scrapy介绍与安装
Scrapy 是开源和协作的一个基于 Twisted 实现的异步处理爬虫框架使用纯 Python 语言编写,被誉为爬虫界的Django,Scrapy 框架应用广泛,常用于数据采集、网络监测,以及自动化测试等
Scrapy安装
mac、linux系统
pip install scrapy在Windows中可能会出现报错等情况这是因为依赖没有安装需要先安装相关依赖
1.pip install scrapy # 报错安装下面依赖
2、pip3 install wheel #安装后,便支持通过wheel文件安装软件 xx.whl
3、pip3 install lxml
4、pip3 install pyopenssl
5、下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/pywin32/
6、下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
7、执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
8、pip3 install scrapy
创建Scrapy爬虫项目
创建爬虫项目:scrapy startproject 项目名
创建爬虫:scrapy genspider 名字 网址
启动爬虫:scrapy crawl 爬虫名字 --nolog在pycharm中运行
# 新建run.py
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', '爬虫名','--nolog'])Scrapy架构工作流程
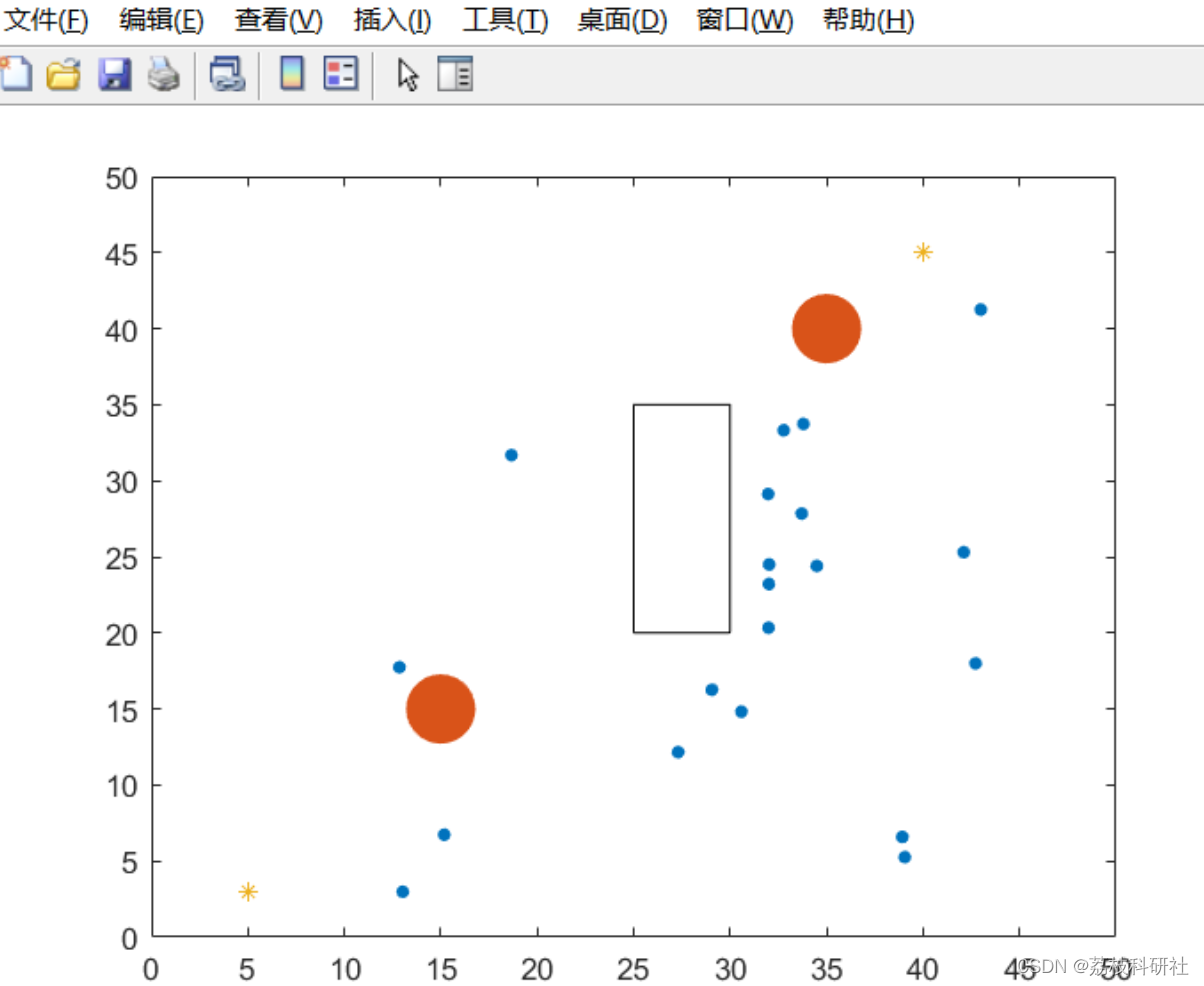
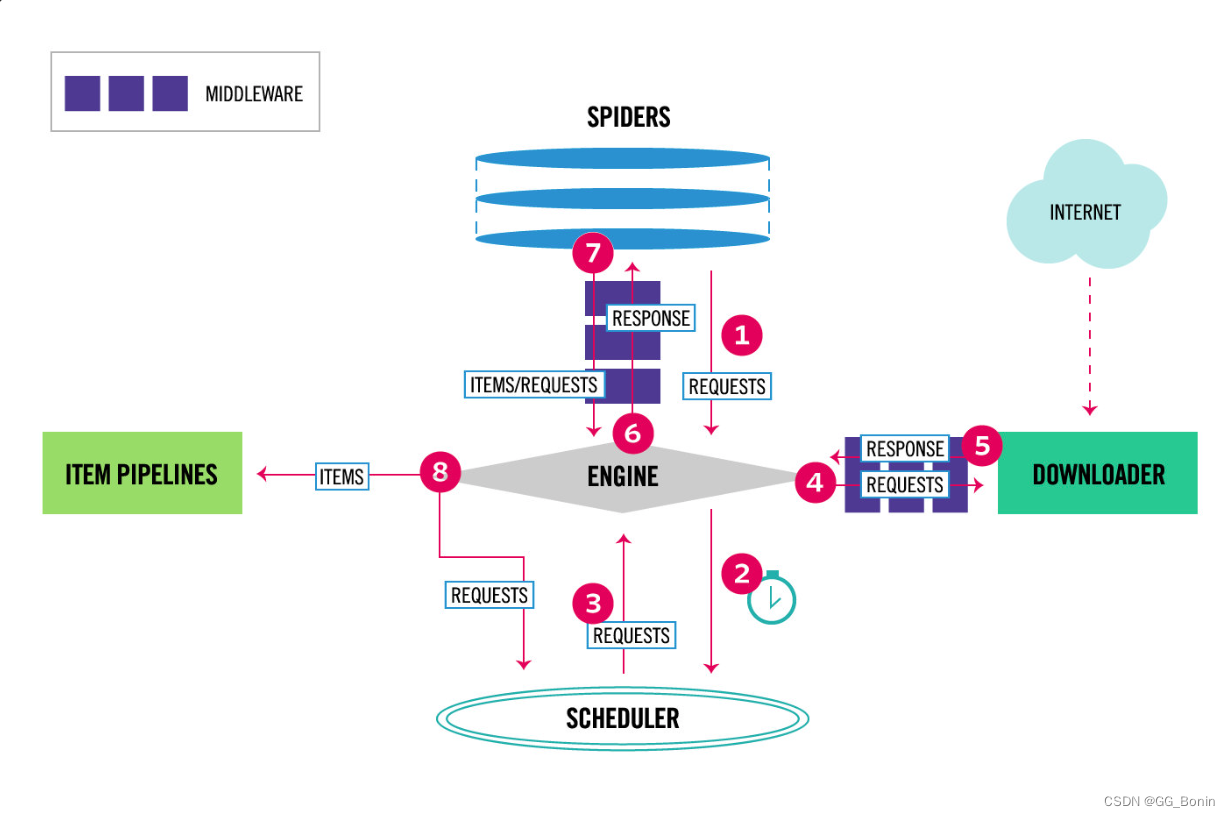
Scrapy 框架构成组件:
| 引擎(EGINE) | 引擎负责控制系统所有组件之间数据流,并在某些动作发生时触发事件。 |
| 调度器(SCHEDULER) | 用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回,可以想像成一个URL的优先级队列,由它来决定下一个抓取的网址是什么,同时去除重复网址 |
| 下载器(DOWLOADER) | 用于下载网页内容,并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的 |
| 爬虫(SPIDERS) | 开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求 |
| 项目管道(ITEM PIPLINES) | 在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作 |
| 下载中间件(Downloader Middlewares) | 位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response,可用该中间件做一下几件事:设置请求头,设置cookie,使用代理,集成selenium |
| 爬虫中间件(Spider Middlewares) | 位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests) |
Scrapy 工作流程示意图如下所示:
