文章目录
- End-to-End Object Detection with Transformers
- 摘要
- 本文方法
- 损失函数
- 代码实现
End-to-End Object Detection with Transformers
摘要
提出了一种将目标检测视为直接集预测问题的新方法。我们的方法简化了检测管道,有效地消除了许多手工设计的组件,如非最大抑制过程或锚生成,这些组件显式地编码了我们对任务的先验知识。新框架的主要组成部分,称为检测变压器或DETR,是一个基于集合的全局损失,通过二部匹配强制进行唯一预测,以及一个变压器编码器-解码器架构。给定一组固定的小学习对象查询,DETR对对象和全局图像上下文的关系进行推理,以直接并行输出最终的预测集。新模型在概念上很简单,不像许多其他现代探测器那样需要专门的库。
代码地址
本文方法
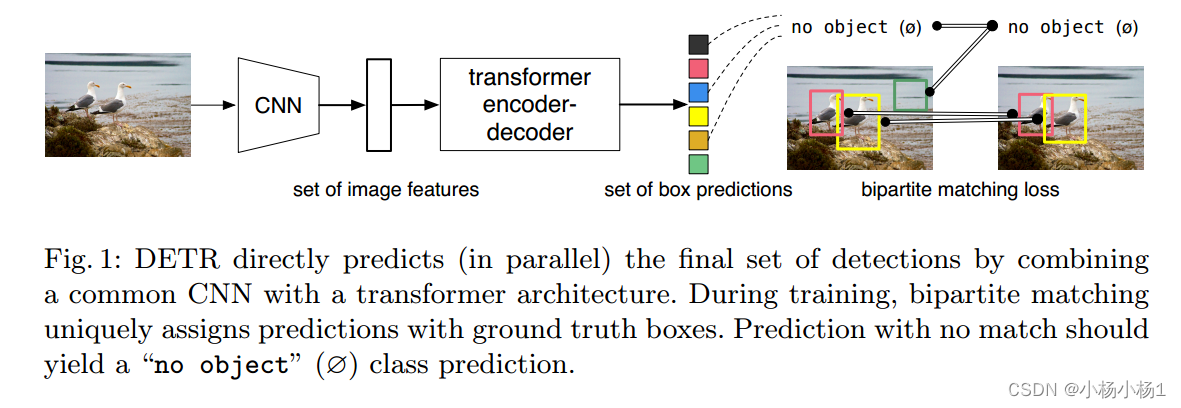
DETR通过将普通CNN与transformer架构相结合,直接预测(并行)最终检测集。
详细结构:
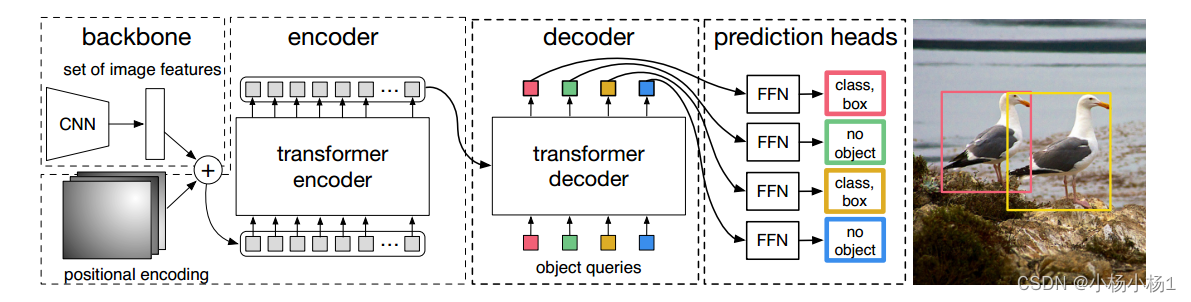
DETR使用传统的CNN主干来学习输入图像的二维表示。在将其传递到变压器编码器之前,模型将其扁平化并使用位置编码进行补充。然后,转换器解码器将少量固定数量的学习到的位置嵌入(我们称之为对象查询)作为输入,并额外关注编码器输出。我们将解码器的每个输出嵌入传递给一个共享前馈网络(FFN),该网络预测检测(类和边界框)或“无对象”类。
损失函数
在通过解码器的单次传递中,DETR推断出固定大小的N个预测集,其中N被设置为明显大于图像中典型对象的数量。训练的主要困难之一是根据真实情况对预测对象(类别、位置、大小)进行评分。我们的损失在预测对象和真实对象之间产生最优的二部匹配,然后优化对象特定的(边界盒)损失
让我们用y表示对象的基本真实集。假设N大于图像中对象的数量,我们也将y视为大小为N的集合,其中填充了?(无对象)。为了找到这两个集合之间的二部匹配,我们搜索代价最小的N个元素σ 2 SN的排列:
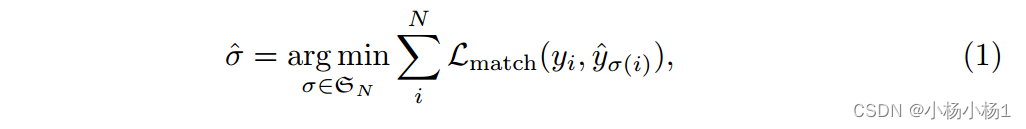
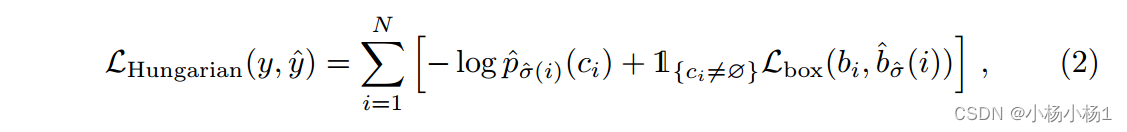
代码实现
第一步:提取CNN特征加上位置编码
features, pos = self.backbone(samples)
提取CNN特征的主要函数
backbone = getattr(torchvision.models, name)(
replace_stride_with_dilation=[False, False, dilation],
pretrained=is_main_process(), norm_layer=FrozenBatchNorm2d)
num_channels = 512 if name in ('resnet18', 'resnet34') else 2048
super().__init__(backbone, train_backbone, num_channels, return_interm_layers)
将得到的特征送入transformer
hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0]
transformer里面包含编码和解码,通过维度变换已经转为词嵌入格式了
bs, c, h, w = src.shape
src = src.flatten(2).permute(2, 0, 1)
pos_embed = pos_embed.flatten(2).permute(2, 0, 1)
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)
mask = mask.flatten(1)
tgt = torch.zeros_like(query_embed)
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)
hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, query_pos=query_embed)
return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)
编码器的代码:
src2 = self.norm1(src)
q = k = self.with_pos_embed(src2, pos)
src2 = self.self_attn(q, k, value=src2, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src2 = self.norm2(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src2))))
src = src + self.dropout2(src2)
return src
解码器的代码,返回的仍然是词嵌入格式
tgt2 = self.norm1(tgt)
q = k = self.with_pos_embed(tgt2, query_pos)
tgt2 = self.self_attn(q, k, value=tgt2, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt2 = self.norm2(tgt)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt2, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt2 = self.norm3(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2))))
tgt = tgt + self.dropout3(tgt2)
return tgt
然后全连接到类别数以及box的数量得到
outputs_class = {Tensor: (6, 2, 100, 11)}#类别的
outputs_coord = {Tensor: (6, 2, 100, 4)} #框的
最后增加一个辅助损失:
out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord)