最近在百度ai上跟了个“深度学习7日打卡营”的课程,目前看到人脸关键点检测章节,地址如下:飞桨AI Studio - 人工智能学习与实训社区 (baidu.com)
老师们讲解的很好,但是对于我这样的白菜来说,有些细节还是感觉略过去了,真正开始动手的时候,又感觉无从下手了。其实自从有了深度学习框架后,深度学习的门槛已经很低了,但是也不是没有,尤其是对于第一次接触的人来说,相关的概念和牵扯的知识还是挺多的,对我来说python基本也算刚开始用,机器学习深度学习啥的都是刚接触,基础课程对我来说也不算太基础,只是有一点代码的功底,一边用一边学吧。
进入正题,一般深度学习hello world级别的应用,数据集都是框架提供好的,用api直接调用就可以下载使用,但是对于实际工作中用到的数据集一般都是通过各种渠道获取的,里面的数据有没有问题,标注有没有错误,对于训练的影响极大,我个人感觉首先应该看下数据了解几个问题:
1、数据集的目录结构;
2、包含多少图片,图片的格式,图片的尺寸等信息;
3、标签文件的内容,格式,大概组织结构;
4、标签里描述的图片和实际图片是否对应,随机选一些图片看看标签和图片是否对应;
5、标签数据中如果有坐标,在数据集拓展时,尤其是剪裁缩放时考虑标签坐标的变化;
有了问题,就写点代码,看看答案:
import os
from PIL import Image
import numpy as np
import pandas as pd
import random
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
class DataViewing(object):
def __init__(self):
self.files = None # 实际目录下的文件列表
self.label_data = None # 标签数据
self.config_files = None # 标签配置文件中的文件列表
def show_files(self, path):
'''看一下图片文件夹下图片的大概信息'''
self.files = os.listdir(path) # 获取目录下所有文件
print("目录下文件数量:%d " % (len(self.files)))
file_types = []
file_shapes = []
for file in self.files:
ext = file.split(".")[-1] # 获取文件拓展名
img = np.array(Image.open(path+file)) # 读取图片并转化为ndarray格式
h, w, c = img.shape # 获取图片长宽高
shape = [h, w, c] # 存入list
if ext not in file_types: # 收集拓展名
file_types.append(ext)
if shape not in file_shapes: # 收集图片形状
file_shapes.append(shape)
print("目录下文件类型有:", file_types)
print("图片形状有:", file_shapes)
# python的列表类型转换为numpy的ndarray类型方便实用numpy的方法获取最大最小值
file_shapes = np.array(file_shapes)
