unlink的意思其实就是删除。在介绍这个函数之前,我们得介绍一点概念。在程序中,如果我们使用malloc申请的内存在不用或者不需要的时候,是需要程序员手动去释放,也就是free操作。我们知道malloc操作free操作都是涉及到内存管理的。那么涉及到硬件操作一定是要通过系统调用。系统调用对性能的消耗是很大的,glibc为了减少频繁的系统调用。在用户free掉一块内存空间的时候,并不会急着把这片内存归还给操作系统。ptmalloc会统一管理heap和mmap区域中的空间chunk。等到下一次用户需要再次申请的时候,会优先从这些空闲的chunk分配给用户。这样做很大程度上降低了内存分配的开销。
那么ptmalloc是怎么操作的呢?首先在ptmalloc中有一个名词叫bin。它是一个链表结构,表示空闲的chunk,在ptmalloc中讲大小差不多的空闲chunk用这样的bin链表来链接起来。根据大小的不同分成了很多种bin。这些bin组合在一起叫bins。是由一个数组表示的,如图: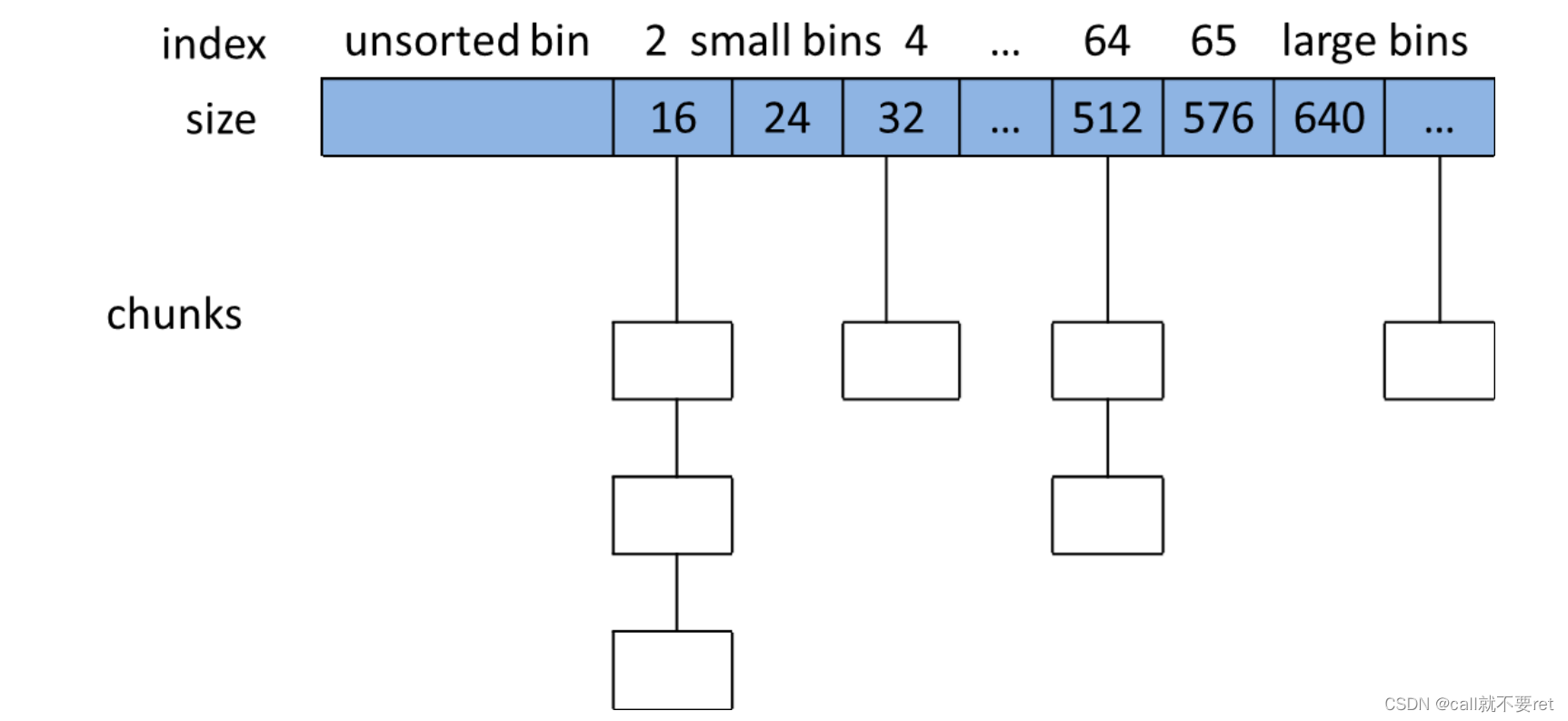
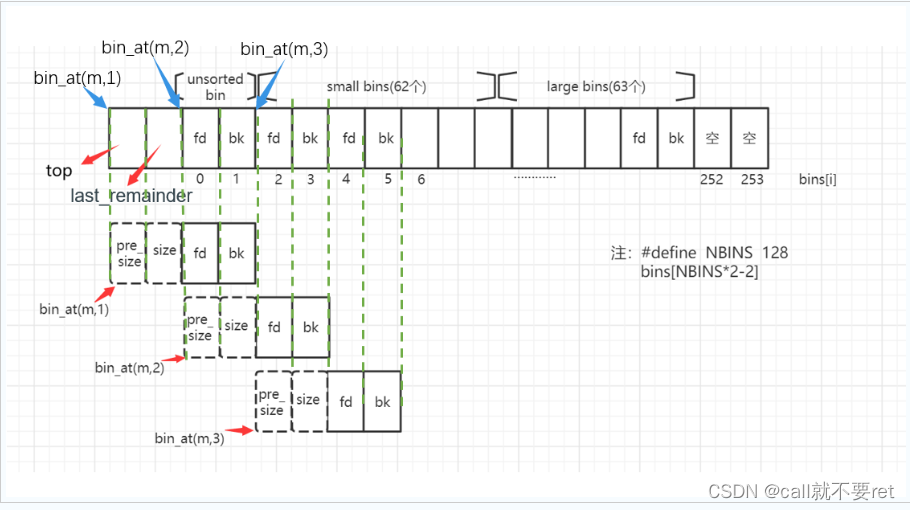
#define bin_at(m, i) \
