文章目录
- 一、前言
- 二、选择题(10 X 2')
- 1、补充
- 2、第一梯队⭐⭐⭐
- 3、第二梯队⭐⭐
- 4、第三梯队⭐
- 三、判断题(10 X 1')
- 1、错误的
- 2、正确的
- 四、程序填空题(10 X 3')
- 1、tensorflow搭建模型
- 2、keras模型编译
- 3、Pytorch的cat()函数操作
- 4、 keras函数使用ReLU激活函数
- 5、OpenCV 实现图像固定國值分割【P167】
- 6、keras搭建YOLOv3与CNN模型
- 五、简答题(4 X 5')
- 1、卷积层和池化层作用
- 2、模型的健壮性
- 3、Inception架构
- 4、YOLOV3和YOLOV2相比
- 5、生成对抗网络(GAN)含义
- 六、编程题(1 X 20')
- 1、训练卷积神经网络
一、前言
小时候最喜欢的一集😿 内容比较多,有点小难捏

二、选择题(10 X 2’)
1、补充
题目很多,基本上齐全了,列了三个梯队,重点看⭐⭐⭐,其余两队有印象即可 😆
2、第一梯队⭐⭐⭐
1、一般的多层感知器不包含哪种类型层次的神经元 (
卷积层)
2、以下关于Sigmoid的特点说法错误的是 (Sigmoid函数计算量小)
3、下列不属于数据增强作用的是(避免欠拟合)
4、假设一个卷积神经网络,第一个全连接层前的池化层输出为7x7x250,其展开的向量长度为?(12250)
【变式】如果改为12x12x250,则(36000)👉就是全部相乘
5、下面哪个条件能证明模型健壮性好(背景干扰、有遮挡、光照不同)
6、以下关于目标检测算法的论述错误的是(rcnn、fast-rcnn、faster-rcnn算法都需要额外的selective search模块来捕获候选框)
7、分水岭图像分割法属于哪一类分割方法(基于区域的分割方法)
8、下面关于深度学习网络结构的描述,正确的说法是哪个?(深层网络结构中,学习到的特征一般与神经元的参数量有关,也与样本的特征多寡相关)
9、下面关于 GRU 模型说法错误的是(上一时刻隐藏状态和候选信息做一个线性组合,二者的权重大小分别为 0.5,权重之和为 1)
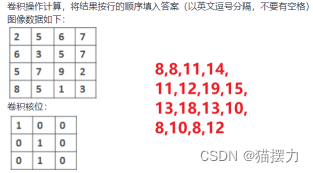
10、写出卷积操作后第二行的数据为(11,12,19,15)
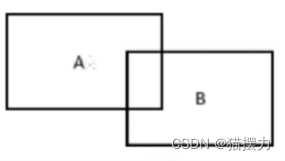
11、IoU是目标检测领域中的结果评测指标之一,上图中A框是物体的真实标记框,面积为9。B框是网络的检测结果,面积为6。两个框的重合区域面积为2。则IoU的值为(2/13)
12、现使用YOLO 网络进行目标检测,待检测的物体种类为10种,输入图像被划分成13*13个格子,每个格子生成2个候选框,则YOLO 网络最终的全连接层输出维度为(3380)
【注】13X13X(5X2+10)=13X13X20=3380
这题应该不考,主要是YOLO,you only look once(你只能看一眼 👀),因为再看一眼就会爆炸 😹
13、在tensorflow中,以下定义常量的方法正确的是(a=tf.constant(2))
14、下面哪项不属于人工智能的应用(扫码支付)
15、引入了条件变量的是下列哪个GAN?(CGAN)
16、下面哪个不是GAN的应用? (百度翻译)
3、第二梯队⭐⭐
1、下面哪项跟近年来人工智能高速发展的原因有关(
互联网技术、云计算、大数据)
2、(分类)不属于无监督学习任务。
3、以下关于Tensorflow中张量的描述不正确的是(带小数点的数会被默认为int16类型)
4、下列不属于数据增强方法的是(直接复制)
5、GooleNet中的辅助分类器作用是(避免梯度消失)
6、InceptionV1架构中,1*1卷积层的主要作用是(防止梯度消失)
7、关于ResNet描述错误的是(可以通过不断加深网络层数来提高分类性能)
8、在 LSTM 的遗忘门中如何进行细胞状态的更新?(将需要忘记的信息与旧的状态进行乘积)
9、从一篇文章中提取一段话用来概括性描述这篇文章的技术属于(自动文摘)
10、对同一个单词的不同形式进行识别并还原的过程称为(词形还原)
4、第三梯队⭐
1、以下关于感知器的说法错误的是(
单层感知器可以用于处理非线性学习问题)
2、以下关于学习率说法错误的是(学习率【必须是固定不变】的)
3、关于BP算法特点描述错误的是 (计算之前【不需要】对训练数据进行归一化)
