1:模型量化是将浮点数替换成整数,并进行存储和计算的方法。
- 原始float数据
- 量化后int数据
- 量化公式
2:非饱和方式量化、饱和方式量化,对称量化、非对称量化,区别与关系是?

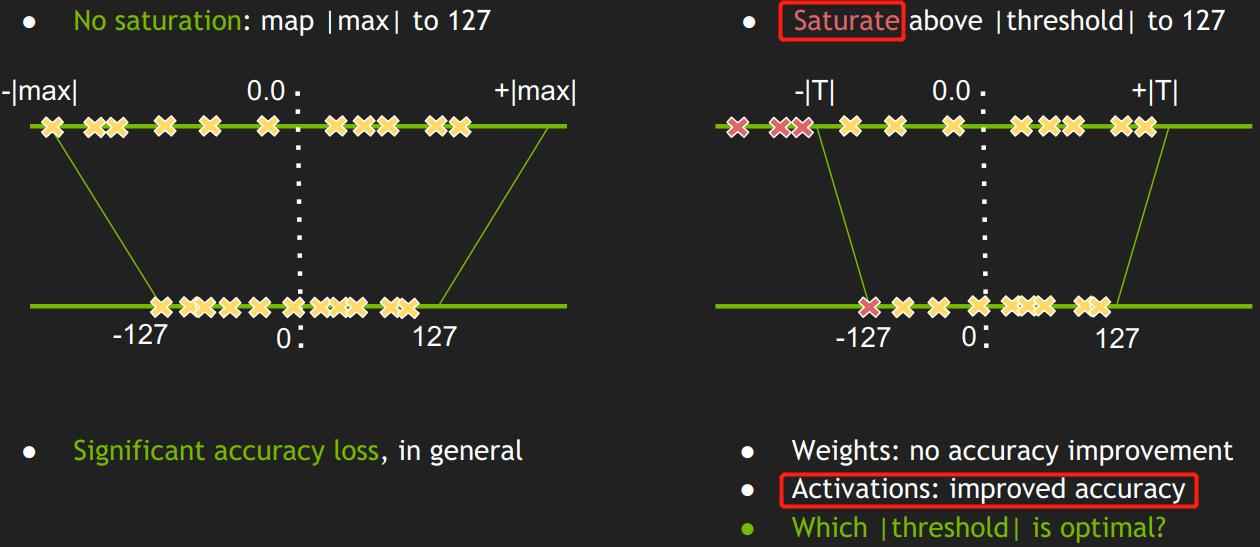
这个是tensorRT的量化方案,可以看出饱和与非饱和是可以与对称、非对称结合的。
量化方法
- 非饱和方式:将浮点数正负绝对值的最大值对应映射到整数的最大最小值,但有效值的动态范围在int8上会很小。
- 饱和方式:先计算浮点数的阈值T,然后根据浮点数的正负阈值T饱和截断,之后映射到整数的最大最小值。
- 仿射方式:将浮点数的最大最小值对应映射到整数的最大最小值。
红色代表非饱和方式,黄色代表饱和方式,绿色代表仿射方式
量化规则
- 非对称量化
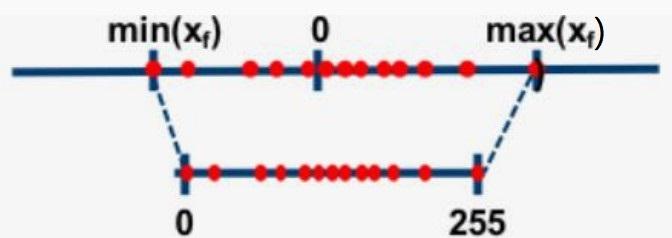

- 对称量化


- 对称量化

3谷歌白皮书建议:
- 对激活值X使用非对称量化,对权重值W使用对称量化
- 对激活值X采用饱和量化, 对权重值W采用非饱和量化
4激活为什么用饱和量化?
因为激活值通常分布不均匀,直接使用非饱和量化会使得量化后的值都挤在一个很小的范围从而浪费了INT8范围内的其他空间,也就是说没有充分利用INT8(-128~+127)的值域;
而进行饱和量化后,使得映射后的-128~+127范围内分布相对均匀,这相当于去掉了一些不重要的因素,保留了主要成分。
因此,如何寻找这个阈值T就成了量化的关键,逐步发展出不同的方案:
- MINMAX
- ADMM
- KL 散度

图中展示的是不同网络结构的不同 layer 的激活值分布统计图,横坐标是激活值,纵坐标是统计数量的归一化表示,而不是绝对数值统计;图中有卷积层和池化层,它们之间分布很不相同,因此合理的量化方法应该是适用于不同的激活值分布,并且减小信息损失。
上图的激活值统计针对的是一批图片,不同图片输出的激活值不完全相同,所以图中是多条曲线而不是一条曲线,曲线中前面一部分数据重合在一起了。(红色虚线)说明不同图片生成的大部分激活值其分布是相似的;但是在曲线的右边,激活值比较大时(红色实现圈起来的部分),曲线不重复了,一个激活值会对应多个不同的统计量,这时激活值分布是比较乱的。
曲线后面激活值分布比较乱的部分在整个网络层占是占少数的,因此曲线后面的激活值分布部分可以不考虑到映射关系中,只保留激活值分布的主方向。
一般认为量化之后的数据分布与量化前的数据分布越相似,量化对原始数据信息的损失也就越小,即量化算法精度越高。
参考文献:
1:一文搞懂模型量化算法_嵌入式视觉的技术博客_51CTO博客
2:【2】量化知识-1:量化基本知识点梳理 - 知乎
3: 【商汤泰坦公开课】模型量化了解一下?-核心技术-SenseTime | 商汤科技