(mbinptr) (((char *) &((m)->bins[((i) - 1) * 2])) \
- offsetof (struct malloc_chunk, fd))这个宏其实是用于定位bin的,m是指向malloc_state的指针,因为bins数组在这个结构体里定义的:
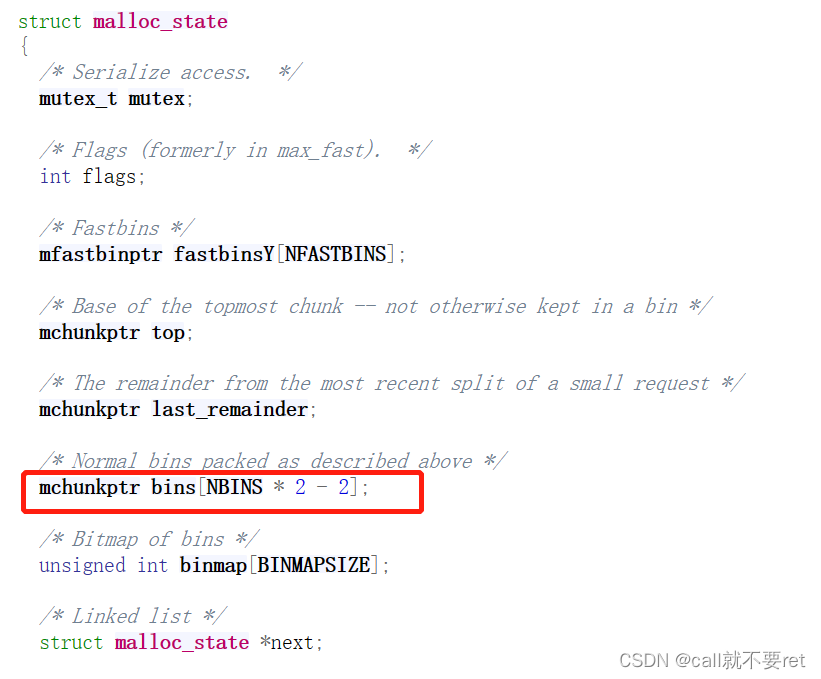
其次i就是一个索引。乘以2是因为2个数组下标为一个bin。假设i=1,我们就找到了unsorted bin的fd,假设i=2,我们就找到了第一个small bins的fd。以此类推而来。
接着- offsetof (struct malloc_chunk, fd)就是减去fd在malloc_chunk的偏移,就能得到这个chunk头。
最后强转为malloc_chunk结构体指针,这个指针的宏定义在这:
typedef struct malloc_chunk *mbinptr;通过这个宏我们能找到相应空闲chunk的头部指针。
#define next_bin(b) ((mbinptr) ((char *) (b) + (sizeof (mchunkptr) << 1)))这个宏是用来找到下一个bin的。这个b其实就是&((m)->bins[((i) - 1) * 2])。就是这个数组的某个bin的地址,语言表达不够,画图来描述:
