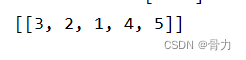现有一个需求,需要在elasticsearch中实现用terms筛选内容,并且按terms传入的内容顺序排列
类型于mysql中order by filed()的排序方式,具体实现如下
目录
- 一、需求
- 二、整体思路
- 三、es查询语句
- 四、java生成es连接
- 五、java调用es
- 六、最终实现结果
一、需求
筛选 fileId 为"3",“2”,“1”,“4”,“5"的记录,并且按照"3”,“2”,“1”,“4”,"5"方式排序
二、整体思路
用terms实现数据的筛选,使用传入集合的索引当作排序的依据
三、es查询语句
terms中是筛选数据内容
sort中是自定义排序规则,将集合索引当作排序的依据
注意:sort 中的 order 内容需要为字符串集合,如果为数字集合,则此排序规则会失效
POST test/_search
{
"query": {
"bool": {
"must": [
{
"terms": {
"fileId": [
"3","2","1","4","5"
]
}
}
]
}
},
"sort": [
{
"_script": {
"type": "number",
"order": "asc",
"script": {
"source": "params.order.indexOf(doc['fileId'].value.toString())",
"params": {
"order": [
"3","2","1","4","5"
]
}
}
}
}
]
}
四、java生成es连接
//生成es连接
private ElasticsearchClient getEsClient() {
try {
//调用es有同步和异步之分,下列方法是同步阻塞调用
// Create the low-level client
RestClient restClient = RestClient.builder(
new HttpHost("127.0.0.1", 9200)).build();
// Create the transport with a Jackson mapper
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
// And create the API client
ElasticsearchClient client = new ElasticsearchClient(transport);
return client;
} catch (Exception e) {
e.printStackTrace();
log.error("生成esClient失败" + e);
}
return null;
}
五、java调用es
下面方法是对java调用es实现第三步中的查询方式
注意:sort 中的 order 内容仍然需要传入字符串格式集合,否则排序都为 -1,无法实现想要的排序效果
public void test() throws Exception {
//基本数据准备
List<Long> fileIdList = new ArrayList<>();
fileIdList.add(3L);
fileIdList.add(2L);
fileIdList.add(1L);
fileIdList.add(4L);
fileIdList.add(5L);
//设置筛选内容
List<String> fileIdStrList = new ArrayList<>();
List<FieldValue> fileValueList = fileIdList.stream().map(m -> {
FieldValue.Builder ff = new FieldValue.Builder();
ff.longValue(m);
fileIdStrList.add(m.toString());
return ff.build();
}).collect(Collectors.toList());
BoolQuery.Builder queryBuilder = new BoolQuery.Builder();
queryBuilder.must(_1 -> _1.terms(_2 -> _2.field("fileId").terms(_3 -> _3.value(fileValueList))));
ElasticsearchClient client = getEsClient();
//设置排序规则
SortOptions.Builder sortOptions2 = new SortOptions.Builder();
sortOptions2.script(_1 -> _1
.type(ScriptSortType.Number)
.order(SortOrder.Asc)
.script(_2 -> _2.inline(_3 -> _3
.source("params.order.indexOf(doc['fileId'].value.toString())")
.params("order", JsonData.of(fileIdStrList)))));
SearchResponse<Map> search = client.search(_1 -> _1
.index("test")
//es默认返回10000条数据,加上此条配置才能返回全部条数
.trackTotalHits(_2 -> _2.enabled(true))
//查询参数
.query(queryBuilder.build()._toQuery())
.sort(sortOptions2.build())
// .from(pageBegin)
// .size(pageSize)
.source(_2 -> _2.filter(_3 -> _3.includes("fileId")))
, Map.class);
Long totalNum = search.hits().total().value(); //查询总条数
List<Integer> resultFileIdList = search.hits().hits().stream().map(m -> (Integer) m.source().get("fileId")).collect(Collectors.toList());
System.out.println(Arrays.asList(resultFileIdList));
}
六、最终实现结果
最终输入结果和传入的 fileId 顺序一致