之前博客介绍了如何跑通charles版本的pointNet,这篇介绍下如何来训练和预测自己的数据集,介绍如何在自己的数据集上做点云语义分割,此篇的环境配置和博客中保持一致。点云分类较简单,方法差不多,这边就不特地说明了。
一.在自己的点云数据集上做语义分割
1. RGB-D Scenes Dataset v.2数据集介绍
博主拿数据集RGB-D Scenes Dataset v.2来做实验,数据集下载链接如下:
RGB-D Scenes Dataset v.2
所下载的数据集的目录结构如下:

01.label是标注数据,01.ply是点云数据,其它类似,可看到点云和标注数据是分离开来的,这边博主手写了如下脚本来合并01.label和01.ply文件,以将label中数据作为Scalar field。脚本如下:
import numpy as np
import glob
import os
import sys
from plyfile import PlyData, PlyElement
import pandas as pd
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
ROOT_DIR = os.path.dirname(BASE_DIR)
sys.path.append(BASE_DIR)
if __name__ == "__main__":
with open(BASE_DIR + '/rgbd-scenes-v2/pc/01.ply', 'rb') as f:
plydata = PlyData.read(f)
print(len(plydata.elements[0].data))
label = np.loadtxt(BASE_DIR + '/rgbd-scenes-v2/pc/01.label')
print(label.shape)
vtx = plydata['vertex']
points = np.stack([vtx['x'], vtx['y'], vtx['z'],vtx['diffuse_red'],vtx['diffuse_green'],vtx['diffuse_blue']], axis=-1)
label = label[1:len(label)]
label = label[:,np.newaxis]
print(label.shape)
print(points.shape)
combined = np.concatenate([points, label], 1)
# current_label = np.squeeze(current_label)
print(combined.shape)
#write the points into txt
out_data_label_filename = BASE_DIR + '/01_data_label.txt'
fout_data_label = open(out_data_label_filename, 'w')
for i in range(combined.shape[0]):
fout_data_label.write('%f %f %f %d %d %d %d\n' % (combined[i,0], combined[i,1], combined[i,2], combined[i,3], combined[i,4], combined[i,5], combined[i,6],))
fout_data_label.close()这里用cloudcompare软件打开合并和的01_data_label.txt文件,显示效果如下:
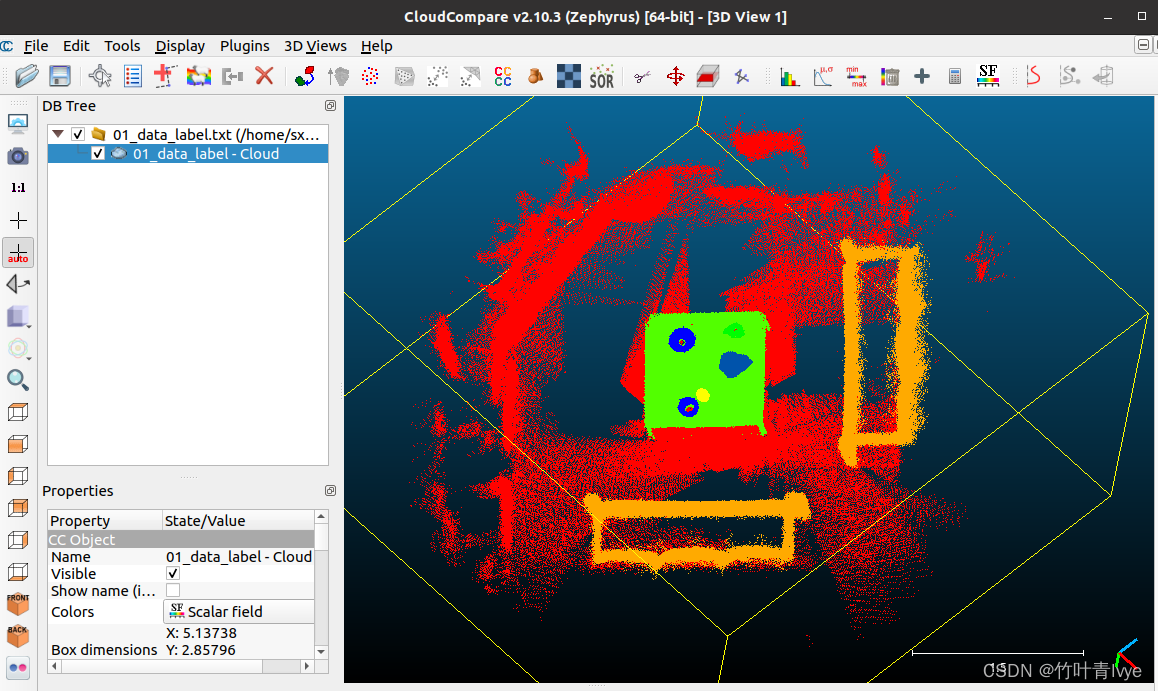
2. 新数据集生成
