不使用固定的全局幅度,而是在每个训练步骤中从预定义的范围中随机选择小批中的每个样本的变换。
3.3 动态交叉集复制粘贴策略
复制-粘贴[12]是一种成功的方法,它将对象从一幅图像复制到另一幅图像,复制属于目标对象的特定像素而不是矩形掩码。 复制粘贴最初的目的是建立一个可以处理稀有对象类别的数据高效模型,通过创建各种新的、高度扰动的样本,然后使用这些样本进行训练,提供了一个更好地利用标记数据的机会。 另外,最近的工作[14]采用了一种自适应的方式来利用复制粘贴策略。 它提出了一个框架,鼓励使用动态信心库对表现不佳的类别进行充分培训。
然而,我们的目标范围显著不同。 [14]虽然扩大了标记样本的层内多样性,但忽略了标记和未标记数据分布的失配问题。 如果标记数据和未标记数据之间存在较大的差距,则会降低网络性能。 最近的工作,如[30,33]显示了数据混合方法的有效性。 因此,我们提出了DCSCP,通过扩展复制粘贴策略来解决标记和未标记数据分布不对齐和长尾问题。 这里的关键思想是,我们通过复制属于特定类别的所有像素来形成新的、增强的样本,并将它们粘贴在标记和未标记的图像上,这些像素是从估计的标记数据置信度分布中采样的。 相应的混合程序为:
x
c
o
p
y
_
p
a
s
t
e
=
M
⊙
x
a
+
(
1
−
M
)
⊙
x
b
,
x_{copy\_paste}=M\odot x^a+(1-M)\odot x^b,
xcopy_paste=M⊙xa+(1−M)⊙xb,
给出了两个图像
x
a
∈
D
a
,
x
b
∈
D
b
,
x^{a}\in D_{a},x^{b}\in D_{b},
xa∈Da,xb∈Db,,其中
D
b
⊂
D
\mathcal{D}_b\subset D
Db⊂D,我们将D扩展为
D
l
∪
D
u
D_{l}\cup D_{u}
Dl∪Du而不是
D
l
D_{l}
Dl,通过解决类不平衡问题,使未标记的数据也能共享复制粘贴的精神。 这里
D
a
⊂
D
l
{\mathcal{D}}_{a}\subset D_{l}
Da⊂Dl保持不变,M表示属于一个特定类别的像素的复制粘贴语义掩码。
具体地说,对于每一次前向传递,我们计算第c类的平均像素置信分布为
σ
^
t
,
c
\hat{\sigma}_{t,c}
σ^t,c。 然后通过指数移动平均的方式更新类内置信度分布:
σ
^
t
,
c
=
α
σ
^
t
−
1
,
c
+
(
1
−
α
)
σ
t
,
c
,
\hat{\sigma}_{t,c}=\alpha\hat{\sigma}_{t-1,c}+(1-\alpha)\sigma_{t,c},
σ^t,c=ασ^t−1,c+(1−α)σt,c,
其中
α
\alpha
α表示均线比,
σ
^
t
,
c
\hat{\sigma}_{t,c}
σ^t,c表示
t
t
t步第
c
c
c类的平均置信度分布,该分布由过去的阈值信息平滑。 然后将置信度分布用于类别选择过程。
3.4 不确定度估计
