什么是 GPTCache?
GPTCache 是一个开源工具,旨在通过实现缓存来提高基于 GPT 的应用程序的效率和速度,以存储语言模型生成的响应。GPTCache 允许用户根据其需求自定义缓存,包括嵌入函数、相似度评估函数、存储位置和驱逐等选项。此外,GPTCache 目前支持 OpenAI ChatGPT 接口和 Langchain 接口。

基于强大而不断增长的社区。
3,435+GitHub 星标
为什么选择 GPTCache?
开发语义缓存(例如 GPTCache)来存储大型语言模型(LLM)的响应可以带来多个优势,包括:
性能改进
将LLM响应存储在缓存中可以显著减少检索响应所需的时间,特别是当之前已经请求过并且已经存在于缓存中时。将响应存储在缓存中可以提高应用程序的整体性能。
降低成本
大多数LLM服务根据请求次数和 令牌数量 的组合收费。缓存LLM响应可以减少向服务发出的API调用次数,从而节省成本。当处理高流量时,缓存尤为重要,因为API调用费用可能很高。

更好的可伸缩性
通过缓存LLM响应,可以减少LLM服务的负载,从而提高应用程序的可伸缩性。缓存有助于避免瓶颈,并确保应用程序可以处理日益增长的请求数量。
降低开发成本
语义缓存可以是降低LLM(语言模型)应用程序开发阶段成本的有价值工具。LLM应用程序在开发过程中需要与LLM API 进行连接,这可能会造成高昂的费用。GPTCache 提供与LLM API 相同的接口,并且可以存储LLM生成的数据或模拟数据。GPTCache 可以帮助您在不连接到LLM API或网络的情况下验证应用程序的功能。
减少网络延迟
语义缓存位于用户附近,从而减少从LLM服务检索数据所需的时间。通过减少网络延迟,可以提高用户的整体体验。
提高可伸缩性和可用性
LLM服务经常强制实施速率限制,即API对用户或客户端在给定时间范围内可以访问服务器的次数设置的限制。达到速率限制意味着附加的请求将被阻塞,直到经过一定时间,导致服务中断。通过GPTCache,您可以快速扩展以适应越来越多的查询量,确保随着应用程序用户群的扩大,始终保持一致的性能。
总的来说,开发用于存储LLM响应的语义缓存可以提供多种好处,包括性能改进、降低成本、更好的可伸缩性、自定义性和降低网络延迟。
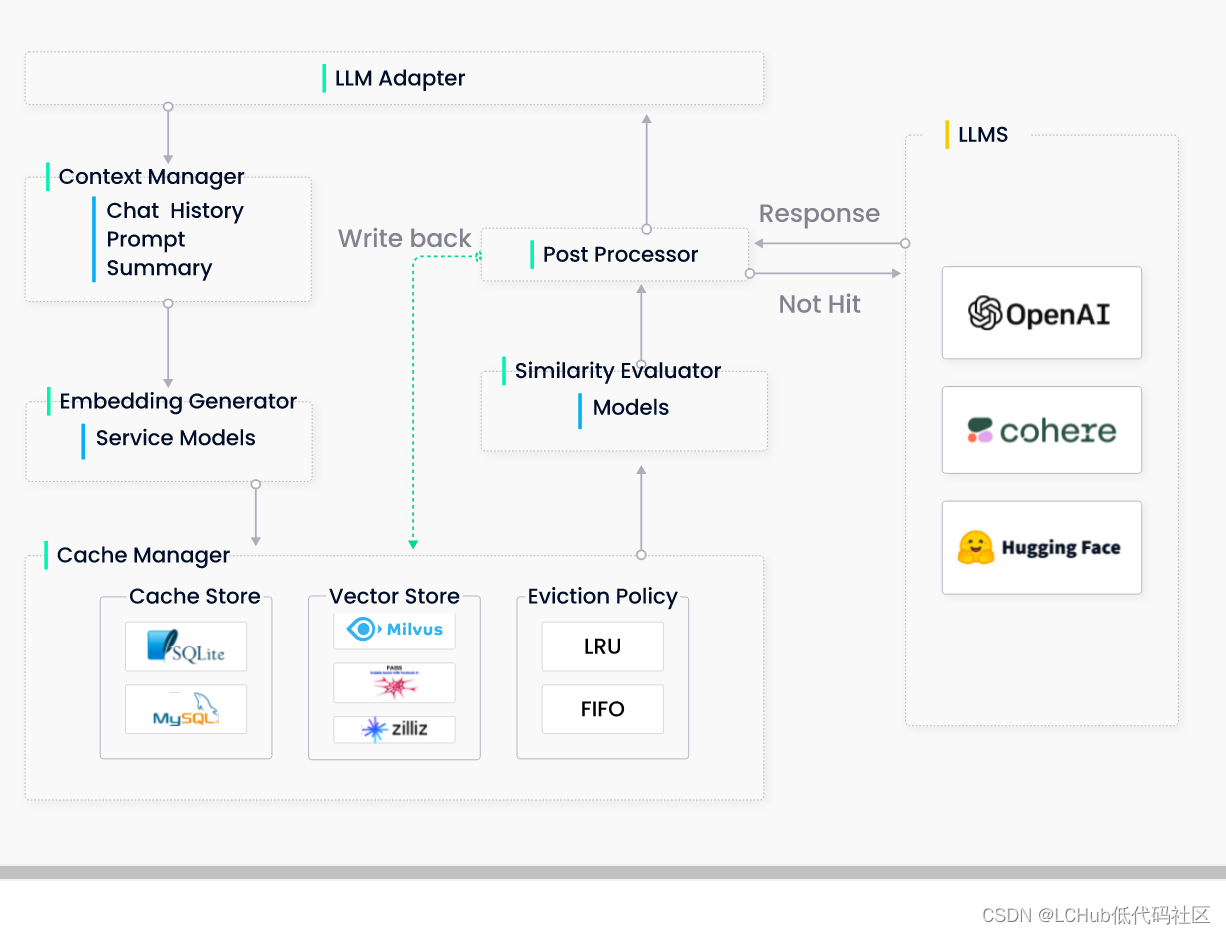
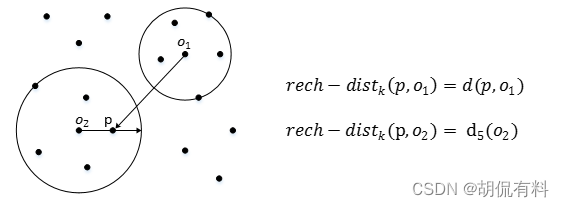
GPTCache 的工作原理
GPTCache 使用嵌入算法将查询转换为嵌入,并使用向量存储在这些嵌入上进行相似度搜索。这个过程允许 GPTCache 从缓存存储中识别和检索相似或相关的查询,如下图所示。