作者 | 百度APP技术平台
导读
在移动互联网快速发展的背景下,保护Android应用程序的安全性和知识产权变得尤为重要。为了防止恶意攻击和未授权访问,通常采用对dex文件进行代码加固来保护应用程序。随着Android加固技术经过动态加载、不落地加载、指令抽取、java2cpp、VMP等技术不断演进和改进,VMP加固技术成为一种高安全性解决方案。因此,本文将着重介绍一种实现和落地VMP技术的思路,以帮助大家了解其工作原理和应用场景。
全文8359字,预计阅读时间21分钟。
01 问题背景
在移动互联网快速发展的背景下,Android 作为全球最受欢迎的移动操作系统,吸引了大量开发者和用户。随着应用市场的竞争加剧,保护应用程序的安全性和知识产权变得越来越重要。
同时,随着公司业务的发展,百度与外部友商深度合作,需要对外输出了百度业务能力SDK。在这种背景下,对Android代码进行加固成为了一种必要的安全措施。加固可以提高应用程序的安全性,保护知识产权,防止逆向工程和破解。
02 问题分析
Android 应用程序是由 Java/Kotlin 语言编写而成,然后打包成 APK 文件。Java 代码被编译成 APK/AAR 中的 dex 文件,dalvik/art 虚拟机解释执行 dex 中的字节码。攻击者可以使用反编译工具很容易的逆向分析 dex 文件,理解代码关键逻辑,增加恶意代码,再打包回 APK 文件。
可以看到,dex 文件就是代码加固的保护核心!
03 加固调研
为了解决对 dex文件的代码加固,我们进行了相关技术调研,其实在Android代码安全领域,相关技术一直属于不断攻防演进的过程。如下是业界常用的加固技术方案:比如最初的360加固给APK加壳,通过不落地动态加载实现加固;市场上常用的类方法抽取指令加固;以及将java方法转native方法jni调用等。
3.1 DexClassLoader 动态加载机制
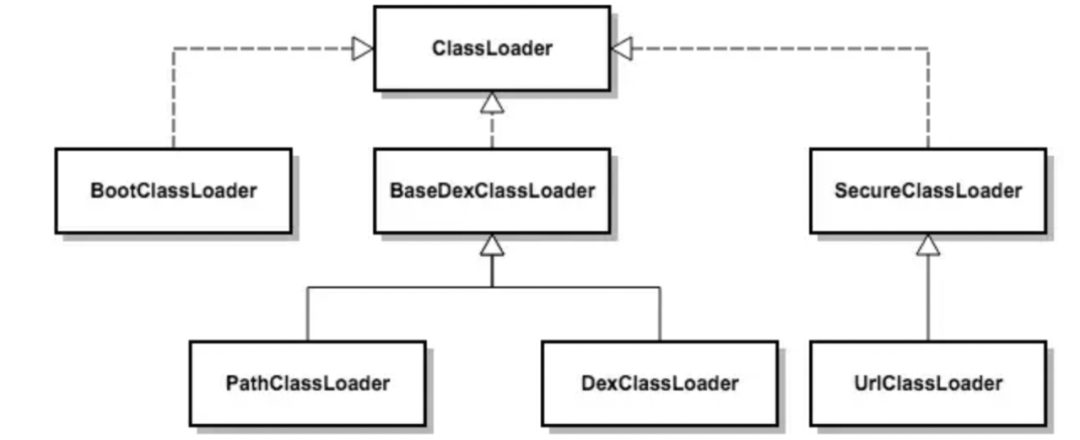
利用 Android 系统的 DexClassLoader 动态加载机制,通过将保护的 dex 文件解压解密后,动态加载到内存中执行。
这种方式有效地抵御了 APK 文件的静态分析,使得逆向分析者无法在 APK 文件中找到真实的 dex 文件。但是由于动态加载技术主要依赖于java的动态加载机制,所以要求关键逻辑部分必须进行解压,并且释放到文件系统。
这种动态加载技术不足之处在于:1.这一解压释放机制就给攻击者留下直接获取对应文件的机会; 2.可以通过hook虚拟机关键函数,进行dump出原始的dex文件数据。
3.2 Hook 技术
针对 DexClassLoader 动态加载机制的保护缺陷,采用 Hook 技术来解决问题。
在动态加载过程中,通过替换 DexClassLoader 执行过程中的 dex 内存,将其替换为真实 dex 文件的内存,从而实现了无需将 dex 落地的加载方式。
然而,dex 文件虽然不会解密并保存到文件系统,但它在内存中是完整存在的。因此,在应用程序运行后,逆向分析者可以通过内存搜索的方式将 dex 文件转储出来。
3.3 指令抽取
