文章目录
- 前言
- 导入所需的库
- 忽略证书验证
- 下载并加载 CIFAR-10 数据集
- 数据预处理
- 构建深度学习模型
- 编译模型
- 模型训练
- 模型评估
- 进行图片识别
- 测试图片
- 运行效果
- 完整代码
- 完结
前言

深度学习模型在图像识别领域的应用越来越广泛。通过对图像数据进行学习和训练,这些模型可以自动识别和分类图像,帮助我们解决各种实际问题。其中,CIFAR-10数据集是一个广泛使用的基准数据集,包含了10个不同类别的彩色图像。本文将介绍如何使用深度学习模型构建一个图像识别系统,并以CIFAR-10数据集为例进行实践和分析。文章中会详细解释代码的每一步,并展示模型在测试集上的准确率。此外,还将通过一张图片的识别示例展示模型的实际效果。通过阅读本文,您将了解深度学习模型在图像识别中的应用原理和实践方法,为您在相关领域的研究和应用提供有价值的参考。
导入所需的库
import tensorflow as tf
from tensorflow import keras
import ssl
import urllib.request
import cv2
代码中导入了 TensorFlow 和 Keras 库。TensorFlow 是一个开源的深度学习框架,Keras 是基于 TensorFlow 的高级神经网络 API。ssl 用于处理证书验证,urllib.request 用于下载图片,cv2 用于读取图片。
忽略证书验证
ssl._create_default_https_context = ssl._create_unverified_context
这行代码将忽略证书验证。在使用 urllib.request 下载数据集时,有时会遇到证书验证的问题。通过这行代码可以忽略证书验证,确保数据集能够顺利下载。
下载并加载 CIFAR-10 数据集
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
这行代码使用 Keras 提供的 cifar10.load_data() 方法从官方网站上下载 CIFAR-10 数据集,并将训练集和测试集分别保存到 (x_train, y_train) 和 (x_test, y_test) 中。该数据集包含了60000张32x32像素的彩色图像,共分为10个类别。
数据预处理

x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
这段代码将训练集和测试集中的图像数据类型转换为浮点型,并将像素值缩放到 [0, 1] 的范围内。这一步是为了使像素值的数值范围一致,便于神经网络的训练。
构建深度学习模型

