目录
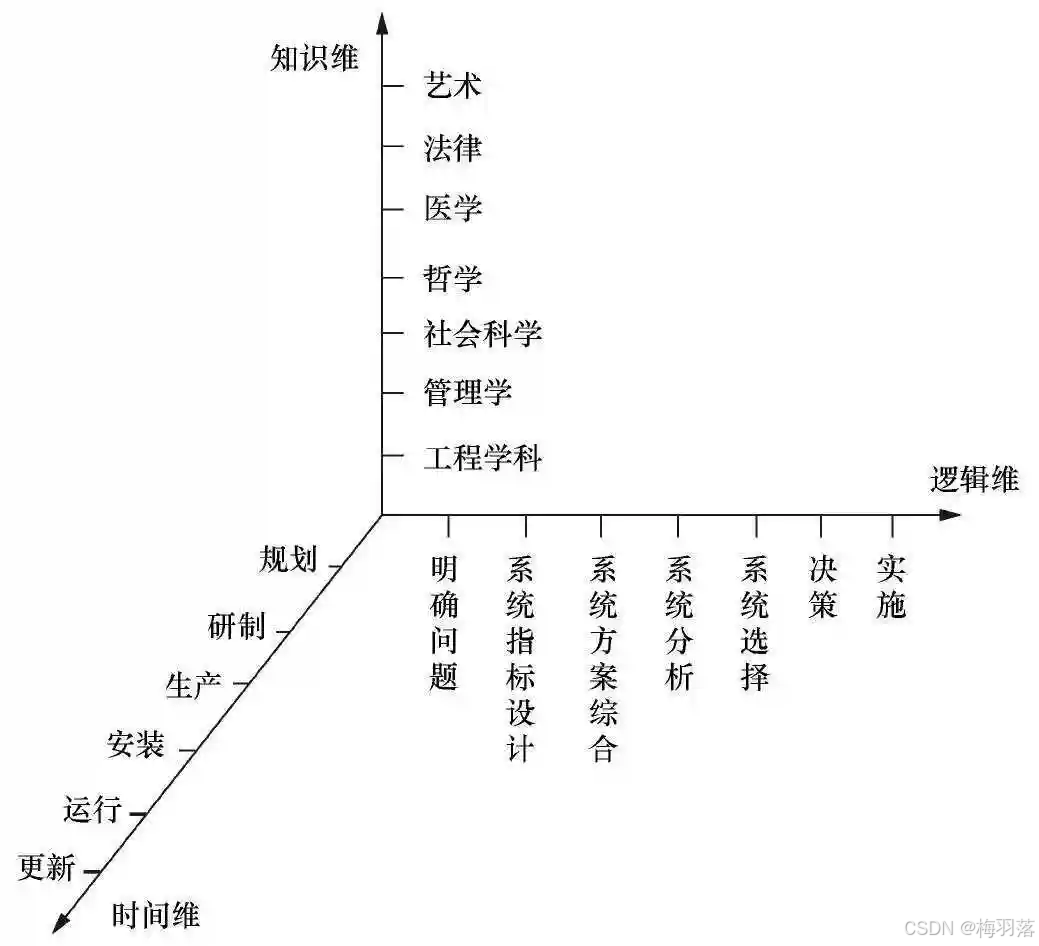
- 一、 为什么需要主从复制?🤔
- 二、 如何搭建主从架构?
- 前提条件✅
- 步骤
- 📁 创建工作目录
- 📜 创建 Docker Compose 配置文件
- 🚀 启动所有 Redis
- 🔍 验证主从状态
- 💡 重要提示和后续改进
- 三、 主从复制的数据同步原理是什么?
- 四、 主从复制的优缺点是什么?
- 五、 总结
🌟我的其他文章也讲解的比较有趣😁,如果喜欢博主的讲解方式,可以多多支持一下,感谢🤗!
🌟了解 缓存雪崩、穿透、击穿 请看 : 缓存雪崩、穿透、击穿:别让你的数据库“压力山大”!
