- 《SourcererCC: Scaling Code Clone Detection to Big Code》代码克隆检测基线方法之一;
ABSTRACT
面向的问题:代码克隆检测在海量源码的场景下的扩展性问题;
提出的解决方案:SourcererCC,a token-based clone detector that targets three clone types;
- 采用了一种索引使用标准工作站来提高大型项目间存储库的可扩展性;
- 一种优化的倒排索引来快速查询给定代码块的潜在克隆;
- 基于 token ordering 的启发式过滤被用于减少 index size、code-block 比较数量、token比较次数
结论:本文方案召回率和精度都比较高,可扩展性好;
2 DEFINITIONS
Code Fragment:连续代码片段
(
l
,
s
,
e
)
(l,s,e)
(l,s,e),源文件
l
l
l,起始行
s
s
s,结束行
e
e
e;
Clone Pair:相似代码
(
f
1
,
f
2
,
ϕ
)
(f_1,f_2,\phi)
(f1,f2,ϕ),
f
1
f_1
f1,
f
2
f_2
f2相似代码,
ϕ
\phi
ϕ克隆类型;
Clone Class: 相似代码集合
(
f
1
,
f
2
,
.
.
,
f
n
,
ϕ
)
(f_1,f_2,..,f_n,\phi)
(f1,f2,..,fn,ϕ)
Code Block: 大括号中的一系列语句,local class、变量声明语句等;
Type-1(T1): 等效代码,只有空白符、layout 和 comments 的差异;
Type-2(T2): 等效代码,标识符和字面量有差异;
Type-3(T3): 语句级别不同但句法相似的代码,添加/修改/删除了部分语句;
Type-4(T4): 功能相同但句法不同的代码,语义相似;
3 THE PROPOSED METHOD: SourcererCC
3.1 Problem Formulation
项目P由一系列代码块 { B 1 , . . . , B n } \{B_1,...,B_n\} {B1,...,Bn}组成,一个代码块B由一系列tokens组成 { T 1 , . . , T k } \{T_1,..,T_k\} {T1,..,Tk}。Token 被视为编程语言的关键字、字面量、标识符等,string literal is split on whitespace,不包含运算符。由于代码块可能包含重复的 tokens,因此每个 token 被表示为 (token, frequency) pair。代码块相似度高于某个阈值的被识别为克隆。
函数相似度度量选择了 “Overlap”,因为其直观地捕获了代码块直接的重叠。
overlap similarity
O
(
B
x
,
B
y
)
O(B_x,B_y)
O(Bx,By) 计算为二者共有的token数量:
O
(
B
x
,
B
y
)
=
∣
B
x
∩
B
y
∣
O(B_x,B_y)=|B_x\cap{B_y}|
O(Bx,By)=∣Bx∩By∣
项目
P
x
P_x
Px,
P
y
P_y
Py,相似函数
f
f
f,阈值
θ
\theta
θ,目标:
s.t.
f
(
P
x
.
B
,
P
y
.
B
)
≥
⌈
θ
⋅
m
a
x
(
∣
P
x
.
B
∣
,
∣
P
y
.
B
∣
)
⌉
f(P_x.B, P_y.B)\geq\lceil{\theta·max(|P_x.B|,|P_y.B|)}\rceil
f(Px.B,Py.B)≥⌈θ⋅max(∣Px.B∣,∣Py.B∣)⌉
- ∣ P x . B ∣ |P_x.B| ∣Px.B∣ 指其 token 数量
在这个基础上,对所有代码块两两匹配计算复杂度为
O
(
n
2
)
O(n^2)
O(n2)(图中圆圈)。代码块的粒度这里被称为 method。其他的线是后续提出的算法对这个问题的优化。可以看到几乎线性,具有极大的性能提升。根据本文提出的启发式过滤来显著减少候选比较数量。