model = keras.Sequential([
keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
keras.layers.MaxPooling2D((2, 2)),
keras.layers.Conv2D(64, (3, 3), activation='relu'),
keras.layers.MaxPooling2D((2, 2)),
keras.layers.Conv2D(64, (3, 3), activation='relu'),
keras.layers.Flatten(),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dense(10)
])
这段代码使用 Keras 的 Sequential 模型构建一个卷积神经网络(CNN)模型。该模型包含了三个卷积层、两个最大池化层、一个扁平化层和两个全连接层。
具体来说:
- 第一个卷积层使用32个大小为3x3的滤波器,并使用ReLU激活函数。
- 第一个最大池化层使用2x2的滤波器。
- 第二个卷积层使用64个大小为3x3的滤波器,并使用ReLU激活函数。
- 第二个最大池化层使用2x2的滤波器。
- 第三个卷积层使用64个大小为3x3的滤波器,并使用ReLU激活函数。
- 扁平化层将多维张量转换为一维向量。
- 第一个全连接层包含64个神经元,并使用ReLU激活函数。
- 输出层包含10个神经元,对应CIFAR-10数据集中的类别。
编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
这段代码编译了模型。指定了优化器(使用 Adam 优化器)、损失函数(使用交叉熵损失函数)和评估指标(准确率)。
模型训练
model.fit(x_train, y_train, epochs=10, validation_data=(x_test, y_test))
这段代码使用模型的 fit() 方法来训练模型。传入训练集图像数据和对应标签,指定迭代次数为10,并提供验证集用于验证训练过程中的性能。
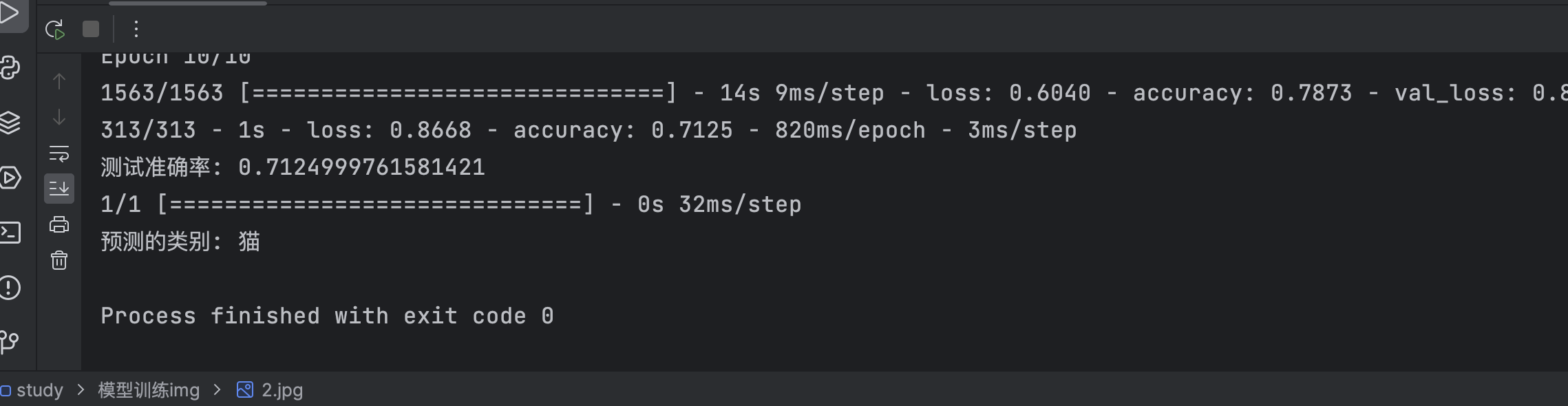
模型评估
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print('测试准确率:', test_acc)
这段代码使用模型的 evaluate() 方法对测试集进行评估,并打印出测试准确率。
进行图片识别
image_url = "模型训练img/2.jpg"
image = cv2.imread(image_url)
image = keras.preprocessing.image.load_img(image_url, target_size=(32, 32))
image = keras.preprocessing.image.img_to_array(image)
image = image.reshape(1, 32, 32, 3)
image = image.astype('float32') / 255.0
predictions = model.predict(image)
class_index = tf.argmax(predictions[0])
class_label = class_index.numpy()
class_labels = ['飞机', '汽车', '鸟', '猫', '鹿', '狗', '青蛙', '马', '船', '卡车']
predicted_label = class_labels[class_label]
print('预测的类别:', predicted_label)
这段代码首先定义了一张图片的URL,然后使用 cv2 库的 imread() 方法读取该图片文件。接着使用 Keras 的图像处理函数 load_img() 加载图片,并将其转换为数组形式。然后对图片进行尺寸调整和归一化处理。最后,使用模型的 predict() 方法对图片进行预测,得到预测结果的概率分布。找到概率分布中概率最大的类别下标,并获取类别标签。最后打印出预测的类别名称。
测试图片

运行效果
完整代码
import tensorflow as tf
from tensorflow import keras
import ssl
import urllib.request
import cv2
# 忽略证书验证
ssl._create_default_https_context = ssl._create_unverified_context
# 下载并加载 CIFAR-10 数据集
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
# 数据预处理
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
# 构建深度学习模型
model = keras.Sequential([
keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
keras.layers.MaxPooling2D((2, 2)),
keras.layers.Conv2D(64, (3, 3), activation='relu'),
keras.layers.MaxPooling2D((2, 2)),
keras.layers.Conv2D(64, (3, 3), activation='relu'),
keras.layers.Flatten(),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dense(10)
])
# 编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 模型训练
model.fit(x_train, y_train, epochs=10, validation_data=(x_test, y_test))
# 模型评估
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print('测试准确率:', test_acc)
# 进行图片识别
image_url = "模型训练img/2.jpg"
image = cv2.imread(image_url)
image = keras.preprocessing.image.load_img(image_url, target_size=(32, 32))
image = keras.preprocessing.image.img_to_array(image)
image = image.reshape(1, 32, 32, 3)
image = image.astype('float32') / 255.0
predictions = model.predict(image)
class_index = tf.argmax(predictions[0])
class_label = class_index.numpy()
class_labels = ['飞机', '汽车', '鸟', '猫', '鹿', '狗', '青蛙', '马', '船', '卡车']
predicted_label = class_labels[class_label]
print('预测的类别:', predicted_label)
完结




![[学习笔记]python的web开发全家桶2(ing)](https://img-blog.csdnimg.cn/1aef71443d294ed2b0bc21b099ca20f1.png)



![银河麒麟系统安装mysql数据库[mysql-5.7.28-linux-glibc2.12-x86_64]](https://img-blog.csdnimg.cn/img_convert/8a29e06240f2733cc3be95870b806925.png)