由于伪标签的噪声,即使是一个微小的误差也会积累到使模型性能大幅度下降的程度。 来对付嘈杂的标签。 以前的工作,如[10]采用了一种基于多数获胜的硬投票方法。 然而,任意使用多数获胜产生的共识结果可能会导致错误积累。 [11,22]通过使用固定阈值过滤噪声伪标签来显示它们的有效性。 然而,不变和固定的阈值忽略了阈值下一些有用的伪标签。
这些方法虽然在一定程度上证明了它们在处理噪声标签方面的有效性,但仍然受到其固有弱点的阻碍。 因此,我们提出了UGRM来解决噪声问题,通过对基于软投票范式的不确定性建模。 具体地说,我们考虑每个学习者的确定性,当目标类的概率值较高时,我们将其作为基本真理。 因此,我们的方法不仅可以有效地缓解伪标签的负面影响,而且可以缓解错误积累问题。 我们首先通过以下方法重新加权像素级损失:
$$
\begin{gathered}
w_{m,i j}=\operatorname*{max}{c\in{1,\ldots,C}}p{m,i j}^{c}, \
u_{m,i j}^{1}=w_{m,i j}, \
\end{gathered}
KaTeX parse error: Can't use function '$' in math mode at position 4: 其中$̲w_{m,i j}$表示类$c…
\begin{gathered}
u_{1,i j}^{2} =1_{ij},w_{2,ij}>w_{1,ij}, \
u_{2,i j}^{2} =1_{ij},w_{1,ij}>w_{2,ij},
\end{gathered}
$$
在公式(7)、公式(8)中,
1
i
j
=
1
1_{i j}=1
1ij=1表示如果当前头部对第
i
i
i幅图像中第
j
j
j个像素的预测置信度比其他像素高,那么它就等于1;否则,
1
i
j
1_{ij}
1ij将为0。否则,在训练过程中应将其舍弃。将
u
m
,
i
j
1
,
u
m
,
i
j
2
u_{m,i j}^{1},u_{m,i j}^{2}
um,ij1,um,ij2合并到我们的无监督损失中,我们可以得出公式(9),并将公式(2)重写如下,这样不仅可以通过权重调整减轻噪声的影响,而且可以将选择的可靠样本送入由两个头决定的训练中。
u m , i j = u m , i j 1 ∗ u m , i j 2 L u = 1 N u ∑ i = 1 N u 1 W H ( 1 ∑ j = 1 W H u 1 , i j ∑ j = 1 W H u 1 , i j ℓ c j ( q 1 , i j W , p 2 , i j S ) + 1 ∑ j = 1 W H u 2 , i j ∑ j = 1 W H u 2 , i j ℓ c e ( q 2 , i j W , p 1 , i j S ) ) \begin{aligned} u_{m,ij}&=u_{m,ij}^1*u_{m,ij}^2 \\ {\cal L}_{u}& =\frac{1}{N_{u}}\sum_{i=1}^{N_{u}}\frac{1}{W H}(\frac{1}{\sum_{j=1}^{W H}u_{1,i