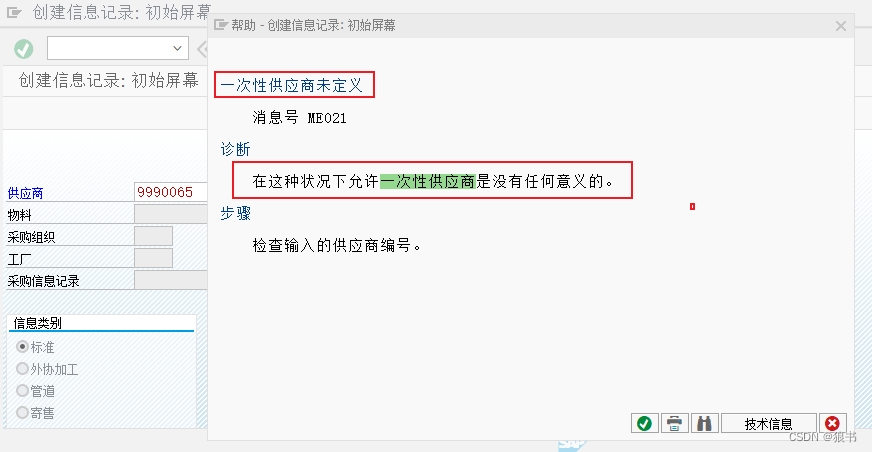
美国时间6月13日,AMD在美国加利福尼亚州旧金山举行了一场名为“数据中心与AI技术首演”的活动,并在主题演讲中介绍了数据中心的解决方案。
其中,宣布推出“AMD Instinct MI300系列加速器”(以下简称Instinct MI300系列),作为新型数据中心的GPU/APU。 发布GPU“AMD Instinct MI300X”(以下简称MI300X)和APU“AMD Instinct MI300A”(以下简称MI300A)。 每款产品均采用 3D Chiplet 技术,并采用独特的架构,通过仅加载 GPU 或混合两种类型的 CPU 和 GPU 来配置 GPU 和 APU。
同时,我们宣布了“AMD Instinct Platform”作为AI计算平台,配备了8个Instinct
300系列,以及NVIDIA提供的“DGX H100”等AI学习平台,配备了8个该公司的GPU。成为计算机领域具有竞争力的产品

AMD认真地在数据中心的AI GPU市场追赶NVIDIA……这是我看完《数据中心与AI技术首秀》主题演讲后的坦白印象。
直到现在,AMD 已经发布了 Instinct 系列作为数据中心的 GPU,但现实是,我并不认为他们在使用 GPU 的 AI 学习市场上与 NVIDIA 进行了认真的竞争。
当然,传统的“Instinct MI200”系列可能是第一款采用chiplet技术并在一个封装上集成两个GPU芯片的GPU,表现出比传统产品更高的性能,我本来是这么想的


该软件包还采用了作为行业标准指定的OAM(OCP加速器模块),并且可以使用它进行扩展。 然而,使用 MI200 系列可扩展至 8 个 GPU 的设备迄今为止尚未以广泛可用的形式出现。
在本次主题演讲的最后,AMD董事长兼首席执行官苏姿丰透露了一个名为“AMD Instinct Platform”的平台,最多可搭载8个Instinct MI300系列。 换句话说,这就像是提供给OEM和ODM厂商的“参考设计”。未来,通过向OEM和ODM厂商发布规格,我们将创建八个Instinct MI300系列,使轻松构建GPU服务器成为可能配备有
在Instinct平台中,八个Instinct MI300通过AMD的芯片到芯片连接技术Infinity Fabric互连(所需数量的Infinity Fabric由每个GPU芯片上实现的Infinity Fabric支持)。 与NVIDIA的DGX系列不同,它不需要外部NVLink Switch芯片,因此可以以相对较低的成本扩展到8个GPU(如果要配置9个以上,可以使用InfiniBand、以太网等进行横向扩展。 )。

这些参考设计的目标很明确,就是与NVIDIA提供的DGX H100和DGX A100等“AI超级计算机”竞争。 NVIDIA提供H100 GPU(Hopper)和A100 GPU(Ampere)作为PCI Express卡,但同时也以NVIDIA自己的标准模块(称为SXM)的形式提供它们(开放标准版本是OAM,被AMD和AMD采用) Intel),其中 8 个安装在 DGX 系列中,例如 DGX H100 和 DGX A100。
AMD的Instinct平台是AMD自己设计的一款产品,用于与DGX系列竞争,提供给OEM/ODM厂商,而对于OEM/ODM厂商来说,客户被NVIDIA产品的价格所说服,它可以为那些需要做的客户提出新的选择。没有,也可以成为与NVIDIA谈判“NVIDIA的GPU贵吗?”的“利器”。

