目录
Mishards:集群分片中间件
Mishards 是什么
Mishards 简单工作原理
Mishards 目标场景
基于 Mishards 的集群方案
总体架构
主要构件
Mishards 配置
全局配置
Mishards:集群分片中间件
Mishards 是什么
Mishards 是一个用 Python 开发的 Milvus 集群分片中间件,其内部处理请求转发、读写分离、水平扩展和动态扩容,为用户提供内存和算力可以扩容的 Milvus 实例。
Mishards 简单工作原理

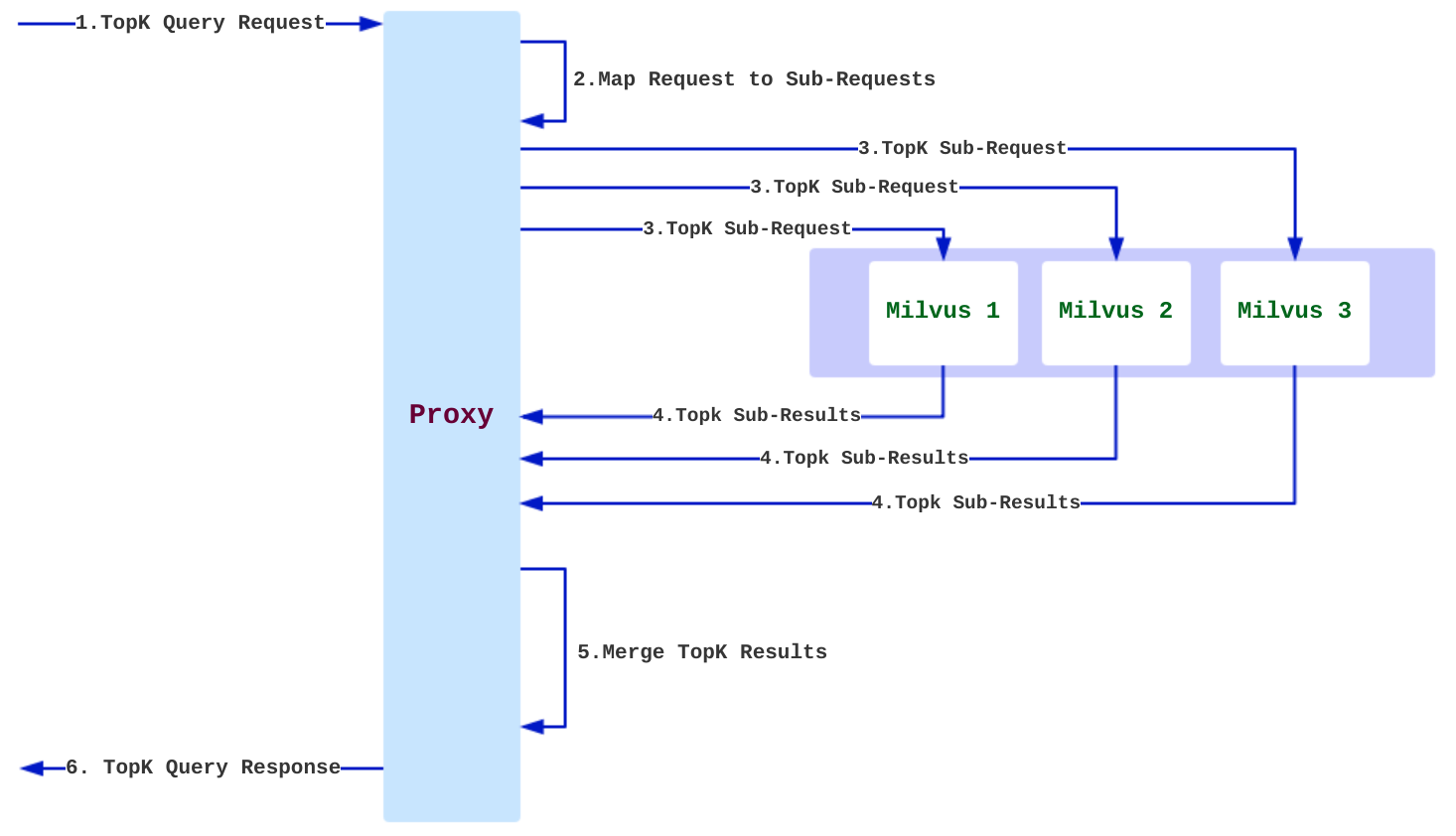
Mishards 负责将上游请求拆分,并路由到内部各细分子服务,最后将子服务结果汇总,返回给上游。
Mishards 目标场景
| 场景分类 | 并发度 | 延迟 | 数据规模 | 是否适合 Mishards |
| 1 | 低 | 低 | 中等、小 | 否 |
| 2 | 高 | 低 | 中等、小 | 否 |
| 3 | 低 | 高 | 大 | 是 |
| 4 | 低 | 低 | 大 | 是 |
| 5 | 高 | 低 | 大 | 是 |
Mishards 适合大数据规模下的搜索场景。那么,怎么判断数据规模的大小呢?这个问题没有标准答案,因为这取决于实际生产环境中使用的硬件资源。这里提供一个简单的判断数据规模的思路:
- 如果你不在意延迟,当数据规模大于单台服务器上硬盘的可用容量时,你可以认为这种场景具有大的数据规模。例如,每次批处理 5000 条查询请求,服务端计算时间已经大于数据从硬盘到内存的加载时间,此时将硬盘的可用容量作为判断数据规模的标准。
- 如果你在意延迟,当数据规模大于单台服务器上的可用内存时,你也可以认为这种场景具有大的数据规模。
基于 Mishards 的集群方案
总体架构

主要构件
- 服务发现:获取读写节点的服务地址。
- 负载均衡器
- Mishards 节点:无状态, 可扩容。
- Milvus 写节点:单节点,不可扩容。为避免单点故障,需为该节点部署高可用 HA 方案。
- Milvus 读节点:有状态,可扩容。
- 共享存储服务:Milvus 读写节点通过共享存储服务共享数据,可选择 NAS 或 NFS。
- 元数据服务:目前只支持 MySQL。生产环境下需要部署 MySQL 高可用方案。
Mishards 配置
全局配置
| 参数 | 是否必填 | 类型 | 默认值 | 说明 |
| Debug | 否 | Boolean | True | 选择是否启用 Debug 工作模式。目前 Debug 模式只会影响日志级别。
|
| TIMEZONE | 否 | String | UTC | 时区 |
| SERVER_PORT | 否 | Integer | 19530 | 定义 Mishards 的服务端口。 |
| WOSERVER | 是 | String | Milvus 写节点地址,参考格式:tcp://127.0.0.1:19530
|