j}}\sum_{j=1}^{W H}u_{1,i j}\ell_{c j}(\boldsymbol{q}_{1,i j}^{W},p_{2,i j}^{\mathcal{S}}) \\ &+\frac{1}{\sum_{j=1}^{WH}u_{2,ij}}\sum_{j=1}^{WH}u_{2,ij}\ell_{ce}(\mathbf{q}_{2,ij}^W,p_{1,ij}^S)) \end{aligned} um,ijLu=um,ij1∗um,ij2=Nu1i=1∑NuWH1(∑j=1WHu1,ij1j=1∑WHu1,ijℓcj(q1,ijW,p2,ijS)+∑j=1WHu2,ij1j=1∑WHu2,ijℓce(q2,ijW,p1,ijS))
4. 实验
4.1 实验设置
数据集。我们的主要实验和消融研究是基于Cityscapes数据集[7],其中包含5K精细注释的图像。这些图像被分为训练集、验证集和测试集,分别包含2975、500和1525张图像。Cityscapes定义了19个城市场景的语义类别。此外,我们在PASCAL VOC 2012数据集(VOC12)[9]上测试所提出的方法,该数据集由20个语义类和一个背景类组成。标准的VOC12包括1464张训练图像,1449张验证图像,以及1456张测试图像。按照通常的做法,我们使用包含10,582张图像的增强集[13]作为训练集。我们遵循[6]的分区协议,将整个训练集分为两组,通过随机子抽样将整个集的1/2、1/4、1/8和1/16作为标记集,并将剩余的图像作为未标记集。评价。我们的性能评估是基于单尺度测试和交集大于联盟的平均值(mIoU)。我们报告了Cityscapes估值集和PASCAL VOC 2012估值集与最先进方法的比较结果。我们以公平的方式将我们的结果与最近的报告进行比较。我们分别使用ResNet-50和ResNet101作为我们的骨干网络。预训练的模型是用监督数据初始化的。此外,我们使用DeepLabv3+[4]作为分割头。我们对Cityscapes数据集使用小型批量SGD与动量来训练我们的Sync-BN模型。特别是,我们采用的学习策略是初始学习率为0.004,然后乘以 ( 1 − i t e r m a x i t e r ) 0.9 (1-\frac{i t e r}{\mathrm{max}i t e r})^{0.9} (1−maxiteriter)0.9,权重衰减为0.0005,动量为0.9。对于PASCAL VOC 2012数据集,我们设定初始学习率为0.0005,权重衰减为0.0005,裁剪尺寸为512×512,批处理尺寸为8。 我们使用随机水平翻转、随机比例和裁剪作为默认的数据增强,在Cityscapes和VOC12上使用OHEM损失。
4.2 对比sota
在这一节中,我们将我们的框架与以前的方法在不同的数据集和设置中进行广泛的比较。其他的比较结果来自于[6],标记为*。
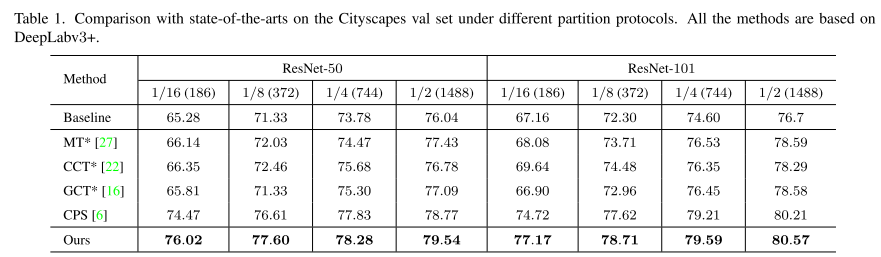