这边博主会对原数据集RGB-D Scenes Dataset v.2做预处理(各ply文件),生成新的数据集。
用cloudcompare打开01.ply文件,通过segment工具(小剪刀)来切割点云,获取桌子及桌子上物品点云。

裁切出的点云数据集如下

然后保存桌子点云到本地磁盘上, 其它点云文件(ply)文件类似,从中只获得桌子的点云。博主这边上传下所裁切得到的12份点云文件。
链接: https://pan.baidu.com/s/1rCDhruH_C_hpoZb5BreujA 提取码: ec0h











博主对这12份点云又做了一些裁切操作, 生成了35份点云出来,如下链接
链接: https://pan.baidu.com/s/1w0hhOhgEonxniiMOvcFsIA 提取码: 4eo6
3. 新数据集标注(35份点云)
这边博主只做3种标签,桌面像素打标签为0,书本打标签1,帽子打标签为2,杯子碗一类的打标签为3。如下是用cloudcompare给tabel01 - Cloud_1(可从如上百度网盘链接中获取文件)打标签过程。先对点云使用如上的剪刀工具,把点云分割成桌面点云和碗两部分点云,然后点击工具栏的“+”符号。
![]()
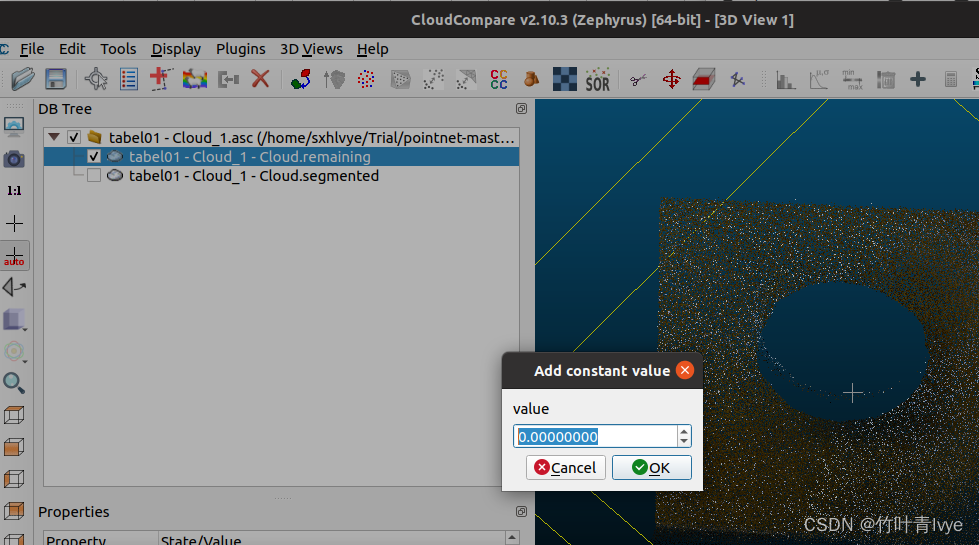
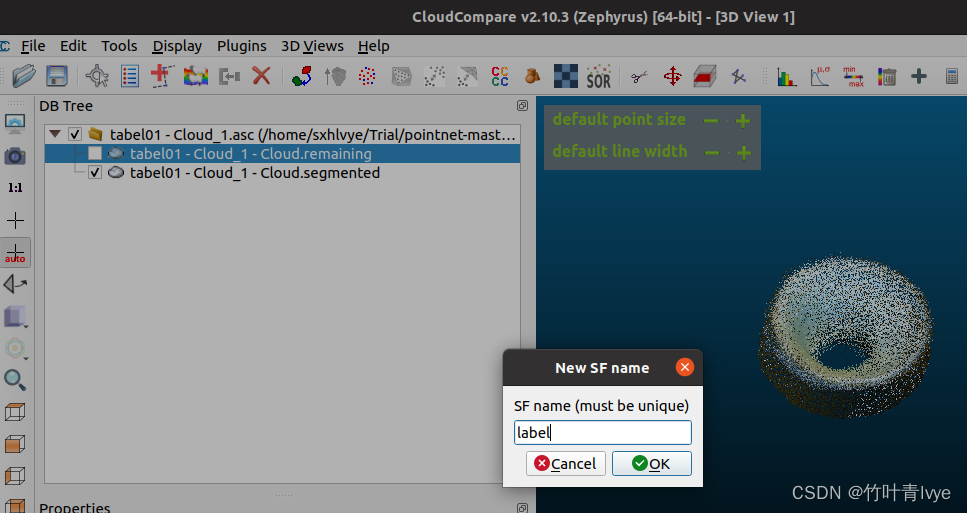

然后选中两个点云和合并


生成后点云效果如下:

如上如果点击的是Yes按钮,则合并后的点云保存的点云文件如下格式

如上如果点击No按钮,则合并后的点云保存的点云文件如下格式(这里采取这种方式保存)
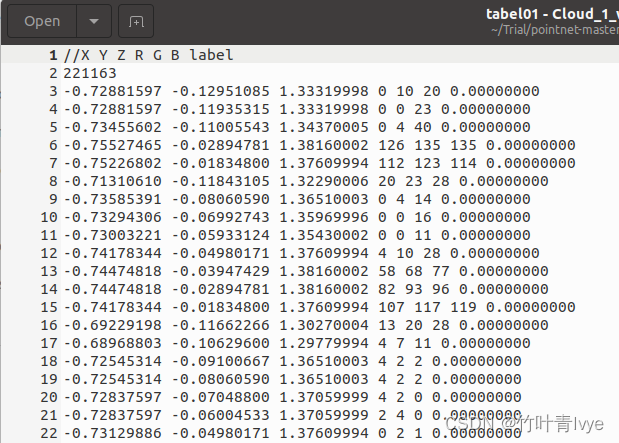
但合并后的带标注数据的点云和原点云的,点的排列顺序不一致
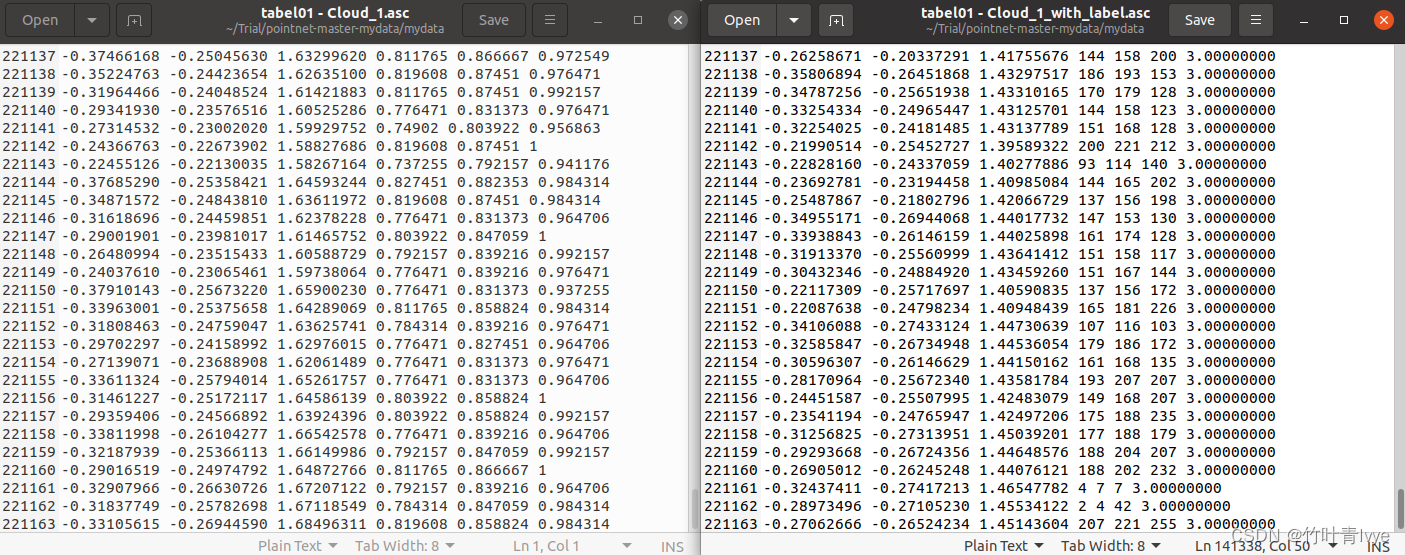
剩余34份文件都按照此方法进行标注下。博主上传下这35份带标注信息的点云文件,链接如下:
链接: https://pan.baidu.com/s/1jbVWHlVKUWcq4t9K-Yk6bQ 提取码: 4t92
4. 生成训练用的h5文件
博主这边修改了gen_indoor3d_h5.py文件,代码如下:
import os
import numpy as np
import sys
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
ROOT_DIR = os.path.dirname(BASE_DIR)
sys.path.append(BASE_DIR)
sys.path.append(os.path.join(ROOT_DIR, 'utils'))
# import data_prep_util
import indoor3d_util
import glob
import h5py
# Constants
# indoor3d_data_dir = os.path.join(data_dir, 'mydata_h5')
NUM_POINT = 4096
H5_BATCH_SIZE = 1000
data_dim = [NUM_POINT, 6]
label_dim = [NUM_POINT]
data_dtype = 'float32'
label_dtype = 'uint8'
# Set paths
# filelist = os.path.join(BASE_DIR, 'meta/all_data_label.txt')
# data_label_files = [os.path.join(indoor3d_data_dir, line.rstrip()) for line in open(filelist)]
output_dir = os.path.join(ROOT_DIR, 'data/mydata_h5')