Instinct MI300系列就是构成这样一个Instinct平台的GPU/APU。 Instinct MI300系列准备了两款产品,分别是GPU的MI300X和APU(CPU+GPU)的MI300A。
这两款产品的特点是均采用3D Chiplet技术制作。 IOD,即基础芯片,层叠在表面可见的CPU和GPU芯片下方,需要散热的CPU和GPU芯片层叠在其上方。
此外,最大容量为192GB的HBM3以围绕CPU/GPU芯片的形式安装。 在使用3D小芯片方面,可以说其结构类似于英特尔去年发布的Intel Data Center GPU Max中宣布的“Ponte Vecchio”。 然而,它的结构比老桥更简单,并且人们认为MI300X在易于制造方面更胜一筹。

Instinct MI300系列的独特之处在于它可以通过一个3D小芯片设计同时实现GPU和APU。 APU的MI300A由6个GPU芯片和3个CPU芯片组成。 另一方面,MI300X取消了3颗CPU芯片,增加了2颗GPU芯片,增加了计算资源,总共8颗GPU芯片。
另外,MI300A的内存为128GB HBM3,而MI300X则增加了192GB HBM3的容量,因此可以用于需要更大显存容量的大规模AI学习/推理。

另外,在APU的MI300A中,内存是共享内存,CPU和GPU共享一个内存地址。 传统架构中,CPU使用的内存和GPU使用的内存是不同的内存地址空间,当CPU中的数据被GPU操作时,会从CPU内存传输到GPU内存。需要进行复制,每次都会进行内存访问,挤压了连接CPU和GPU的内部互连的带宽,导致性能下降。
MI300A在架构上CPU和GPU之间共享内存地址,GPU处理数据时只需要CPU指定内存地址即可。

不过,这次AMD并没有过多解释CDNA 3,这将是Instinct MI300系列的GPU架构。 基本上,它被认为是一个架构,将是RDNA 3的数据中心版本,但它对AI学习和推理做了什么样的扩展,以及是否可以使用RDNA 3中实现的AI引擎等等。细节完全未知。
另外,这次并没有具体提及性能,只是呼吁它比NVIDIA的H100拥有2.4倍的密度和1.6倍的内存带宽。
至于发布日期,正如之前报道的那样,MI300A的样品已经发货,MI300X的样品预计在第三季度开始发货。
Meta的PyTorch 2.0宣布结合最新版本的ROCm对AMD GPU优化的标准支持

这次,我们还介绍了AI数据中心的软件开发环境“ROCm”。 至于ROCm,我们已经为Instinct推出了它,现在有一个名为ROCm
5的版本。 ROCm 是 CUDA 的 AMD 版本,易于构建。

这样的开发环境对于通过并行扩展或横向扩展GPU来构建超级计算机非常重要,可以灵活地支持大规模并行环境。 用NVIDIA的Jensen Huang的话说,它可以用作“一个巨型GPU”,因此即使你不懂AI开发人员难以理解的硬件,你也可以使用CUDA来执行具有巨大性能的计算,这是可能的。
当然,AMD的ROCm是一样的,从1个GPU到8个Instinct Platform,即使扩展到数百个GPU,也可以通过ROCm将其作为1个GPU来处理。
此外,还提供了将 CUDA 代码转换为 ROCm 代码的工具,已经拥有基于 CUDA 的 AI 软件资产的公司和开发者可以将 CUDA + NVIDIA GPU 环境替换为 ROCm + AMD GPU 环境。

在本次活动中,AMD 总裁 Victor Penn 上台解释了公司与其软件开发合作伙伴之间的合作。 台上,PyTorch创始人、Meta副总裁Soumis Chintara受邀上台讲解AMD与PyTorch的合作关系。
PyTorch 是基于 Facebook 内部推出的开源项目的深度学习框架,许多 AI 开发人员使用 PyTorch 来构建 AI 学习和 AI 推理应用程序。
这次,AMD和Meta宣布,在即将发布的“ROCm版本5.4.2”中,他们将通过PyTorch 2.0的ROCm对Instinct加速器进行优化,即使你没有任何软件知识,也可以使用Instinct加速器通过引入 ROCm 作为开发环境。

