15. SparkOnYarn
15.1 Hadoop YARN回顾
15.1.1 YARN 的基本设计思想
将Hadoop 1.0中JobTracker拆分成两个独立的服务,一个全局的资源管理器ResourceManager(RM)和每个应用独有的ApplicationMaster(AM).其中RM负责整个系统的资源管理和分配,而AM负责单个的应用程序的管理
15.1.2 YARN的基本组成
- ResourceManager(RM)
全局的资源管理器,负责整个系统的资源管理和分配,由调度器(ResourceScheduler)和应用管理器(ApplicationS Manger,ASM)组成:
1 调度器(ResourceScheduler)
调度器根据容量,队列等限制条件,将系统中的资源分配给各个正在运行的应用程序.调度器不参与任何应用程序的具体工作,仅根据应用程序的资源需求进行资源分配.调度器是个可拔插的组件,用户可根据自己的需要设计新的调度器.
2 应用程序管理器(ASM)
应用程序管理器负责整个系统中所有应用程序,包括应用程序的提交,与调度器协商资源以启动ApplicationMaster(AM),监控AM运行状态并在失败时重启它
- ApplicationMaster(AM)
用户提交的每个应用程序均包含一个AM,主要功能包括:
1.与RM调度器协商以获取资源
2.将得到的资源进一步分配给内部的任务
3.与NodeManager(NM)通信,以启动\停止任务
4.监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务
- NodeManager(NM)
NM是每个节点上的资源和任务管理器.一方面,它会定时的向RM汇报本节点上的资源使用情况和各个Container的运行状态;另一方面,它接收并处理来自AM的Container启动\停止等请求Container
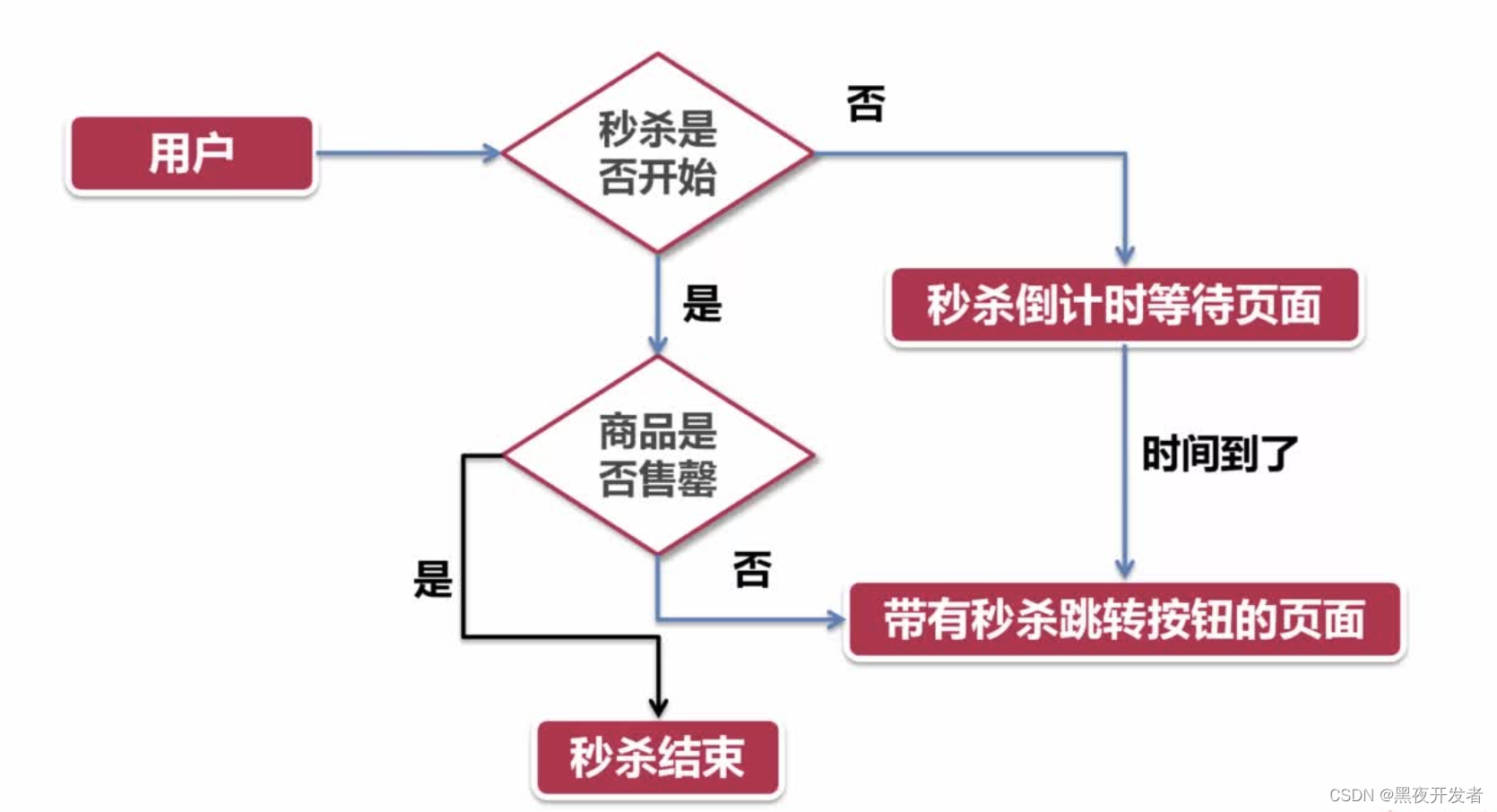
