string(字符串):最常见的用户是缓存用户信息,将用户信息结构体使用JSON序列化成字符串,然后将序列化后的字符串塞进Redis来缓存,然后取用户信息的过程会经历一次反序列化的过程。
Redis的字符串是动态字符串,可以修改,内部实现结构类似于Java的ArrayList,采用冗余分配空间的方式来减少内存的频繁分配。
list(列表):类似于Java的LinkedList,插入和删除很快,但是索引定位比较慢。list可以用作异步队列,将需要延后处理的任务结构体序列化成字符串塞进Redis中的列表,然后用另外一个线程来从这个列表中轮询数据进行处理。 右边进入左边弹出是队列,右边进入右边弹出是栈。
hash字典 : 相当于是Java中的HashMap,是无序的,底层是数组+链表实现
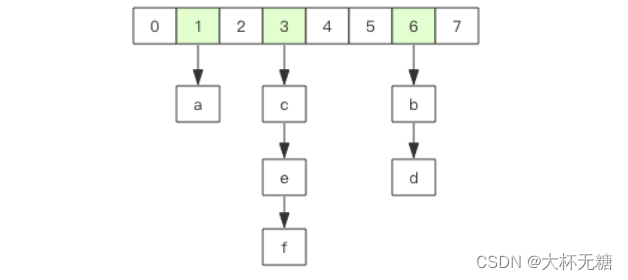
第一维hash 的数组位置碰撞时,就会将碰撞的元素使用链表串接起来。 (此处不是很理解,之前使用hash存储对象的时候,如果有两个相同的字段,会直接报错,不让存储,必须要给第二个重复的字段添加一些其他标识.....)
Hash也可以用来存储用户信息,不同于字符串一次性需要序列化整个用户对象,hash可以对用户结构中的每个字段单独存储,这样获取用户信息的时候可以部分获取,节省流量。 hash也有缺点,hash结构存储小高要高于单个字符串,具体使用哪个结构来存储对象信息,需要再三权衡。
set集合
相当于是Java中的HashSet ,它内部的键值对无序且唯一,内部其实是一个特殊的字典,字典的值全部都是null。 主要用来去重。
zset ,最为特色的数据结构,类似于Java的SortedSet和HashMap的结合体,一方面它是一个set,保证了内部value的唯一性,另一方面,他可以给每个value赋予一个score,这个代表value的排序权重,内部是通过一种叫做跳跃列表的数据结构来实现的。