4、以下有关卷积神经网络的说法,哪个是错误的?(卷积核中的取值都是事先人工设计的,在网络的训练过程中【不变化】)
5、下列关于双向 RNN 说法正确的是(双向 RNN 的结构与单向 RNN 的结构相似,都连着输出层,但是会比单向RNN 多出两个隐藏层)
6、有关生成器和判别器的交叉嫡代价函数,以下哪个说法是错误的?(当训练生成器时,希望判别器的输出越逼近0越好)
7、下列关于生成对抗网络的描述错误的是(既然生成对抗网络是无监督模型,则【不需要】任何训练数据)
三、判断题(10 X 1’)
1、错误的
看看错的有哪些就行 ,有的(一眼假)我就做了个分类🙂
1、跨物种语义级别的图像分类,类间方差小,因此一般要求图像分辨率高。
(X)
2、两步走"类算法都是先识别再选择候选区域。 (X)
3、矩阵运算中的矩阵乘法满足交换律。 (X)
4、感知器模型中用到的激活函数通常是线性的。 (X)
5、R-CNN在做候选框选择这一步的时候是使用卷积神经网络做的。 (X)
6、用于预测的新数据可以从训练数据中获取。 (X)
7、在训练数据集上模型执行的很好,说明是个好模型。 (X)
8、感知器可以解决二次函数型的回归预测问题。 (X)
9、在keras中训练模型可以使用model.train()方法。 (X)
10、VGG16网络有16层卷积层。 (X)【注】:是13层
11、智能体下一时刻的状态不仅与当前状态有关,还与上一时刻状态有关。(X)
12、Inception架构是VGG16网络的核心架构。(X)
下面的一眼假😮
1、卷积神经网络使用的都是局部连接,
没有全连接。(X)
2、用于分类的数据集,不同类别数据数量相差很大不会对模型产生影响(X)
3、神经网络的层数越多,在数据集上的表现就越好。(X)
4、循环神经网络的反向误差会随着层数的增加而增加。(X)
5、自动驾驶只是一种简单的模拟人类驾驶的技术,不属于人工智能。(X)
6、运算能力的高低对人工智能影响很小。(X)
7、人工智能技术可以做到车辆的精确识别,永远不会出错。(X)
8、机器学习只有监督学习一种方法。(X)
9、一个感知器单元可以接收多个输入但只能产生一个输出给下一层的感知器。(X)
10、在神经网络的训练过程中,学习率设置的越大越好。(X)
11、模型评估只需要输入测试数据即可,不需要标签。(X)
12、卷积神经网络使用的都是局部连接,没有全连接。(X)
13、用于分类的数据集,不同类别数据数量相差很大不会对模型产生影响(X)
14、YOLOv2中没有使用锚框。(X)
15、YOLOv1中可以进行多尺寸图片训练。 (X)
2、正确的
正确的瞅一眼就行🙄
1、人工智能主要涉及的数学理论有线性代数、微积分、概率论和数理统计等(√)
2、局部响应归一化可以让相应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强模型的泛化能力。(√)
3、Inception架构是通过增加网络宽度来提高网络准确率的。(√)
4、ReLU激活函数是一种常见的激活函数,它的特性是:当输入值x小于0时,输出值y是0(√)
5、keras中加载训练、测试数据用的函数是load_data()。(√)
6、反向传播算法其实是将输出层的损失,从输出层往后传播逐步分配给各个层,并用梯度下降算法对各个层的权重参数进行更新。(√)
7、CPU模型训练运行速度不如GPU,是因为CPU单元不能同时运算,有的需要负责控制,有的负责缓存。(√)
8、人工智能之所以能在近年来掀起新一轮高潮,主要是因为三大驱动要素:算法、大数据、运算能力。(√)
9、淘宝会根据我们以前的购物的喜好推荐其他产品,也是人工智能的一种应用。(√)
10、深度学习可以说是机器学习的一个子集,机器学习是人工智能的一个子集。(√)
11、神经网络的输入层和输出层中神经元个数往往是固定的,在问题和数据集输入确定以后,输入层和输出层的神经元个数往往也就确定下来了,而隐藏层中的神经元个数可以人为改变。(√)
12、反向传播算法其实是将输出层的损失,从输出层往后传播逐步分配给各个层,并用梯度下降算法对各个层的权重参数进行更新。(√)
13、梯度下降算法是一种常用的优化器。(√)
14、使用Anaconda可以方便的管理多python编程环境,尤其是在CPU和GPU版本算法环境进行切换时非常方便。(√)
15、局部响应归一化可以让相应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强模型的泛化能力。(√)
