梳理逻辑
整个流程
- 准备好Paddle的环境
- 准备好训练样本
- 设计模型(定义模型)
- 训练模型
- 模型测试
1、准备好环境
#加载飞桨和相关类库
import paddle
from paddle.nn import Linear
import paddle.nn.functional as F
import os
import numpy as np
import matplotlib.pyplot as plt
开始之前,需要使用下面的命令安装 Python 的 matplotlib 库和 numpy 库,matplotlib 库用于可视化图片,numpy 库用于处理数据。
# 使用 pip 工具安装 matplotlib 和 numpy
! python3 -m pip install matplotlib numpy -i https://mirror.baidu.com/pypi/simple
2、训练样本
# 设置数据读取器,API自动读取MNIST数据训练集
train_dataset = paddle.vision.datasets.MNIST(mode='train')
我使用的是飞浆AI提供的样本,样本是一个像素28*28的图片。样本如下所示
#加载飞桨和相关类库
import paddle
from paddle.nn import Linear
import paddle.nn.functional as F
import os
import numpy as np
import matplotlib.pyplot as plt
train_dataset = paddle.vision.datasets.MNIST(mode='train')
# 取出第一个样本
train_data0 = np.array(train_dataset[0][0])
train_label_0 = np.array(train_dataset[0][1])
# 显示第一batch的第一个图像
import matplotlib.pyplot as plt
plt.figure("Image") # 图像窗口名称
plt.figure(figsize=(2,2))
plt.imshow(train_data0, cmap=plt.cm.binary)
plt.axis('on') # 关掉坐标轴为 off
plt.title('image') # 图像题目
plt.show()
print("图像数据形状和对应数据为:", train_data0.shape)
print("图像标签形状和对应数据为:", train_label_0.shape, train_label_0)
print("\n打印第一个batch的第一个图像,对应标签数字为{}".format(train_label_0))
运行结果如下

3、模型设计
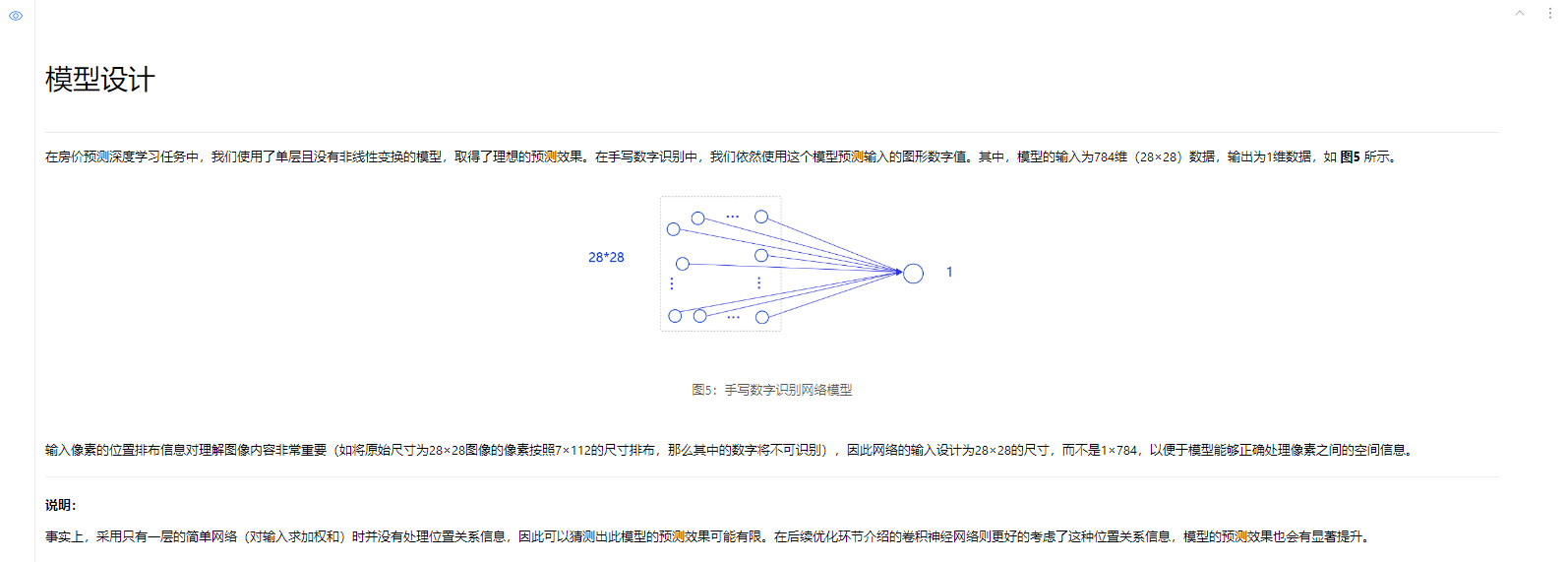
# 定义mnist数据识别网络结构,同房价预测网络
class MNIST(paddle.nn.Layer):
def __init__(self):
super(MNIST, self).__init__()