为了对抗逆向开发通过内存搜索的方式将 dex 文件转储出来,加固技术采用了函数抽取的方法,使得 dex 文件在内存中一直处于不完整的状态。
其实现思路大致如下:
1、对要保护的 dex 文件进行预处理,将需要保护的函数指令抽取出来并进行加密存储,同时在原位置填充 nop 指令。
2、当 dalvik/art 执行到抽取的函数时,利用 hook 技术拦截 libdalvik.so/libart.so 中的指令读取部分,将函数对应的真实指令解密并填充,使得 dalvik/art 能够继续解释执行。
随着逆向技术的不断发展,改造 dalvik 并遍历所有 dex 方法,以及内存重组 dex,成为了对抗此种加固保护的有效方法。其中,dexhunter 是该领域的主要代表之一。
3.4 java2cpp 技术
随着内存脱壳机的出现,指令抽取的保护方式逐渐失去有效性。为了应对这一问题,java2cpp 技术开始被引入到加固保护中。
核心是对 dex 中的函数进行处理,将函数中的 dalvik 指令转换成等效的 cpp 代码(基于 JNI),然后编译成本地的动态链接库(native so 库),并将保护的方法标记为 native 属性。这样,在执行到受保护的方法时,执行流会转移到本地层执行对应的 cpp 代码。
比如原函数:
public class HelloVMP2 {
public int compute(int a, int b) {
int c = a + a;
int d = a * b;
int e = a - b;
int f = a / b;
int result = c + d + e + f;
return result;
}
}
转换后:
public class HelloVMP2 {
static {
System.loadLibrary("hello_vmp2");
}
public native int compute(int a, int b);
}
extern "C" JNIEXPORT jint JNICALL
Java_com_vmp_mylibrary_HelloVMP2_compute(JNIEnv* env, jobject obj, jint a, jint b) {
jint c = a + a;
jint d = a * b;
jint e = a - b;
jint f = a / b;
jint result = c + d + e + f;
return result;
}
这种方式下,仅将 java 转 cpp 编译成动态链接库,但是so代码依然可以被破解,在此基础上其实还是可以继续提高代码保护的安全性,那就是 DEX-VMP 技术。
3.5 DEX-VMP
DEX-VMP 原理理解起来比较容易,其针对的保护单位也是函数。将方法的 dalvik 指令转换成等价的自定义指令,函数原指令替换成自定义 VM 的调用入口指令,再将函数参数通过 VMP 入口传入到自定义 VM 中执行,自定义 VM 解释执行自定义指令。
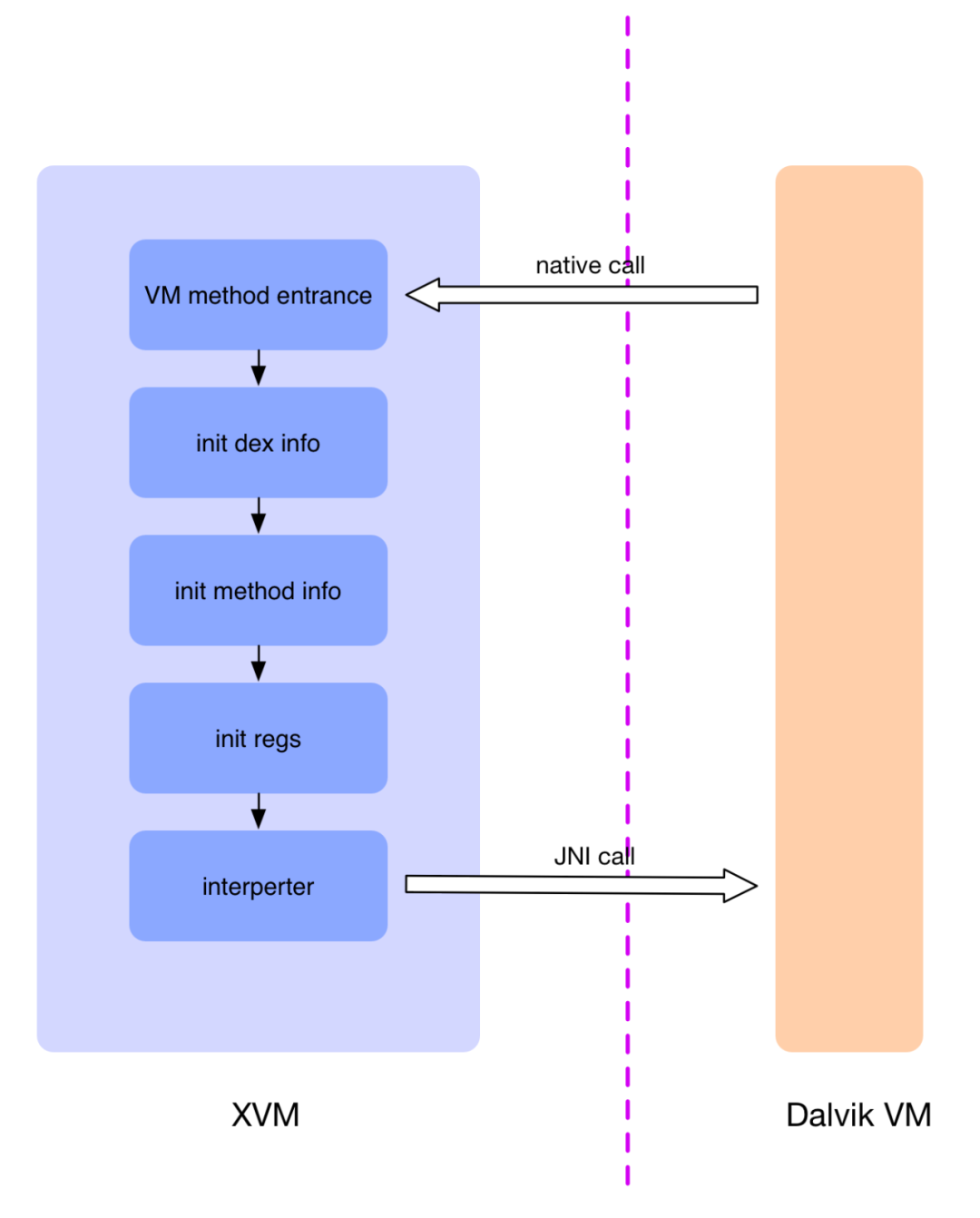