15.1.3 YARN的运行流程
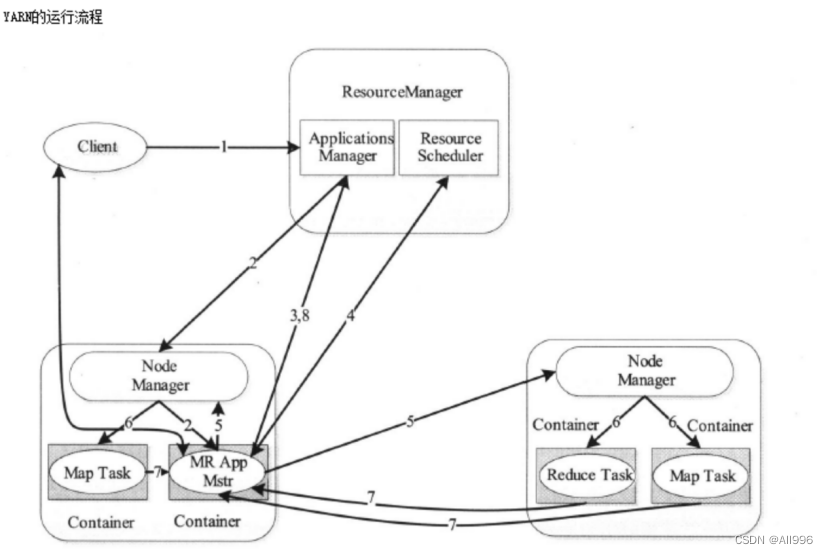
①用户向YARN提交应用程序,ResourceManager会返回一个applicationID,client将jar上传到HDFS
②RM(其中的调度器)为该应用程序分配第一个Container,(ASM)与对应的NM通信,要求它在这个Container中启动应用程序的AM
③AM首先向RM(其中的ASM)注册,这样用户可以直接通过RM查看应用程序的运行状况,然后AM会为各个任务申请资源,并监控任务的运行状态直至任务完成,运行结束.在任务未完成时,4-7步是会循环运行的
④AM采用轮询的方式通过RPC协议向RM(其中的调度器)申请和领取资源
⑤AM申请到资源后与对应NM通信,要求启动任务
⑥NM为任务设置好运行环境后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务.
⑦各个任务通过RPC协议向AM汇报自己的状态和进度,让AM随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务,在应用程序运行过程中,用户可随时通过RPC向AM查询应用程序的当前状况
⑧应用程序运行完成后,AM向RM注销并关闭自己
15.2 SparkOnYarn准备工作
- 需要在/etc/profile中配置HADOOP_CONF_DIR的目录,目的是为了让Spark找到core-site.xml、hdfs-site.xml和yarn-site.xml【让spark知道NameNode、ResourceManager】,不然会包如下错误:Exception in thread "main" java.lang.Exception: When running with master 'yarn' either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment.
