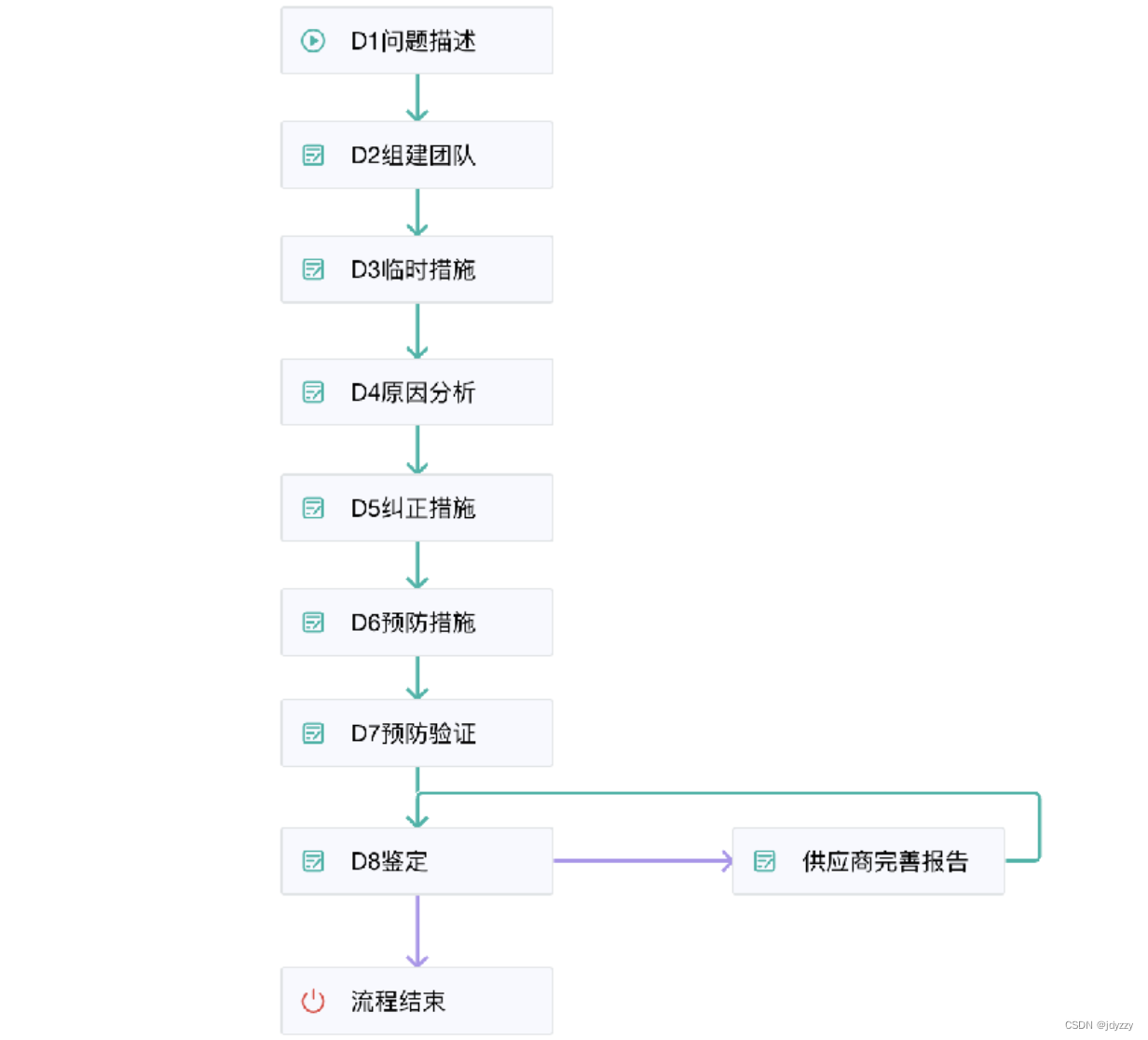
目录
模型搭建
模型训练
模型搭建
使用到的数据集为IMDB电影评论情感分类数据集,该数据集包含 50,000 条电影评论,其中 25,000 条用于训练,25,000 条用于测试。每条评论被标记为正面或负面情感,因此该数据集是一个二分类问题。
①导入所需的库。
import tensorflow as tf
from keras.datasets import imdb
from keras.models import Sequential
from keras.layers import Dense, Embedding, GlobalAveragePooling1D
②通过调用 imdb.load_data 函数加载 IMDB 电影评论数据集,并将其拆分为训练集和测试集,其中 num_words 参数指定了词汇表的大小,只选择出现频率最高的前 10000 个单词。
vocab_size = 10000
maxlen = 256
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=vocab_size)③使用 tf.keras.preprocessing.sequence.pad_sequences 函数对训练集和测试集中的序列进行填充,使它们具有相同的长度。
x_train = tf.keras.preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = tf.keras.preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen)
④定义了一个序列模型,模型包含了嵌入层(Embedding)、全局平均池化层(GlobalAveragePooling1D)和一个具有 sigmoid 激活函数的全连接层(Dense)。模型使用二元交叉熵作为损失函数,使用 Adam 优化器进行参数优化。
model = Sequential()
model.add(Embedding(vocab_size, 16))
model.add(GlobalAveragePooling1D())
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
⑤使用训练集对模型进行训练,并指定了训练的轮数、批次大小以及在测试集上验证模型。
model.fit(x_train, y_train, epochs=10, batch_size=128, validation_data=(x_test, y_test))
⑥使用测试集对训练好的模型进行评估,计算模型在测试集上的损失和准确率,并将准确率打印出来。
loss, accuracy = model.evaluate(x_test, y_test)
print('Test accuracy:', accuracy)完整代码如下:
import tensorflow as tf
from keras.datasets import imdb
from keras.models import Sequential
from keras.layers import Dense, Embedding, GlobalAveragePooling1D
# 加载 IMDB 电影评论数据集
vocab_size = 10000
maxlen = 256
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=vocab_size)
x_train = tf.keras.preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = tf.keras.preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen)
# 定义模型
model = Sequential()
model.add(Embedding(vocab_size, 16))
model.add(GlobalAveragePooling1D())
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=10, batch_size=128, validation_data=(x_test, y_test))
# 在测试集上评估模型
loss, accuracy = model.evaluate(x_test, y_test)
print('Test accuracy:', accuracy)
模型训练
使用 Adam 优化器和二元交叉熵损失函数进行模型训练,并以准确率作为评估指标,共训练10轮,训练过程如图9所示。

