GPT发展历程
在回答这个问题之前,首先要搞清楚ChatGPT的发展历程。
- GPT-1用的是无监督预训练+有监督微调。
- GPT-2用的是纯无监督预训练。
- GPT-3沿用了GPT-2的纯无监督预训练,但是数据大了好几个量级。
- InstructGPT在GPT-3上用强化学习做微调,内核模型为PPO-ptx,下面的论文会详细分析。
- ChatGPT沿用了InstructGPT,但是数据大了好几个量级。

总结来看,就是结合了监督学习和强化学习。
-
监督学习先让GPT-3有一个大致的微调方向,强化学习用了AC(Actor-Critic)架构里面的PPO(Proximal Policy Optimization)更新方法来更新GPT-3的参数。
-
PPO是OpenAI的baseline method,可以说使用PPO是InstructGPT非常自然的一个选择。
InstructGPT的这种训练方法的提出就是为了解决AI的毒性和不忠实性,因为人工标注数据的时候特别关注了这一块的优化,从结果来看在忠实性上InstructGPT已经比GPT-3提升了不少。
论文里提到,微调的数据考虑了大量安全方面的case,甚至邀请了DeepMind安全专家组共同研究。但是题主说的毁灭人类计划书的这个case诱导性还是比较强,模型在诱导attack的case下能力还是不足的,这也在论文的5.3节和5.4节讨论到了。随着模型能够存储的有效知识越来越多,模型的可靠性会越来越重要,这估计会引来一大堆研究。总体而言,目前模型的毒性还比较高,需要进一步的探索。
方法
为了使我们的模型更安全、更有帮助和更一致,我们使用了一种称为基于人类反馈的强化学习 (RLHF) 的现有技术。 在我们的客户向 API 提交的提示中,[1] 我们仅使用通过 Playground 提交给 2021 年 1 月部署的早期版本 InstructGPT 模型的提示。我们的人工注释者会从所有提示中删除个人身份信息,然后再将其添加到训练集。
我们的标签提供所需模型行为的演示,并对我们模型的几个输出进行排名。 然后我们使用这些数据来微调 GPT-3。
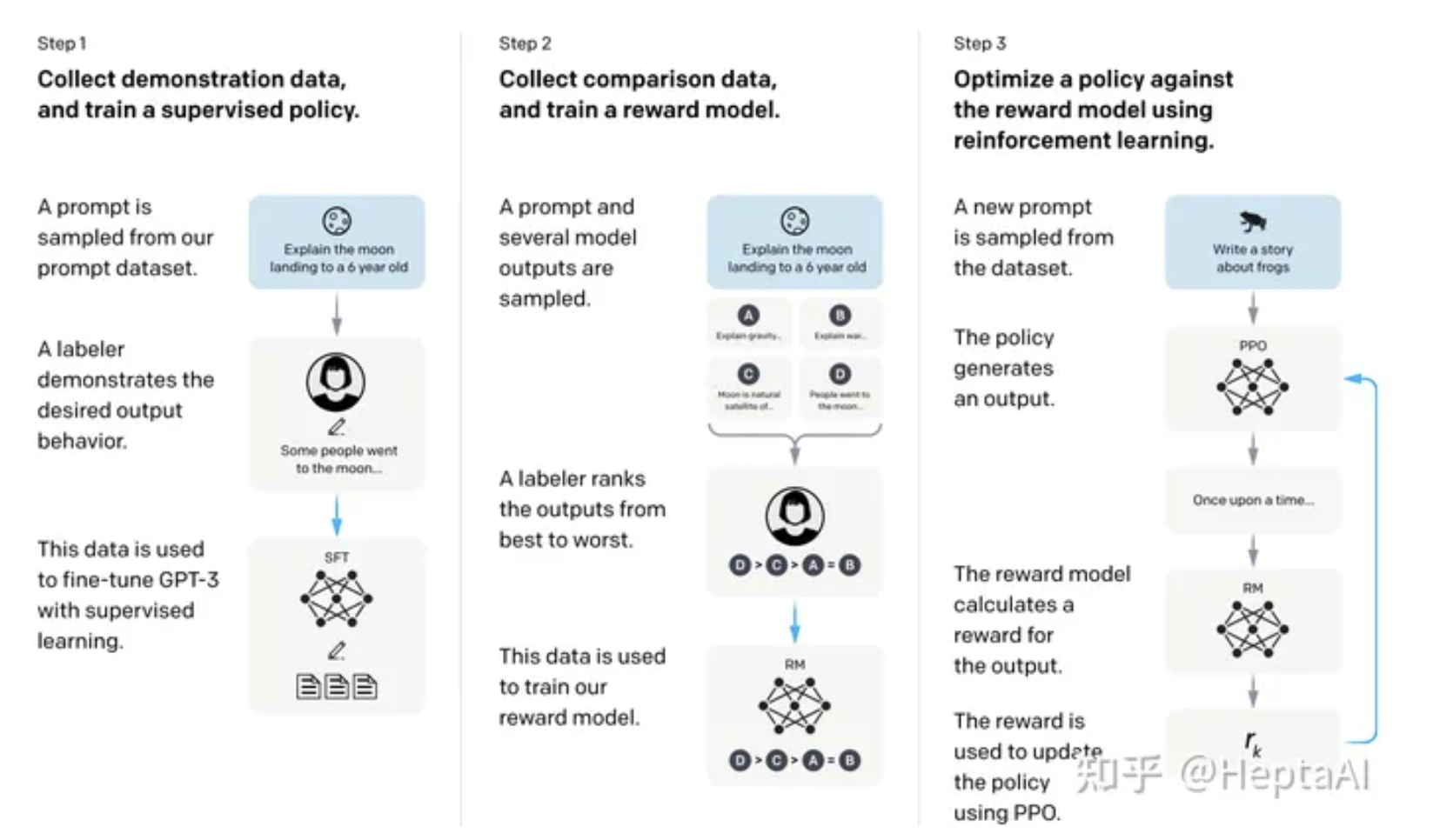
过程简述:
我们首先收集关于提交给我们 API 的提示的人工编写演示数据集,并使用它来训练我们的监督学习基线。 接下来,我们收集了一个数据集,该数据集包含两个模型输出在更大的 API 提示集上的人工标记比较。 然后我们在这个数据集上训练一个奖励模型 (RM) 来预测我们的标签者更喜欢哪个输出。 最后,我们使用此 RM 作为奖励函数并微调我们的 GPT-3 策略以使用 PPO 算法最大化此奖励。
对这一过程的一种思考方式是,它 “解锁 "了GPT-3已经具备的能力,但仅通过提示工程难以激发”
- 这是因为我们的训练程序相对于预训练期间学到的东西,教给模型新能力的能力有限,因为相对于模型预训练,它使用的计算和数据不到2%。