同样,提供AI模型的Hugging Face也发布公告,并透露Hugging Face提供的AI模型将针对AMD的CPU/GPU/FPGA等进行优化。 使用 Hugging Face 人工智能模型的客户将能够按原样使用 AMD 处理器进行高性能学习和推理。
AMD此次之所以上诉,是因为NVIDIA的实力在于,很多开发者都熟悉CUDA作为软件开发环境,并且坚信开发者正在选择NVIDIA GPU作为AI计算硬件的现实。(这就是NVIDIA的实力吧现在)。 这就是为什么他呼吁可以轻松地从CUDA移植,并且AMD的CPU/GPU/FPGA可以以集成的方式使用,而不必从AI开发人员熟悉的框架(例如PyTorch)中考虑任何特别困难的事情。是想要克服这种情况的另一面。
CUDA已经有15年的历史了,而ROCm只有7年左右的历史,比CUDA晚了很多才开始在AI中认真使用。 从这个意义上来说,AMD 想要赶上这种延迟并不容易,但这是一种“先有鸡还是先有蛋”的关系,如果 AMD 的 GPU 比 NVIDIA 的 GPU 快得多,例如,许多开发者可能会认为它是“鸡”并且开始编写大量“蛋”代码,这将下下一只鸡…等等。
可以说,AMD这次一睹风采的Instinct MI300系列,就有成为那只“鸡”的潜质,而它的去向,包括能成为“NVIDIA DGX杀手”的Instinct Platform的存在,都是一个必看。
[官方稿] AMD 通过全新 EPYC CPU 扩展了领先的数据中心产品组合,并分享了下一代 AMD Instinct 加速器和生成式 AI 软件支持的详细信息
加利福尼亚州圣克拉拉,2023 年 6 月 13 日 (环球通讯社) – 今天,在“数据中心和人工智能技术首映”上, AMD (纳斯达克股票代码:AMD)宣布了将塑造计算未来的产品、战略和生态系统合作伙伴,突出了数据中心创新的下一阶段。 AMD 与来自 Amazon Web Services (AWS)、Citadel、Hugging Face、Meta、Microsoft Azure 和 PyTorch 的高管一起登台,展示了与行业领导者的技术合作伙伴关系,将下一代高性能 CPU 和 AI 加速器解决方案推向市场。
“今天,我们在数据中心战略方面又向前迈出了重要一步,我们扩展了 4 个数据中心 th AMD 董事长兼首席执行官 Lisa Su
博士表示:“Gen EPYC™
处理器系列为云和技术计算工作负载提供了全新的领先解决方案,并宣布与最大的云提供商进行新的公共实例和内部部署。”
“人工智能是塑造下一代计算的决定性技术,也是 AMD 最大的战略增长机会。 我们专注于加速 AMD AI
平台在数据中心的大规模部署,计划于今年晚些时候推出 Instinct MI300 加速器,以及针对我们的硬件优化的企业级 AI
软件生态系统不断发展。”
针对现代数据中心优化的计算基础设施
AMD 发布了其 4 的一系列更新 th Gen EPYC 系列旨在为客户提供满足企业独特需求所需的工作负载专业化。
- 推进世界上最好的数据中心 CPU 的发展 。 AMD 强调了 4 th 新一代 AMD EPYC 处理器继续推动领先的性能和能效。 AMD 与 AWS 一起重点 的预览 下一代 Amazon Elastic Compute Cloud (Amazon EC2) M7a 实例 展示了由第四代 AMD EPYC 处理器(“Genoa”)提供支持的 。 在活动之外, Oracle 宣布 计划提供采用第四代 AMD EPYC 处理器的新 Oracle 计算基础设施 (OCI) E5 实例。
- 不妥协的云原生计算。 AMD推出4 th Gen AMD EPYC 97X4 处理器,以前的代号为“Bergamo”。 这些处理器每个插槽有 128 个“Zen 4c”内核,可提供最大的 vCPU 密度 1 并处于行业领先地位 2 在云中运行的应用程序的性能以及领先的能源效率。 Meta 也加入了 AMD 的行列,讨论了这些处理器如何非常适合 Instagram、WhatsApp 等主流应用程序; Meta 如何通过 4 获得令人印象深刻的性能提升 th 一代 AMD EPYC 97x4 处理器与 3 代处理器相比 RD 跨各种工作负载的新一代 AMD EPYC(霄龙),同时还提供了显着的 TCO 改进,以及 AMD 和 Meta 如何优化 EPYC CPU 以满足 Meta 的功效和计算密度要求。