Cityscapes。在表1中,我们展示了在不同比例的标注样本下,我们在城市景观验证数据集上的平均交集(mIoU)的结果。我们还在表的顶部显示了相应的基线,它表示由相同的标注数据训练的纯监督学习结果。请注意,所有的方法都使用DeepLab V3+来进行公平的比较。
正如我们所看到的,我们的方法始终优于城市景观的监督基线。 与基线相比,在1/16、1/8、1/4和1/2分区协议下,Resnet-50的改进分别为10.74%、6.27%、4.50%和3.50%;在1/16、1/8、1/4和1/2分区协议下,Resnet-101的改进分别为10.01%、6.41%、4.99%和3.87%。
当标记数据的比例变小(例如1/8,1/16)时,我们的方法表现出显著的性能改善。 值得注意的是,在极少的数据设置下,特别是在1/16分区下,我们的方法的增益比基线高10.01%,在使用Resnet-101作为主干时,这一增益大大超过了以前的最先进的方法[27]的+2.45%,在1/8分区下,这一增益提高了+1.09%。 总之,我们提出的方法在各种情况下都有显著的改进。 在训练过程中,将一致性、规则化和自训练相结合,可以处理大量的未标记数据,并保持良好的性能。
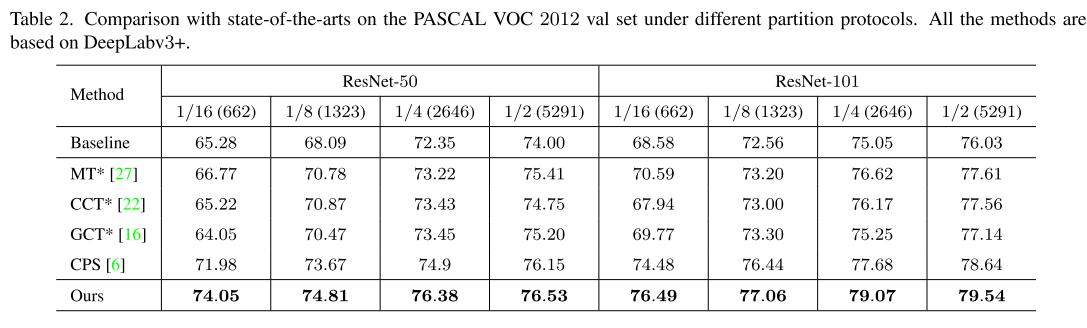
Pascol VOC 2012。 为了进一步证明该方法的泛化能力,我们还在Pascal VOC 2012 VAL数据集上进行了实验。 从表2中我们可以看出,我们的方法在很大程度上始终优于监督基线,在1/16、1/8、1/4和1/2分区协议下,RESNET-50的改进分别为8.77%、6.72%、4.03%和2.53%,在1/16、1/8、1/4和1/2分区协议下,RESNET-101的改进分别为7.91%、4.50%、4.02%和3.51%。 此外,在不同的设置下,我们的方法优于所有其他先进的方法。 具体地说,在1/16和1/4分区下,它的性能比以前的最新技术[6]高出2.01%和1.39%。
4.3 消融实验
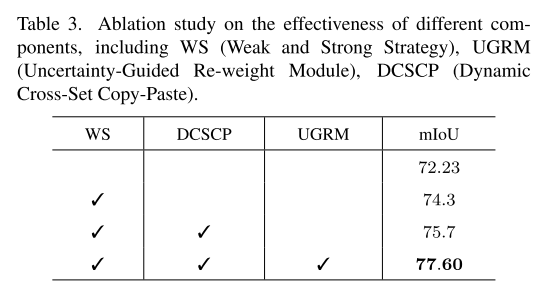
在本小节中,我们将讨论每个组件对我们框架的贡献。 如果不是出于目的,所有方法都基于1/8分区协议下的DeepLabv3+和Resnet50[6]。
不同组成部分的有效性。 进一步了解不同组件带来的优势。 我们一步一步地进行消融研究,并逐步检查每个成分的有效性。 表3报告了结果。 在不使用3.2、3.3、3.4中所述策略的情况下,对普通交叉头框架进行训练,可以获得72.23%的MIOU。 此外,WS还可以使原框架的预测结果进一步提高2.07%,这是由于WS充分利用了一致性训练的优点,对弱预测和强预测加强了约束。 在WS的基础上,通过将DCSCP合并到我们的框架中,进一步改善了类平衡和分布失调问题,提高了1.40%。 另外,UGRM通过重新考虑每个像素的重要性以及两个分割头所带来的不同信息,进一步将算法的性能提高到77.60%,说明了我们提出的不确定性估计方法的有效性。
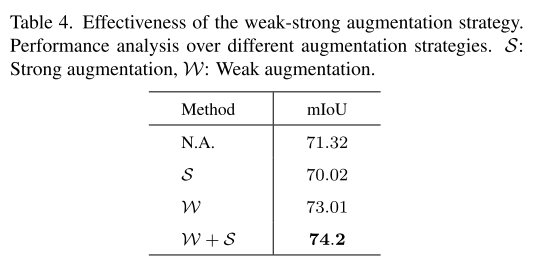