Scrapy相关配置
1.1settings基础配置
#1 是否遵循爬虫协议
ROBOTSTXT_OBEY = True
#2 LOG_LEVEL 日志级别
LOG_LEVEL='ERROR' # 报错如果不打印日志,在控制台看不到错误
# 3 USER_AGENT
USER_AGENT = ''
# 4 DEFAULT_REQUEST_HEADERS 默认请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
# 5 SPIDER_MIDDLEWARES 爬虫中间件
SPIDER_MIDDLEWARES = {
'cnblogs.middlewares.CnblogsSpiderMiddleware': 543,
}
# 6 DOWNLOADER_MIDDLEWARES 下载中间件
DOWNLOADER_MIDDLEWARES = {
'cnblogs.middlewares.CnblogsDownloaderMiddleware': 543,
}
# 7 ITEM_PIPELINES 持久化配置
ITEM_PIPELINES = {
'cnblogs.pipelines.CnblogsPipeline': 300,
}
#8 爬虫项目名字
BOT_NAME = 'onefirstscrapy'
#9 指定爬虫类的py文件的位置
SPIDER_MODULES = ['onefirstscrapy.spiders']
NEWSPIDER_MODULE = 'onefirstscrapy.spiders'1.2增加爬虫的爬取效率
#1 增加并发:默认16
默认scrapy开启的并发线程为32个,可以适当进行增加。在settings配置文件中修改
CONCURRENT_REQUESTS = 100
值为100,并发设置成了为100。
#2 降低日志级别:
在运行scrapy时,会有大量日志信息的输出,为了减少CPU的使用率。可以设置log输出信息为INFO或者ERROR即可。在配置文件中编写:
LOG_LEVEL = 'INFO'
# 3 禁止cookie:
如果不是真的需要cookie,则在scrapy爬取数据时可以禁止cookie从而减少CPU的使用率,提升爬取效率。在配置文件中编写:
COOKIES_ENABLED = False
# 4 禁止重试:
对失败的HTTP进行重新请求(重试)会减慢爬取速度,因此可以禁止重试。在配置文件中编写:
RETRY_ENABLED = False
# 5 减少下载超时:
如果对一个非常慢的链接进行爬取,减少下载超时可以能让卡住的链接快速被放弃,从而提升效率。在配置文件中进行编写:
DOWNLOAD_TIMEOUT = 10 超时时间为10s
持久化方案
一般常用基于管道的持久化存储scrapy框架中已经为我们专门集成好了高效、便捷的持久化操作功能,我们直接使用即可。要想使用scrapy的持久化操作功能
items.py:数据结构模板文件。定义数据属性。
pipelines.py:管道文件。接收数据(items),进行持久化操作。持久化流程:
-1 在items.py中写一个类[相当于写django的表模型],继承scrapy.Item
-2 在类中写属性,写字段,所有字段都是scrapy.Field类型title = scrapy.Field()-3 在爬虫中导入类,实例化得到对象,把要保存的数据放到对象中