其他优质专栏: 【🎇SpringBoot】【🎉多线程】【🎨Redis】【✨设计模式专栏(已完结)】…等
如果喜欢作者的讲解方式,可以点赞收藏加关注,你的支持就是我的动力
✨更多文章请看个人主页: 码熔burning
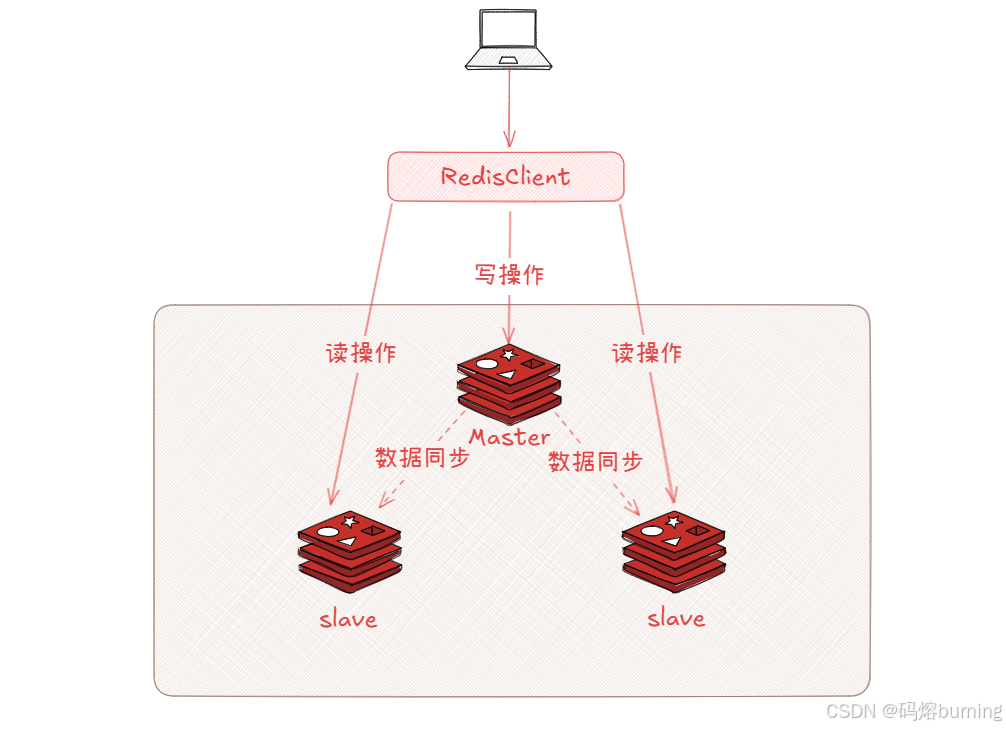
Redis主从复制,可以把它想象成一个“跟班”系统
- Master (主节点):就是“大哥” ,所有的事情(写数据📝、改数据✏️)都由他说了算,他手里有最新的、最全的信息(数据)。
- Slave (从节点):就是“小弟”或“跟班” ,他们不直接干活(默认不能写数据),主要任务就是时刻盯着大哥 👀,大哥做了什么,他们就跟着学(复制数据🔄),保持和大哥信息同步。
一、 为什么需要主从复制?🤔
主要有这么几个原因:
-
a. 数据备份与高可用 (大哥万一出事了 💀,有人顶上 💪):
- 备份:小弟手里有大哥数据的完整副本 📑。万一大哥突然“挂了”(服务器宕机、硬盘坏了),数据不会完全丢失,至少小弟那里还有一份。
- 高可用:如果大哥真的出事了,我们可以快速“提拔”一个小弟当新大哥(这个过程叫“故障转移”,通常需要配合哨兵模式或集群模式自动完成 ✨),保证服务能快速恢复,不会停太久。
-
b. 读写分离,提升性能 (大哥太忙 🥵,小弟分担点任务 🤝):
- 在一个系统中,“读”数据的操作往往比“写”数据的操作多得多。
- 如果所有读写请求都压在大哥一个人身上,他可能会累垮(性能瓶颈 🏺)。
- 有了小弟后,可以让大哥专门处理“写”请求和少量的“读”请求,而把大量的“读”请求分流给各个小弟去处理。这样大家分工合作,整个系统的处理能力就上去了 🚀,响应速度也更快 ⚡。这就像大哥负责决策和发布命令,小弟们负责对外宣传和解答疑问。
-
c. 负载均衡 (分摊压力 ⚖️):
- 和读写分离类似,多个小弟可以分摊读请求的压力,避免所有读请求都集中在一台服务器上。
二、 如何搭建主从架构?