如图,当 Dalvik VM 执行到 DEX-VMP 保护的函数时,执行的是 VMP native 入口函数,开始进入 VMP 的执行流程,VMP 首先会初始化 dex 文件信息,接着获取该保护方法的一些信息,比如寄存器数量,待执行指令的内存位置等,然后初始化寄存器存储结构,最后进入到解释器中解释执行每一条指令。在解释执行的过程,如果执行到外部函数,就会使用 JNI CallMethod 的形式调用,让其切换回 Dalvik VM,让 Dalvik 去执行真正的函数。
加固过程原函数的代码逻辑替换为 native 方法,同时对 Custom VM 进行初始化,原函数 native 方法负责将参数传入到 Custom VM 中,Custom VM 解释执行原代码的等价指令。
实现 DEX-VMP 总体来说需要两步:
1、对原 dex 处理,找到要保护的方法,将原指令翻译成等价指令,加密存储,并将原指令替换为 VMP 入口指令
2、实现 VM,解释执行存储的等价指令
3.6 加固方案对比
可以看到,加固技术是不断攻防升级的过程,下面我们将以上加固技术分为五代进行对比:
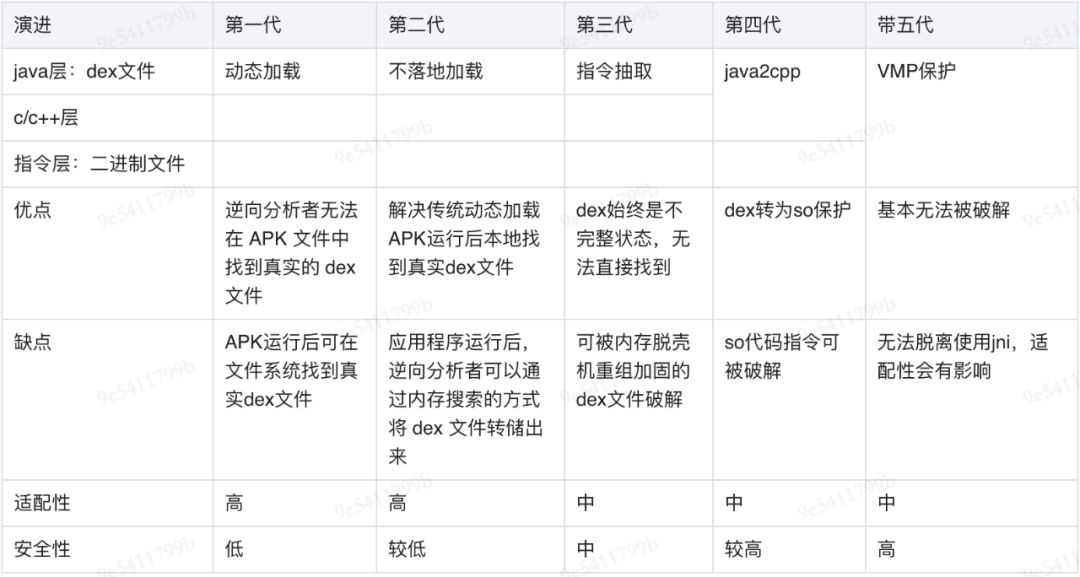
由以上对比我们可以看出,在加固技术演进过程中,VMP方案是发展到目前,加固安全度最高的方式,本着安全性角度出发,我们选择VMP方案重点介绍与分析,以下是对于项目中VMP加固的分析过程。
04 DEX-VMP加固落地实现
以下是我们要保护的一段示例代码:
package com.vmp.mylibrary;
public class HelleVMP3 {
public int compute(int a, int b) {
int c = a + a;
int d = a * b;
int e = a - b;
int f = a / b;
int result = c + d + e + f;
return result;
}
}
4.1 dex 文件预处理
dex 预处理主要做两方面工作:
1、保护方法的原指令拷贝出来并存储
2、保护方法的原指令替换成 VMP 入口方法
将要保护的 java 代码编译成 dex 文件,放入 010editor 中可以查看 compute 方法对应的指令数据:

可以看到蓝色区域包含的方法所需要的寄存器数,内部参数,外部参数及指令长度。这些都是 VM 需要的关键信息,需要存储起来。然后将指令替换为 DEX-VMP 的 native 入口指令。
有一些工具可以帮我们实现以上操作,比如 dexlib2,使用该工具可以对指定方法构造 dalvik 指令,或获取方法的指令数据。该工具的具体使用方法大家可以自定搜索。
4.2 寄存器结构设计
通过dexdump 命令查看,原方法二进制结构内容如下:
Virtual methods -
#0 : (in Lcom/vmp/mylibrary/HelloVMP3;)
name : 'compute'
registers : 6
ins : 3
outs : 0
insns size : 11 16-bit code units
28e588: |[28e588] com.vmp.mylibrary.HelloVMP3.compute:(II)I
