在前面几章中,我们下载的静态网页总是返回相同的内容。而在本章中,我们将与网页进行交互 根据用户输入返回对应的内容。本章将包含如下几个主题:
发送 POST 请求提交表单:
使用 cookie 登录网站:
用于简化表单提交的高级模块Mechanize。

想要和表单进行交互,就需要拥有可以登录网站的用户账号。现在我们需要手工注册账号,其 网址为http://example.webscraping.com/user/register。本章目前还无法自动化注册表单,不过在下一章我们会介绍处理验证码问题的方法,从而实现自动化表单注册。
6.1登录表单
我们最先要实施 自 动化提交的 是登录表单 , 其网址为 http : / / exampl e . webscraping . com/user/ l ogin o 要想理解该表单 , 我们需要用 到 Firebug Lite 。 如果使用完整版的 Firebug 或者 Chrome 的 开发者工具 , 我们只需要提 交表单就可 以在 网 络选项卡 中检查传输的 数据 。 但是 , Lite 版本 限制我们只 能查看结构 ,如下图所示
①

上图中包括几个重要组成部分,分别是form标签的action...enctype 和method属性,以及两个 input域。action属性用于设置表单数据提交的地址,本例中为#,也就是和登录表单相同的URL。 enctype属性用于设置数据提交的编码,本例中为 application/x-www- form-urlencoded。而me thod 属性被设为 post,表示通过请求体向服务器端提交表单数据。对于input标签,重要的属性是 name,用于设定提交到服务器端时某个域的名称。

当普通用户通过浏览器打开该网页时,需要输入邮箱和密码,然后单击登录按钮将数据提交到服务端。如果登录成功,则会跳转到主页:否则,会跳转回登录页。下面是尝试自动化处理该流程的初始版本代码。
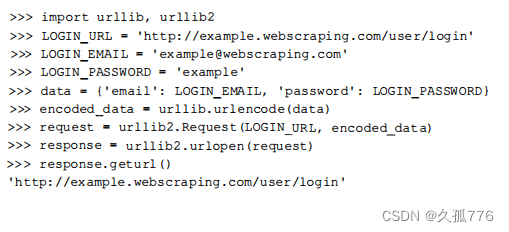
上述代码中,我们设置了邮箱和密码域,并将其进行了urlencode编码,然后将这些数据提交到 服务器端。当执行最后的打印语句时,输出的依然是登录页的U阻,也就是说登录失败了。
这是因 为登录表单十分严格 , 除 邮箱和密码外 , 还需要提交另外几个域。
我们可以从图①的最下方找到这几个域不过由于设置为 hidden,所以不会在浏览器中显示出来。为了访问这些隐藏域,下面使用第2章中介绍的工xml库编写一个函数,提取表单中所有input 标签的详情。

上述代码使用 lxml 的 css 选择器遍历表单中所有的妇 put 标签,然后以字典的形式返回其中的 name和value属性。对登录页运行该函数后,得到的结果如下所示。
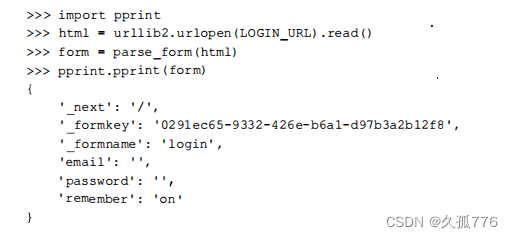
其 中,_f ormkey属性是这里的关键部分,服务器端使用这个唯一的ID来避免表单多次提交。每次加载网页时,都会产生不同的ID,然后服务器端
就可以通过这个给定的ID来判断表单是否己经提 交过。下面是提交了_formkey及其他隐藏域的新版本登录代码。
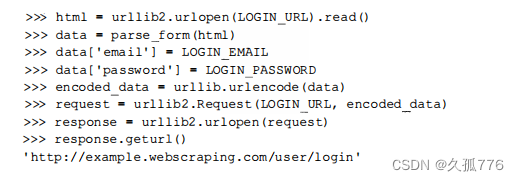
很遗憾,这个版本依然不能正常工作,运行时还是会打印出登录URL。这是因为我们缺失了一个重要的组成部分一一
cookie。当普通用户加载登录表单时_formkey的值将会保存在cookie中,然后该值会与提交的登录表单数据中的_formkey值进行对比。下面是使用urllib2.HTTPCookie Process or 类增加了cookie支持之后的代码。
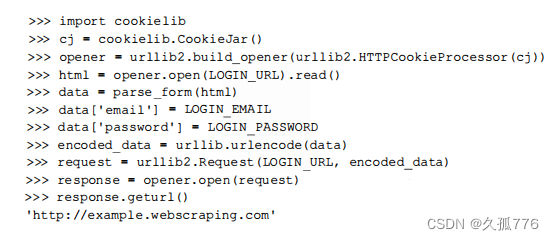