下面是使用一台 Linux 服务器和 Docker 技术搭建 Redis 一主二从(Master-Slave)复制结构的步骤。我们将使用 Docker Compose 来简化管理。
前提条件✅
- 拥有一台 Linux 服务器 🖥️。
- 服务器上已安装 Docker 和 Docker Compose 🐳(这里就不演示了,自行查找教程安装)。
- 安装完成之后,使用
docker pull redis来拉去最新的redis的镜像。
步骤
📁 创建工作目录
在你的服务器上选择一个合适的位置,创建一个用于存放配置文件的目录。
mkdir redis-cluster
cd redis-cluster
📜 创建 Docker Compose 配置文件
在 redis-cluster 目录下创建一个名为 docker-compose.yml 的文件,并填入以下内容:
services:
redis-master:
image: redis:latest # 或者指定具体版本, 如 redis:7.2
container_name: redis-master
ports:
- "6379:6379" # 将主节点的 6379 端口映射到宿主机的 6379 端口
networks:
- redis-net
# 可以添加 volumes 实现数据持久化 (可选) 💾
# volumes:
# - ./master-data:/data
# - ./master-redis.conf:/usr/local/etc/redis/redis.conf # 如果需要自定义配置
# command: redis-server /usr/local/etc/redis/redis.conf # 如果使用了自定义配置
redis-slave1:
image: redis:latest
container_name: redis-slave1
ports:
- "6380:6379" # 将第一个从节点的 6379 端口映射到宿主机的 6380 端口
networks:
- redis-net
command: redis-server --slaveof redis-master 6379 # 🔑 指定主节点地址和端口
depends_on:
- redis-master # 确保主节点先启动
# 可以添加 volumes 实现数据持久化 (可选) 💾
# volumes:
# - ./slave1-data:/data
# - ./slave1-redis.conf:/usr/local/etc/redis/redis.conf
# command: redis-server /usr/local/etc/redis/redis.conf --slaveof redis-master 6379
redis-slave2:
image: redis:latest
container_name: redis-slave2
ports:
- "6381:6379" # 将第二个从节点的 6379 端口映射到宿主机的 6381 端口
networks:
- redis-net
command: redis-server --slaveof redis-master 6379 # 🔑 指定主节点地址和端口
depends_on:
- redis-master # 确保主节点先启动
# 可以添加 volumes 实现数据持久化 (可选) 💾
# volumes:
# - ./slave2-data:/data
# - ./slave2-redis.conf:/usr/local/etc/redis/redis.conf
# command: redis-server /usr/local/etc/redis/redis.conf --slaveof redis-master 6379
networks:
redis-net:
driver: bridge # 创建一个桥接网络供容器间通信
配置说明:
services: 定义了三个服务(容器):redis-master,redis-slave1,redis-slave2。image: redis:latest: 指定使用最新的官方 Redis 镜像。建议在生产环境中使用具体的版本号(如redis:7.2)。container_name: 为容器指定一个易于识别的名称。ports: 将容器的 6379 端口映射到宿主机的不同端口。redis-master映射到 6379,redis-slave1映射到 6380,redis-slave2映射到 6381。这样你可以在宿主机上通过不同端口访问它们。networks: - redis-net: 将所有容器连接到名为redis-net的自定义 Docker 网络。这使得容器可以通过容器名称(redis-master,redis-slave1,redis-slave2)相互通信。command: redis-server --slaveof redis-master 6379🔑: 这是关键配置。它告诉redis-slave1和redis-slave2容器启动时,连接到名为redis-master的容器的 6379 端口,并成为它的从节点。depends_on: - redis-master: 确保从节点容器在主节点容器启动之后再启动。