目录
- 正文
- 函数开头定义的一些常量和变量
- while 循环
- parseStartTag 函数解析开始标签
- 总结:
正文
接上篇:
Vue编译器源码分析AST 抽象语法树
?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | function parseHTML(html, options) {
var stack = [];
var expectHTML = options.expectHTML;
var isUnaryTag$$1 = options.isUnaryTag || no;
var canBeLeftOpenTag$$1 = options.canBeLeftOpenTag || no;
var index = 0;
var last, lastTag;
// 开启一个 while 循环,循环结束的条件是 html 为空,即 html 被 parse 完毕
while (html) {
last = html;
if (!lastTag || !isPlainTextElement(lastTag)) {
// 确保即将 parse 的内容不是在纯文本标签里 (script,style,textarea)
} else {
// parse 的内容是在纯文本标签里 (script,style,textarea)
}
//将整个字符串作为文本对待
if (html === last) {
options.chars && options.chars(html);
if (!stack.length && options.warn) {
options.warn(("Mal-formatted tag at end of template: \"" + html + "\""));
}
break
}
}
// Clean up any remaining tags
parseEndTag();
function advance(n) {
index += n;
html = html.substring(n);
}
//parse 开始标签
function parseStartTag() {
//...
}
//处理 parseStartTag 的结果
function handleStartTag(match) {
//...
}
//parse 结束标签
function parseEndTag(tagName, start, end) {
//...
}
}
|
可以看到 parseHTML 函数接收两个参数:html 和 options ,其中 html 是要被编译的字符串,而options则是编译器所需的选项。
整体上来讲 parseHTML分为三部分。
- 函数开头定义的一些常量和变量
- while 循环
- parse 过程中需要用到的 analytic function
函数开头定义的一些常量和变量
先从第一部分开始讲起
?
| 1 2 3 4 5 6 | var stack = [];
var expectHTML = options.expectHTML;
var isUnaryTag$$1 = options.isUnaryTag || no;
var canBeLeftOpenTag$$1 = options.canBeLeftOpenTag || no;
var index = 0;
var last, lastTag;
|
第一个变量是 stack,它被初始化为一个空数组,在 while 循环中处理 html 字符流的时候每当遇到一个非单标签,都会将该开始标签 push 到该数组。它的作用模板中 DOM 结构规范性的检测。
但在一个 html 字符串中,如何判断一个非单标签是否缺少结束标签呢?
假设我们有如下html字符串:
?
| 1 | <div><p><span></p></div>
|
在编译这个字符串的时候,首先会遇到 div 开始标签,并将该 push 到 stack 数组,然后会遇到 p 开始标签,并将该标签 push 到 stack ,接下来会遇到 span 开始标签,同样被 push 到 stack ,此时 stack 数组内包含三个元素。
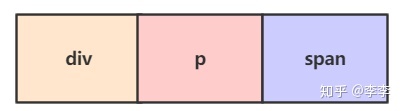
再然后便会遇到 p 结束标签,按照正常逻辑可以推理出最先遇到的结束标签,其对应的开始标签应该最后被push到 stack 中,也就是说 stack 栈顶的元素应该是 span ,如果不是 span 而是 p,这说明 span 元素缺少闭合标签。
这就是检测 html 字符串中是否缺少闭合标签的原理。
第二个变量是 expectHTML,它的值被初始化为 options.expectHTML,也就是编译器选项中的 expectHTML。
第三个常量是 isUnaryTag,用来检测一个标签是否是一元标签。
第四个常量是 canBeLeftOpenTag,用来检测一个标签是否是可以省略闭合标签的非一元标签。
- index 初始化为 0 ,标识着当前字符流的读入位置。
- last 存储剩余还未编译的 html 字符串。
- lastTag 始终存储着位于 stack 栈顶的元素。
while 循环
接下来将进入第二部分,即开启一个 while 循环,循环的终止条件是 html 字符串为空,即html 字符串全部编译完毕。
?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 | while (html) {
last = html;
// Make sure we're not in a plaintext content element like script/style
if (!lastTag || !isPlainTextElement(lastTag)) {
var textEnd = html.indexOf('<');
if (textEnd === 0) {
// Comment:
if (comment.test(html)) {
var commentEnd = html.indexOf('-->');
if (commentEnd >= 0) {
if (options.shouldKeepComment) {
options.comment(html.substring(4, commentEnd));
}
advance(commentEnd + 3);
continue
}
}