if not os.path.exists(output_dir):
os.mkdir(output_dir)
output_filename_prefix = os.path.join(output_dir, 'ply_data_all')
output_room_filelist = os.path.join(output_dir, 'all_files.txt')
fout_room = open(output_room_filelist, 'w')
# --------------------------------------
# ----- BATCH WRITE TO HDF5 -----
# --------------------------------------
batch_data_dim = [H5_BATCH_SIZE] + data_dim
batch_label_dim = [H5_BATCH_SIZE] + label_dim
h5_batch_data = np.zeros(batch_data_dim, dtype = np.float32)
h5_batch_label = np.zeros(batch_label_dim, dtype = np.uint8)
buffer_size = 0 # state: record how many samples are currently in buffer
h5_index = 0 # state: the next h5 file to save
def save_h5(h5_filename, data, label, data_dtype='uint8', label_dtype='uint8'):
h5_fout = h5py.File(h5_filename)
h5_fout.create_dataset(
'data', data=data,
compression='gzip', compression_opts=4,
dtype=data_dtype)
h5_fout.create_dataset(
'label', data=label,
compression='gzip', compression_opts=1,
dtype=label_dtype)
h5_fout.close()
def insert_batch(data, label, last_batch=False):
global h5_batch_data, h5_batch_label
global buffer_size, h5_index
data_size = data.shape[0]
# If there is enough space, just insert
if buffer_size + data_size <= h5_batch_data.shape[0]:
h5_batch_data[buffer_size:buffer_size+data_size, ...] = data
h5_batch_label[buffer_size:buffer_size+data_size] = label
buffer_size += data_size
else: # not enough space
capacity = h5_batch_data.shape[0] - buffer_size
assert(capacity>=0)
if capacity > 0:
h5_batch_data[buffer_size:buffer_size+capacity, ...] = data[0:capacity, ...]