修改/etc/profile
| Shell |
- 关闭内存资源检测(生产环境不用关)
修改yarn-site.xml
| XML |
参数说明:
yarn.nodemanager.pmem-check-enabled
是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
yarn.nodemanager.vmem-check-enabled
是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true
- 配置一个yarn的container可以使用多个vcores,因为capacity schedule使用的是DefaultResourceCalculator,那么DefaultResourceCalculator它在加载Container时其实仅仅只会考虑内存而不考虑vcores,默认vcore就是1。yarn 默认情况下,只根据内存调度资源,所以 spark on yarn 运行的时候,即使通过--executor-cores 指定 core 个数为 N,但是在 yarn 的资源管理页面上看到使用的 vcore 个数还是 1
修改capacity-scheduler.xml
| XML |
- 重新分发到yarn中的各个节点:
| Shell |
然后,启动hdfs和yarn集群。注意:要保证yarn集群的各个节点的时间是同步的。否则会报错
15.3 cluster模式
| Shell |
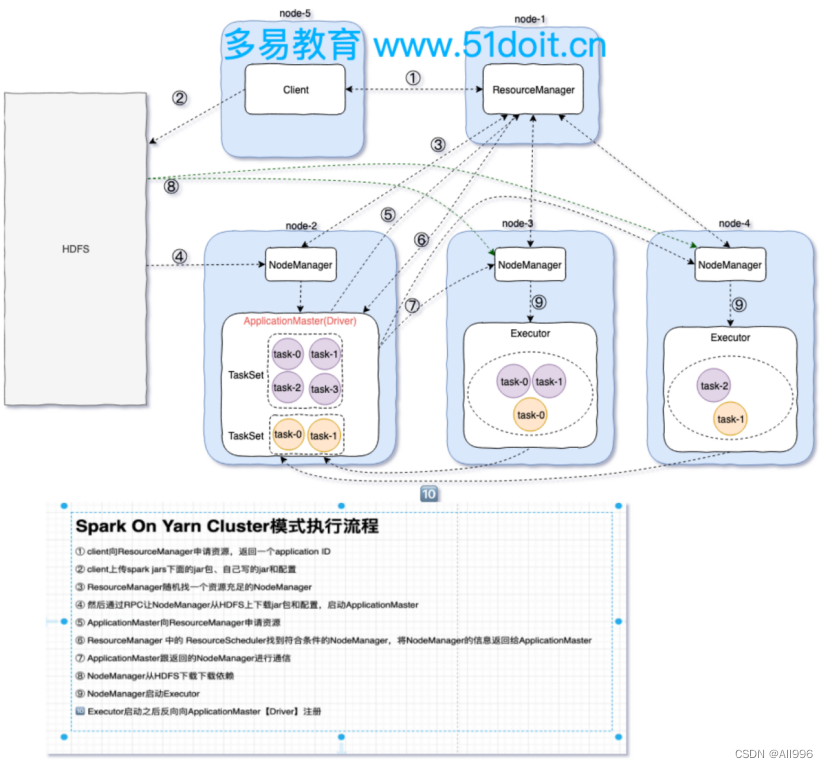
15.4 client模式
| Shell |
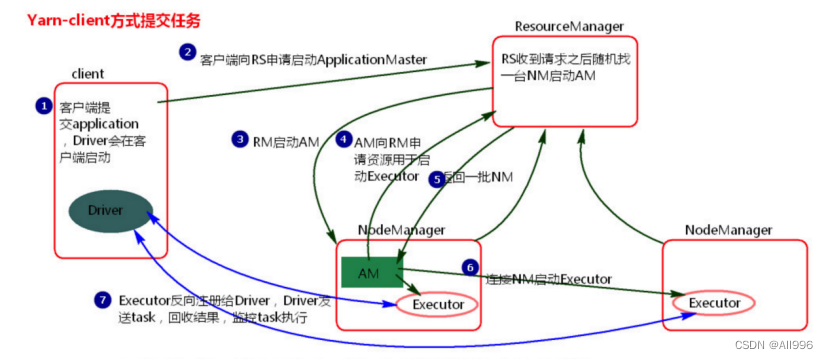
①客户端提交一个Application,在客户端启动一个Driver进程。
②Driver进程会向ResourceManager发送请求,启动ApplicationMaster的资源。
③ResourceManager收到请求,随机选择一台NodeManager,然后该NodeManager到HDFS下载jar包和配置,接着启动ApplicationMaster【ExecutorLuacher】。这里的NodeManager相当于Standalone中的Worker节点。
④ApplicationMaster启动后,会向ResourceManager请求一批container资源,用于启动Executor.