// http://en.wikipedia.org/wiki/Conditional_comment#Downlevel-revealed_conditional_comment
if (conditionalComment.test(html)) {
var conditionalEnd = html.indexOf(']>');
if (conditionalEnd >= 0) {
advance(conditionalEnd + 2);
continue
}
}
// Doctype:
var doctypeMatch = html.match(doctype);
if (doctypeMatch) {
advance(doctypeMatch[0].length);
continue
}
// End tag:
var endTagMatch = html.match(endTag);
if (endTagMatch) {
var curIndex = index;
advance(endTagMatch[0].length);
parseEndTag(endTagMatch[1], curIndex, index);
continue
}
// Start tag:
var startTagMatch = parseStartTag();
if (startTagMatch) {
handleStartTag(startTagMatch);
if (shouldIgnoreFirstNewline(startTagMatch.tagName, html)) {
advance(1);
}
continue
}
}
var text = (void 0),
rest = (void 0),
next = (void 0);
if (textEnd >= 0) {
rest = html.slice(textEnd);
while (
!endTag.test(rest) &&
!startTagOpen.test(rest) &&
!comment.test(rest) &&
!conditionalComment.test(rest)
) {
// < in plain text, be forgiving and treat it as text
next = rest.indexOf('<', 1);
if (next < 0) {
break
}
textEnd += next;
rest = html.slice(textEnd);
}
text = html.substring(0, textEnd);
advance(textEnd);
}
if (textEnd < 0) {
text = html;
html = '';
}
if (options.chars && text) {
options.chars(text);
}
} else {
var endTagLength = 0;
var stackedTag = lastTag.toLowerCase();
var reStackedTag = reCache[stackedTag] || (reCache[stackedTag] = new RegExp('([\\s\\S]*?)(</' + stackedTag +
'[^>]*>)', 'i'));
var rest$1 = html.replace(reStackedTag, function(all, text, endTag) {
endTagLength = endTag.length;
if (!isPlainTextElement(stackedTag) && stackedTag !== 'noscript') {
text = text
.replace(/<!\--([\s\S]*?)-->/g, '$1') // #7298
.replace(/<!\[CDATA\[([\s\S]*?)]]>/g, '$1');
}
if (shouldIgnoreFirstNewline(stackedTag, text)) {
text = text.slice(1);
}
if (options.chars) {
options.chars(text);
}
return ''
});
index += html.length - rest$1.length;
html = rest$1;
parseEndTag(stackedTag, index - endTagLength, index);
}
if (html === last) {
options.chars && options.chars(html);
if (!stack.length && options.warn) {
options.warn(("Mal-formatted tag at end of template: \"" + html + "\""));
}
break
}
}
|
首先将在每次循环开始时将 html 的值赋给变量 last :
?
为什么这么做?在 while 循环即将结束的时候,有一个对 last 和 html 这两个变量的比较,在此可以找到答案:
?
如果两者相等,则说明html 在经历循环体的代码之后没有任何改变,此时会"Mal-formatted tag at end of template: \"" + html + "\"" 错误信息提示。
接下来可以简单看下整体while循环的结构。
?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | while (html) {
last = html
if (!lastTag || !isPlainTextElement(lastTag)) {
// parse 的内容不是在纯文本标签里
} else {
// parse 的内容是在纯文本标签里 (script,style,textarea)
}
// 极端情况下的处理
if (html === last) {
options.chars && options.chars(html)
if (process.env.NODE_ENV !== 'production' && !stack.length && options.warn) {
options.warn(`Mal-formatted tag at end of template: "${html}"`)
}
break
}
}
|
接下来我们重点来分析这个if else 中的代码。
?
