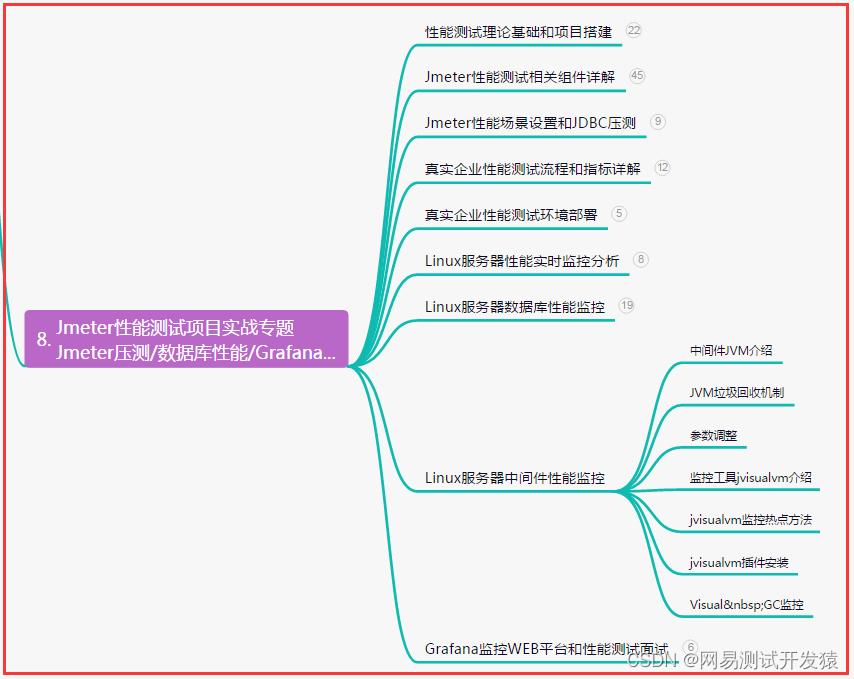
目录
项目说明
题目一:Top5热门品类
题目二:Top5热门品类中每个品类的Top5活跃Session统计
scala实现
新建maven项目结构如下
配置pom.xml文件
scala代码
python实现
项目说明
本项目的数据是采集电商网站的用户行为数据,主要包含用户的4种行为:搜索、点击、下单和支付。需求说明:品类是指产品的分类,大型电商网站品类分多级,咱们的项目中品类只有一级,不同的公司可能对热门的定义不一样。我们按照每个品类的点击、下单、支付的量来统计热门品类。
数据格式如下:

| 编号 | 字段名称 | 字段类型 | 字段含义 |
| 1 | date | String | 用户点击行为的日期 |
| 2 | user_id | Long | 用户的ID |
| 3 | session_id | String | Session的ID |
| 4 | page_id | Long | 某个页面的ID |
| 5 | action_time | String | 动作的时间点 |
| 6 | search_keyword | String | 用户搜索的关键词 |
| 7 | click_category_id | Long | 点击某一个商品品类的ID |
| 8 | click_product_id | Long | 某一个商品的ID |
| 9 | order_category_ids | String | 一次订单中所有品类的ID集合 |
| 10 | order_product_ids | String | 一次订单中所有商品的ID集合 |
| 11 | pay_category_ids | String | 一次支付中所有品类的ID集合 |
| 12 | pay_product_ids | String | 一次支付中所有商品的ID集合 |
| 13 | city_id | Long | 城市 id |
题目一:Top5热门品类
需求:品类是指产品的分类,大型电商网站品类分多级,咱们的项目中品类只有一级,不同的公司可能对热门的定义不一样。我们按照每个品类的点击、下单、支付的量来统计热门品类。本项目需求为:先按照点击数排名,靠前的就排名高;如果点击数相同,再比较下单数;下单数再相同,就比较支付数。输出结果如下:

- 通过使用groupby实现,Top5热门品类,将聚合后的数据排序,取前5名
- 通过使用reduceByKey实现,Top5热门品类,将聚合后的数据排序,取前5名
题目二:Top5热门品类中每个品类的Top5活跃Session统计
需求:对于排名前5的品类,分别获取每个品类点击次数排名前5的sessionId。(注意: 这里我们只关注点击次数,不关心下单和支付次数)这个就是说,对于top5的品类,每一个都要获取对它点击次数排名前5的sessionId。这个功能,可以让我们看到,对某个用户群体最感兴趣的品类,各个品类最感兴趣最典型的用户的session的行为。
- 输出结果

scala实现
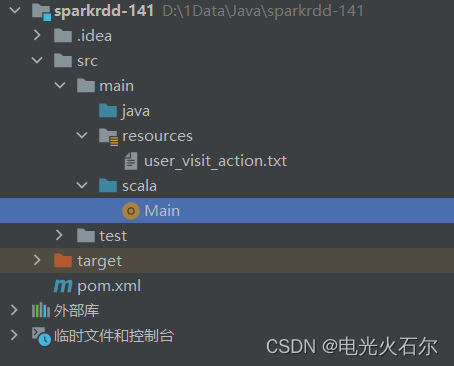
新建maven项目结构如下
配置pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>sparkrdd-141</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<scala.version>2.11.8</scala.version>
<spark.version>2.1.0</spark.version>
</properties>
<dependencies>
<!-- Spark Core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Scala 标准库 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
</dependencies>
</project>scala代码
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.storage.StorageLevel
object Main {
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val conf = new SparkConf().setMaster("local[*]").setAppName("WordCountHelloWorld")
val sc = new SparkContext(conf)
// 加载数据
val rdd01 = sc.textFile("src/main/resources/user_visit_action.txt")
val rdd02 = rdd01.map(_.split("_"))
val rdd03 = rdd02.map(x => x.slice(6, x.length)) // ['-1', '-1', 'null', 'null', 'null', 'null', '18'], ['9', '51', 'null', 'null', 'null', 'null', '6']
// 过滤点击、订单和支付数据
val click_RDD = rdd03.filter(_(0) != "-1")
val order_RDD = rdd03.filter(_(2) != "null")
val pay_RDD = rdd03.filter(_(4) != "null")
// ==================================================================================================================
// 题目1
// 使用groupBy
val click_RDD11 = click_RDD.map(x => (x(0), 1))
val click_RDD12 = click_RDD11.groupBy(_._1)