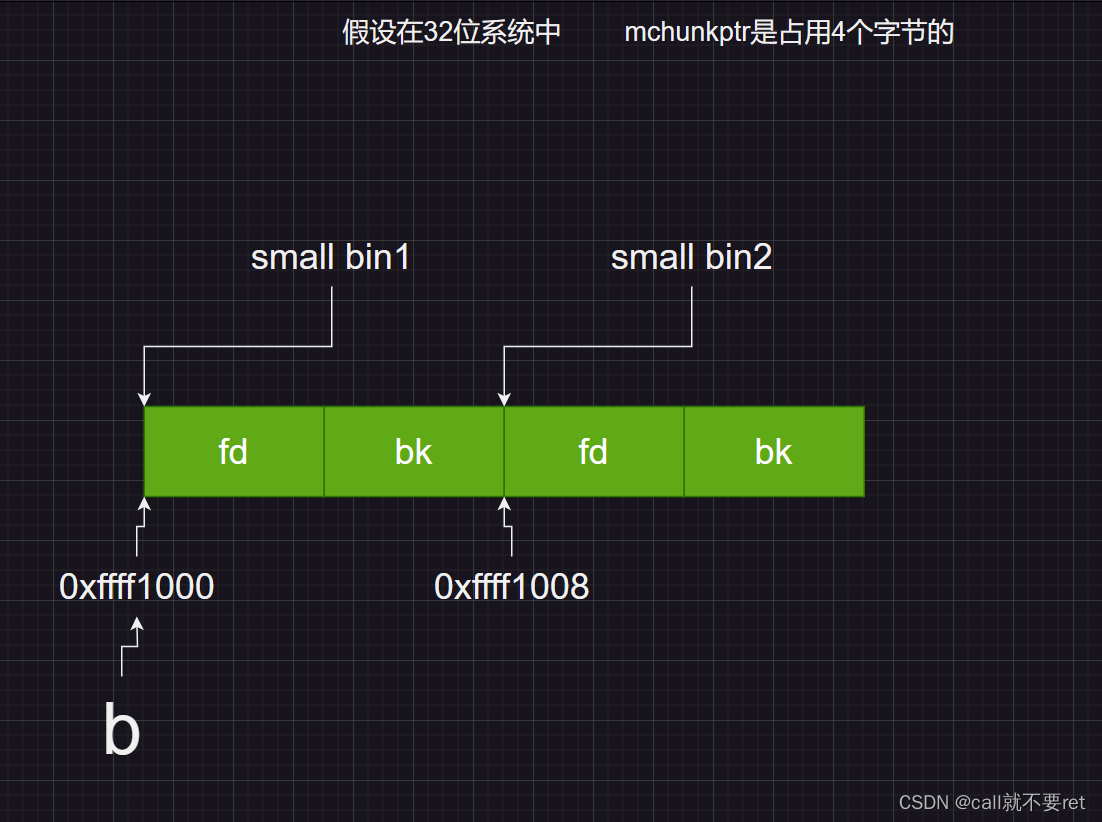
(mchunkptr)<<1相当于乘以2,因此直接能找到下一个bin所在的位置。图应该很好理解。
#define first(b) ((b)->fd)
#define last(b) ((b)->bk)这两个宏很简单吧就不解释了。
接下来就是我们的unlink宏的解析了。代码如下:
#define unlink(AV, P, BK, FD) { \
FD = P->fd; \
BK = P->bk; \
if (__builtin_expect (FD->bk != P || BK->fd != P, 0)) \
malloc_printerr (check_action, "corrupted double-linked list", P, AV); \
else { \
FD->bk = BK; \
BK->fd = FD; \
if (!in_smallbin_range (P->size) \
&& __builtin_expect (P->fd_nextsize != NULL, 0)) { \
if (__builtin_expect (P->fd_nextsize->bk_nextsize != P, 0) \