h5_batch_label[buffer_size:buffer_size+capacity, ...] = label[0:capacity, ...]
# Save batch data and label to h5 file, reset buffer_size
h5_filename = output_filename_prefix + '_' + str(h5_index) + '.h5'
save_h5(h5_filename, h5_batch_data, h5_batch_label, data_dtype, label_dtype)
fout_room.write('mydata_h5' + '\'' + h5_filename)
print('Stored {0} with size {1}'.format(h5_filename, h5_batch_data.shape[0]))
h5_index += 1
buffer_size = 0
# recursive call
insert_batch(data[capacity:, ...], label[capacity:, ...], last_batch)
if last_batch and buffer_size > 0:
h5_filename = output_filename_prefix + '_' + str(h5_index) + '.h5'
save_h5(h5_filename, h5_batch_data[0:buffer_size, ...], h5_batch_label[0:buffer_size, ...], data_dtype, label_dtype)
fout_room.write('mydata_h5/ply_data_all' + '_' + str(h5_index) + '.h5')
print('Stored {0} with size {1}'.format(h5_filename, buffer_size))
h5_index += 1
buffer_size = 0
return
path = os.path.join(BASE_DIR + '/mydata_withlabel', '*.asc')
files = glob.glob(path)
points_list = []
for f in files:
print(f)
points = np.loadtxt(f)
print(points.shape)
sample = np.random.choice(points.shape[0], NUM_POINT)
sample_data = points[sample,...]
print(sample_data.shape)
points_list.append(sample_data)
data_label = np.stack(points_list, axis=0)
print(data_label.shape)
data = data_label[:,:,0:6]
label = data_label[:,:,6]
print(data.shape)
print(label.shape)
sample_cnt = 0
insert_batch(data, label, True)
# for i, data_label_filename in enumerate(data_label_files):
# print(data_label_filename)
# data, label = indoor3d_util.room2blocks_wrapper_normalized(data_label_filename, NUM_POINT, block_size=1.0, stride=0.5,
# random_sample=False, sample_num=None)
# print('{0}, {1}'.format(data.shape, label.shape))
# for _ in range(data.shape[0]):
# fout_room.write(os.path.basename(data_label_filename)[0:-4]+'\n')
#
# sample_cnt += data.shape[0]
# insert_batch(data, label, i == len(data_label_files)-1)
#
fout_room.close()
# print("Total samples: {0}".format(sample_cnt))
运行结果如下:

5. 分割网络训练
修改sem_seg/train.py文件,代码如下:
import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution()
import argparse
import math
import h5py
import numpy as np
import socket
import os
import sys
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
ROOT_DIR = os.path.dirname(BASE_DIR)
sys.path.append(BASE_DIR)
sys.path.append(ROOT_DIR)
sys.path.append(os.path.join(ROOT_DIR, 'utils'))
import provider
import tf_util
from model import *
parser = argparse.ArgumentParser()
parser.add_argument('--gpu', type=int, default=0, help='GPU to use [default: GPU 0]')
parser.add_argument('--log_dir', default='log', help='Log dir [default: log]')
parser.add_argument('--num_point', type=int, default=4096, help='Point number [default: 4096]')
parser.add_argument('--max_epoch', type=int, default=500, help='Epoch to run [default: 50]')
parser.add_argument('--batch_size', type=int, default=2, help='Batch Size during training [default: 24]')
parser.add_argument('--learning_rate', type=float, default=0.001, help='Initial learning rate [default: 0.001]')
parser.add_argument('--momentum', type=float, default=0.9, help='Initial learning rate [default: 0.9]')
parser.add_argument('--optimizer', default='adam', help='adam or momentum [default: adam]')
parser.add_argument('--decay_step', type=int, default=300000, help='Decay step for lr decay [default: 300000]')
parser.add_argument('--decay_rate', type=float, default=0.5, help='Decay rate for lr decay [default: 0.5]')
parser.add_argument('--test_area', type=int, default=6, help='Which area to use for test, option: 1-6 [default: 6]')
FLAGS = parser.parse_args()
BATCH_SIZE = FLAGS.batch_size
NUM_POINT = FLAGS.num_point
MAX_EPOCH = FLAGS.max_epoch
NUM_POINT = FLAGS.num_point
BASE_LEARNING_RATE = FLAGS.learning_rate
GPU_INDEX = FLAGS.gpu
MOMENTUM = FLAGS.momentum
OPTIMIZER = FLAGS.optimizer
DECAY_STEP = FLAGS.decay_step
DECAY_RATE = FLAGS.decay_rate
LOG_DIR = FLAGS.log_dir
