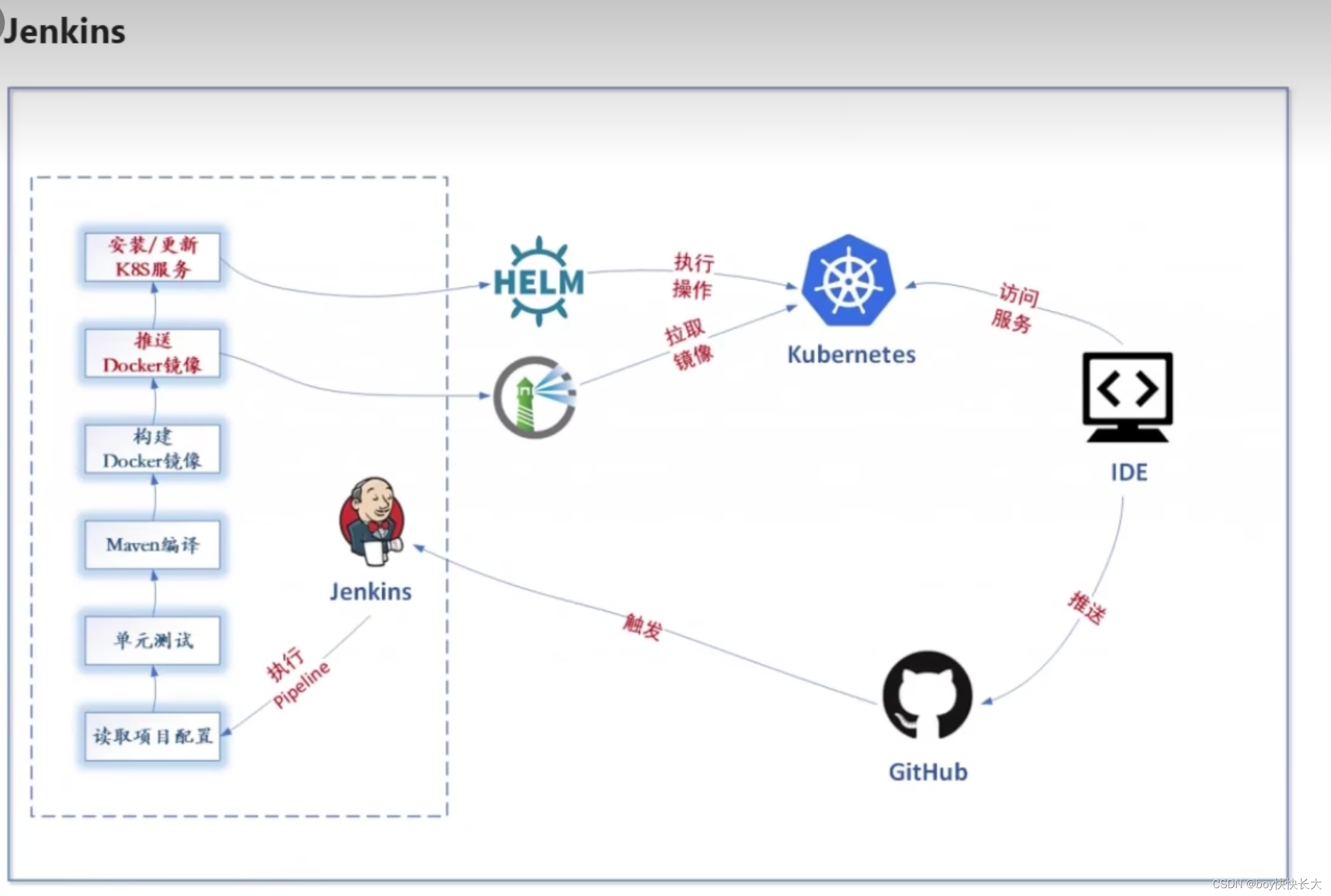
爬虫可以应用于各种应用场景,包括数据分析、市场研究、舆情监测、竞争报、价格比较、内容聚合等。对于需要大量数据的业务和研究领域,爬虫能够提供宝贵的支持。 爬虫可以按照设定的规则从多个网进行批量数据抓取,比人工手动方式更高效。量数据,并支持后续的数据分析和决策。

爬虫可以通过解析HTML和CSS来采集数据。下面是一些常用的方法:
1、HTML解析: 使用HTML解析库(如Beautiful Soup、lxml等),可以提取HTML文档中的特定元素和属性。你可以根据HTML的标签、类名、ID等定位所需的数据,并提取它们的文本内容或其他属性。
2、CSS选择器: 许多HTML解析库都支持使用类似CSS选择器的语法来选择和提取元素。你可以使用类似于jQuery的选择器语法,通过标签名、类名、ID、属性等对HTML进行更精确的选择。
3、XPath: XPath是一种用于在XML和HTML文档中定位元素的语言。它提供了一种灵活且强大的方式来定位元素,并提取相关的文属性。许多HTML解析库也支持XPath选择器。
4、CSS解析: CSS文件通常包含有关网页布局和样式的信息。通过解析CSS,你可以获取有关元素样式的信息,例如颜色、字体大小、边距等。对于需要定位和筛选具有特定样式的元素的情况,这非常有用。
使用以上方法,你可以根据要抓取的网页结构和规则,编写相应的解析代码,从HTML中提取出你所需的数据。请注意,在实际应用中,可能需要结合多种技术和方法来处理不同类型的页面和数据,以获得最佳结果。
当涉及编写爬虫代码时,需要考虑的因素很多包括目标网站的结构、数据提取规则以及你要采集和处理的具体信息。以下是一个基本的Python爬虫代码示例,用于从网页中提取标题和链接:
import requests
from bs4 import BeautifulSoup
# 发起HTTP请求
url = 'https://www.example.com' # 替换为目标网页的URL
response = requests.get(url)
# 解析HTML文档
soup = BeautifulSoup(response.text, 'html.parser')
# 提取标题和链接
titles = soup.find_all('h3') # 假设标题使用<h3>标签
links = soup.find_all('a') # 假设链接使用<a>标签
# 打印结果
for title in titles:
print('标题:', title.text)
for link links:
print('链接:', link['href'])
请注意,这只是一个简单的示例,实际的爬虫代码可能需要更复杂的数据提取和处理逻辑。在编写爬虫代码时,你还需要考虑头部信息、页面反爬机制、异常处理等方面的问题,并遵守法律和道德规范进行合法和负责任的数据采集。