28e598: 9000 0404 |0000: add-int v0, v4, v4
28e59c: 9201 0405 |0002: mul-int v1, v4, v5
28e5a0: 9102 0405 |0004: sub-int v2, v4, v5
28e5a4: b354 |0006: div-int/2addr v4, v5
28e5a6: b010 |0007: add-int/2addr v0, v1
28e5a8: b020 |0008: add-int/2addr v0, v2
28e5aa: b040 |0009: add-int/2addr v0, v4
28e5ac: 0f00 |000a: return v0
从示例 compute 方法的一些 hex 数据中,可以得到一些关键信息:
compute 方法在执行过程中需要使用到 6 个寄存器,传入参数 3 个, 没有使用 try 结构,指令数据为 16 个字。
Dalvik 寄存器最大长度为 32bit,我们可以直接申请一段内存来表示寄存器:
regptr_t regs[6];
regs[0] = 0;
regs[1] = 0;
regs[2] = 0;
regs[3] = 0;
regs[4] = 0;
regs[5] = 0;
regs[3] = (regptr_t) thiz;
regs[4] = p1;
regs[5] = p2;
u1 reg_flags[6];
reg_flags[0] = 0;
reg_flags[1] = 0;
reg_flags[2] = 0;
reg_flags[3] = 0;
reg_flags[4] = 0;
reg_flags[5] = 0;
reg_flags[3] = 1;
regs 表示寄存器,4 个寄存器分别为 regs [0], regs [1], regs [2], regs [3]。regs_bits_obj 表示对应寄存器是否是 Object,比如 regs [3] 是 Object,则 regs_bits_obj [3] = 1,非 object 的情况均为 0;
每一个保护方法在进入 VM 后,我们就像示例这样创建好这样的寄存器单元,供 VM 在解释执行阶段使用,执行完毕销毁即可。
注意这个过程的专业的加固工具会在 dex 预处理过程中识别二进制结构内容进行执行,无需每保护一个方法单独开发。
4.3 虚拟机实现
我们就以示例 compute 方法中的 add-int, mul-int, sub-int, div-int 这几条指令来实现一个简易的解释器
介绍一下这几条指令的作用:add-int、mul-int、sub-int、div-int 对两个源寄存器执行已确定的二元运算,并将结果存储到目标寄存器中。
首先定义自定义虚拟机需要执行的vmCode结构:
typedef struct {
const u2 *insns; // 指令
const u4 insnsSize; // 指令大小
regptr_t *regs; // 寄存器
u1 *reg_flags; // 寄存器数据类型标记,主要标记是否为对象
const u1 *triesHandlers; // 异常表
} vmCode;