if not os.path.exists(LOG_DIR): os.mkdir(LOG_DIR)
os.system('cp model.py %s' % (LOG_DIR)) # bkp of model def
os.system('cp train.py %s' % (LOG_DIR)) # bkp of train procedure
LOG_FOUT = open(os.path.join(LOG_DIR, 'log_train.txt'), 'w')
LOG_FOUT.write(str(FLAGS)+'\n')
MAX_NUM_POINT = 4096
NUM_CLASSES = 4
BN_INIT_DECAY = 0.5
BN_DECAY_DECAY_RATE = 0.5
#BN_DECAY_DECAY_STEP = float(DECAY_STEP * 2)
BN_DECAY_DECAY_STEP = float(DECAY_STEP)
BN_DECAY_CLIP = 0.99
HOSTNAME = socket.gethostname()
ALL_FILES = provider.getDataFiles(ROOT_DIR + '/data/mydata_h5/all_files.txt')
# room_filelist = [line.rstrip() for line in open('indoor3d_sem_seg_hdf5_data/room_filelist.txt')]
# Load ALL data
data_batch_list = []
label_batch_list = []
for h5_filename in ALL_FILES:
data_batch, label_batch = provider.loadDataFile(ROOT_DIR + '/data/' + h5_filename)
data_batch_list.append(data_batch)
label_batch_list.append(label_batch)
data_batches = np.concatenate(data_batch_list, 0)
label_batches = np.concatenate(label_batch_list, 0)
print(data_batches.shape)
print(label_batches.shape)
train_data = data_batches
train_label = label_batches
test_data = data_batches
test_label = label_batches
print(train_data.shape, train_label.shape)
print(test_data.shape, test_label.shape)
def log_string(out_str):
LOG_FOUT.write(out_str+'\n')
LOG_FOUT.flush()
print(out_str)
def get_learning_rate(batch):
learning_rate = tf.train.exponential_decay(
BASE_LEARNING_RATE, # Base learning rate.
batch * BATCH_SIZE, # Current index into the dataset.
DECAY_STEP, # Decay step.
DECAY_RATE, # Decay rate.
staircase=True)
learning_rate = tf.maximum(learning_rate, 0.00001) # CLIP THE LEARNING RATE!!
return learning_rate
def get_bn_decay(batch):
bn_momentum = tf.train.exponential_decay(
BN_INIT_DECAY,
batch*BATCH_SIZE,
BN_DECAY_DECAY_STEP,
BN_DECAY_DECAY_RATE,
staircase=True)
bn_decay = tf.minimum(BN_DECAY_CLIP, 1 - bn_momentum)
return bn_decay
def train():
with tf.Graph().as_default():
with tf.device('/gpu:'+str(GPU_INDEX)):
pointclouds_pl, labels_pl = placeholder_inputs(BATCH_SIZE, NUM_POINT)
is_training_pl = tf.placeholder(tf.bool, shape=())
# Note the global_step=batch parameter to minimize.
# That tells the optimizer to helpfully increment the 'batch' parameter for you every time it trains.
batch = tf.Variable(0)
bn_decay = get_bn_decay(batch)
tf.summary.scalar('bn_decay', bn_decay)
# Get model and loss
pred = get_model(pointclouds_pl, is_training_pl, bn_decay=bn_decay)
loss = get_loss(pred, labels_pl)
tf.summary.scalar('loss', loss)
correct = tf.equal(tf.argmax(pred, 2), tf.to_int64(labels_pl))
accuracy = tf.reduce_sum(tf.cast(correct, tf.float32)) / float(BATCH_SIZE*NUM_POINT)
tf.summary.scalar('accuracy', accuracy)
# Get training operator
learning_rate = get_learning_rate(batch)
tf.summary.scalar('learning_rate', learning_rate)
if OPTIMIZER == 'momentum':
optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=MOMENTUM)
elif OPTIMIZER == 'adam':
optimizer = tf.train.AdamOptimizer(learning_rate)
train_op = optimizer.minimize(loss, global_step=batch)
# Add ops to save and restore all the variables.
saver = tf.train.Saver()
# Create a session
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.allow_soft_placement = True
config.log_device_placement = True
sess = tf.Session(config=config)
# Add summary writers
merged = tf.summary.merge_all()
train_writer = tf.summary.FileWriter(os.path.join(LOG_DIR, 'train'),
sess.graph)
test_writer = tf.summary.FileWriter(os.path.join(LOG_DIR, 'test'))
# Init variables
init = tf.global_variables_initializer()
sess.run(init, {is_training_pl:True})
ops = {'pointclouds_pl': pointclouds_pl,
'labels_pl': labels_pl,
'is_training_pl': is_training_pl,
'pred': pred,
'loss': loss,
'train_op': train_op,
'merged': merged,
'step': batch}
for epoch in range(MAX_EPOCH):
log_string('**** EPOCH %03d ****' % (epoch))
sys.stdout.flush()
train_one_epoch(sess, ops, train_writer)
eval_one_epoch(sess, ops, test_writer)
