引入依赖
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
编写函数
注意必须要继承GenericUDF 类
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class SimilarEval extends GenericUDF {
/**
* 初始化方法,一般用来校验数据参数个数,返回值是int类型的PrimitiveObjectInspectorFactory
* @param objectInspectors
* @return
* @throws UDFArgumentException
*/
@Override
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
if (objectInspectors.length != 2){
//判断参数个数是否为2,抛出异常
throw new UDFArgumentException("参数个数必须为2,请重新输入");
}
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
/**
* 业务逻辑处理方法
* @param
* @return
* @throws HiveException
*/
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
//获取输入的参数
String targetStr = deferredObjects[0].get().toString();
String sourceStr = deferredObjects[1].get().toString();
//判断输入数据是否为null,如果为null,返回0
if (targetStr == null || sourceStr == null){
return 0;
}else{
//输入数据不为null,进行业务处理
int tar_len = targetStr.length();
int b = 0;
for (int i = 0; i < tar_len; i++) {
String tmpChar = targetStr.substring(i,i+1);
int a = sourceStr.indexOf(tmpChar);
if (a >= 0){
a+=1;
b = b +1;
} else{
a = 0;
}
}
int result = (int) Math.round((b*100)/(double)tar_len);
return result;
}
}
/**
*
* @param strings
* @return
*/
@Override
public String getDisplayString(String[] strings) {
return "";
}
}
项目结构
打成jar包,并上传到linux服务器,将jar包添加到hive指定路径
# 将jar包添加到hive指定路径
add jar hdfs:/stq/ltdq/jars/SimilarEval-1.0-SNAPSHOT.jar;
# 创建函数
create function similar_eval as 'SimilarEval';
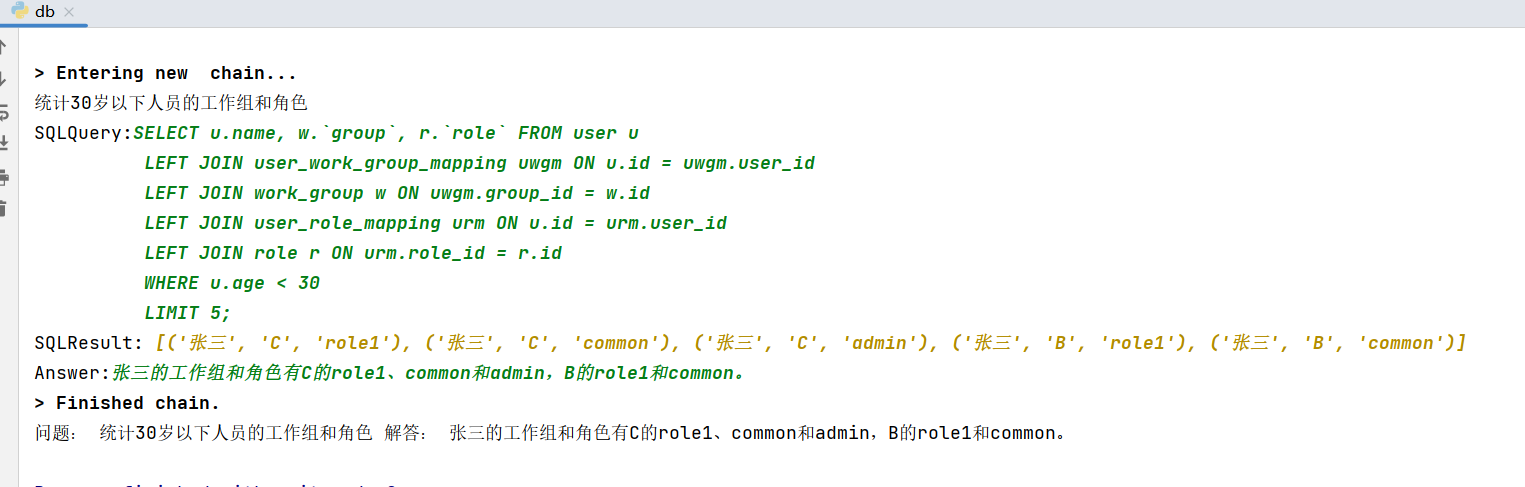
使用效果