networks: redis-net: driver: bridge: 定义了一个名为redis-net的自定义桥接网络。volumes(注释掉的部分) 💾: 如果需要数据持久化(即使容器停止或删除,数据也不会丢失),取消这些行的注释。./master-data:/data:将宿主机当前目录下的master-data文件夹挂载到redis-master容器内的/data目录(Redis 默认数据存储目录)。你需要手动创建master-data,slave1-data,slave2-data目录。./master-redis.conf:/usr/local/etc/redis/redis.conf:如果你需要更复杂的 Redis 配置(如设置密码requirepass和masterauth,修改 RDB/AOF 配置等),可以创建一个redis.conf文件,并将其挂载到容器内。如果挂载了自定义配置文件,通常需要修改command来指定加载该配置文件。
🚀 启动所有 Redis
在 redis-cluster 目录下(包含 docker-compose.yml 文件的目录),运行以下命令:
# 启动容器并在后台运行
docker compose up -d
# 如果你的 docker compose 不是插件形式,可能是 docker-compose up -d
Docker Compose 会根据 `docker-compose.yml` 文件创建并启动三个 Redis 容器。`-d` 参数表示在后台(detached mode)运行。
🔍 验证主从状态
-
查看容器状态:
docker compose ps # 或者 docker ps
你应该能看到
redis-master,redis-slave1,redis-slave2三个容器正在运行 (State 为Up)。✅ -
检查主节点信息:
连接到主节点容器并查看复制信息。docker exec -it redis-master redis-cli进入
redis-cli后,输入:INFO replication
在输出中查找:
role:master✅:确认它是主节点。connected_slaves:2✅:确认有两个从节点连接。- 下面会列出两个 slave 的信息(IP、端口、状态等)。
-
检查从节点信息:
连接到任意一个从节点容器(例如redis-slave1)并查看复制信息。docker exec -it redis-slave1 redis-cli进入
redis-cli后,输入:INFO replication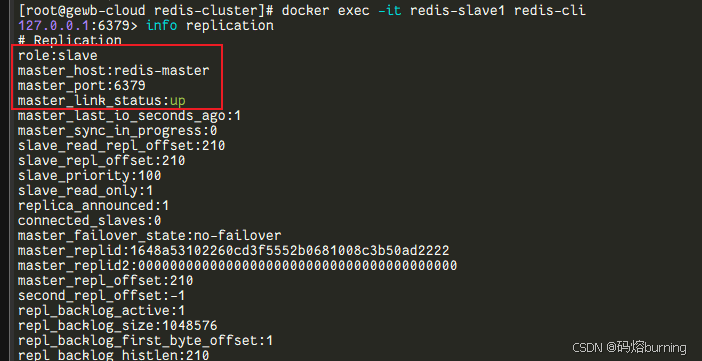
在输出中查找:
role:slave✅:确认它是从节点。master_host:redis-master✅:确认主节点的主机名正确。master_port:6379✅:确认主节点的端口正确。master_link_status:up✅:确认与主节点的连接正常。
-
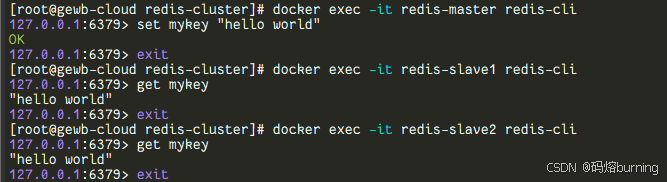
➡️ 测试数据同步:
- 在主节点 (
redis-master) 的redis-cli中设置一个键值对:
应该返回SET mykey "hello world from master! 👋"OK。 - 在从节点 (
redis-slave1或redis-slave2) 的redis-cli中获取这个键的值:
应该能成功返回GET mykey"hello world from master! 👋"。这表明数据已从主节点同步到从节点 🎉。
- 在主节点 (
🛑 停止和清理 (如果需要):
如果你想停止并删除这些容器、网络,可以在 redis-cluster 目录下运行:
docker compose down
如果使用了挂载卷(volumes)并且想删除数据,可以添加 -v 选项:
docker compose down -v # 这个会把数据也删掉哦,请小心!
💡 重要提示和后续改进
- 数据持久化: 上面的示例默认没有启用持久化。对于生产环境,强烈建议通过挂载
volumes💾 来持久化/data目录,并可能需要配置 RDB 快照或 AOF 日志。 - 安全性: 示例没有设置密码 🔑。在生产环境中,务必为主节点设置
requirepass,并为从节点设置masterauth来连接到需要密码的主节点。这需要在自定义的redis.conf文件中配置,并通过volumes挂载进去,同时修改command以加载配置文件。 - 高可用: 这个设置只是主从复制,如果主节点宕机 💥,从节点不会自动提升为主节点。你需要手动处理故障转移,或者使用 Redis Sentinel(哨兵模式)或 Redis Cluster(集群模式)来实现自动故障转移和更高可用性。
- 资源限制: 在生产环境中,你可能需要为每个 Redis 容器设置 CPU 和内存限制 ⚖️,以防止它们消耗过多服务器资源。这可以在
docker-compose.yml文件的服务定义中通过deploy->resources->limits来配置。 - 监控: 部署后,需要建立监控机制 📊 来跟踪 Redis 实例的健康状况、内存使用、连接数和复制延迟等。
这样,你就成功地在一台 Linux 服务器上使用 Docker 搭建了一个 Redis 一主二从的复制结构啦!👍
三、 主从复制的数据同步原理是什么?