泛化的设置
我们的程序使我们的模型行为与我们的标签人员和我们的研究人员的偏好相一致,前者直接产生用于训练我们的模型的数据,后者则通过书面说明、对具体例子的直接反馈和非正式对话向标签人员提供指导。
- 它也受到我们的客户和我们的API政策中隐含的偏好的影响。我们选择了那些在识别和回应敏感提示的能力的筛选测试中表现良好的标签人员。然而,这些对数据的不同影响来源并不能保证我们的模型与任何更广泛群体的偏好相一致。
我们进行了两个实验来调查这一点。
- 首先,我们使用没有产生任何训练数据的被扣留的标签者来评估GPT-3和InstructGPT,发现这些标签者喜欢InstructGPT模型的输出的比率与我们的训练标签者差不多。
- 第二,我们在来自我们的标签者的一个子集的数据上训练奖励模型,发现它们在预测不同子集的标签者的偏好方面有很好的概括性。这表明,我们的模型并没有完全过度适应我们的训练标签者的偏好。然而,还需要做更多的工作来研究这些模型在更广泛的用户群体中的表现,以及它们在人类对所需行为有分歧的输入中的表现。
局限
- 尽管取得了重大进展,我们的InstructGPT模型还远未完全统一或完全安全;它们仍然产生有毒或有偏见的输出,编造事实,并在没有明确提示的情况下产生性和暴力内容。
- 现在,InstructGPT被训练成遵循英语指令;因此,它偏向于讲英语的人的文化价值观。
RLHF
构建安全 AI 系统的一个步骤是消除人类编写目标函数的需要,因为对复杂目标使用简单代理,或者将复杂目标弄错一点,可能会导致不良甚至危险的行为。 通过与 DeepMind 的安全团队合作,我们开发了一种算法,可以通过告知两种提议的行为中哪一种更好来推断人类的需求。
- 使用少量人类反馈来解决现代 RL 环境
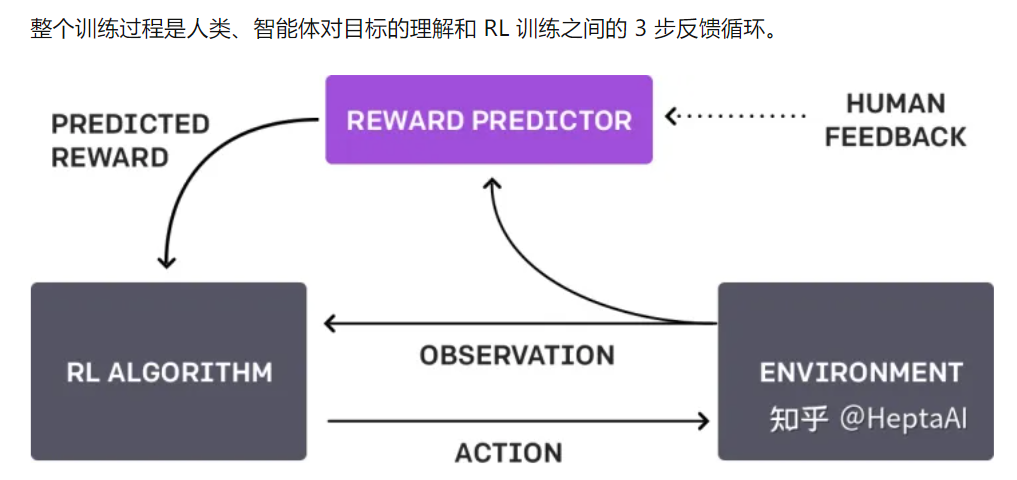
请注意,反馈不需要与环境的正常奖励函数保持一致:
- 例如,我们可以训练我们的代理在 Enduro 中精确地与其他汽车保持平衡,而不是通过超过它们来最大化游戏分数。
- 有时我们还发现,从反馈中学习比使用正常奖励函数的强化学习效果更好,因为人类比编写环境奖励的人更好地塑造奖励。
模型相关
- 我们然后使用三种不同的技术训练模型
监督微调(SFT)
我们使用监督学习在我们的标签演示中微调 GPT-3。 我们训练了 16 个epochs,使用余弦学习率衰减和 0.2 的残差丢失。 我们根据验证集上的 RM 分数进行最终的 SFT 模型选择。 与 Wu 等人类似 (2021),我们发现我们的 SFT 模型在 1 个时期后对验证损失过度拟合; 然而,我们发现尽管存在这种过度拟合,但更多时期的训练有助于 RM 分数和人类偏好评级。
奖励建模 (RM)
从移除了最终反嵌入层的 SFT 模型开始,我们训练了一个模型来接收提示和响应,并输出标量奖励。 在本文中,我们只使用 6B RM,因为这样可以节省大量计算,而且我们发现 175B RM 训练可能不稳定,因此不太适合用作 RL 期间的值函数(有关更多详细信息,请参见附录 C)。