强弱互补策略的有效性。 通过利用弱-强策略,我们可以为一致性引入更多的信息(值得注意的是,强变换函数每次都会生成不同的增强图像)。 我们进行了添加不同强度的增强实验。 如表4所示,直接应用强增广预测作为监督信号导致业绩下降。 它可能是由于来自另一头的错误预测显著增加,误导了网络的优化方向。 为了得到更直观、更准确的伪标签,一个自然的想法是通过弱增强的未标记图像生成伪标签,而不是通过强增强的图像生成伪标签。 如表4所示。 用弱增广的监督信号代替弱增广的监督信号与弱增广的预测匹配后,性能提高了1.69%。 最后,在两个头上进行弱增强和强增强时,结果可以进一步提高2.88%,说明了该策略的有效性。
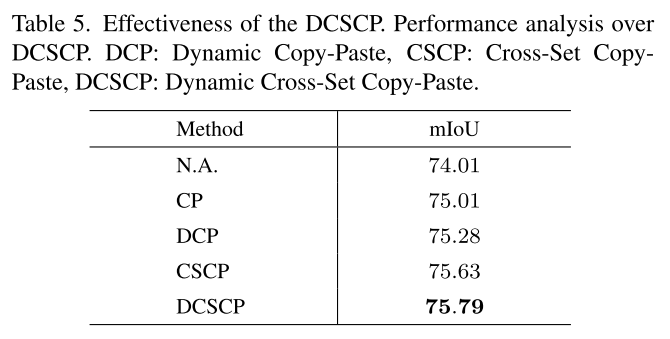
DCSCP的有效性。我们逐步剥除了DCSCP的各个组成部分。从表6可以看出,直接使用intra-level copy-paste可以形成新的扰动样本,提高1.00%的效率。在CP的基础上,将我们的方法进一步扩展到DCP,可以获得0.27%的收益,这可能是因为从估计的类分布中抽样目标类,并鼓励对稀有类进行充分的训练。此外,在标记和非标记数据之间扩展DCP可以带来0.62%的额外改进,这可以归因于解决标记和非标记数据分布不匹配问题。最后,通过DCP和CSCP的结合,该方法的性能提高了1.78%,说明该方法是一种更强大的半监督语义分割工具。
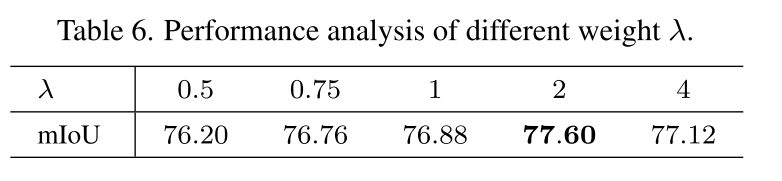
权衡权重λ。 λ用于平衡有监督损失和无监督损失之间的权衡。 结果表明,λ=2在我们的设置中表现最好,较小的λ=0.5将减少伪分割图带来的大量有用信息。 较大的λ=4是有问题的,并导致性能下降,因为网络可能会向错误的方向收敛。
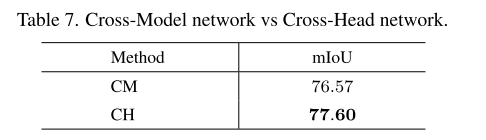
跨头部网络vs跨模型网络。 与十字头网络和十字模型网络在城市景观评价中的比较。 CH=十字头网络,CM=交叉模型网络。 从表7中我们可以看出,十字头网络比跨模型网络的性能高出+1.03%。 通过共享相同的表示,十字头网络可以进一步提高泛化能力,从而从不同的视图学习更紧凑的特征。
5. 总结
本文提出了一种新的半语义分割框架UCC(不确定性引导十字头协同训练)。 我们的方法是第一个将弱增强和强增强合并到十字头协同训练框架中,它自然地结合了一致性和自我训练的好处。 一方面,我们提出的DCSCP提高了一致性训练样本的多样性,同时解决了由于数据集的不平衡以及标记数据与未标记数据之间的差距而导致的偏差分布。 另一方面,我们提出的UGRM通过建模不确定性来抑制来自同行的低质量伪标签的影响,从而增强自训练伪标签。 我们通过两个常用的基准,包括Cityscapes和Pascal VOC2012来证明我们的范式在半监督语义分割中的有效性。
在过去的几十年里,基于一致性正则化的方法得到了很好的发展,但自我训练的有效性一直被忽视。 因此,如何在利用一致性正则化的同时,进一步挖掘噪声伪标签在自训练中的潜在优势,是今后研究的一个重要方向。