- 通过技术计算实现更好的产品。 AMD 推出采用 AMD 3D V-Cache™ 技术的第四代 AMD EPYC 处理器,这是全球性能最高的用于技术计算的 x86 服务器 CPU 3 。 Microsoft 宣布全面推出 Azure HBv4 和 HX 实例,由 4 th 采用 AMD 3D V-Cache 技术的新一代 AMD EPYC 处理器。
点击 此处 了解最新4 th 新一代 AMD EPYC 处理器并了解 AMD 客户的评价,请点击 此处
AMD AI 平台 – 无处不在的 AI 愿景
今天,AMD 发布了一系列公告,展示其 AI 平台战略,为客户提供从云到边缘、再到端点的硬件产品组合,并与行业软件进行深入合作,以开发可扩展且普及的 AI 解决方案。
- 推出世界上最先进的生成人工智能加速器 4 。 AMD 公布了 AMD Instinct™ MI300 系列加速器系列的新细节,包括推出 AMD Instinct MI300X 加速器,这是全球最先进的生成式 AI 加速器。 MI300X 基于下一代 AMD CDNA™ 3 加速器架构,支持高达 192 GB 的 HBM3 内存,为生成型 AI 工作负载提供大型语言模型训练和推理所需的计算和内存效率。 借助 AMD Instinct MI300X 的大内存,客户现在可以在单个 MI300X 加速器上安装大型语言模型,例如 Falcon-40(一种 40B 参数模型) 5 。 AMD 还推出了 AMD Instinct™ 平台,该平台将八个 MI300X 加速器整合到行业标准设计中,为 AI 推理和训练提供终极解决方案。 MI300X 将从第三季度开始向主要客户提供样品。 AMD 还宣布,全球首款用于 HPC 和 AI 工作负载的 APU 加速器 AMD Instinct MI300A 现已向客户提供样品。
- 将开放、经过验证且就绪的人工智能软件平台推向市场。 AMD 展示了用于数据中心加速器的 ROCm™ 软件生态系统,强调了与行业领导者整合开放 AI 软件生态系统的准备和合作。 PyTorch 讨论了 AMD 和 PyTorch 基金会之间为全面上游 ROCm 软件堆栈而开展的工作,在所有 AMD Instinct 加速器上为 PyTorch 2.0 和 ROCm 版本 5.4.2 提供即时“零日”支持。 这种集成使开发人员能够获得由 PyTorch 支持的广泛 AI 模型,这些模型与 AMD 加速器兼容并可以“开箱即用”。 面向人工智能构建者的领先开放平台 Hugging Face 宣布将优化 AMD 平台上的数千个 Hugging Face 模型,从 AMD Instinct 加速器到 AMD Ryzen™ 和 AMD EPYC 处理器、AMD Radeon™ GPU 以及 Versal™ 和 Alveo™ 自适应处理器。
适用于云和企业的强大网络产品组合
AMD 展示了强大的网络产品组合,包括 AMD Pensando™ DPU、AMD 超低延迟网卡和 AMD 自适应网卡。 此外,AMD Pensando DPU 将强大的软件堆栈与“零信任安全”和领先的可编程数据包处理器相结合,打造出世界上最智能、最高性能的 DPU。 AMD Pensando DPU 已在 IBM Cloud、 Microsoft Azure 和 Oracle Compute Infrastructure 等云合作伙伴中大规模部署。 在企业中,它部署在 HPE Aruba Networking CX 10000 系列交换机中,并与领先的 IT 服务公司 DXC 等客户合作,并作为 VMware vSphere的一部分 ® 分布式服务引擎™ ,为客户加速应用程序性能。
AMD 重点介绍了代号为“Giglio”的下一代 DPU 路线图,与当前一代产品相比,该产品旨在为客户带来更高的性能和能效,预计将于 2023 年底上市。
AMD 还发布了 AMD Pensando 硅内软件开发套件 (SSDK),使客户能够快速开发或迁移服务,以部署在 AMD Pensando P4 可编程 DPU 上,并与 AMD 上已实现的现有丰富功能相协调。 Pensando平台。 AMD Pensando SSDK 使客户能够发挥领先的 AMD Pensando DPU 的强大功能,并在其基础设施内定制网络虚拟化和安全功能,与 Pensando 平台上已实现的现有丰富功能集相协调。
关于AMD