val click_RDD13 = click_RDD12.mapValues(_.map(_._2).sum)
// println(click_RDD13.collect())
val order_RDD11 = order_RDD.flatMap(x => x(2).split(','))
val order_RDD12 = order_RDD11.map(x => (x, 1))
val order_RDD13 = order_RDD12.groupBy(_._1)
val order_RDD14 = order_RDD13.mapValues(_.map(_._2).sum)
// println(order_RDD14.collect())
val pay_RDD11 = pay_RDD.flatMap(x => x(4).split(','))
val pay_RDD12 = pay_RDD11.map(x => (x, 1))
val pay_RDD13 = pay_RDD12.groupBy(_._1)
val pay_RDD14 = pay_RDD13.mapValues(_.map(_._2).sum)
// println(pay_RDD14.collect())
val end_RDD10 = click_RDD13.join(order_RDD14).join(pay_RDD14) // ('16', ((5928, 1782), 1233)), ('19', ((6044, 1722), 1158)),
val end_RDD11 = end_RDD10.map(x => (x._1.toInt, x._2._1._1, x._2._1._2, x._2._2))
// 缓存一下
// end_RDD11.cache()
end_RDD11.persist(StorageLevel.DISK_ONLY)
// 法1 使用top
val end_RDD_top = end_RDD11.top(5)(Ordering[(Int, Int, Int)].on(x => (x._2, x._3, x._4)))
println('\n' + end_RDD_top.mkString("\n"))
// 法2 使用sortBy
val end_RDD_sort = end_RDD11.sortBy(x => (-x._2, -x._3, -x._4))
println('\n' + end_RDD_sort.take(5).mkString("\n"))
// ==================================================================================================================
// 题目2
// reduceByKey实现
// 点击
val click_RDD01 = click_RDD.map(x => (x(0), 1))
val click_RDD02 = click_RDD01.reduceByKey(_ + _)
// println('\n' + click_RDD02.collect())
// 订单
val order_RDD01 = order_RDD.flatMap(x => x(2).split(','))
val order_RDD02 = order_RDD01.map(x => (x, 1))
val order_RDD03 = order_RDD02.reduceByKey(_ + _)
// println('\n' + order_RDD03.collect())
// 支付
val pay_RDD01 = pay_RDD.flatMap(x => x(4).split(','))
val pay_RDD02 = pay_RDD01.map(x => (x, 1))
val pay_RDD03 = pay_RDD02.reduceByKey(_ + _)
// println('\n' + pay_RDD03.collect())
val end_RDD = click_RDD02.join(order_RDD03).join(pay_RDD03)
val end_RDD01 = end_RDD.map(x => (x._1.toInt, x._2._1._1, x._2._1._2, x._2._2))
// 缓存一下
// end_RDD01.cache()
end_RDD01.persist(StorageLevel.DISK_ONLY)
// 法1 使用top
val end_RDD02 = end_RDD01.top(5)(Ordering[(Int, Int, Int)].on(x => (x._2, x._3, x._4)))
println('\n' + end_RDD02.mkString("\n"))
// 法2 使用sortBy
val end_RDD03 = end_RDD01.sortBy(x => (-x._2, -x._3, -x._4))
println('\n' + end_RDD03.take(5).mkString("\n"))
// ==================================================================================================================
// 题目3
// 过滤出top5点击品类id 中的会话id
val list_clickID_top = end_RDD_top.map(_._1).toList
println(list_clickID_top)
val session_RDD = rdd02.map(x => (x(6), x(2)))
val session_RDD01 = session_RDD.filter(x => list_clickID_top.contains(x._1.toInt))
// 构造 (clickid_sessionid,1)