自定义Opcode:
enum Opcode {
OP_ADD_INT = 0x3a,
OP_MUL_INT = 0xe4,
OP_SUB_INT = 0x77,
OP_DIV_INT_2ADDR = 0x6c,
OP_ADD_INT_2ADDR = 0xcf,
OP_RETURN = 0xde,
};
目标方法转化的 native 方法:
static jint Java_com_vmp_mylibrary_HelloVMP3_compute__II_I(JNIEnv *env, jobject thiz , jint p1, jint p2) {
regptr_t regs[6];
regs[0] = 0;
regs[1] = 0;
regs[2] = 0;
regs[3] = 0;
regs[4] = 0;
regs[5] = 0;
regs[3] = (regptr_t) thiz;
regs[4] = p1;
regs[5] = p2;
u1 reg_flags[6];
reg_flags[0] = 0;
reg_flags[1] = 0;
reg_flags[2] = 0;
reg_flags[3] = 0;
reg_flags[4] = 0;
reg_flags[5] = 0;
reg_flags[3] = 1;
static const u2 insns[] = {
0x00b3, 0x0404, 0x0120, 0x0504, 0x02ee, 0x0504, 0x546c, 0x10a9, 0x20a9, 0x40a9,
0x00ad,
};
const u1 *tries = NULL;
const vmCode code = {
.insns=insns,
.insnsSize=11,
.regs=regs,
.reg_flags=reg_flags,
.triesHandlers=tries
};
jvalue value = vmInterpret(env,
&code,
&dvmResolver);
return value.i;
}
执行指令处理逻辑:
#define OP_END
#define INST_AA(_inst) ((_inst) >> 8)
#define FETCH(_offset) (pc[(_offset)])
#define SET_REGISTER(_idx, _val) \
DELETE_LOCAL_REF(_idx); \
(fp[(_idx)] =(u4) (_val)); \
SET_REGISTER_FLAGS(_idx, 0)
#define HANDLE_OP_X_INT(_opcode, _opname, _op, _chkdiv)
HANDLE_OPCODE(_opcode /*vAA, vBB, vCC*/)
{
u2 srcRegs;
vdst = INST_AA(inst);
srcRegs = FETCH(1);
vsrc1 = srcRegs & 0xff;
vsrc2 = srcRegs >> 8;
ILOGV("|%s-int v%d,v%d", (_opname), vdst, vsrc1);
......