50 多年来,AMD 一直在推动高性能计算、图形和可视化技术的创新。 全球数十亿人、领先的财富 500 强企业和尖端科研机构每天都依靠 AMD 技术来改善他们的生活、工作和娱乐方式。 AMD 员工专注于打造领先的高性能和适应性产品,突破可能的界限。 有关 AMD 如何实现今天并激励明天的更多信息,请访问 AMD(纳斯达克股票代码:AMD) 网站 、 博客 、 LinkedIn 和 Twitter 页面。
AMD、AMD 箭头徽标、EPYC、AMD Instinct、ROCm、Ryzen、Radeon 及其组合是 Advanced Micro Devices, Inc. 的商标。其他名称仅供参考,可能是其各自所有者的商标。
警示性声明
本新闻稿包含有关 Advanced Micro Devices, Inc. (AMD) 的前瞻性陈述,例如 AMD 产品的特性、功能、性能、可用性、时间安排和预期优势,包括 AMD 4 th Gen EPYC™ 处理器系列、AMD Instinct™ MI300 系列加速器系列(包括 AMD Instinct™ MI300X 和 AMD Instinct™ MI300A)以及代号为“Giglio”的 AMD Pensando DPU,均根据私人证券诉讼的安全港条款制定1995 年改革法案。前瞻性陈述通常用“愿意”、“可能”、“期望”、“相信”、“计划”、“打算”、“项目”和其他具有类似含义的术语来识别。 请投资者注意,本新闻稿中的前瞻性陈述基于当前的信念、假设和预期,仅代表截至本新闻稿发布之日的情况,涉及可能导致实际结果与当前预期存在重大差异的风险和不确定性。 此类陈述受到某些已知和未知的风险和不确定性的影响,其中许多风险和不确定性难以预测,通常超出 AMD 的控制范围,可能导致实际结果和其他未来事件与陈述中明示、暗示或预测的结果存在重大差异。前瞻性信息和声明。 可能导致实际结果与当前预期存在重大差异的重大因素包括但不限于: 英特尔公司在微处理器市场的主导地位及其激进的商业行为; 全球经济的不确定性; 半导体行业的周期性; AMD 产品销售行业的市场状况; 失去重要客户; COVID-19 大流行对 AMD 的业务、财务状况和运营业绩的影响; AMD 产品销售的竞争市场; 季度和季节性销售模式; AMD 充分保护其技术或其他知识产权的能力; 不利的货币汇率波动; 第三方制造商有能力及时、足量地生产 AMD 产品并使用有竞争力的技术; 基本设备、材料、基材或制造工艺的可用性; AMD 产品实现预期制造良率的能力; AMD 及时推出具有预期功能和性能水平的产品的能力; AMD 从其半定制 SoC 产品中创收的能力; 潜在的安全漏洞; 潜在的安全事件,包括 IT 中断、数据丢失、数据泄露和网络攻击; 升级和操作AMD新的企业资源规划系统的潜在困难; AMD 产品订购和发货的不确定性; AMD依靠第三方知识产权及时设计和推出新产品; AMD 依赖第三方公司设计、制造和供应主板、软件和其他计算机平台组件; AMD 依赖微软和其他软件供应商的支持来设计和开发在 AMD 产品上运行的软件; AMD 对第三方分销商和插件板合作伙伴的依赖; AMD 内部业务流程和信息系统修改或中断的影响; AMD 产品与部分或全部行业标准软件和硬件的兼容性; 与缺陷产品相关的成本; AMD 供应链的效率; AMD 依赖第三方供应链物流功能的能力; AMD 有效控制其产品在灰色市场销售的能力; 政府行为和法规的影响,例如出口管理法规、关税和贸易保护措施; AMD 变现递延税项资产的能力; 潜在的税务负担; 当前和未来的索赔和诉讼; 环境法、冲突矿产相关规定以及其他法律或法规的影响; 收购、合资和/或投资对 AMD 业务以及 AMD 整合所收购业务的能力的影响; 合并后公司资产的任何减值对合并后公司财务状况和经营业绩的影响; AMD 票据、Xilinx 票据担保和循环信贷安排协议所施加的限制; AMD的债务; AMD 有能力产生足够的现金来满足其营运资金需求,或产生足够的收入和运营现金流来进行所有计划的研发或战略投资; 政治、法律、经济风险和自然灾害; 未来商誉减值和技术许可购买; AMD 吸引和留住合格人才的能力; AMD股价波动; 和全球政治状况。 投资者应详细审查 AMD 向美国证券交易委员会提交的文件中的风险和不确定性,包括但不限于 AMD 关于 10-K 表格和 10-Q 表格的最新报告。
1 EPYC-049:AMD EPYC 9754 是一款 128 核双线程 CPU,在每个 vCPU 1 个线程的 2 插槽服务器中,每个 EPYC 支持的服务器可提供 512 个 vCPU,这比截至 05/23 为止任何基于 Ampere 或 4 插槽 Intel CPU 的服务器都要多/2023。