⑤ResourceManager会找到一批符合条件NodeManager返回给ApplicationMaster,用于启动Executor。
⑥ApplicationMaster会向NodeManager发送请求,NodeManager到HDFS下载jar包和配置,然后启动Executor。
⑦Executor启动后,会反向注册给Driver,Driver发送task到Executor,执行情况和结果返回给Driver端
15.5 资源分配
- YARN中可以虚拟VCORE,虚拟cpu核数,以后部署在物理机上,建议配置YARN的VCORES的使用等于物理机的逻辑核数,即物理机的核数和VCORES是一一对应的,在YARN中为spark分配任务,spark的cores跟逻辑核数一一对应,另一个逻辑和对应一个VCORE,一个VCORES对应一个spark cores【官方建议spark的cores是逻辑核的2到3倍】
- yarn中的资源分配,针对的是容器, 容器默认最少的资源是1024mb, 容器接受的资源,必须是最小资源的整数倍。
- spark中分配的资源由两部分组成,参数 + overhead,例如 --executor-memory 1g,overhead为
max(1024 * 0.1, 384),executor真正占用的资源应该是:1g + 384mb = 1408Mb
- 在yarn中,分配的资源最终都是分配给容器的1408 向上取整,例如--executor-memory 2g那么最终的内存为:2048 + Max(2048*0.1, 384)
16. Spark内存管理机制
16.1 概述
在执行Spark的应用程序时,Spark集群会启动Driver和Executor两种JVM进程,前者为主控进程,负责创建Spark上下文,提交Spark作业(Job),并将作业转化为计算任务(Task),在各个Executor进程间协调任务的调度,后者负责在工作节点上执行具体的计算任务,并将结果返回给Driver,同时为需要持久化的RDD提供存储功能。由于Driver的内存管理相对来说较为简单,本章节要对Executor的内存管理进行分析,下文中的Spark内存均特指Executor的内存。
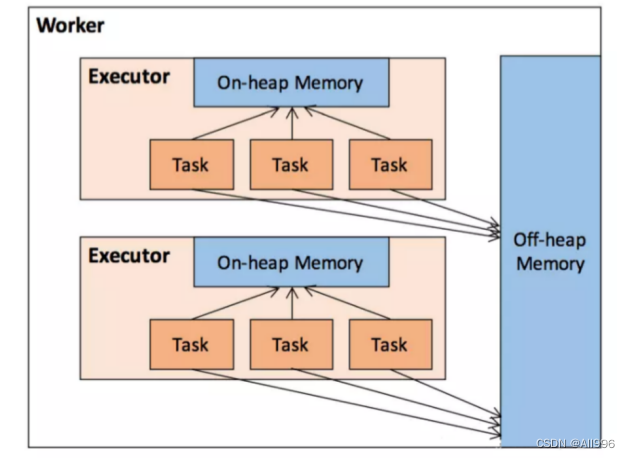
16.2 堆内内存和堆外内存
作为一个JVM进程,Executor的内存管理建立在JVM的内存管理之上,Spark对JVM的堆内(On-heap)空间进行了更为详细的分配,以充分利用内存。同时,Spark引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,进一步优化了内存的使用。
16.3 堆内内存
堆内内存的大小,由Spark应用程序启动时的–executor-memory或spark.executor.memory参数配置。Executor内运行的并发任务共享JVM堆内内存,这些任务在缓存RDD和广播(Broadcast)数据时占用的内存被规划为存储(Storage)内存,而这些任务在执行Shuffle时占用的内存被规划为执行(Execution)内存,剩余的部分不做特殊规划,那些Spark内部的对象实例,或者用户定义的Spark应用程序中的对象实例,均占用剩余的空间。不同的管理模式下,这三部分占用的空间大小各不相同(下面第2小节介绍)。