item['title'] = title # 注意用[]取而不是. 解析类中 yield item-4 修改配置文件,指定pipline,数字表示优先级,越小越大
ITEM_PIPELINES = { 'crawl_cnblogs.pipelines.CrawlCnblogsPipeline': 300, }-5 写一个pipline:CrawlCnblogsPipeline
open_spider:数据初始化,打开文件,打开数据库链接
process_item:真正存储的地方
一定不要忘了return item,交给后续的pipline继续使用
close_spider:销毁资源,关闭文件,关闭数据库链接
爬虫和下载中间件
scrapy的所有中间件都写在middlewares.py中做一些拦截
有两种中间件:下载器中间件(Downloader Middleware)和爬虫中间件(Spider Middleware)
# 爬虫中间件
MyfirstscrapySpiderMiddleware
def process_spider_input(self, response, spider): # 进入爬虫会执行它
def process_spider_output(self, response, result, spider): #从爬虫出来会执行它
def process_spider_exception(self, response, exception, spider):#出了异常会执行
def process_start_requests(self, start_requests, spider):#第一次爬取执行
def spider_opened(self, spider): #爬虫开启执行
# 下载中间件
MyfirstscrapyDownloaderMiddleware
def process_request(self, request, spider): # request对象从引擎进入到下载器会执行
def process_response(self, request, response, spider):# response对象从下载器进入到引擎会执行
def process_exception(self, request, exception, spider):#出异常执行它
def spider_opened(self, spider): #爬虫开启执行它下载中间件的process_request,process_response返回值
# 下载中间件的process_request返回值:
- return None: 继续执行下面的中间件的process_request
- return a Response object: 不进入下载中间件了,直接返回给引擎,引擎把它通过6给爬虫
- return a Request object:不进入中间件了,直接返回给引擎,引擎把它放到调度器中
- raise IgnoreRequest: process_exception() 抛异常,会执行process_exception
# 下载中间件的process_response返回值:
- return a Response object:正常,会进入到引擎,引擎把它给爬虫
- return a Request object: 会进入到引擎,引擎把它放到调度器中,等待下次爬取
- raise IgnoreRequest 会执行process_exception