|| __builtin_expect (P->bk_nextsize->fd_nextsize != P, 0)) \
malloc_printerr (check_action, \
"corrupted double-linked list (not small)", \
P, AV); \
if (FD->fd_nextsize == NULL) { \
if (P->fd_nextsize == P) \
FD->fd_nextsize = FD->bk_nextsize = FD; \
else { \
FD->fd_nextsize = P->fd_nextsize; \
FD->bk_nextsize = P->bk_nextsize; \
P->fd_nextsize->bk_nextsize = FD; \
P->bk_nextsize->fd_nextsize = FD; \
} \
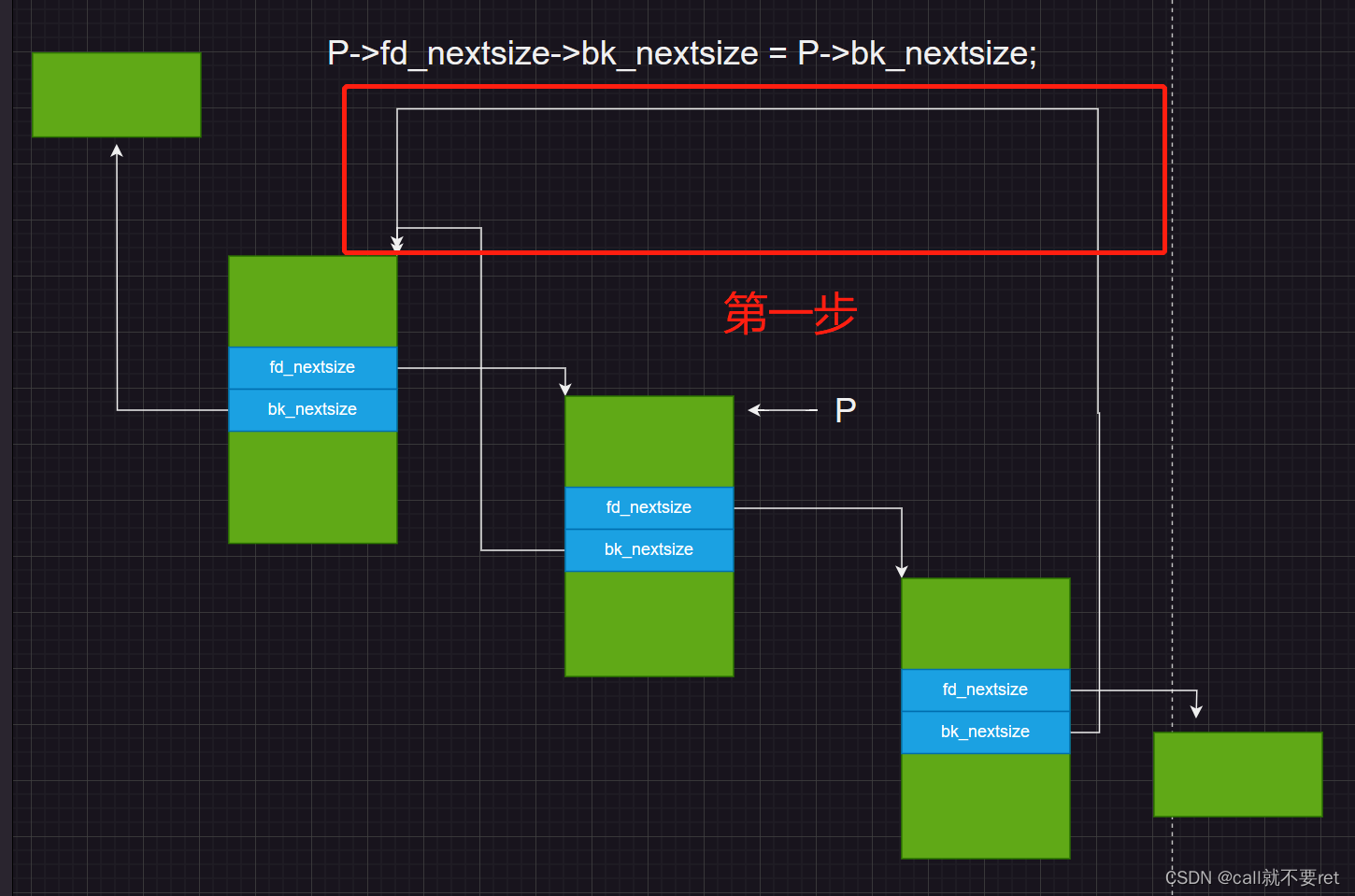
} else { \
P->fd_nextsize->bk_nextsize = P->bk_nextsize; \
P->bk_nextsize->fd_nextsize = P->fd_nextsize; \
} \
} \
} \