16、加入dropout层可以防止模型过拟合(√)
17、Inception架构是通过增加网络宽度来提高网络准确率的。(√)
18、Fast R-CNN 算法中使用 Softmax 替代 SVM 进行分类。(√)
四、程序填空题(10 X 3’)
1、tensorflow搭建模型
使用tensorflow的高阶API—keras搭建模型,请将下面代码补充完整
#创建一个Sequential模型
model=tf.keras. Sequential()
#创建一个全连接层,神经元个数为368,输入神经元个数为784,激活函数为sigmoid
model.add(tf.keras.layers.Dense(368,activation=‘sigmoid’,input_dim=784))
2、keras模型编译
使用keras对模型进行编译,请将下列代码补充完整
optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001)
lossfunction=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[tf.keras.metrics.sparse_categorical_accuracy]
model.compile(optimizer、 lossfunction、metrics)
这题没啥意义…把上面出现的三单词填进来 🥱
3、Pytorch的cat()函数操作
a=torch.rand((5,4))
b=torch.rand((5,4))
c=torch.cat((a,b),dim=1)
d=torch.cat((a,b),dim=0)
print(c.shape)
print(d.shape)
运行结果:
torch.size([5,8])
torch.size([10,4])
记住dim=0是行,dim=1是列,这题就是说ab都是5行4列,c就是列扩展,d就是行扩展了【可能考rand、dim、reshape的空】 🥴
4、 keras函数使用ReLU激活函数
def make_generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(77256, use_bias=False, input_shape=(100,)))
#/添加批归一化层
model.add(layers.BatchNormalization ( )
model.add(layers.Reshape((7, 7, 256)))
assert model.output_shape = = (None, 7, 7, 256)
#添加转置卷积层,卷积核数量128个,卷积核大小5x5
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding=‘same’, use_bias=False))
assert model.output_shape = = (None, 7, 7, 128)
#使用LeakyReLU激活函数
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding=‘same’, use_bias=False))
assert model.output_shape = = (None, 14, 14, 64)
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding=‘same’, use_bias=False, activation=‘tanh’))
assert model.output_shape = = (None, 28, 28, 1)
return model
这题可能不考,就记这三个空罢,题目里面有对照着抄,放自己一马 🥵
5、OpenCV 实现图像固定國值分割【P167】

就记划线的地方罢,我们并不是编译器,考threshold这种函数就太初生了 😱
6、keras搭建YOLOv3与CNN模型
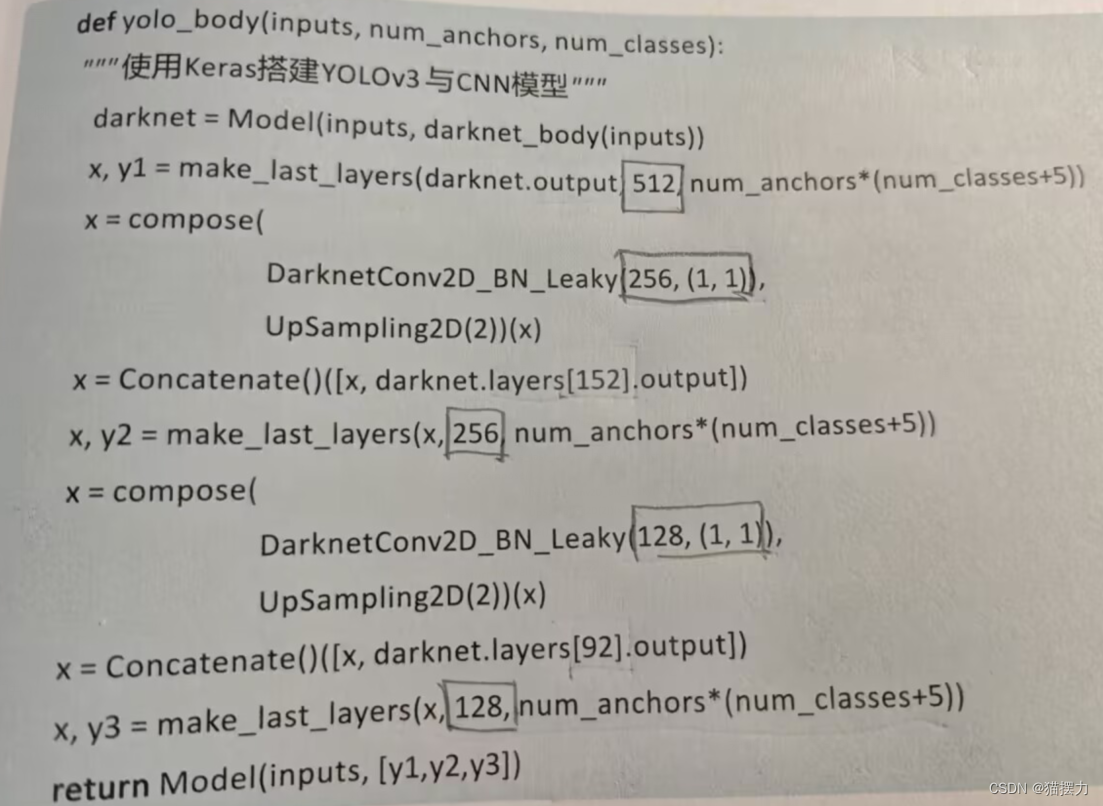
还是一样,就只看看数字的部分,如果考到的话 😥
五、简答题(4 X 5’)
1、卷积层和池化层作用
卷积神经网络结构中,卷积层和池化层的作用分别是什么?
