强化学习
本文是强化学习和Q-Learning算法的概念及原理
项目实战案例可查看下一篇文章:Q-Learning 单路径吃宝箱问题–棋盘格吃宝箱问题–拓扑节点较优路径问题
一. 强化学习概述
1.1 什么是强化学习
基于环境的反馈而行动,通过不断与环境的交互、试错,最终完成特定目的或者使得行动收益最大化。强化学习不需要训练数据,但是它需要每一步行动环境给予的反馈,是奖励还是惩罚,反馈可以量化,基于反馈不断调整训练对象的行为。
1.2 强化学习的特点
- 试错学习:强化学习需要训练对象不停地和环境进行交互,通过试错的方式去总结出每一步的最佳行为决策,整个过程没有任何的指导,只有反馈。所有的学习基于环境反馈,训练对象去调整自己的行为决策。
- 延迟反馈:强化学习训练过程中,训练对象的“试错”行为获得环境的反馈,有时候可能需要等到整个训练结束以后才会得到一个反馈,比如Game Over或者是Win。
- 时间是强化学习的一个重要因素:强化学习的一系列环境状态的变化和环境反馈等都是和时间强挂钩,整个强化学习的训练过程是一个随着时间变化,而状态&反馈也在不停变化。
- 当前的行为影响后续接收到的数据:强化学习当前状态以及采取的行动,将会影响下一步接收到的状态,数据与数据之间存在一定的关联性。
1.2 强化学习术语
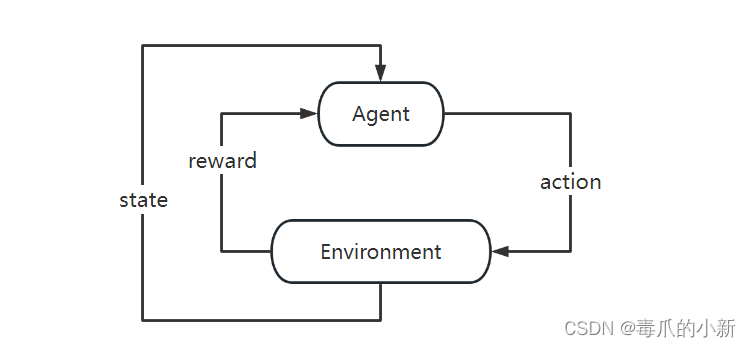
简单解释强化学习来说,即:智能体在于环境的交互过程中为了达到目标而进行的学习过程
-
Agent(智能体):强化学习训练的主体就是Agent
-
Environment(环境):强化学习所处的环境
-
goal(目标):强化学习要实现的目标
进一步理解,智能体在当前状态下采取行动可以获得反馈,最终需要达到目标
-
State(状态):当前环境和智能体所处的状态
-
Action(行动):基于当前的状态,智能体可以采取什么行动
-
Reward(奖励,也可以理解为反馈):智能体采取行动后获得的奖励或惩罚
二. 强化学习决策及算法
2.1 马尔科夫决策过程
强化学习的整个训练过程都基于一个前提,我们认为整个过程都是符合马尔可夫决策过程(Markov Decision Process,MDP)
核心思想
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0ZSTg6T6-1687939218832)(C:\Users\29973\AppData\Roaming\Typora\typora-user-images\image-20230616171616808.png)]](https://img-blog.csdnimg.cn/d88de0ded63143bc9522a1a12ea8e99a.png)
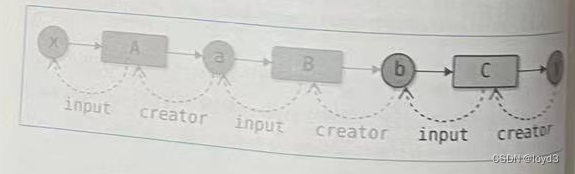
马尔可夫决策过程的核心思想是:
下一步的State只和当前的状态State以及当前状态将要采取的Action有关,如上图所示State3只和State2以及Action2有关,和State1以及Action1无关
2.2 价值函数
2.2.1 Value Based 算法
介绍
价值函数分为两种,一种是V状态价值函数,一种是Q状态行动函数。Q值评估的是动作的价值,代表agent做了这个动作之后一直到最终状态奖励总和的期望值;V值评估的是状态的价值,代表agent在这个状态下一直到最终状态的奖励总和的期望。价值越高,表示我从当前状态到最终状态能获得的平均奖励将会越高,因此我选择价值高的动作就可以了
2.2.2 Policy Based 算法
Policy决定了某个state下应该选取哪一个action。策略Policy为每一个动作分配概率,例如:π(s1|a1) = 0.3,表示在状态s1下选择动作a1的概率是0.3,而该策略只依赖于当前的状态,不依赖于以前时间的状态,因此整个过程也是一个马尔可夫决策过程
三. Q-learning
3.1 算法讲解
Q-learning 算法
Q-learning是一种基于动作函数(即Q函数)的强化学习方法,即通过判断每一步 action 的 value来进行下一步的动作,具体步骤如下:
- 建立
Q表,行是每种状态,列是每种状态的行为,值是某状态下某行为估计获得的奖励 - 每次进行状态转移时有
e_greedy概率选当前状态最优方法,有1- e_greedy选随机方法 - 选完之后就更新当前状态下对应所选行为的
Q值(估计值)
Q函数更新方法
在讲解函数的更新方法前,Q函数中有两个操作因素需要重点关注
α:称之为学习率,决定了在更新Q值时,当前状态和动作对于新估计值的贡献程度。值为0意味着代理不会学到任何东西,只依赖于初始的Q值或之前学习到的知识;值为1意味着意味着完全采用新观察到的奖励或更新的目标值,忽略之前学习到的估计值。γ:称之为折扣因子或者衰减率,它定义了未来奖励的重要性。值为0意味着只考虑短期奖励,其中1的值更重视长期奖励。
在实际算法中,Q函数的具体的更新函数为
实际更新Q值 = 当前Q值 + 学习率 *(立即回报 + 预测后继状态的最大Q值 - 当前Q值)
定义公式化更新函数
Q ( S t , A t ) ← Q ( S t , A t ) + α [ R + γ ∗ M a x Q ( S t + 1 , a t + 1 ) − Q ( S t , A t ) ] Q(S_t,A_t)←Q(S_t,A_t)+α[R+γ*MaxQ(S_{t+1},a_{t+1})−Q(S_t,A_t)] Q(St,At)←Q(St,At)+α[R+γ∗MaxQ(St+1,at+1)−Q(St,At)]
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-f0VeQvSh-1687939218833)(C:\Users\29973\AppData\Roaming\Typora\typora-user-images\image-20230625093857183.png)]](https://img-blog.csdnimg.cn/c2cd26207e544f41b9c078576af37e4f.png)
实现步骤
在实际算法中,Q-learning算法的实现步骤如下:
Step 1 :给定折扣因子 γ 、学习率 α、奖励矩阵 Q
Step 2 :令状态行动 Q 函数初始化为 0
Step 3 :开始迭代
3.1 随机选择一个状态 s
3.2 若从该状态无法达到目标,则执行以下几步
(1)从当前状态所有可能的行为中选取一个行为 a
(2)从选定的行为 a ,得到下一个状态 r
(3)按照 Q 函数的更新方法进行值更行
(4)设置当前状态 s 为 r
四. 参考文献
本次学习参考了部分文章,较原始代码进行了部分改良或全部改良,添加了大量注释方便初学者学习,原参考文章链接:
强化学习系列(一):基本原理和概念
机器学习算法(三十):强化学习(Reinforcement Learning)