}第一步是保存要删除节点的前后指向的位置:
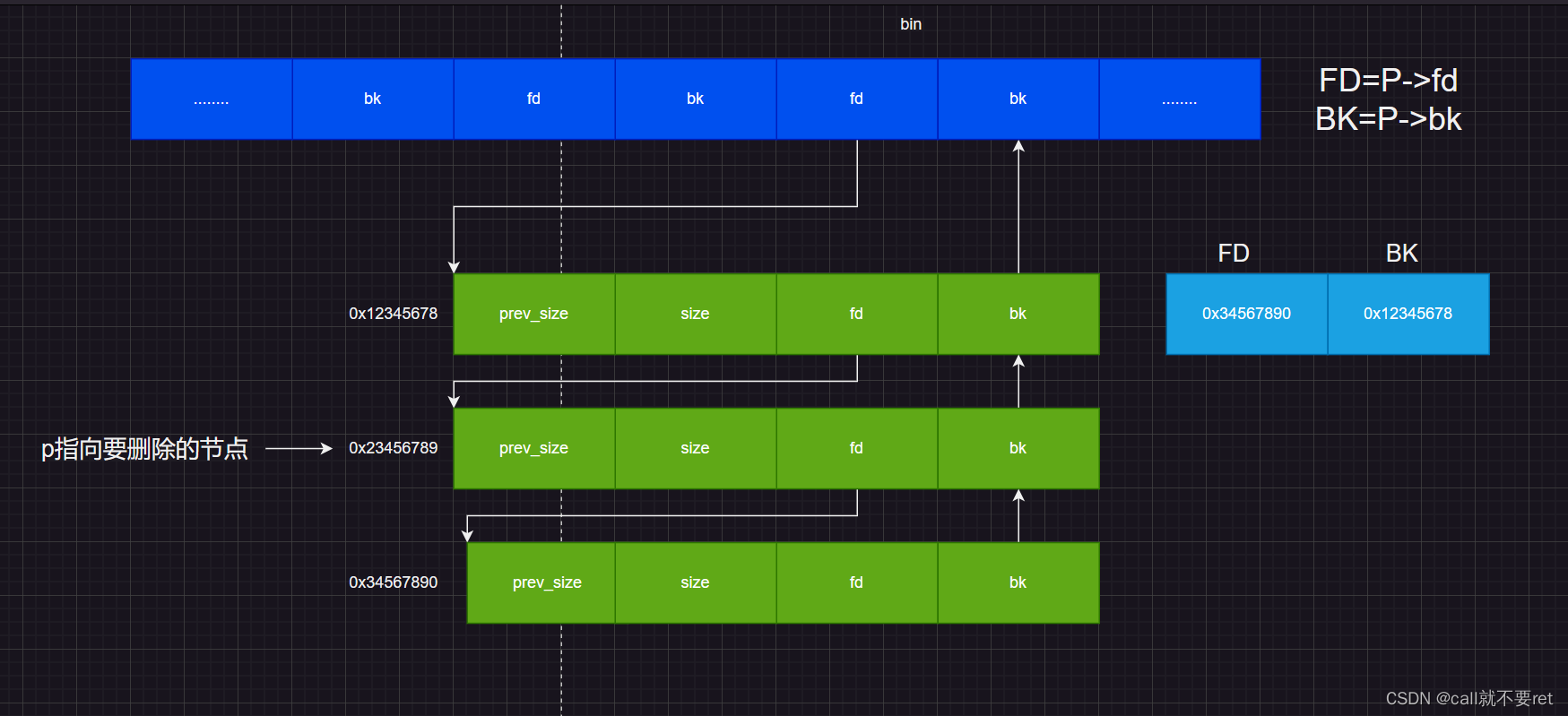
因为fd和bk其实都是指向一个chunk的头部的,千万不要以为是指向其fd或者bk的位置,我图画不好请见谅。
if (__builtin_expect (FD->bk != P || BK->fd != P, 0)) \
malloc_printerr (check_action, "corrupted double-linked list", P, AV);这一段是判断这个P的完整性,用下一个chunk的bk指针和前一个chunk的fd指针来验证是否都指向p,如果验证不完整则会调用malloc_printerr函数来报告错误。
如果P是完整的,那么将执行如下步骤:
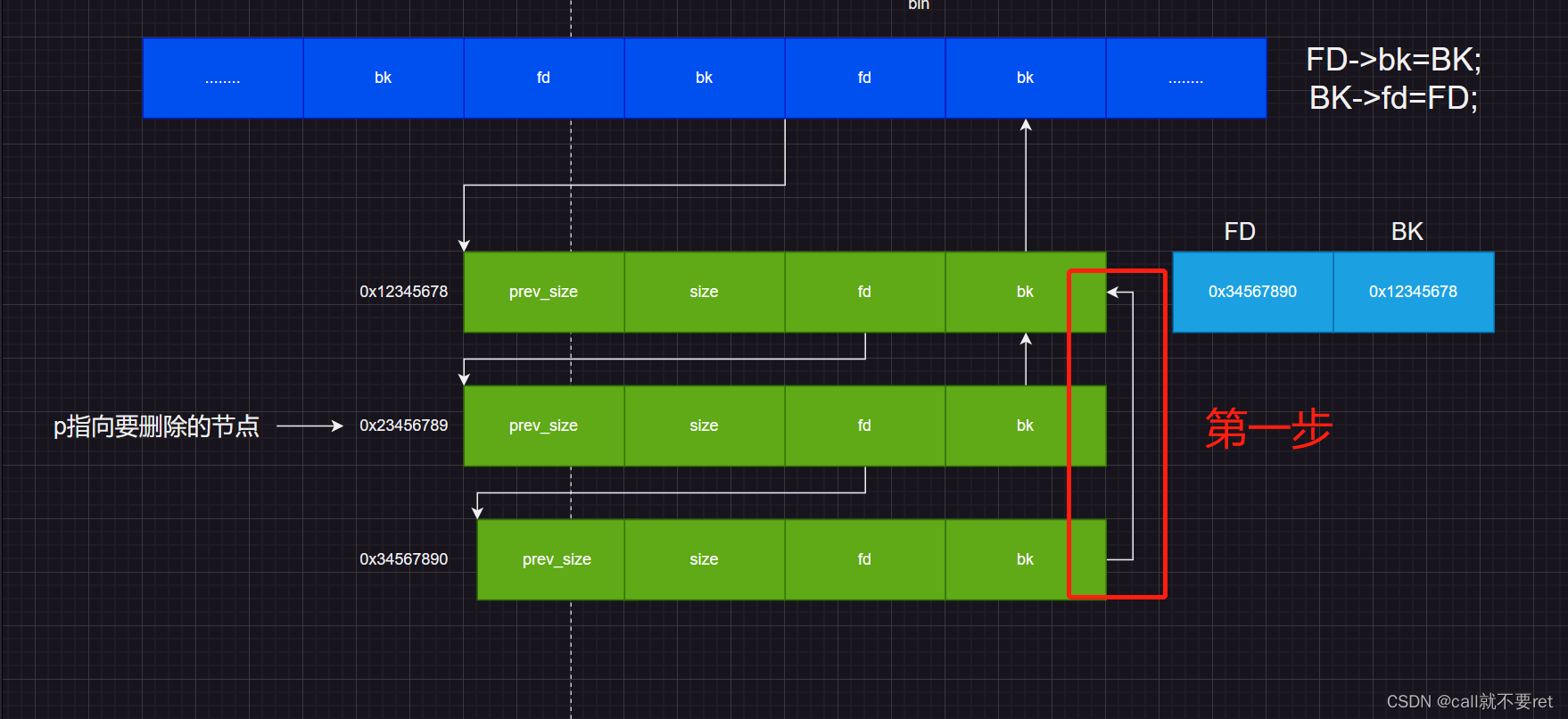
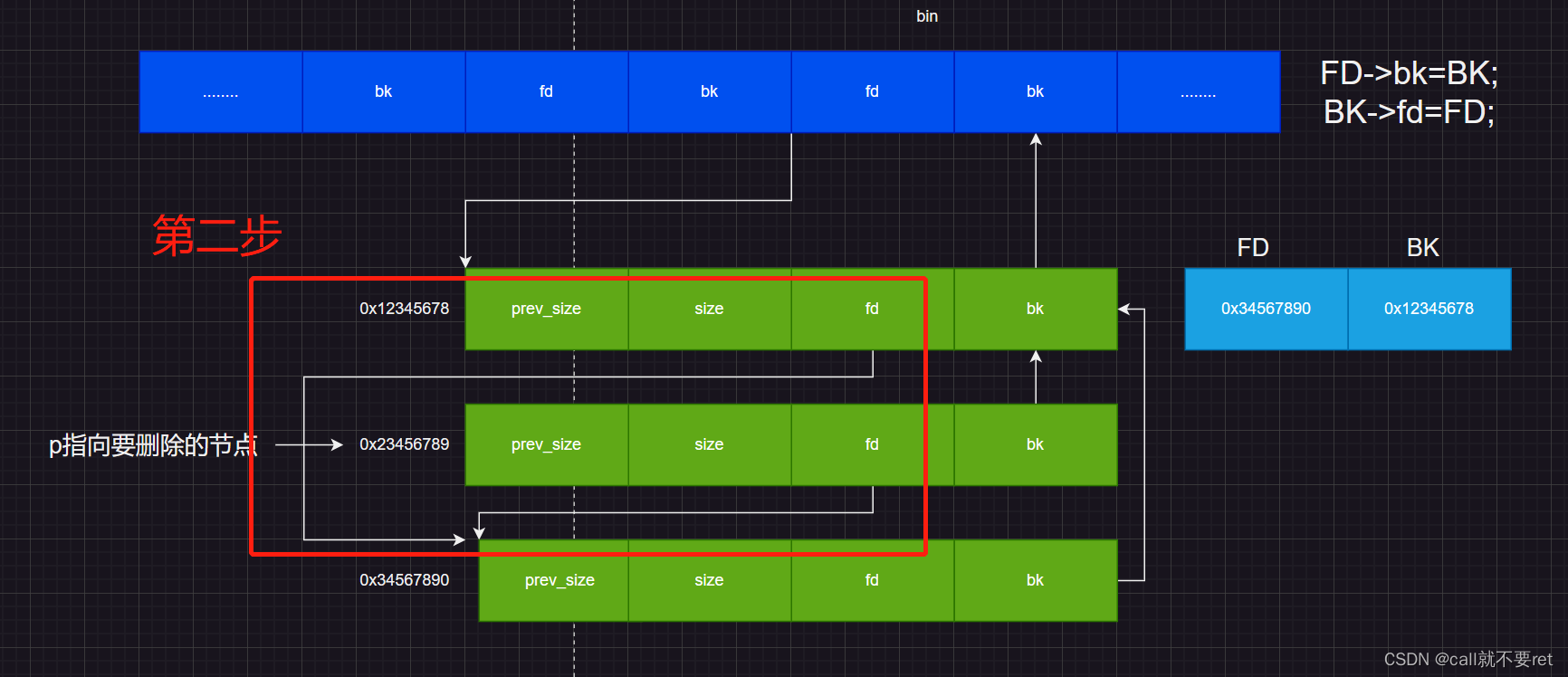
这两步操作俗称断链。就是双向链表的断链操作。
if (!in_smallbin_range (P->size) \
&& __builtin_expect (P->fd_nextsize != NULL, 0))in_smallbin_range (P->size): 这部分是一个条件判断语句,判断节点 P 的大小是否不在小块范围内。