# Save the variables to disk.
if epoch % 10 == 0:
save_path = saver.save(sess, os.path.join(LOG_DIR, "model.ckpt"))
log_string("Model saved in file: %s" % save_path)
def train_one_epoch(sess, ops, train_writer):
""" ops: dict mapping from string to tf ops """
is_training = True
log_string('----')
current_data, current_label, _ = provider.shuffle_data(train_data, train_label)
current_data = current_data[:,0:NUM_POINT,:]
current_label = current_label[:,0:NUM_POINT]
file_size = current_data.shape[0]
num_batches = file_size // BATCH_SIZE
total_correct = 0
total_seen = 0
loss_sum = 0
for batch_idx in range(num_batches):
if batch_idx % 1 == 0:
print('Current batch/total batch num: %d/%d'%(batch_idx,num_batches))
start_idx = batch_idx * BATCH_SIZE
end_idx = (batch_idx+1) * BATCH_SIZE
feed_dict = {ops['pointclouds_pl']: current_data[start_idx:end_idx, :, :],
ops['labels_pl']: current_label[start_idx:end_idx],
ops['is_training_pl']: is_training,}
summary, step, _, loss_val, pred_val = sess.run([ops['merged'], ops['step'], ops['train_op'], ops['loss'], ops['pred']],
feed_dict=feed_dict)
train_writer.add_summary(summary, step)
pred_val = np.argmax(pred_val, 2)
correct = np.sum(pred_val == current_label[start_idx:end_idx])
total_correct += correct
total_seen += (BATCH_SIZE*NUM_POINT)
loss_sum += loss_val
log_string('mean loss: %f' % (loss_sum / float(num_batches)))
log_string('accuracy: %f' % (total_correct / float(total_seen)))
def eval_one_epoch(sess, ops, test_writer):
""" ops: dict mapping from string to tf ops """
is_training = False
total_correct = 0
total_seen = 0
loss_sum = 0
total_seen_class = [0 for _ in range(NUM_CLASSES)]
total_correct_class = [0 for _ in range(NUM_CLASSES)]
log_string('----')
current_data, current_label, _ = provider.shuffle_data(test_data, test_label)
current_data = current_data[:, 0:NUM_POINT, :]
current_label = current_label[:, 0:NUM_POINT]
current_label = np.squeeze(current_label)
file_size = current_data.shape[0]
num_batches = file_size // BATCH_SIZE
for batch_idx in range(num_batches):
start_idx = batch_idx * BATCH_SIZE
end_idx = (batch_idx+1) * BATCH_SIZE
feed_dict = {ops['pointclouds_pl']: current_data[start_idx:end_idx, :, :],
ops['labels_pl']: current_label[start_idx:end_idx],
ops['is_training_pl']: is_training}
summary, step, loss_val, pred_val = sess.run([ops['merged'], ops['step'], ops['loss'], ops['pred']],
feed_dict=feed_dict)
test_writer.add_summary(summary, step)
pred_val = np.argmax(pred_val, 2)
correct = np.sum(pred_val == current_label[start_idx:end_idx])
total_correct += correct
total_seen += (BATCH_SIZE*NUM_POINT)
loss_sum += (loss_val*BATCH_SIZE)
for i in range(start_idx, end_idx):
for j in range(NUM_POINT):
l = current_label[i, j]
total_seen_class[l] += 1
total_correct_class[l] += (pred_val[i-start_idx, j] == l)
log_string('eval mean loss: %f' % (loss_sum / float(total_seen/NUM_POINT)))
log_string('eval accuracy: %f'% (total_correct / float(total_seen)))
log_string('eval avg class acc: %f' % (np.mean(np.array(total_correct_class)/np.array(total_seen_class,dtype=np.float))))
if __name__ == "__main__":
train()
LOG_FOUT.close()
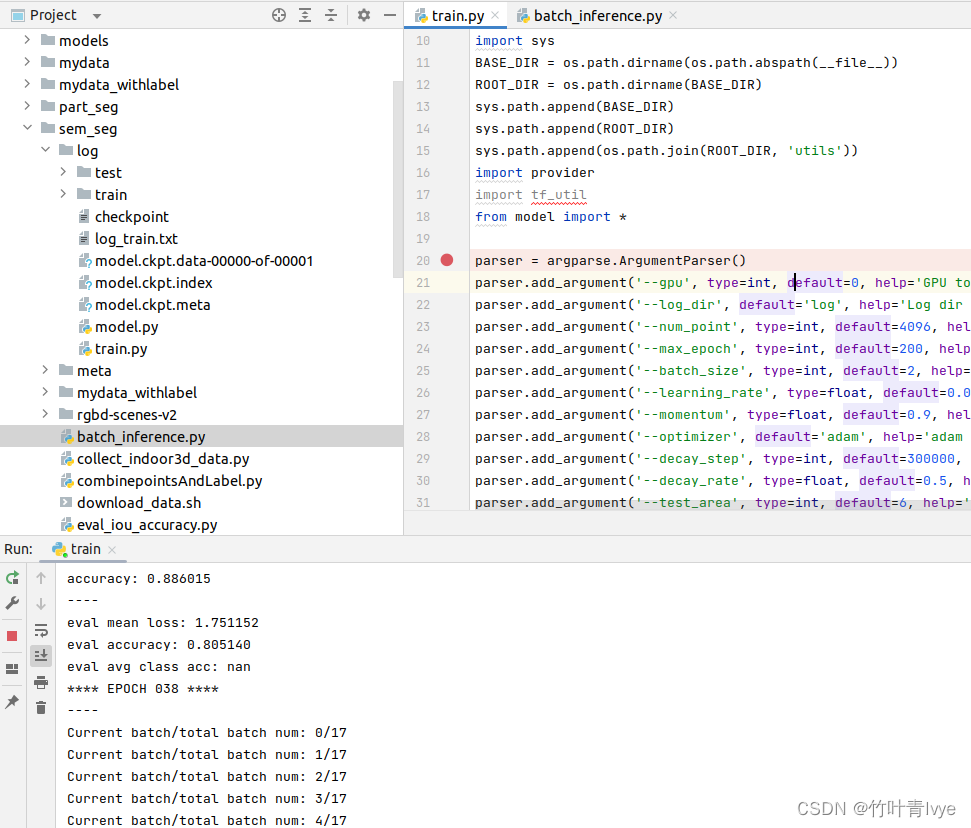
运行文件,开始训练
6. 分割网络预测
博主修改了下sem_seg/batch_inference.py中的代码,如下:
import numpy as np
import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution()
import argparse
import os
import sys
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
ROOT_DIR = os.path.dirname(BASE_DIR)
sys.path.append(BASE_DIR)