16.3.1 堆内内存的申请与释放
Spark对堆内内存的管理是一种逻辑上的“规划式”的管理,因为对象实例占用内存的申请和释放都由JVM完成,Spark只能在申请后和释放前记录这些内存:
- 申请内存
Spark在代码中new一个对象实例
JVM从堆内内存分配空间,创建对象并返回对象引用
Spark保存该对象的引用,记录该对象占用的内存
- 释放内存
Spark记录该对象释放的内存,删除该对象的引用
等待JVM的垃圾回收机制释放该对象占用的堆内内存
- 堆内内存优缺点分析
堆内内存采用JVM来进行管理。而JVM的对象可以以序列化的方式存储,序列化的过程是将对象转换为二进制字节流,本质上可以理解为将非连续空间的链式存储转化为连续空间或块存储,在访问时则需要进行序列化的逆过程——反序列化,将字节流转化为对象,序列化的方式可以节省存储空间,但增加了存储和读取时候的计算开销。
对于Spark中序列化的对象,由于是字节流的形式,其占用的内存大小可直接计算。
对于Spark中非序列化的对象,其占用的内存是通过周期性地采样近似估算而得,即并不是每次新增的数据项都会计算一次占用的内存大小。这种方法:
- 降低了时间开销但是有可能误差较大,导致某一时刻的实际内存有可能远远超出预期;此外,在被Spark标记为释放的对象实例,很有可能在实际上并没有被JVM回收,导致实际可用的内存小于Spark记录的可用内存。所以Spark并不能准确记录实际可用的堆内内存,从而也就无法完全避免内存溢出(OOM, Out of Memory)的异常。
- 虽然不能精准控制堆内内存的申请和释放,但Spark通过对存储内存和执行内存各自独立的规划管理,可以决定是否要在存储内存里缓存新的RDD,以及是否为新的任务分配执行内存,在一定程度上可以提升内存的利用率,减少异常的出现。
16.3.2 堆内内存分区(静态方式,弃)
在静态内存管理机制下,存储内存、执行内存和其他内存三部分的大小在Spark应用程序运行期间是固定的,但用户可以在应用程序启动前进行配置,堆内内存的分配如图所示:
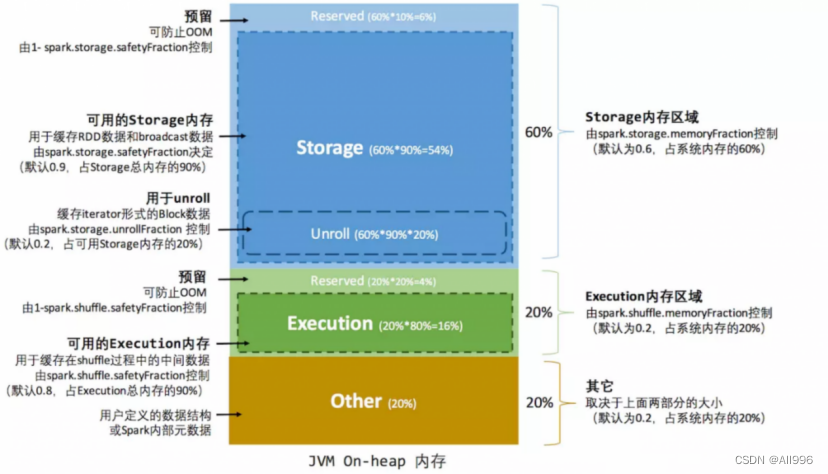
可以看到,可用的堆内内存的大小需要按照下面的方式计算:
可用的存储内存 = systemMaxMemory * spark.storage.memoryFraction * spark.storage.safetyFraction
可用的执行内存 = systemMaxMemory * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction
其中systemMaxMemory取决于当前JVM堆内内存的大小,最后可用的执行内存或者存储内存要在此基础上与各自的memoryFraction参数和safetyFraction参数相乘得出。上述计算公式中的两个safetyFraction参数,其意义在于在逻辑上预留出1-safetyFraction这么一块保险区域,降低因实际内存超出当前预设范围而导致OOM的风险(上文提到,对于非序列化对象的内存采样估算会产生误差)。值得注意的是,这个预留的保险区域仅仅是一种逻辑上的规划,在具体使用时Spark并没有区别对待,和“其它内存”一样交给了JVM去管理。