在 Stiennon 等人 (2020) 的研究中,RM 在同一输入的两个模型输出之间进行比较的数据集上进行训练。 他们使用交叉熵损失,将比较作为标签——奖励的差异代表人类贴标签者更喜欢一种反应的对数几率。

- 最后,由于 RM 损失对于奖励的变化是不变的,我们使用偏差对奖励模型进行归一化,以便在进行 RL 之前,标记器演示的平均得分为 0。

为什么要训练这样一个reward model呢?当然,人类可以扮演Environment的角色,衡量模型输出每句对话的好坏(reward),但这需要大量的人工成本。所以,不妨训练好一个reward model,可以省去人工标注的麻烦。
强化学习 (RL)
再次跟随 Stiennon 等人 (2020),我们使用 PPO 在我们的环境中微调了 SFT 模型(Schulman 等人,2017)。 该环境是一个 bandit 环境,它呈现随机的客户提示并期望对提示的响应。 给定提示和响应,它会产生由奖励模型确定的奖励并结束episode。 此外,我们在每个token上添加了 SFT 模型的每个token的 KL penalty,以减轻奖励模型的过度优化。 值函数从 RM 初始化。 我们称这些模型为“PPO”。
我们将 PPO 模型的性能与我们的 SFT 模型和 GPT-3 进行了比较。 我们还与 GPT-3 进行了比较,当它被提供一个 few-shot 前缀以“提示”它进入指令跟随模式(GPT-3-prompted)时。
我们还在 FLAN(Wei 等人,2021 年)和 T0(Sanh 等人,2021 年)数据集上将 InstructGPT 与微调 175B GPT-3 进行了比较,这两个数据集都包含各种 NLP 任务,并对于每个任务结合了自然语言指令(数据集在包含的 NLP 数据集和使用的指令风格方面有所不同)。 我们分别在大约 100 万个示例上对它们进行微调,并选择在验证集上获得最高奖励模型分数的检查点。 有关更多training的详细信息,请参阅附录 C。
PPO
InstructGPT用的算法是强化学习中的PPO,PPO也是OpenAI之前的工作,作为OpenAI强化学习的baseline。
- 损失函数如下所示:

评估
要评估我们的模型“对齐”的程度,我们首先需要弄清楚对齐在这种情况下的含义。
目标是训练根据用户意图行事的模型。 有帮助、诚实、无害。
我们使用两个指标来衡量真实性——模型关于世界的陈述是否真实:
(1) 评估我们的模型在封闭域任务上编造信息的倾向(“幻觉”也就“hallucinations”)
(2) 使用 TruthfulQA 数据集( 林等人,2021)。 不用说,这只抓住了真实真正含义的一小部分。
定量评估:我们可以将定量评估分为两个独立的部分