from model import *
import indoor3d_util
parser = argparse.ArgumentParser()
parser.add_argument('--gpu', type=int, default=0, help='GPU to use [default: GPU 0]')
parser.add_argument('--batch_size', type=int, default=1, help='Batch Size during training [default: 1]')
parser.add_argument('--num_point', type=int, default=4096*20, help='Point number [default: 4096]')
parser.add_argument('--model_path', default='log/model.ckpt', help='model checkpoint file path')
parser.add_argument('--dump_dir', default='dump', help='dump folder path')
parser.add_argument('--output_filelist', default='output.txt', help='TXT filename, filelist, each line is an output for a room')
parser.add_argument('--room_data_filelist', default='meta/area6_data_label.txt', help='TXT filename, filelist, each line is a test room data label file.')
parser.add_argument('--no_clutter', action='store_true', help='If true, donot count the clutter class')
parser.add_argument('--visu', default='true', help='Whether to output OBJ file for prediction visualization.')
FLAGS = parser.parse_args()
BATCH_SIZE = FLAGS.batch_size
NUM_POINT = FLAGS.num_point
MODEL_PATH = FLAGS.model_path
GPU_INDEX = FLAGS.gpu
DUMP_DIR = FLAGS.dump_dir
if not os.path.exists(DUMP_DIR): os.mkdir(DUMP_DIR)
LOG_FOUT = open(os.path.join(DUMP_DIR, 'log_evaluate.txt'), 'w')
LOG_FOUT.write(str(FLAGS)+'\n')
ROOM_PATH_LIST = [BASE_DIR + "/mydata_withlabel/tabel01 - Cloud_1_withlabel.asc",
BASE_DIR + "/mydata_withlabel/tabel01 - Cloud_2_withlabel.asc",
BASE_DIR + "/mydata_withlabel/tabel01 - Cloud_3_withlabel.asc",
BASE_DIR + "/mydata_withlabel/tabel05 - Cloud_1_withlabel.asc",
BASE_DIR + "/mydata_withlabel/tabel10 - Cloud_2_withlabel.asc"]
NUM_CLASSES = 4
def log_string(out_str):
LOG_FOUT.write(out_str+'\n')
LOG_FOUT.flush()
print(out_str)
def evaluate():
is_training = False
with tf.device('/gpu:'+str(GPU_INDEX)):
pointclouds_pl, labels_pl = placeholder_inputs(BATCH_SIZE, NUM_POINT)
is_training_pl = tf.placeholder(tf.bool, shape=())
# simple model
pred = get_model(pointclouds_pl, is_training_pl)
loss = get_loss(pred, labels_pl)
pred_softmax = tf.nn.softmax(pred)
# Add ops to save and restore all the variables.
saver = tf.train.Saver()
# Create a session
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.allow_soft_placement = True
config.log_device_placement = True
sess = tf.Session(config=config)
# Restore variables from disk.
saver.restore(sess, MODEL_PATH)
log_string("Model restored.")
ops = {'pointclouds_pl': pointclouds_pl,
'labels_pl': labels_pl,
'is_training_pl': is_training_pl,
'pred': pred,
'pred_softmax': pred_softmax,
'loss': loss}
for room_path in ROOM_PATH_LIST:
out_data_label_filename = os.path.basename(room_path)[:-4] + '_pred.txt'
out_data_label_filename = os.path.join(DUMP_DIR, out_data_label_filename)
out_gt_label_filename = os.path.basename(room_path)[:-4] + '_gt.txt'
out_gt_label_filename = os.path.join(DUMP_DIR, out_gt_label_filename)
print(room_path, out_data_label_filename)
eval_one_epoch(sess, ops, room_path, out_data_label_filename, out_gt_label_filename)
def eval_one_epoch(sess, ops, room_path, out_data_label_filename, out_gt_label_filename):
error_cnt = 0
is_training = False
total_correct = 0
total_seen = 0
loss_sum = 0
total_seen_class = [0 for _ in range(NUM_CLASSES)]
total_correct_class = [0 for _ in range(NUM_CLASSES)]
points = np.loadtxt(room_path)
print(points.shape)
sample = np.random.choice(points.shape[0], NUM_POINT)
sample_data = points[sample,...]