print(file_shapes.shape) # 打印一下转换后的数据形状,确认形状是否正确
print("图片形状有:%d 种" % (file_shapes.shape[0]))
max = file_shapes.max(axis=0) # 按列统计最大值
min = file_shapes.min(axis=0) # 按列统计最小值
avg = file_shapes.sum(axis=0)/file_shapes.shape[0] # 均值
print("图片最大高度:", max[0])
print("图片最大宽度:", max[1])
print("图片最大通道数:", max[2])
print("图片最小通道数:", min[2])
print("图片平均大小:", avg)
self.show_some_pics(path, 3)
def show_some_pics(self, path, num):
''' 随便找几张图片展示一下'''
samples = random.sample(self.files, num) #随机获取指定数量的元素
for file in samples:
img = np.array(Image.open(path+file))
plt.figure()
plt.title(file)
plt.imshow(img)
plt.show()
def show_csv(self, file_path):
'''看下标签配置文件的大概信息'''
# 申明式条件判断,挺好用的
assert os.path.exists(file_path), '文件不存在'
data = pd.read_csv(file_path) # pandas方式读取csv文件,比较便捷
print("标签数据形状:", data.shape)
# 获取前5行数据看看,jupyter命令方式执行data.head(5)可以直接显示美观的表格数据
head5 = data.head(5)
print(head5)
self.label_data = data.values # 除了标题的数据,返回的还是dataframe
def label_data_summary(self):
'''看看配置文件中的文件信息和实际图片目录中的能不能对应上,
顺便获取一下标签数据的均值和标准差
'''
# 第一列是文件名 后面的列是标签数据
self.config_files, self.label_data = self.label_data[:,
0], self.label_data[:, 1:]
print(self.config_files[1])
print("配置文件中记录的文件数量:", self.config_files.shape)
print("目录下的文件数量:", len(self.files))
if self.config_files.shape[0] == len(self.files):
flag = True
for file_name in self.config_files:
if file_name not in self.files:
flag = False
print(file_name, "不存在")
if flag:
print("配置文件中的文件和实际文件完全对应")
else:
print("配置文件中的文件数量和实际目录下的文件数量不一样")