- API 分布评估。 我们的主要指标是人类对一组提示的偏好评级,这些提示来自与我们的训练分布相同的来源。 当使用来自 API 的提示进行评估时,我们只选择我们未包含在培训中的客户的提示。
- 对公共 NLP 数据集的评估。 我们评估两种类型的公共数据集:那些捕捉语言模型安全性方面的数据集,特别是真实性、毒性和偏见,以及那些捕捉传统 NLP 任务(如问答、阅读理解和摘要)的零样本性能的数据集。
对准性研究
对准的目的:使人工智能系统与人类意图保持一致
吸取对齐研究的经验教训:
相对于预训练,增加模型对齐的成本是适度的。RLHF 在使语言模型对用户更有帮助方面非常有效,比模型大小增加 100 倍更有效。- 我们已经看到一些证据表明 InstructGPT 将“遵循指令”泛化为我们不对其进行监督的设置,例如非英语语言任务和与代码相关的任务。 这是一个重要的属性,因为让人类监督模型执行的每项任务的成本高得令人望而却步。
我们能够减轻微调带来的大部分性能下降。为了避免激励未来的高性能人工智能系统与人类意图保持不一致,需要具有低对齐税的对齐技术。 为此,我们的结果对于 RLHF 作为一种低税对准技术来说是个好消息。我们已经从现实世界的研究中验证了对齐技术。
如何调整对准的偏好
- 首先,我们正在调整我们的训练贴标机提供的演示和偏好,他们直接生成我们用来微调模型的数据。
- 其次,我们正在调整我们的偏好。我们编写标记说明,标记者在编写演示和选择他们喜欢的输出时用作指南,并且 我们在共享聊天室中回答他们关于边缘案例的问题。
- 第三,我们的训练数据由 OpenAI 客户发送给 OpenAI API Playground 上的模型的提示决定,因此我们隐含地与客户认为有价值的东西保持一致,在某些情况下,他们的最终用户认为当前使用的有价值的东西 的API。
- 第四,OpenAI 的客户并不代表所有潜在或当前的语言模型用户——更不用说所有受语言模型使用影响的个人和群体了。
数据集
- plain:标注人员自己去想一些问题出来
- few-shot:标注人员想一些instruction,然后给一些输入输出的实例
- user-based:根据用户提出的一些想让应用实现的功能(waitlist applications)来构建任务
- 用这些prompt数据来设计第一个instructGPT模型,然后把这个模型拿出来放到PlayGround上让大家去使用,从而收集更多的prompt数据。这样就构建了如下三个数据集:
- 让标注人员直接把prompt的答案写出来,这就构成了训练SFT(supervised finetuning model)的数据 (13k样本)
- 让标注人员把模型的输出排序,这就构成了训练RM(reward model)的数据 (33k样本)
- 根据RM的标注来生成训练强化学习模型的数据(31k样本)
InstructGPT学习:知乎文章
https://zhuanlan.zhihu.com/p/589747432