这个过程分为两个阶段:
-
a. 首次连接/全量复制 (小弟刚入门,大哥先给一本完整的秘籍 📖)
- 握手 🤝:小弟启动后,会主动向大哥发送一个
PSYNC(或者旧版的SYNC) 命令,告诉大哥:“大哥,我是新来的(或者断线重连的),我想跟你混,告诉我你的ID和现在的数据进度(偏移量)”。 - 大哥准备:大哥收到后,会执行一个
BGSAVE命令,在后台生成一个当前数据的快照(RDB文件)📸。这就像大哥把目前所有的武功秘籍复印一份。 - 缓冲命令 ⏳:在生成快照期间,大哥如果又收到了新的写命令(比如又学了新招式),会先把这些新命令缓存起来,不立刻发给这个正在等待快照的小弟。
- 发送快照 📤📁:大哥把生成的RDB快照文件发给小弟。
- 小弟加载 📥⏳:小弟收到快照文件后,会清空自己原来的旧数据(如果有的话),然后加载这个RDB文件,这样小弟的数据就和大哥生成快照那个时间点完全一致了。
- 发送缓冲命令 📨:大哥把在生成快照期间缓存起来的新命令,再发给小弟。小弟执行这些命令,追上大哥最新的状态。
- 完成 👍✅:至此,小弟的数据就和大哥完全同步了。这个过程叫“全量复制”。
- 握手 🤝:小弟启动后,会主动向大哥发送一个
-
b. 持续同步/增量复制 (入门后,大哥有新招式随时教 🏃♂️💨)
- 全量复制完成后,大哥每次执行一个“写”命令(如
SET,DEL,INCR等),都会把这个命令实时地、异步地发送给所有跟着他的小弟 📡。 - 小弟收到命令后,就在自己这边也执行一遍同样的命令,从而保持和大哥的数据一致。
- 这个过程是持续不断的,只要主从连接正常,大哥一有动作,小弟马上跟着学。
- 全量复制完成后,大哥每次执行一个“写”命令(如
-
断线重连优化 (小弟临时掉线了怎么办?🔗❓)
- Redis 2.8 版本之后引入了
PSYNC命令,支持部分重同步(Partial Resynchronization)。 - 大哥会维护一个“复制积压缓冲区”(Replication Backlog),这是一个固定大小的队列,记录了最近发送给小弟们的命令。
- 如果小弟只是短暂断线(比如网络抖动),重连时,小弟会告诉大哥自己断线前的“进度”(复制偏移量 offset)。
- 大哥检查这个进度,如果在自己的积压缓冲区里还能找到小弟断线后产生的所有新命令,那么大哥就只把这些增量的命令发给小弟 🩹➡️。小弟执行完就追上了。这样就避免了代价很高的全量复制。
- 如果小弟断线时间太长,或者积压缓冲区太小,大哥找不到小弟需要的增量信息了,那就只能辛苦一点 😥,再来一次全量复制 🏋️♀️。
- Redis 2.8 版本之后引入了
四、 主从复制的优缺点是什么?
-
优点 (好处 👍):
- 高可用性基础 🛡️:是Redis Sentinel(哨兵)和 Redis Cluster(集群)实现自动故障转移和高可用的基石。
- 读扩展性好 📈:可以通过增加Slave节点来线性地扩展系统的读性能。
- 数据冗余 📑:提供了数据的热备份。
-
缺点 (不足之处 👎):
- 写能力无扩展 ✍️➡️:所有写操作都必须经过Master,Master的写压力无法通过增加Slave来分摊。单点写性能瓶颈 🏺。
- 主节点故障问题 (若无哨兵等机制) ⚠️:如果Master宕机,需要手动将一个Slave提升为新的Master,并且通知应用切换连接,这期间服务会中断。需要配合哨兵或集群才能实现自动故障恢复。
- 数据一致性问题 ⏰:主从复制是异步的。命令从Master发送到Slave需要时间,Slave执行也需要时间。所以在极短的时间窗口内,Slave的数据可能稍微落后于Master(比如Master刚写完一个值,还没来得及传给Slave,这时去Slave读可能读到旧值)。这叫最终一致性,对于要求强一致性的场景可能有影响。
- 全量复制开销 🏋️♀️💸:首次连接或断线重连时间过长导致的全量复制,会对Master造成CPU、内存和网络带宽的压力,尤其是在数据量大的情况下。
五、 总结
Redis主从复制就是找一堆小弟(Slaves)跟着大哥(Master)学习。好处是大哥倒了有人顶上(高可用备份 💪),人多力量大能帮大哥分担读数据的活儿(读写分离/负载均衡 🤝🚀)。搭建起来就是在小弟的配置文件里写上大哥的地址和密码 ⚙️🔑。同步原理是,新来的小弟先拿一份大哥的完整笔记(全量复制 📸➡️📖),之后大哥有新动作就实时通知小弟们跟着做(增量复制 🏃♂️💨)。缺点是写操作还得大哥一个人扛 ✍️➡️,大哥真挂了得有人手动扶小弟上位(除非有哨兵帮忙 ⚠️),而且小弟学东西总会慢半拍(数据有延迟 ⏰)。











![[ctfshow web入门] web18](https://i-blog.csdnimg.cn/direct/fcea7af616dc45eea1f28a432f24b51c.png)