val session_RDD02 = session_RDD01.map(x => (x._1 + "_" + x._2, 1))
// 聚合
val session_RDD03 = session_RDD02.reduceByKey(_ + _)
// 构造 (clickid,(sessionid,sum))
val session_RDD04 = session_RDD03.map(x => (x._1.split("_"), x._2)).map(x => (x._1(0), (x._1(1), x._2)))
// 根据clickid分组
val session_RDD05 = session_RDD04.groupBy(_._1)
// 排序取Top5热门品类中每个品类的Top5活跃Session统计
val sorted_rdd = session_RDD05.mapValues(x => x.toList.sortBy(_._2._2).reverse.take(5))
val sorted_rdd2 = sorted_rdd.mapValues(x => x.map(_._2))
sorted_rdd2.foreach(x => println("(" + x._1 + ", " + x._2.toList + ")"))
// println(sorted_rdd.collect())
// val session_RDD06 = session_RDD05.map(x => (x._1, x._2.toList)).mapValues(x => (x.sorted(Ordering.by((_: (String, Int))._2).reverse).take(5))) // [('12', ('6502cdc9-cf95-4b08-8854-f03a25baa917', 1)),
// println(sorted_rdd.collect())
}
}
python实现
from pyspark import SparkConf, SparkContext, StorageLevel
if __name__ == '__main__':
conf = SparkConf().setSparkHome('spark_hw').setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd01 = sc.textFile(r"D:\TASK\PythonProject\pythonSpark\01_RDD\user_visit_action.txt")
rdd02 = rdd01.map(lambda x: x.split('_'))
rdd03 = rdd02.map(lambda x: x[
6:]) # ['-1', '-1', 'null', 'null', 'null', 'null', '18'], ['9', '51', 'null', 'null', 'null', 'null', '6']]
click_RDD = rdd03.filter(lambda x: x[0] != '-1')
order_RDD = rdd03.filter(lambda x: x[2] != 'null')
pay_RDD = rdd03.filter(lambda x: x[4] != 'null')
# ==================================================================================================================
# reduceByKey实现
# 点击
click_RDD01 = click_RDD.map(lambda x: (x[0], 1))
click_RDD02 = click_RDD01.reduceByKey(lambda sum1, x: sum1 + x)
# print('\n', click_RDD02.collect())
# 订单
order_RDD01 = order_RDD.flatMap(lambda x: x[2].split(','))
order_RDD02 = order_RDD01.map(lambda x: (x, 1))
order_RDD03 = order_RDD02.reduceByKey(lambda sum1, x: sum1 + x)
# print('\n', order_RDD03.collect())
# 支付
pay_RDD01 = pay_RDD.flatMap(lambda x: x[4].split(','))
pay_RDD02 = pay_RDD01.map(lambda x: (x, 1))
pay_RDD03 = pay_RDD02.reduceByKey(lambda sum1, x: sum1 + x)
# print('\n', pay_RDD03.collect())
end_RDD = click_RDD02.join(order_RDD03).join(
pay_RDD03) # ('16', ((5928, 1782), 1233)), ('19', ((6044, 1722), 1158)),
end_RDD01 = end_RDD.map(lambda x: (int(x[0]), x[1][0][0], x[1][0][1], x[1][1]))
# 缓存一下
# end_RDD01.cache()
end_RDD01.persist(StorageLevel.DISK_ONLY)
# 法1 使用top
end_RDD02 = end_RDD01.top(5, key=lambda x: (x[1], x[2], x[3]))
print('\n', end_RDD02)
# 法2 使用sortBy
end_RDD02 = end_RDD01.sortBy(lambda x: (-x[1], -x[2], -x[3]))
print('\n', end_RDD02.take(5))