# 定义一层全连接层,输出维度是1
self.fc = paddle.nn.Linear(in_features=784, out_features=1)
# 定义网络结构的前向计算过程
def forward(self, inputs):
outputs = self.fc(inputs)
return outputs
4、训练配置
训练配置需要先生成模型实例(设为“训练”状态),再设置优化算法和学习率(使用随机梯度下降SGD,学习率设置为0.001),实现方法如下所示。
# 声明网络结构
model = MNIST()
def train(model):
# 启动训练模式
model.train()
# 加载训练集 batch_size 设为 16
train_loader = paddle.io.DataLoader(paddle.vision.datasets.MNIST(mode='train'),
batch_size=16,
shuffle=True)
# 定义优化器,使用随机梯度下降SGD优化器,学习率设置为0.001
opt = paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters())
5、训练过程
训练过程采用二层循环嵌套方式,训练完成后需要保存模型参数,以便后续使用。
- 内层循环:负责整个数据集的一次遍历,遍历数据集采用分批次(batch)方式。
- 外层循环:定义遍历数据集的次数,本次训练中外层循环10次,通过参数EPOCH_NUM设置。
图像归一化处理
图像处理为什么要归一化和如何归一化
答:其中一个原因是,对于网络模型训练等,是为了加速神经网络训练收敛,以及保证程序运行时收敛加快。
对图像归一化有2种处理方式:
(1) img/255.0
(2) img/127.5 - 1
第一种图像归一化方式,范围为[0, 1];
第二种图像归一化方式,范围为[-1, 1],这两种只是归一化范围不同.
一般归一化还会做减去均值除以方差的操作, 这种方式可以移除图像的平均亮度值(intensity)。
很多情况下我们对图像的亮度并不感兴趣,而更多地关注其内容,比如在目标识别任务中,图像的整体明亮程度并不会影响图像中存在的是什么物体。
此时,在每个样本上减去数据的统计平均值可以移除共同的部分,凸显个体差异。其效果如下所示: 去除了天空和其他纹理,凸显其我们想要的特征

# 图像归一化函数,将数据范围为[0, 255]的图像归一化到[0, 1]
def norm_img(img):
# 验证传入数据格式是否正确,img的shape为[batch_size, 28, 28]
assert len(img.shape) == 3
batch_size, img_h, img_w = img.shape[0], img.shape[1], img.shape[2]
# 归一化图像数据
img = img / 255
# 将图像形式reshape为[batch_size, 784]
img = paddle.reshape(img, [batch_size, img_h*img_w])
return img
训练样本保存模型参数
什么是模型参数?