3.2 Overview
算法阶段:(i) partial index creation; (ii) clone detection;
- 索引创建阶段:从源文件解析代码块,使用 scanner 进行 tokenize。然后从代码块构建倒排索引即 token 到 code block 的映射。基于后续的启发式过滤规则只对部分 token 构建 partial index;
- 克隆检测阶段:遍历代码块,从索引中拿到候选比较对象;然后使用另一个启发式方法,根据 token 顺序来度量查询和候选块相似度得分的上下界。候选块的相似度上界小于阈值的直接被过滤不用比较。候选者相似度下界高于阈值即被作为候选对象。

3.3 Filtering Heuristics to Reduce Candidate Comparisons
3.3.1 Sub-block Overlap Filtering
when two sets have a large overlap, even their smaller subsets overlap
将代码块视为 bag-of-tokens (i.e. multiset),可以得到:
when two code blocks have large overlap, even their smaller sub-blocks should overlap
Property 1

- 2个代码块公共块有 i i i个,那么其各自的子块(前t-i+1个tokens)至少需要match上一个块。
利用这个性质,我们根据阈值算出需要 match 多少个 token(即 i i i),然后计算前 t-i+1 个tokens构成的子集是否满足至少有一个相交元素。 性质一可以让我们不用所有 tokens 做比较。为了使用这个性质,代码块中的 tokens 需要遵循一个预设的全局顺序。虽然有很多方法设置这个顺序,但一个问题是哪个排序方式最有效?一个直观的想法是让 rare token 在前,这样做会消除大量的 FPs(图1中的🔺)。
但性质一在某些情况下(两个集合的阶不一致时)可能无效,这种情况还需要引入另一个启发式过滤策略来消除 FPs。
3.3.2 Token Position Filtering
考虑position,可以对overlap做一个估计,估计出 current matched tokens 总数和 minimum number of unseen tokens。比如假设此时后面的全匹配中,最大可能匹配的 token 上限可以得到(两个块后续的 tokens 的最小值)如果这个已经小于阈值,那么可以pass这次匹配(已经可以确定无法满足要求)。同理,如果没匹配完已经超出阈值,可以接受这个候选块。

这个规则的效果如图1的“+”所示,可以看到更稳定。
3.4 Clone Detection Algorithm
Partial Index Creation:SourcererCC 根据性质1创建 Partial Index;
名词:global token frequency map (GTP)

Clone Detection

3.5 Detection of Near-miss (Type-3) clones
Type-3 克隆在检测的 bags-of-tokens level 上保留了足够的相似性,基于 token-seqence 的匹配方案则难以处理。
4 EVALUATION
LOC:lines of code
- 使用不同size的输入来检测 SourcererCC 执行和检测的性能。
4.1 Execution Time and Scalability

4.2 Experiment with Big IJaDataset
略
4.3 Recall
4.3.1 Recall Measured by The Mutation Framework

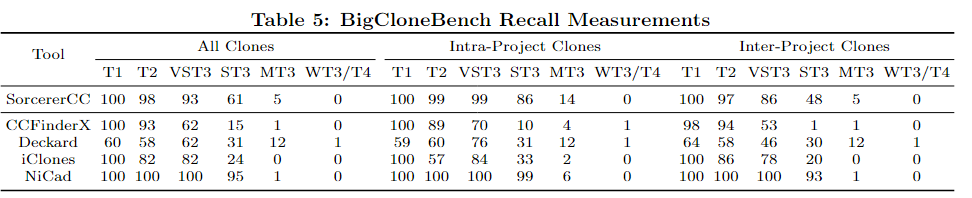
4.3.2 Recall Measured by BigCloneBench

4.4 Precision
5 THREATS OF VALIDITY
6 RELATED WORK
7 CONCLUSION
扩展性实验数据集:IJaDataset,a Big Data inter-project repository containing 25,000 open-source Java systems, and 250MLOC;
评估Benchmarks:1)Mutation Framework;2)BigCloneBench;
结论:在 Type-3 克隆检测上取得了当年的 SOTA;
相关资源
- Code1 | Code2