这次我们终于成功了!服务器端接受了我们提交的表单值,response的U也
是主页。该代码片段以及本章中其他登录示例代码都可以从https
:
//bitbucket.org/wswp/code/src/tip/chapter06/login.py 获取。
6.1.1从浏览器加载cookie
从前面的例子可以看出,如何向服务器提交它所需的登录信息,有时候会很复杂。幸好,对于这种麻烦的网站还有一个变通方法,即先在浏览器中手工执行登录,然后在Python脚本中复用之前得 到的cookie,从而实现自动登录。不同浏览器采用不同的格式存储 cookie ,这里我们仅以Firefox 浏览器为例。
Firefox在sqlite数据库中存储cookie,在JSON文件中存储session,这两种存储方式都可以直接通过Python获取。对于登录操作来说,我们只需要获取session,其存储结构如下所示。

下面是把 session 解析到 Cookie Ja r 对象的函数代码 。


这里有一个比较麻烦的地方:不同的操作系统中,Firef
ox存储session文件的位置不同。在 Linux 系统中,其路径如下所示。
~I.mozilla/firefox/*.default/se.ssionstore.js
在OSX中,其路径如下所示。
~/Library/ApplicationSupport/Firefox/Profiles/*.default/sessionstore.js
而在WindowsVista及以上版本系统中,其路径如下所示。
%APPDATA%/Roaming/Mozilla/Firefox/Profiles/*.default/sessionstore.js
下面是返回session文件路径的辅助函数代码。

需要注意的是,这里使用的glob模块会返回指定路径中所有匹配的文件。下面是修改后使用浏览器cookie登录的代码片段。

要检查session是否加载成功这次我们无法再依靠登录跳转了这时我们需要抓取产生的 HTML, 检查是否存在登录用户标签。如果得到的结果是Login,则说明session没能正确加载。如果出现这种情况,你就需要确认一下Firefox中是否已经成功登录示例网站。如下图所示为Firebug中显示的用户标签结构。
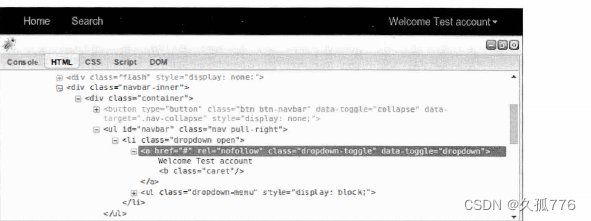
Firebug中显示该标签位于ID为“navbar”的<ul>标签中我们可以使用第2章中介绍的lxml库抽取其 中的信息 。
>>> tree = lxml.html . fromstring (html)
>>> tree . cssselect (’ul#navbar li a’) [O] . text_conte口t ()
Welcome Test account
本节中的代码非常复杂,而且只支持从Firefox浏览器中加载session。如果你想支持其他浏览器的 cookie,可以使用browsercookie模块。该模块可以通过pip install browsercookie 命令进行安装,其文档地址为https://pypi.python.org/pypi/browsercookie。
6.2 支持内容更新的登录脚本扩展
自动化登录成功运行后,我们还可以继续扩展该脚本,使其与网站进行交互,更新国家数据。 本节中使用的代码可以从https://bitbucket.org/wswp/code/src/t ip/chapter06/edit.py获取。如下图 所示,每个国家页面底部均有
一
个
Edit
链接。
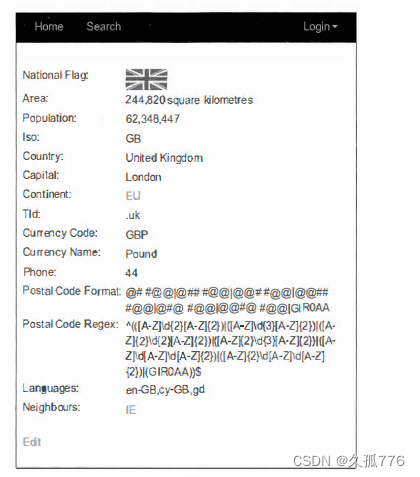
在登录情况下,该链接会指向另一个页面,在该页面中所有国家属性都可以进行编辑,如下图 所示。
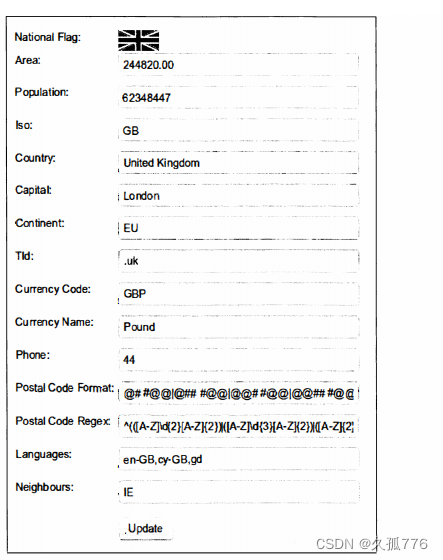
这里我们编写一个脚本,每次运行时都会使该国家的人口数量加1。首先是复用parseform( ) 函数,抽取国家人口数量的当前值。