print(self.label_data.shape)
mean = self.label_data.mean() # 计算均值
std = self.label_data.std() # 计算标准差
print("标签数据的均值为:", mean)
print("标签数据的标准差为:", std)
def show_some_pic_with_label(self, path, num):
'''随便取几张图,输出标签点看看'''
for i in range(num):
index = np.random.randint(0, len(self.config_files)) #随机取数组索引
file_name = self.config_files[index] #按随机索引获取文件名字
key_pts = self.label_data[index, :].astype('float') #按随机索引获取标签数据
plt.figure(figsize=(5, 5))
print(os.path.join(path, file_name))
self.show_keypoints(Image.open(
os.path.join(path, file_name)), key_pts) #读取图片,和标签数据传参
plt.show() # 展示图像
def show_keypoints(self, image, key_pts):
'''展示带关键点的图像信息,传入的是图片的ndarray和关键信息nadrray'''
# plt.imshow(image.astype("uint8")) 有人转换了一下图片数组,变成无符号整型,我这里图片显示不出来
plt.imshow(np.array(image)) # 展示图片信息,直接转成adarray就能显示
#描点
for i in range(len(key_pts)//2, ):
plt.scatter(key_pts[i*2], key_pts[i*2+1], c='b', marker='.', s=20)
# 参数c --点的颜色
# marker --点的样式
# s --点的面积(大小)
dv = DataViewing()这个代码我反反复复调整了多次,基本能展示我需要的信息了。相关的注释我描述的基本算很细致,不懂的我都在网上查资料补充进去了。
首先看下训练集中的图片信息:
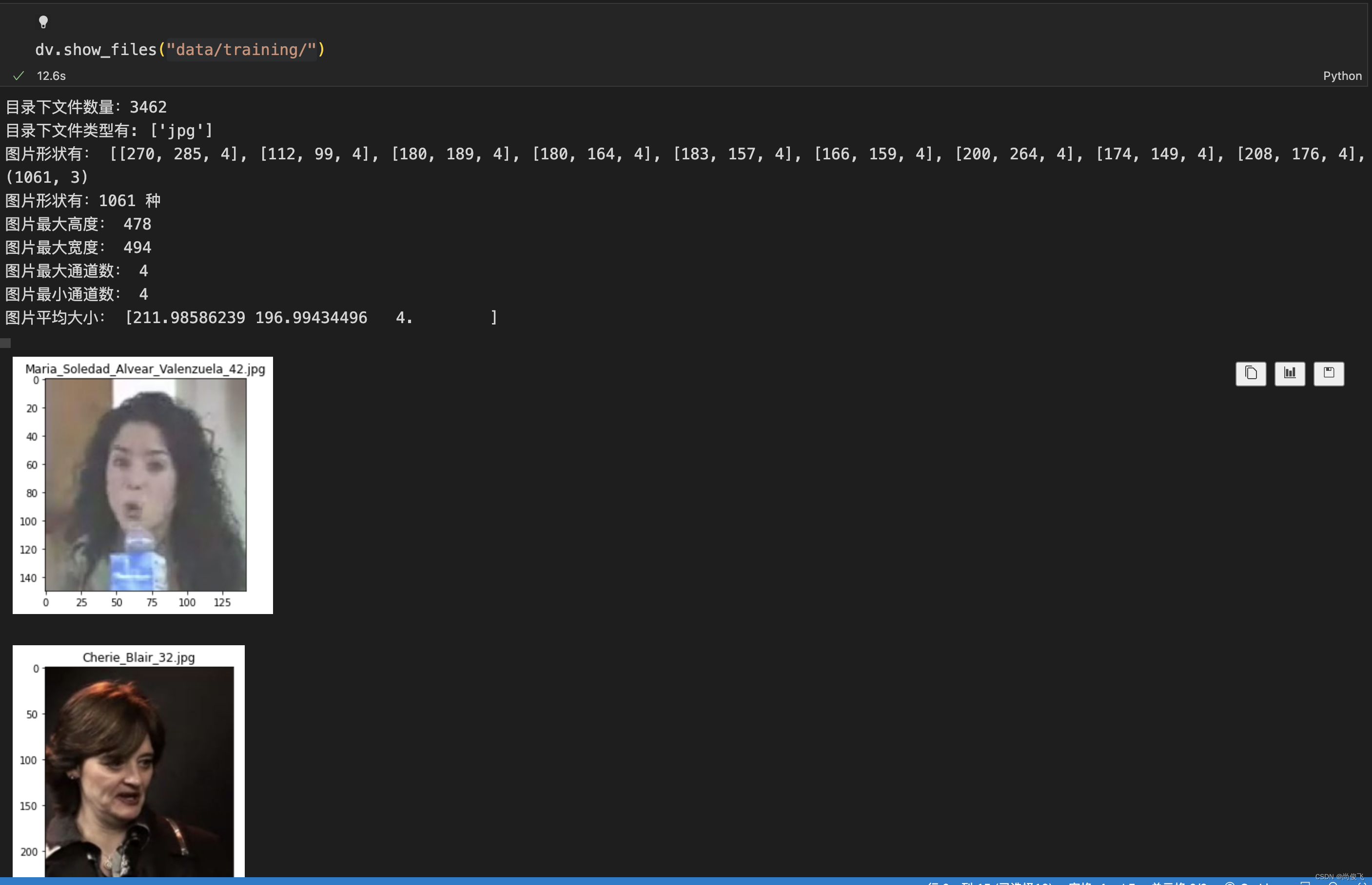
图片数量,拓展名,各种尺寸都有,图片有4个通道,训练一般用3通道的图片,这些在后面归一化时都要处理。
再看下标签文件信息:

这里我只显示了前面5行,有个标题行,基本就是个列索引,第一列是图片名字,后面是人脸关键点坐标信息,0-135就是68个坐标信息。
标签数据统计信息:

打标签的文件数量3462个,实际图片文件夹中有3462张图片,完全对应。顺便看了下标签数据的均值和标准差
随机抽几张图片,把标签坐标打到图片上看看对不对:
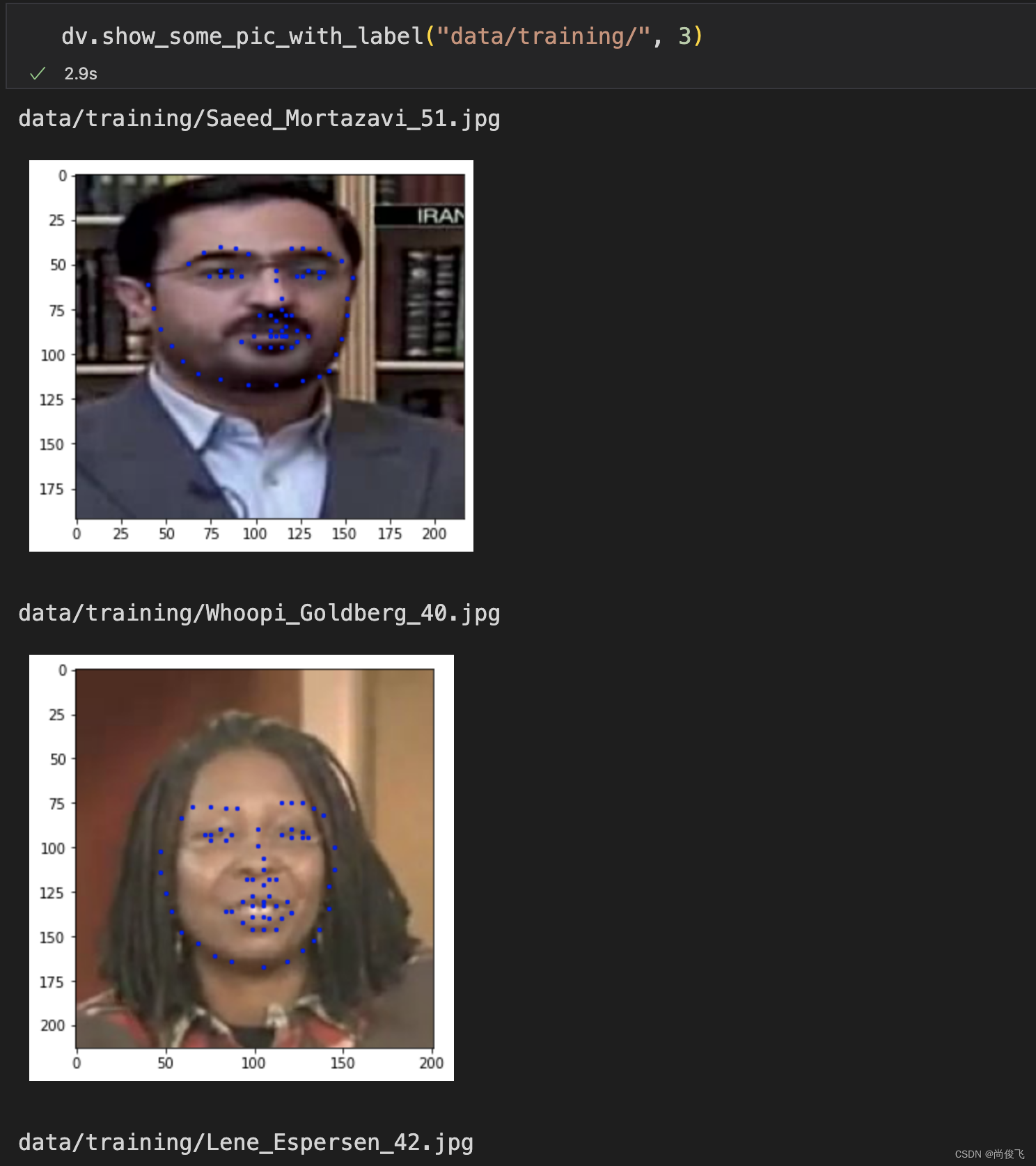
标签坐标和图片上的位置是对应的,没啥问题。
这样基本上就把数据集的一些基本情况了解清楚了,随着后面学习的深度,回头看需要补充什么信息,再来完善这个类。
ps:这个数据集就是7日打卡营人脸关键点检测项目的数据集,有兴趣的朋友可以点文章开头的连接,自己fork项目下载查看。