# ==================================================================================================================
# 使用sortBy
click_RDD11 = click_RDD.map(lambda x: (x[0], 1))
click_RDD12 = click_RDD11.groupBy(lambda x: x[0])
click_RDD13 = click_RDD12.mapValues(lambda x: sum(i for j, i in x))
# print(click_RDD13.collect())
order_RDD11 = order_RDD.flatMap(lambda x: x[2].split(','))
order_RDD12 = order_RDD11.map(lambda x: (x, 1))
order_RDD13 = order_RDD12.groupBy(lambda x: x[0])
order_RDD14 = order_RDD13.mapValues(lambda x: sum(i for j, i in x))
# print(order_RDD14.collect())
pay_RDD11 = pay_RDD.flatMap(lambda x: x[4].split(','))
pay_RDD12 = pay_RDD11.map(lambda x: (x, 1))
pay_RDD13 = pay_RDD12.groupBy(lambda x: x[0])
pay_RDD14 = pay_RDD13.mapValues(lambda x: sum(i for j, i in x))
# print(pay_RDD14.collect())
end_RDD10 = click_RDD13.join(order_RDD14).join(
pay_RDD14) # ('16', ((5928, 1782), 1233)), ('19', ((6044, 1722), 1158)),
end_RDD11 = end_RDD10.map(lambda x: (int(x[0]), x[1][0][0], x[1][0][1], x[1][1]))
# 缓存一下
# end_RDD11.cache()
end_RDD11.persist(StorageLevel.DISK_ONLY)
# 法1 使用top
end_RDD_top = end_RDD11.top(5, key=lambda x: (x[1], x[2], x[3]))
print('\n', end_RDD_top)
# 法2 使用sortBy
end_RDD_sort = end_RDD11.sortBy(lambda x: (-x[1], -x[2], -x[3]))
print('\n', end_RDD_sort.take(5))
# ==================================================================================================================
# 过滤出top5点击品类id 中的会话id
list_clickID_top = [x[0] for x in end_RDD_top]
print(list_clickID_top)
session_RDD = rdd02.map(lambda x: (x[6], x[2]))
session_RDD01 = session_RDD.filter(lambda x: int(x[0]) in list_clickID_top)
# 构造 (clickid_sessionid,1)
session_RDD02 = session_RDD01.map(lambda x: (x[0] + '_' + x[1], 1))
# 聚合
session_RDD03 = session_RDD02.reduceByKey(lambda sum1, x: sum1 + x)
# 构造 (clickid,(sessionid,sum))
session_RDD04 = session_RDD03.map(lambda x: (x[0].split('_'), x[1])).map(lambda x: (x[0][0], (x[0][1], x[1])))
# 根据 clcikid分组
session_RDD05 = session_RDD04.groupBy(lambda x: x[0])
session_RDD05.cache()
session_RDD05.foreach(print)
# for i in session_RDD05.collect():
# for j in i:
# print(list(j))
# session_RDD05.saveAsTextFile("../my.txt")
# x为迭代器对象 y为迭代器对象中的每一个元素
sorted_rdd = session_RDD05.mapValues(lambda x: sorted(x, key=lambda y: y[1][1], reverse=True)[:5])
sorted_rdd = sorted_rdd.mapValues(lambda x: (j for i, j in x))
# modified_rdd = sorted_rdd.mapValues(lambda values: [y for _, y in values])
sorted_rdd.foreach(lambda x: print("(", x[0], list(x[1]), ")"))
# print(sorted_rdd.collect())
# session_RDD06 = session_RDD05.map(lambda x: (x[0], list(x[1]))).mapValues(lambda x: (sorted(-i[1][1] for i in x)[:5])) # [('12', ('6502cdc9-cf95-4b08-8854-f03a25baa917', 1)),
# print(sorted_rdd.collect())