模型参数,就是输入参数在模型中会通过参数的值不同程度的影响到输出结果。这个参数就是模型参数
import paddle
# 确保从paddle.vision.datasets.MNIST中加载的图像数据是np.ndarray类型
paddle.vision.set_image_backend('cv2')
# 声明网络结构
model = MNIST()
def train(model):
# 启动训练模式
model.train()
# 加载训练集 batch_size 设为 16
train_loader = paddle.io.DataLoader(paddle.vision.datasets.MNIST(mode='train'),
batch_size=16,
shuffle=True)
# 定义优化器,使用随机梯度下降SGD优化器,学习率设置为0.001
opt = paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters())
EPOCH_NUM = 10
for epoch in range(EPOCH_NUM):
for batch_id, data in enumerate(train_loader()):
images = norm_img(data[0]).astype('float32')
labels = data[1].astype('float32')
#前向计算的过程
predicts = model(images)
# 计算损失
loss = F.square_error_cost(predicts, labels)
avg_loss = paddle.mean(loss)
#每训练了1000批次的数据,打印下当前Loss的情况
if batch_id % 1000 == 0:
print("epoch_id: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, avg_loss.numpy()))
#后向传播,更新参数的过程
avg_loss.backward()
opt.step()
opt.clear_grad()
train(model)
paddle.save(model.state_dict(), './mnist.pdparams')
6、模型测试
模型测试的主要目的是验证训练好的模型是否能正确识别出数字,包括如下四步:
声明实例
加载模型:加载训练过程中保存的模型参数,
灌入数据:将测试样本传入模型,模型的状态设置为校验状态(eval),显式告诉框架我们接下来只会使用前向计算的流程,不会计算梯度和梯度反向传播。
获取预测结果,取整后作为预测标签输出。
在模型测试之前,需要先从'./work/example_0.png'文件中读取样例图片,并进行归一化处理。
# 导入图像读取第三方库
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
# 读取一张本地的样例图片,转变成模型输入的格式
def load_image(img_path):
# 从img_path中读取图像,并转为灰度图
im = Image.open(img_path).convert('L')
# print(np.array(im))
im = im.resize((28, 28), Image.ANTIALIAS)
im = np.array(im).reshape(1, -1).astype(np.float32)
# 图像归一化,保持和数据集的数据范围一致
im = 1 - im / 255
return im
# 定义预测过程
model = MNIST()
params_file_path = 'mnist.pdparams'
img_path = './work/example_0.jpg'
# 加载模型参数
param_dict = paddle.load(params_file_path)
model.load_dict(param_dict)
# 灌入数据
model.eval()
tensor_img = load_image(img_path)
result = model(paddle.to_tensor(tensor_img))
print('result',result)
# 预测输出取整,即为预测的数字,打印结果
print("本次预测的数字是", result.numpy().astype('int32'))
输出结果

实际输入的样本图片
在这里插入代码片从打印结果来看,模型预测出的数字是与实际输出的图片的数字不一致。这里只是验证了一个样本的情况,如果我们尝试更多的样本,可发现许多数字图片识别结果是错误的。因此完全复用房价预测的实验并不适用于手写数字识别任务!
接下来我们会对手写数字识别实验模型进行逐一改进,直到获得令人满意的结果。
7、完整的模型训练代码
7.1、Version 2.3 写法
import paddle
from paddle.nn import Linear
import paddle.nn.functional as F
import os
import numpy as np
import matplotlib.pyplot as plt
# 组件手写数字识别网络
# 定义mnist数据识别网络结构,同房价预测网络
class MNIST(paddle.nn.Layer):
def __init__(self):
super(MNIST, self).__init__()
# 定义一层全连接层,输出维度是1
self.fc = paddle.nn.Linear(in_features=784, out_features=1)
# 定义网络结构的前向计算过程
def forward(self, inputs):
outputs = self.fc(inputs)
return outputs
# 图像归一化函数,将数据范围为[0, 255]的图像归一化到[0, 1]
def norm_img(img):
# 验证传入数据格式是否正确,img的shape为[batch_size, 28, 28]
assert len(img.shape) == 3
batch_size, img_h, img_w = img.shape[0], img.shape[1], img.shape[2]
# 归一化图像数据
img = img / 255
# 将图像形式reshape为[batch_size, 784]
img = paddle.reshape(img, [batch_size, img_h*img_w])
return img
# 使用飞浆训练模型
import paddle