| 1 | !lastTag || !isPlainTextElement(lastTag)
|
lastTag 刚刚讲到它会一直存储 stack 栈顶的元素,但是当编译器刚开始工作时,他只是一个空数组对象,![] == false
isPlainTextElement(lastTag) 检测 lastTag 是否为纯标签内容。
?
| 1 | var isPlainTextElement = makeMap('script,style,textarea', true);
|
lastTag 为空数组 ,isPlainTextElement(lastTag ) 返回false, !isPlainTextElement(lastTag) ==true, 有兴趣的同学可以阅读下 makeMap 源码。
接下来我们继续往下看,简化版的代码。
?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | if (!lastTag || !isPlainTextElement(lastTag)) {
var textEnd = html.indexOf('<')
if (textEnd === 0) {
// 第一个字符就是(<)尖括号
}
var text = (void 0),
rest = (void 0),
next = (void 0);
if (textEnd >= 0) {
//第一个字符不是(<)尖括号
}
if (textEnd < 0) {
// 第一个字符不是(<)尖括号
}
if (options.chars && text) {
options.chars(text)
}
} else {
// 省略 ...
}
|
textEnd ===0
当 textEnd === 0 时,说明 html 字符串的第一个字符就是左尖括号,比如 html 字符串为:<div>box</div>,那么这个字符串的第一个字符就是左尖括号(<)。
?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | if (textEnd === 0) {
// Comment: 如果是注释节点
if (comment.test(html)) {
var commentEnd = html.indexOf('-->');
if (commentEnd >= 0) {
if (options.shouldKeepComment) {
options.comment(html.substring(4, commentEnd));
}
advance(commentEnd + 3);
continue
}
}
//如果是条件注释节点
if (conditionalComment.test(html)) {
var conditionalEnd = html.indexOf(']>');
if (conditionalEnd >= 0) {
advance(conditionalEnd + 2);
continue
}
}
// 如果是 Doctyp节点
var doctypeMatch = html.match(doctype);
if (doctypeMatch) {
advance(doctypeMatch[0].length);
continue
}
// End tag: 结束标签
var endTagMatch = html.match(endTag);
if (endTagMatch) {
var curIndex = index;
advance(endTagMatch[0].length);
parseEndTag(endTagMatch[1], curIndex, index);
continue
}
// Start tag: 开始标签
var startTagMatch = parseStartTag();
if (startTagMatch) {
handleStartTag(startTagMatch);
if (shouldIgnoreFirstNewline(startTagMatch.tagName, html)) {
advance(1);
}
continue
}
}
|
细枝末节我们不看,重点在End tag 、 Start tag 上。
我们先从解析标签开始分析
?
| 1 2 3 4 5 6 7 8 | var startTagMatch = parseStartTag();
if (startTagMatch) {
handleStartTag(startTagMatch);
if (shouldIgnoreFirstNewline(startTagMatch.tagName, html)) {
advance(1);
}
continue
}
|
parseStartTag 函数解析开始标签
解析开始标签会调用parseStartTag函数,如果有返回值,说明开始标签解析成功。
?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | function parseStartTag() {
var start = html.match(startTagOpen);
if (start) {
var match = {
tagName: start[1],
attrs: [],
start: index
};
advance(start[0].length);
var end, attr;
while (!(end = html.match(startTagClose)) && (attr = html.match(attribute))) {
advance(attr[0].length);
match.attrs.push(attr);
}
if (end) {
match.unarySlash = end[1];
advance(end[0].length);
match.end = index;
return match
}
}
}
|
parseStartTag 函数首先会调用 html 字符串的 match 函数匹配 startTagOpen 正则,前面我们分析过编译器所需的正则。
Vue编译器token解析规则-正则分析
如果匹配成功,那么start 将是一个包含两个元素的数组:第一个元素是标签的开始部分(包含< 和 标签名称);第二个元素是捕获组捕获到的标签名称。比如有如下template:
?
start为:
?
| 1 | start = ['<div', 'div']
|
接下来:
定义了 match 变量,它是一个对象,初始状态下拥有三个属性:
- tagName:它的值为 start[1] 即标签的名称。
- attrs :这个数组就是用来存储将来被匹配到的属性。
- start:初始值为 index,是当前字符流读入位置在整个 html 字符串中的相对位置。
?