16.3.3 堆内内存分区(统一方式,现)
默认情况下,Spark 仅仅使用了堆内内存。Executor 端的堆内内存区域大致可以分为以下四大块:

整个 Executor 端堆内内存如果用图来表示的话,可以概括如下:
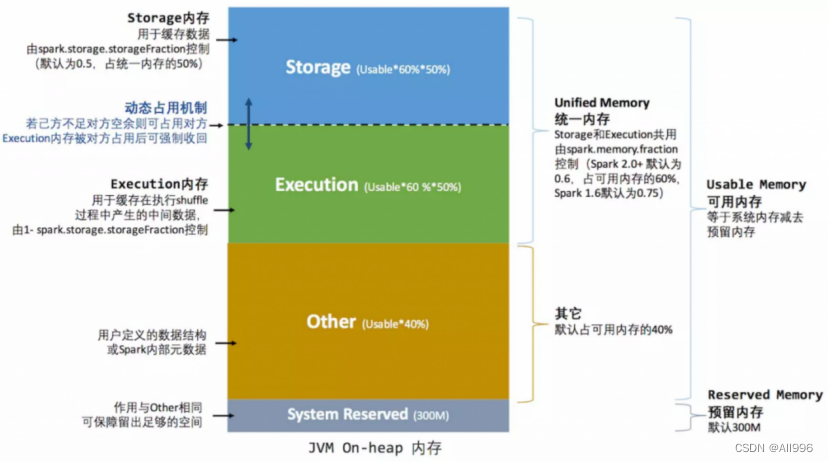
对上图进行以下说明:
- systemMemory = Runtime.getRuntime.maxMemory,其实就是通过参数 spark.executor.memory 或 --executor-memory 配置的。
- reservedMemory 在 Spark 2.2.1 中是写死的,其值等于 300MB,这个值是不能修改的(如果在测试环境下,我们可以通过 spark.testing.reservedMemory 参数进行修改);
- usableMemory = systemMemory – reservedMemory,这个就是 Spark 可用内存;
16.4 堆外内存(Off-heap Memory)
为了进一步优化内存的使用以及提高Shuffle时排序的效率,Spark引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,存储经过序列化的二进制数据。除了没有other空间,堆外内存与堆内内存的划分方式相同,所有运行中的并发任务共享存储内存和执行内存。
Spark 1.6 开始引入了Off-heap memory(详见SPARK-11389)。这种模式不在 JVM 内申请内存,而是调用 Java 的 unsafe 相关 API 进行诸如 C 语言里面的 malloc() 直接向操作系统申请内存。由于这种方式不经过 JVM 内存管理,所以可以避免频繁的 GC,这种内存申请的缺点是必须自己编写内存申请和释放的逻辑。
16.4.1 堆外内存的优缺点
利用JDK Unsafe API(从Spark 2.0开始,在管理堆外的存储内存时不再基于Tachyon(Alluxio),而是与堆外的执行内存一样,基于JDK Unsafe API实现[3]),Spark可以直接操作系统堆外内存,减少了不必要的内存开销,以及频繁的GC扫描和回收,提升了处理性能。堆外内存可以被精确地申请和释放,而且序列化的数据占用的空间可以被精确计算,所以相比堆内内存来说降低了管理的难度,也降低了误差。
16.4.2 堆外内存分区(静态方式,弃)
堆外的空间分配较为简单,存储内存、执行内存的大小同样是固定的
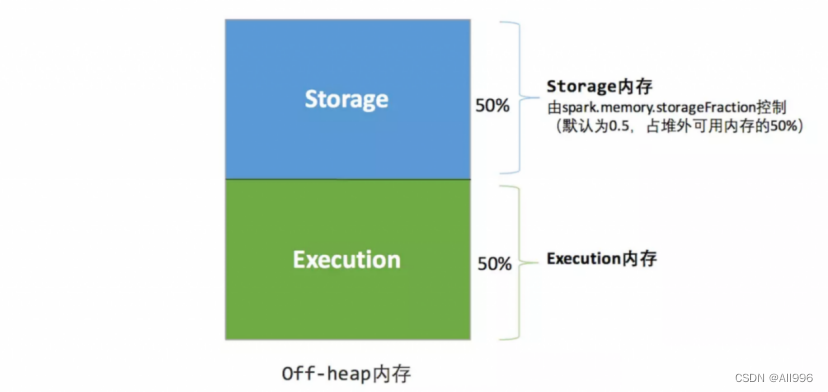
可用的执行内存和存储内存占用的空间大小直接由参数spark.memory.storageFraction决定,由于堆外内存占用的空间可以被精确计算,所以无需再设定保险区域。