# 确保从paddle.vision.datasets.MNIST中加载的图像数据是np.ndarray类型
paddle.vision.set_image_backend('cv2')
# 声明网络结构
model = MNIST()
def train(model):
# 启动训练模式
model.train()
# 加载训练集 batch_size 设为 16
train_loader = paddle.io.DataLoader(paddle.vision.datasets.MNIST(mode='train'),
batch_size=16,
shuffle=True)
# 定义优化器,使用随机梯度下降SGD优化器,学习率设置为0.001
opt = paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters())
EPOCH_NUM = 10
for epoch in range(EPOCH_NUM):
for batch_id, data in enumerate(train_loader()):
images = norm_img(data[0]).astype('float32')
labels = data[1].astype('float32')
#前向计算的过程
predicts = model(images)
# 计算损失
loss = F.square_error_cost(predicts, labels)
avg_loss = paddle.mean(loss)
#每训练了1000批次的数据,打印下当前Loss的情况
if batch_id % 1000 == 0:
print("epoch_id: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, avg_loss.numpy()))
#后向传播,更新参数的过程
avg_loss.backward()
opt.step()
opt.clear_grad()
train(model)
# 保存模型训练的参数
paddle.save(model.state_dict(), './mnist.pdparams')
7.2、Version 2.4 写法
import paddle
import numpy as np
from paddle.vision.transforms import Normalize
transform = Normalize(mean=[127.5], std=[127.5], data_format='CHW')
# 下载数据集并初始化 DataSet
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
# 模型组网并初始化网络
lenet = paddle.vision.models.LeNet(num_classes=10)
model = paddle.Model(lenet)
# 模型训练的配置准备,准备损失函数,优化器和评价指标
model.prepare(paddle.optimizer.Adam(parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# 模型训练
model.fit(train_dataset, epochs=5, batch_size=64, verbose=1)
# 模型评估
model.evaluate(test_dataset, batch_size=64, verbose=1)
# 保存模型
model.save('./output/mnist')
8、模型预测代码
8.1、Version 2.3 写法
# 读取一张本地的样例图片,转变成模型输入的格式
def load_image(img_path):
# 从img_path中读取图像,并转为灰度图
im = Image.open(img_path).convert('L')
# print(np.array(im))
im = im.resize((28, 28), Image.ANTIALIAS)
im = np.array(im).reshape(1, -1).astype(np.float32)
# 图像归一化,保持和数据集的数据范围一致
im = 1 - im / 255
return im
# 定义预测过程
model = MNIST()
params_file_path = 'mnist.pdparams'
img_path = './work/example_0.jpg'
# 加载模型参数
param_dict = paddle.load(params_file_path)
model.load_dict(param_dict)
# 灌入数据
model.eval()
tensor_img = load_image(img_path)
result = model(paddle.to_tensor(tensor_img))
print('result',result)
# 预测输出取整,即为预测的数字,打印结果
print("本次预测的数字是", result.numpy().astype('int32'))
输出结果与第6步模型测试的结果一致。
8.2、Version 2.4 写法
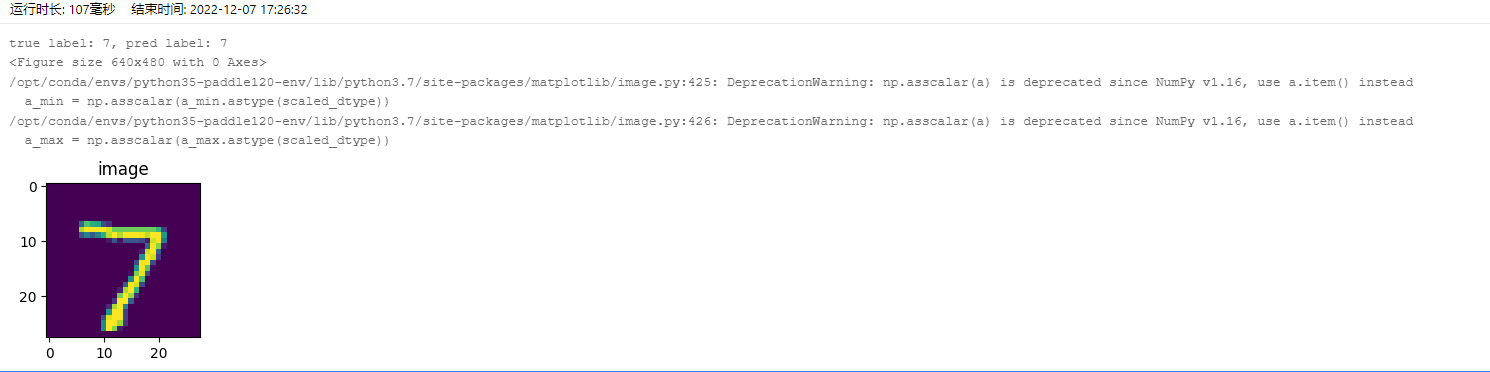
# 运行训练好的模型
model = paddle.Model(lenet)
# 加载模型
model.load('output/mnist')
# 从测试集中取出一张图片
img, label = test_dataset[0]
# 将图片shape从1*28*28变为1*1*28*28,增加一个batch维度,以匹配模型输入格式要求
img_batch = np.expand_dims(img.astype('float32'), axis=0)
# 执行推理并打印结果,此处predict_batch返回的是一个list,取出其中数据获得预测结果
out = model.predict_batch(img_batch)[0]
pred_label = out.argmax()
print('true label: {}, pred label: {}'.format(label[0], pred_label))
# 可视化图片
from matplotlib import pyplot as plt
plt.figure("Image") # 图像窗口名称
plt.figure(figsize=(2,2))
plt.imshow(img[0])
plt.axis('on') # 关掉坐标轴为 off
plt.title('image') # 图像题目
plt.show()