2 SP5-143A:SPECrate®2017_int_base 比较基于截至 2013 年 6 月 13 日 www.spec.org 上发布的执行系统分数。 2P AMD EPYC 9754 得分 1950 SPECrate®2017_int_base http://www.spec.org/cpu2017/results/res2023q2/cpu2017-20230522-36617.html 高于所有其他 2P 服务器。 1P AMD EPYC 9754 得分 981 SPECrate®2017_int_base 得分 (981.4 得分/插槽) http://www.spec.org/cpu2017/results/res2023q2/cpu2017-20230522-36613.html 每个插槽高于所有其他服务器。 SPEC®、SPEC CPU® 和 SPECrate® 是标准性能评估公司的注册商标。 请参阅 www.spec.org 了解更多信息。
3 SP5-165:EPYC 9684X CPU 是全球性能最高的用于技术计算的 x86 服务器 CPU,比较基于截至 2023 年 6 月 13 日的 SPEC.org 出版物,测量了每个 SPECrate®2017_fp_base 的分数、评级或每天的工作数量( SP5-009E)、Altair AcuSolve (https://www.amd.com/en/processors/server-tech-docs/amd-epyc-9004x-pb-altair-acusolve.pdf)、Ansys Fluent (https:// www.amd.com/en/processors/server-tech-docs/amd-epyc-9004x-pb-ansys- Fluent.pdf),OpenFOAM (https://www.amd.com/en/processors/server-tech -docs/amd-epyc-9004x-pb-openfoam.pdf)、Ansys LS-Dyna (https://www.amd.com/en/processors/server-tech-docs/amd-epyc-9004x-pb-ansys -ls-dyna.pdf)和 Altair Radioss (https://www.amd.com/en/processors/server-tech-docs/amd-epyc-9004x-pb-altair-radioss.pdf) 应用测试用例模拟运行 96 核 EPYC 9684X 的 2P 服务器与顶级 2P 性能通用 56 核 Intel Xeon Platinum 8480+ 或基于堆栈顶部 60 核 Xeon 8490H 的服务器的平均加速比,可实现技术计算性能领先。 AMD 定义的“技术计算”或“技术计算工作负载”可包括:电子设计自动化、计算流体动力学、有限元分析、地震层析成像、天气预报、量子力学、气候研究、分子建模或类似工作负载。 结果可能会因芯片版本、硬件和软件配置以及驱动程序版本等因素而有所不同。 SPEC®、SPECrate® 和 SPEC CPU® 是标准性能评估公司的注册商标。 请参阅 www.spec.org 了解更多信息。
4 MI300-09 - AMD Instinct™ MI300X 加速器基于具有 3D 小芯片堆叠的 AMD CDNA™ 3 5nm FinFet 工艺技术,采用高速 AMD Infinity Fabric 技术,拥有 192 GB HBM3 内存容量(Nvidia Hopper H100 为 80GB), 5.218 TFLOPS 的持续峰值内存带宽性能,高于 Nvidia Hopper H100 GPU 的最高带宽。
5 MI300-07K:内部 AMD 性能实验室截至 2023 年 6 月 2 日根据当前规格和/或内部工程计算进行的测量。 以 FP16 精度运行或计算大型语言模型 (LLM),以确定运行 Falcon(40B 参数)模型所需的最小 GPU 数量。 测试结果配置:AMD 实验室系统由 1 个 EPYC 9654(96 核)CPU 和 1 个 AMD Instinct™ MI300X(192GB HBM3,OAM 模块)750W 加速器组成,在 FP16 精度下进行测试。 服务器制造商可能会改变配置产品,从而产生不同的结果。