图9 IMDB电影评论情感分析训练过程
训练出的电影评论情感分析模型在测试集上的准确率和损失随训练的轮次的变化如图10所示。
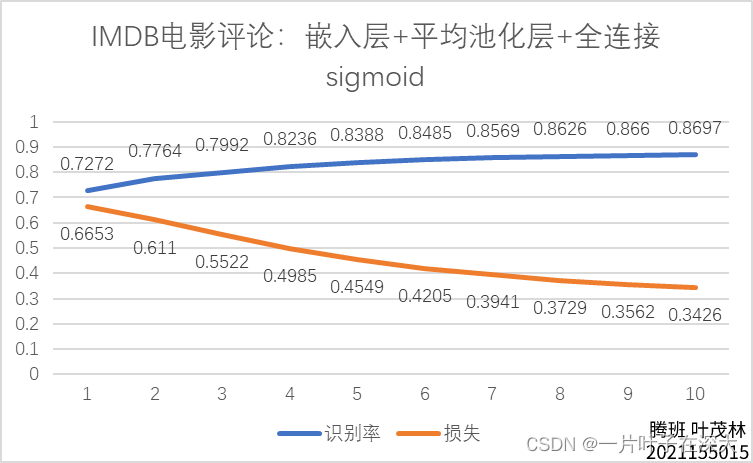
图10情感分析 准确率
具体数据如表5所示。

表5 情感分析
由结果可以知道,我们训练出来的电影评论情感分析模型,其数据的拟合效果和测试的泛化效果都比较理想。










![[学习笔记]python的web开发全家桶2(ing)](https://img-blog.csdnimg.cn/1aef71443d294ed2b0bc21b099ca20f1.png)