静态内存管理机制实现起来较为简单,但如果用户不熟悉Spark的存储机制,或没有根据具体的数据规模和计算任务或做相应的配置,很容易造成“一半海水,一半火焰”的局面,即存储内存和执行内存中的一方剩余大量的空间,而另一方却早早被占满,不得不淘汰或移出旧的内容以存储新的内容。由于新的内存管理机制的出现,这种方式目前已经很少有开发者使用,出于兼容旧版本的应用程序的目的,Spark仍然保留了它的实现。
16.4.3 堆外内存分区(统一方式,现)
相比堆内内存,堆外内存只区分 Execution 内存和 Storage 内存,其内存分布如下图所示:
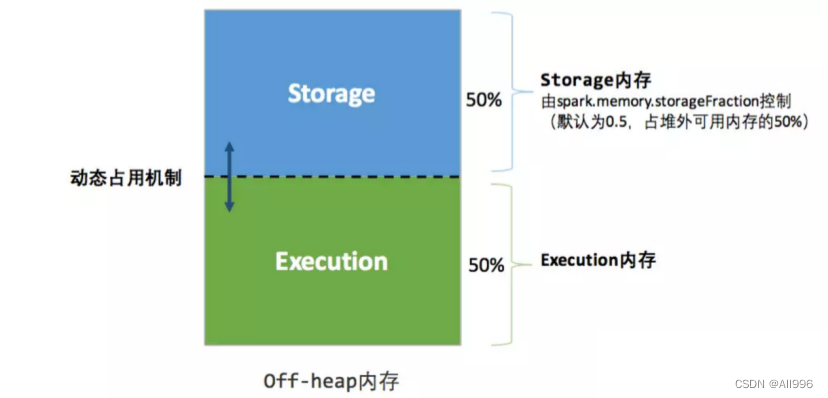
关于动态占用机制,由于统一内存管理方式中堆内堆外内存的管理均基于此机制,所以单独提出来讲解。参见文本第三节。
16.5 动态占用机制–Execution与Storage
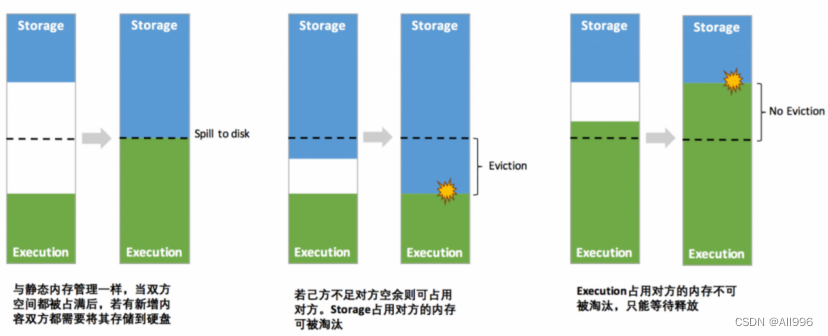
上面两张图中的 Execution 内存和 Storage 内存之间存在一条虚线,这是为什么呢?
在 Spark 1.5 之前,Execution 内存和 Storage 内存分配是静态的,换句话说就是如果 Execution 内存不足,即使 Storage 内存有很大空闲程序也是无法利用到的;反之亦然。这就导致我们很难进行内存的调优工作,我们必须非常清楚地了解 Execution 和 Storage 两块区域的内存分布。
而目前 Execution 内存和 Storage 内存可以互相共享的。也就是说,如果 Execution 内存不足,而 Storage 内存有空闲,那么 Execution 可以从 Storage 中申请空间;反之亦然。所以上图中的虚线代表 Execution 内存和 Storage 内存是可以随着运作动态调整的,这样可以有效地利用内存资源。Execution 内存和 Storage 内存之间的动态调整可以概括如下:
16.6 动态调整策略
具体的实现逻辑如下:
- 程序提交的时候我们都会设定基本的 Execution 内存和 Storage 内存区域(通过 spark.memory.storageFraction 参数设置);
- 在程序运行时,双方的空间都不足时,则存储到硬盘;将内存中的块存储到磁盘的策略是按照 LRU 规则(Least Recently Used)进行的。若己方空间不足而对方空余时,可借用对方的空间;(存储空间不足是指不足以放下一个完整的 Block)
- Execution 内存的空间被对方占用后,可让对方将占用的部分转存到硬盘,然后”归还”借用的空间
- Storage 内存的空间被对方占用后,目前的实现是无法让对方”归还”,因为需要考虑 Shuffle 过程中的很多因素,实现起来较为复杂;而且 Shuffle 过程产生的文件在后面一定会被使用到,而 Cache 在内存的数据不一定在后面使用。
注意,上面说的借用对方的内存需要借用方和被借用方的内存类型都一样,都是堆内内存或者都是堆外内存,不存在堆内内存不够去借用堆外内存的空间。
统一内存分配机制的优点是:提高了内存的利用率,可以更加灵活、可靠的分配和管理内存