}
FINISH(2);
#define HANDLE_OP_X_INT(_opcode, _opname, _op, _chkdiv) \
HANDLE_OPCODE(_opcode /*vAA, vBB, vCC*/) \
{ \
u2 srcRegs; \
vdst = INST_AA(inst); \
srcRegs = FETCH(1); \
vsrc1 = srcRegs & 0xff; \
vsrc2 = srcRegs >> 8; \
ILOGV("|%s-int v%d,v%d", (_opname), vdst, vsrc1); \
if (_chkdiv != 0) { \
s4 firstVal, secondVal, result; \
firstVal = GET_REGISTER(vsrc1); \
secondVal = GET_REGISTER(vsrc2); \
if (secondVal == 0) { \
dvmThrowArithmeticException(env,"divide by zero"); \
GOTO_exceptionThrown(); \
} \
if ((u4)firstVal == 0x80000000 && secondVal == -1) { \
if (_chkdiv == 1) \
result = firstVal; /* division */ \
else \
result = 0; /* remainder */ \
} else { \
result = firstVal _op secondVal; \
} \
SET_REGISTER(vdst, result); \
} else { \
/* non-div/rem case */ \
SET_REGISTER(vdst, (s4) GET_REGISTER(vsrc1) _op (s4) GET_REGISTER(vsrc2)); \
} \
} \
FINISH(2);
__attribute__((visibility("default")))
jvalue vmInterpret(JNIEnv *env, const vmCode *code, const vmResolver *dvmResolver) {
jvalue args_tmp[5]; // 方法调用时参数传递(参数数量小于等于5)
jvalue retval;
regptr_t *fp = code->regs; // 寄存器
u1 *fp_flags = code->reg_flags; // 寄存器类型标识
const u2 *pc = code->insns;
......
/* File: c/OP_ADD_INT.cpp */
HANDLE_OP_X_INT(OP_ADD_INT, "add", +, 0)
OP_END
/* File: c/OP_SUB_INT.cpp */
HANDLE_OP_X_INT(OP_SUB_INT, "sub", -, 0)
OP_END
/* File: c/OP_MUL_INT.cpp */
HANDLE_OP_X_INT(OP_MUL_INT, "mul", *, 0)
OP_END
/* File: c/OP_DIV_INT.cpp */
HANDLE_OP_X_INT(OP_DIV_INT, "div", /, 1)
OP_END
/* File: c/OP_REM_INT.cpp */
HANDLE_OP_X_INT(OP_REM_INT, "rem", %, 2)
OP_END
end:
return 0;
}
上面是一个解析自定义 opcode 的解释器,大家可以从其中看到解释器就是 while switch 的程序结构,执行到 return 指令时退出循环。
4.4 总结
通过以上实现,可以发现虚拟机加固核心自定义一套opcode用于对保护方法的指令替换,同时还需要对替换后的指令识别后,如果对Java函数的调用交给DVM进行处理,如果是原函数指令则创建寄存器交给机器处理。整个加固过程中分为编译器+解释器两部分。
其中编译器负责对打包的AAR或者APK进行加固,加固过程则是将要保护的方法转换为JNI调用,同时C++部分根据原方法指令生成需要的寄存器与opcode;而解释器则是在运行过程,当执行到JNI调用时,能够对创建的opcode进行识别,转化原指令与寄存器交由真正的DVM进行执行。
05 兼容与性能
5.1 兼容性风险
兼容风险:
- 加固方案主要的兼容问题在于无法脱离JNI实现,而 VM 中 JNI 实现细节不尽相同。比如 Android 5.0 某个小版本中 JNI 实现会存在一个隐含的 jobject(local reference)忘记 delete 掉,当多次调用该 JNI 函数时,内存溢出不可避免。这个BUG 在之后的 Android 版本中更正过来,也就是说每个 Android 版本出来之后,我们都要看看 VMP 会不会存在 JNI 兼容性方面的 BUG。
规避建议:
- 每个Android 版本更新需要重点关注JNI实现的变化,是否存在 JNI 兼容性方面问题。
5.2 性能问题
产生性能消耗的主要有两点:
-
JNI 调用
-
DEX-VMP 与 系统 VM 的切换
优化建议:
-
JNI 调用是性能消耗主要因素。对于一些常用的 java class,可以在初始化时统一获取 jclass 缓存起来,这可以一定程度上提高性能,类似的还有避免重复查找 class。
-
尽量避免全量代码保护(dex 中所有的方法都 DEX-VMP 保护,包含 Android SDK 的基础类库),排除Android基础类库和开源类库,仅将业务自己的核心逻辑代码方法进行保护。
06 结语
总结来说,虚拟机加固是一种可以提高应用程序安全性的技术,但它也带来了性能、兼容性和维护成本等方面的挑战。
我们在使用代码虚拟化时,需要根据应用程序的特点和安全需求,合理选择和优化虚拟化方案。
——END——
推荐阅读:
搜索语义模型的大规模量化实践
如何设计一个高效的分布式日志服务平台
视频与图片检索中的多模态语义匹配模型:原理、启示、应用与展望
百度离线资源治理
百度APP iOS端包体积50M优化实践(三) 资源优化
代码级质量技术之基本框架介绍