| 1 | advance(start[0].length);
|
相对就比较简单了,他的作用就是在源字符中截取已经编译完成的字符,我们知道当html 字符为 “”,整个词法分析的工作就结束了,在这中间扮演重要角色的就是advance方法。
?
| 1 2 3 4 | function advance(n) {
index += n;
html = html.substring(n);
}
|
接下来:
?
| 1 2 3 4 5 6 7 8 9 10 11 12 | var end, attr;
while (!(end = html.match(startTagClose)) && (attr = html.match(attribute))) {
advance(attr[0].length);
match.attrs.push(attr);
}
if (end) {
match.unarySlash = end[1];
advance(end[0].length);
match.end = index;
return match
}
}
|
主要看while循环,循环的条件有两个,第一个条件是:没有匹配到开始标签的结束部分,这个条件的实现方式主要使用了 startTagClose 正则,并将结果保存到 end 变量中。
第二个条件是:匹配到了属性,主要使用了attribute正则。
总结下这个while循环成立要素:没有匹配到开始标签的结束部分,并且匹配到了开始标签中的属性,这个时候循环体将被执行,直到遇到开始标签的结束部分为止。
接下来在循环体内做了两件事,首先调用advance函数,参数为attr[0].length即整个属性的长度。然后会将此次循环匹配到的结果push到前面定义的match对象的attrs数组中。
?
| 1 2 | advance(attr[0].length);
match.attrs.push(attr);
|
接下来看下最后这部分代码。
?
| 1 2 3 4 5 6 | if (end) {
match.unarySlash = end[1];
advance(end[0].length);
match.end = index;
return match
}
|
首先判断了变量 end 是否为真,我们知道,即使匹配到了开始标签的开始部分以及属性部分但是却没有匹配到开始标签的结束部分,这说明这根本就不是一个开始标签。所以只有当变量end存在,即匹配到了开始标签的结束部分时,才能说明这是一个完整的开始标签。
如果变量end的确存在,那么将会执行 if 语句块内的代码,不过我们需要先了解一下变量end的值是什么?
比如当html(template)字符串如下时:
<br />
那么匹配到的end的值为:
end = ['/>', '/']
比如当html(template)字符串如下时:
<div></div>
那么匹配到的end的值为:
end = ['>', undefined]
结论如果end[1]不为undefined,那么说明该标签是一个一元标签。
那么现在再看if语句块内的代码,将很容易理解,首先在match对象上添加unarySlash属性,其值为end[1]
?
| 1 | match.unarySlash = end[1];
|
然后调用advance函数,参数为end[0].length,接着在match 对象上添加了一个end属性,它的值为index,注意由于先调用的advance函数,所以此时的index已经被更新了。最后将match 对象作为 parseStartTag 函数的返回值返回。
只有当变量end存在时,即能够确定确实解析到了一个开始标签的时候parseStartTag函数才会有返回值,并且返回值是match对象,其他情况下parseStartTag全部返回undefined。
总结:
我们模拟假设有如下html(template)字符串:
?
| 1 | <div id="box" v-if="watings"></div>
|
则parseStartTag函数的返回值如下:
?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | match = {
tagName: 'div',
attrs: [
[
'id="box"',
'id',
'=',
'box',
undefined,
undefined
],
[
' v-if="watings"',
'v-if',
'=',
'watings',
undefined,
undefined
]
],
start: index,
unarySlash: undefined,
end: index
}
|
我们讲解完了parseStartTag函数及其返回值,现在我们回到对开始标签的 parse 部分,接下来我们会继续讲解,拿到返回值之后的处理。
?
| 1 2 3 4 5 6 7 8 | var startTagMatch = parseStartTag();
if (startTagMatch) {
handleStartTag(startTagMatch);
if (shouldIgnoreFirstNewline(startTagMatch.tagName, html)) {
advance(1);
}
continue
}
|
篇幅有限请移步:
parseHTML 函数源码解析返回值后的处理