🧐答:卷积层:运用卷积操作提取特征;
池化层:缩小特征图的尺寸,减少计算量。
2、模型的健壮性
模型的健壮性应该从哪些方面判断?至少列出4条
🧐答:不同视角、不同大小、形变、遮挡、不同光照、背景干扰、同类异形。
3、Inception架构
GoogLeNet的核心Inception架构,采用并行的方式将4个成分的运算结果在通道上组合。这4个运算分别是什么?其体现的主要思想是什么?
🧐答:①1×1卷积 ;②3×3卷积 ; ③5×5卷积 ; ④3×3池化。
Inception架构的主要思想是找出如何用密集成分来近似最优的局部稀疏结构。
4、YOLOV3和YOLOV2相比
简述YOLOV3相比于YOLOV2有哪些优点?
🧐答:一、 类别预测更加灵活,模型中用多个Sigmoid分类器,可以解决多分类问题;
二、多尺度预测,YOLOv3采用先上采样再融合,里面融合了3个尺寸,然后在多个特征图上做检测。
5、生成对抗网络(GAN)含义
简述生成对抗网络(GAN)的目标函数含义?
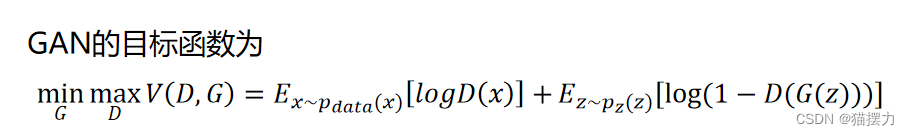
🧐答:判别器D希望尽可能区分真实样本和生成器 G生成的样本,因此希望D(x)尽可能大、 D(G(z))尽可能小,即V(D,G)尽可能大。生成器 G希望生成的样本尽可能骗过D,希望D(G(z))尽可能大,即V(D,G)尽可能小。两个模型相互对抗,最终达到全局最优。
看到简答题又活过来了,明天上午考完再背背捏 🤤
如果在简答题里放一个卷积计算题,阁下又该如何应对呢?前面选择题有的 🤡
六、编程题(1 X 20’)
1、训练卷积神经网络
使用keras搭建网络模型,使用relu激活函数

(1)创建一个Sequential模型
model = Sequential()
😎不写tf.keras.Sequential()是因为导包导了Sequential
(2)给模型添加一个卷积核大小为1X1,输入图形形状为32x32,256通道的2D卷积层(Conv2D)
model.add(Conv2D(256, (1, 1), input_shape=(32, 32, 256), activation='relu’))
(3)再添加一个卷积核大小3x3的256通道卷积层
model.add(Conv2D(256, (3, 3), activation='relu’))
(4)添加一个最大池化层
model.add(MaxPooling2D())
(5)添加一个卷积核大小为2x2的512通道卷积层,并加入最大池化层
model.add(Conv2D(512, (2, 2), activation=‘relu’))
model.add(MaxPooling2D())
(6)添加一个扁平化层
model.add(Flatten())
(7)添加一个具有196个神经元的全连接层
model.add(Dense(196))
呃呃,不清楚最后是要写整段代码还是像这样看注释写【总之,每段代码的意思我都标注出来了,大家可以开背 💪】
明天上午考完后再添加点细节,因为是今天下午写完上篇博客才开始学的,存在的不足和错误,懂哥可以嗦一嗦 🥺






![[Selenium] 通过Java+Selenium查询某个博主的Top100文章质量分](https://img-blog.csdnimg.cn/cf61ca69b9c6496a9e2e1c9f53b5ca42.png)