in_smallbin_range 是一个函数或宏,用于确定节点 P 的大小是否在小块范围内。
如果节点 P 的大小不在小块范围内,条件成立。
__builtin_expect (P->fd_nextsize != NULL, 0): 这部分是另一个条件判断语句,使用了内置函数 __builtin_expect 来提高条件判断的预测性能。它判断节点 P 的 fd_nextsize 成员是否不为 NULL。
如果条件成立(即 fd_nextsize 不为 NULL),表达式的值为非零。
如果条件不成立(即 fd_nextsize 为 NULL),表达式的值为零。
如果不是小块,那就是大块,大块会多两个指针,这在chunk结构里面讲过:
struct malloc_chunk* fd_nextsize;
struct malloc_chunk* bk_nextsize;如果上述的判断成立接着判断双向链表的完整性:
if (__builtin_expect (P->fd_nextsize->bk_nextsize != P, 0) \
|| __builtin_expect (P->bk_nextsize->fd_nextsize != P, 0)) \
malloc_printerr (check_action, \
"corrupted double-linked list (not small)", \
P, AV); 和前面的判断其实是类似的,只不过这是执行大块的逻辑。如果其中有一个不成立,则表明链表出现异常,则会执行malloc_printerr函数报告错误。
if(FD->fd_nextsize == NULL){
代码块;
}如果P指向chunk的下一个chunk是最后一个(这里有点绕,可以回看上面的图),将执行代码块内的内容。如果不是最后一个则执行如下代码:
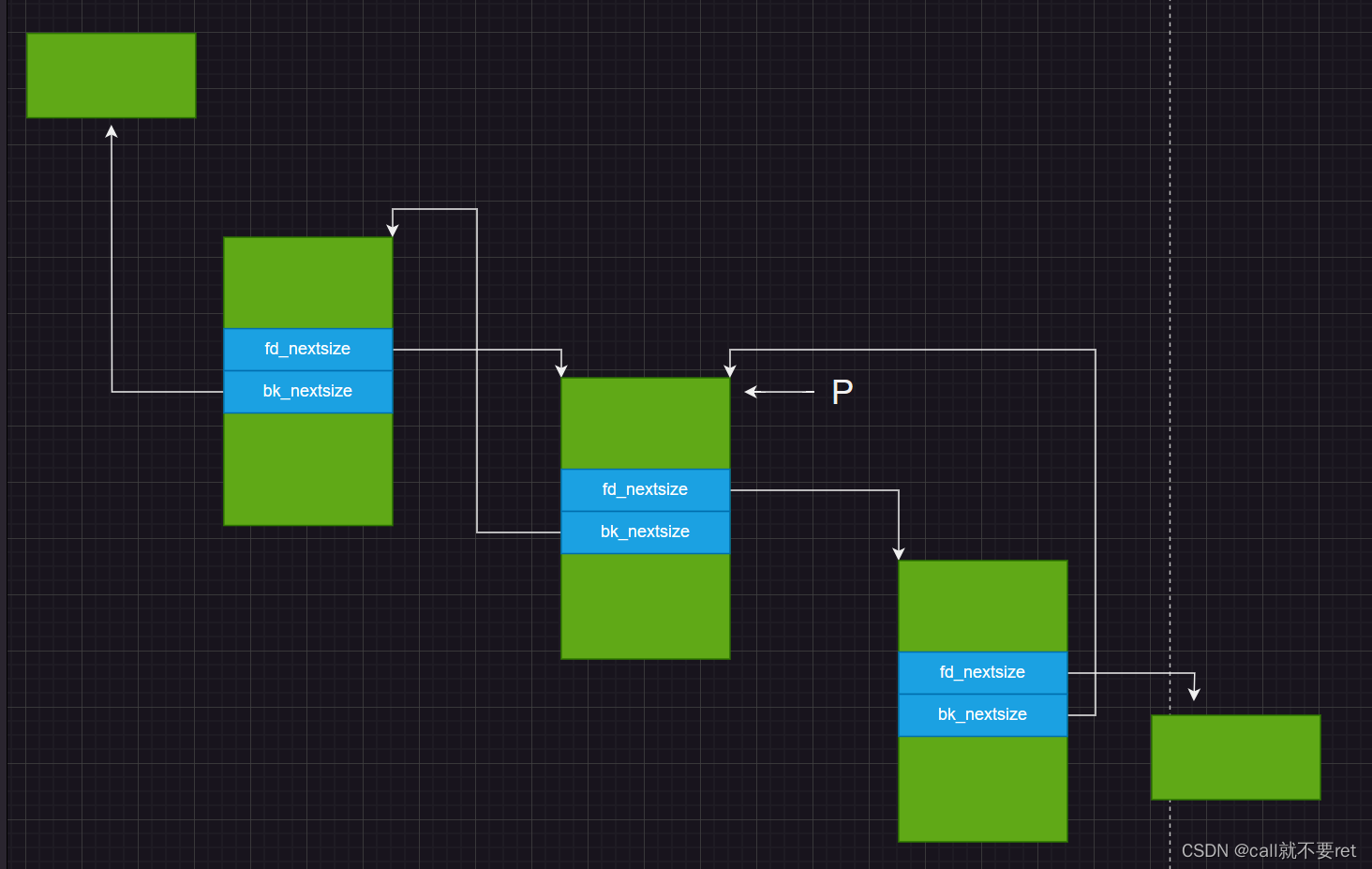
else {
P->fd_nextsize->bk_nextsize = P->bk_nextsize;
P->bk_nextsize->fd_nextsize = P->fd_nextsize;
}
忽略P的fd_nextsize和bk_nextsize的指向后图示如下: 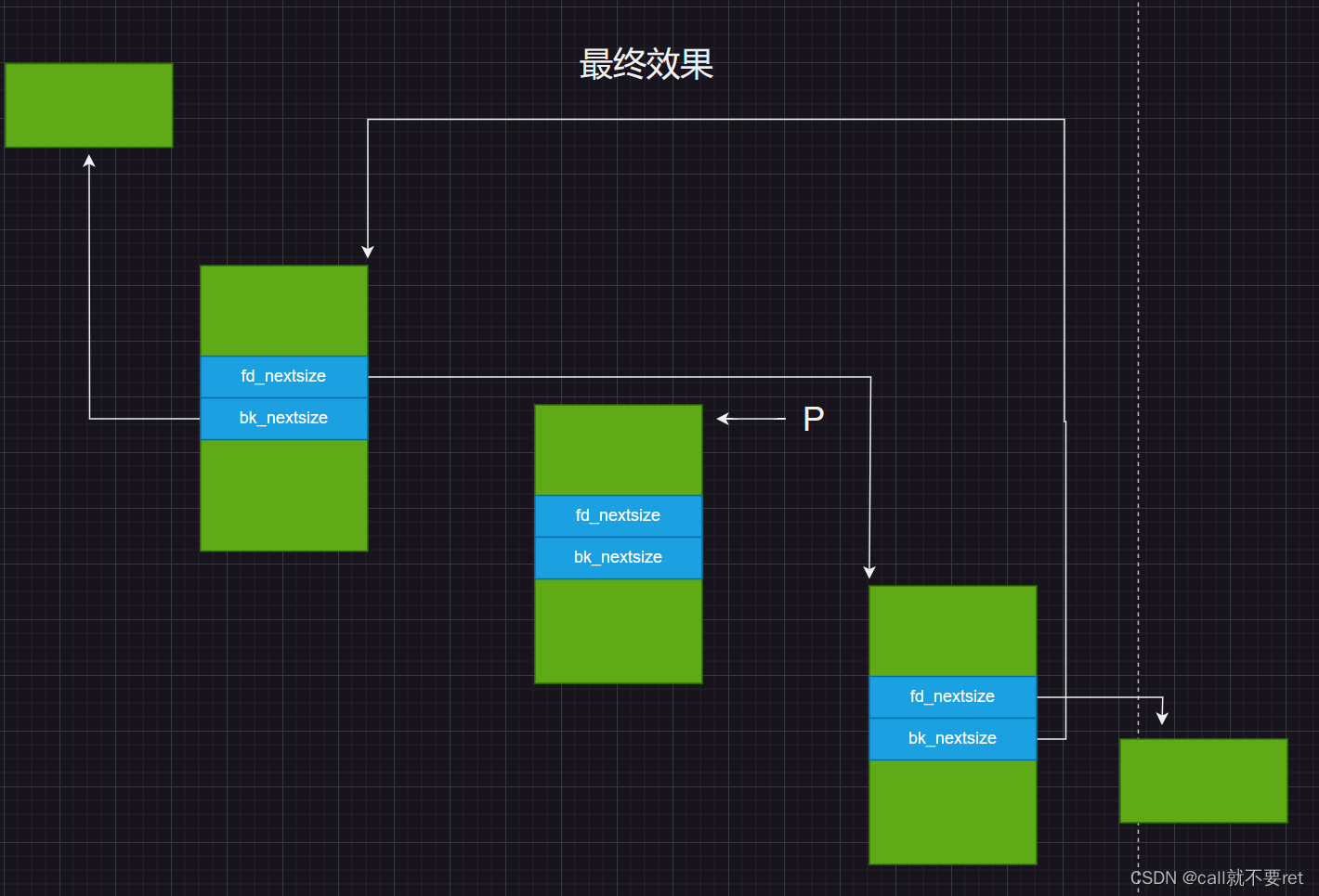
如果上述条件不成立将执行如下逻辑:
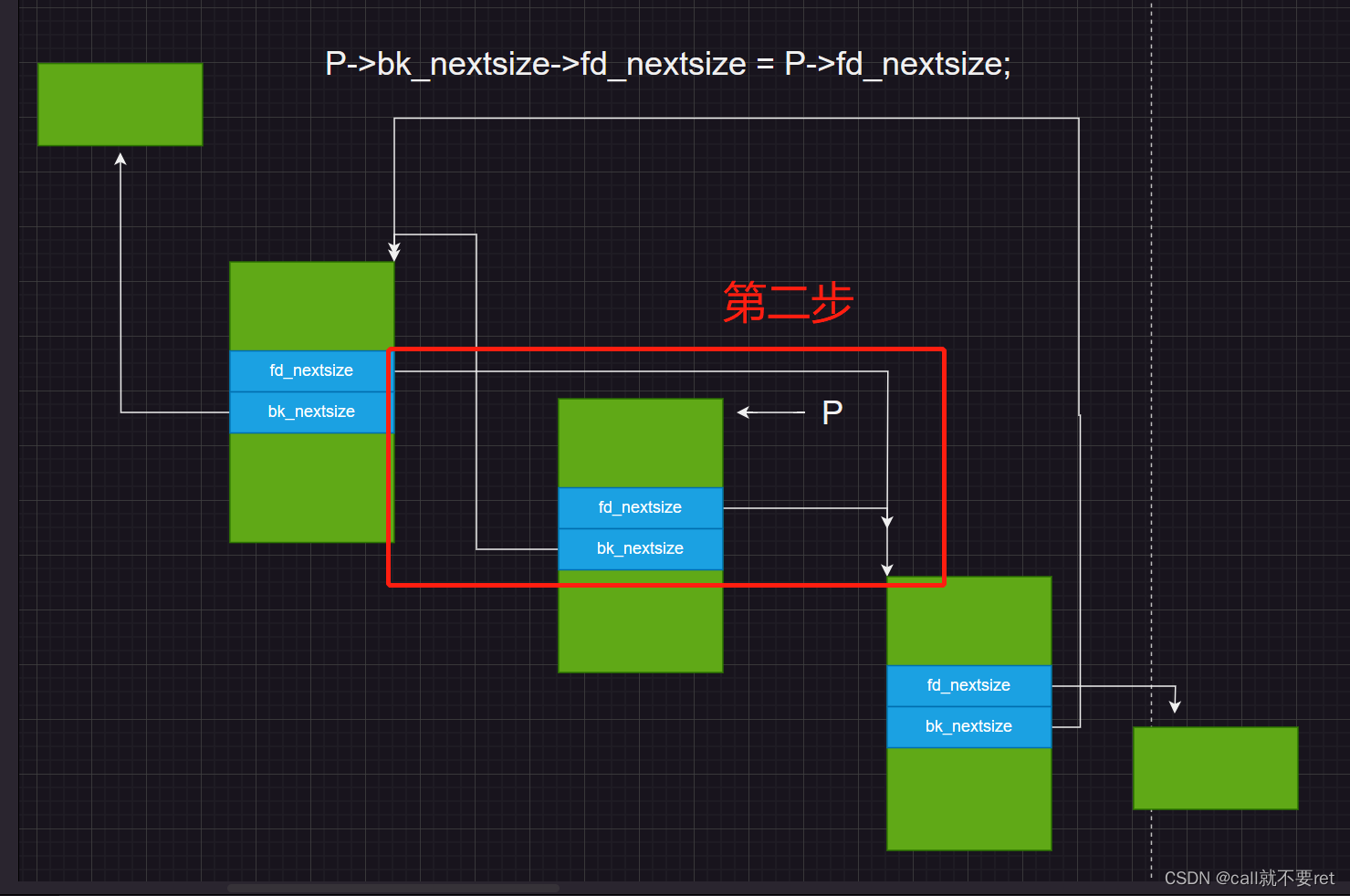
if (P->fd_nextsize == P) \
FD->fd_nextsize = FD->bk_nextsize = FD; \
else { \
FD->fd_nextsize = P->fd_nextsize; \
FD->bk_nextsize = P->bk_nextsize; \
P->fd_nextsize->bk_nextsize = FD; \
P->bk_nextsize->fd_nextsize = FD; \
} 如果 P->fd_nextsize == P 成立,意味着节点 P 的 fd_nextsize 成员指向自身。这在双向链表中表示链表中只有一个节点。将执行:
FD->fd_nextsize = FD->bk_nextsize = FD;否则执行:
FD->fd_nextsize = P->fd_nextsize;
FD->bk_nextsize = P->bk_nextsize;
P->fd_nextsize->bk_nextsize = FD;
P->bk_nextsize->fd_nextsize = FD;这就是unlink实现的基本过程(可能理解不过透彻有错误欢迎指出),主要就是设计不同大小的bin实现不同的断链。有一丢丢复杂吧。
![[框架]Spring框架](https://img-blog.csdnimg.cn/9619f614046a4988ac084995f3f37199.png)