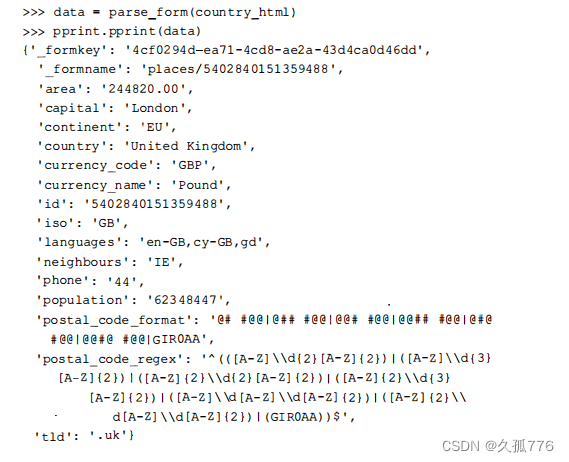
然后为人口数量加1,并将更新提交到服务器端。

当我们再次回到国家页时,可以看到人口数量己经增长到62,348,448,如图

读者可以对任何字段随意进行修改和测试,因为网站所用的数据库每个小时都会将国家数据恢复为初始值,以保证数据正常。本节中使用的代码可以从https://bitbucket.org/wswp/code/ src/tip/chapter06/edit.py获取。需要注意的是,严格来说,本例并不算是网络爬虫,而是广义上的 网络机器人。不过,这里使用的表单技术可以应用于抓取时的复杂表单交互当中。
6.3 使用Mechanize模块实现自动化表单处理
尽管我们的例子现在已经可以正常运行,但是可以发现每个表单都需要大量的工作
和测试。我们可以使用Mechanize模块减轻这方面的工作,该模块提供了与表单交互的高级接口。Mechanize 可 以通过 pip 命令进行安装。
pip install mechanize
下面是使用Mechanize 实现前面的人数量增长示例的代码。
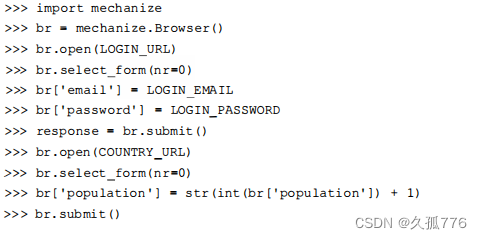
这段代码比之前的例子要简单得多,因为我们不再需要管理 cookie,而且访问表单输入框也更加容易。该脚本首先创建一个 Mechanize 浏览器对象,然后定位到登录 URL,选择登录表单我们可以直接向浏览器对象传递名称和值,来设置选定表单的输入框内容。调试时,我们可以直接调用 br.form,获取提交之前的表单状态,如下面的代码所示。
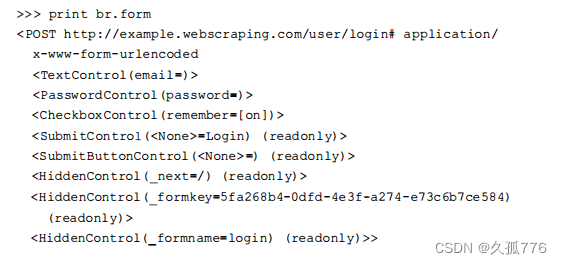
设定好登录表单的参数之后,调用br.submit( )提交选定的登录表单,然后脚本就处于登录态 了。现在,定位到国家的编辑页面,继续使用表单界面增加人口数量。需要注意的是,人口数量的输入框需要字符串类型的值,否则Mechanize会抛出TypeError异常。
要检查上面的代码是否运行成功,可以使用 Mechanize 返回到国家表单,查询当前的人口数量 如下所示。

和预期一样,人口数量再次增加,现在是62,348,449。

6.4 本章小结
在抓取网页时,和表单进行交互是一个非常重要的技能。本章介绍了两种交互方法:第一种是分析表单,然后手工生成期望的 POST请求:第二种则是直接使用高级模块Mechanize。