points_list = []
points_list.append(sample_data)
data_label = np.stack(points_list, axis=0)
print(data_label.shape)
current_data = data_label[:, :, 0:6]
current_label = data_label[:, :, 6]
print(current_data .shape)
print(current_label.shape)
file_size = current_data.shape[0]
num_batches = file_size // BATCH_SIZE
print(file_size)
for batch_idx in range(num_batches):
start_idx = batch_idx * BATCH_SIZE
end_idx = (batch_idx+1) * BATCH_SIZE
cur_batch_size = end_idx - start_idx
feed_dict = {ops['pointclouds_pl']: current_data[start_idx:end_idx, :, :],
ops['labels_pl']: current_label[start_idx:end_idx],
ops['is_training_pl']: is_training}
loss_val, pred_val = sess.run([ops['loss'], ops['pred_softmax']],
feed_dict=feed_dict)
if FLAGS.no_clutter:
pred_label = np.argmax(pred_val[:,:,0:12], 2) # BxN
else:
pred_label = np.argmax(pred_val, 2) # BxN
correct = np.sum(pred_label == current_label[start_idx:end_idx,:])
total_correct += correct
total_seen += (cur_batch_size*NUM_POINT)
loss_sum += (loss_val*BATCH_SIZE)
pred_label = pred_label[:, :, np.newaxis]
pred_data_label = np.concatenate([current_data, pred_label], 2)
np.savetxt(out_data_label_filename, pred_data_label[0, :, :], fmt="%.8f %.8f %.8f %.8f %.8f %.8f %d",
delimiter=" ")
log_string('eval mean loss: %f' % (loss_sum / float(total_seen/NUM_POINT)))
log_string('eval accuracy: %f'% (total_correct / float(total_seen)))
return
if __name__=='__main__':
with tf.Graph().as_default():
evaluate()
LOG_FOUT.close()
注意model.py文件中13需要改为4(自己的数据集上只区分了四类)

运行文件,结果保存在 dump中,可用cloudcompare打开以预测标签作为scalar field的文件
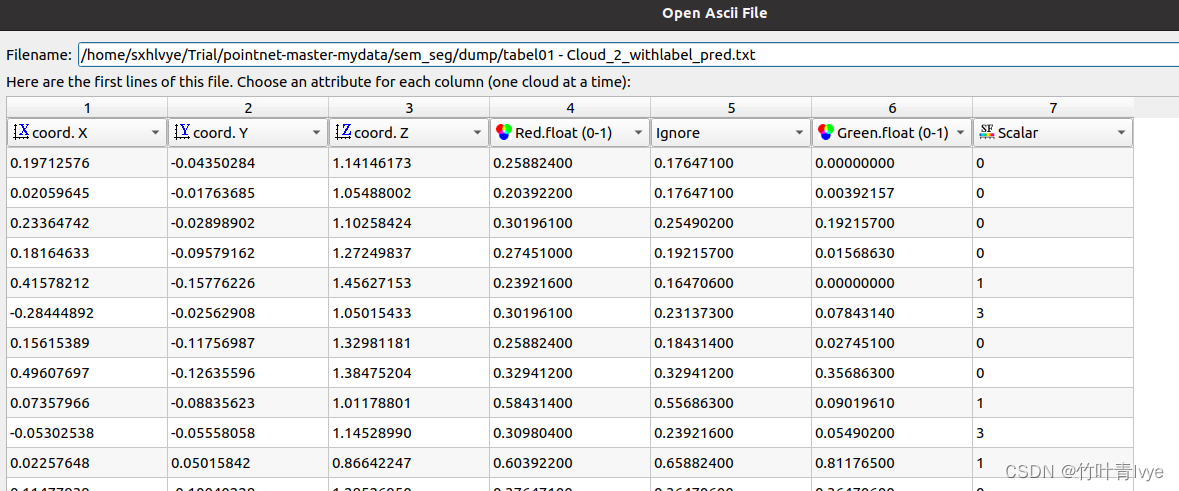
可看到,大体分割出来了。

这边由于在前面训练时候,只随机从各点云文件中提取了4096个点,还是很稀疏的。一些类别的点参与训练不充分。后续可以就这些点再去优化,博主这边暂时不继续做了,感兴趣的童鞋可以继续优化下去,这边只说明如何在自己的训练集上做训练和预测。
上传下博主的工程,链接如下:
链接: https://pan.baidu.com/s/1HWRCwtorUC6fVWeaKjh5Qg 提取码: 318v
参考博客
制作PointNet以及PointNet++点云训练样本_点云数据集制作_CC047964的博客-CSDN博客
点云标注 - 知乎




![[Selenium] 通过Java+Selenium查询某个博主的Top100文章质量分](https://img-blog.csdnimg.cn/cf61ca69b9c6496a9e2e1c9f53b5ca42.png)