作者主页:爱笑的男孩。的博客_CSDN博客-深度学习,活动,python领域博主爱笑的男孩。擅长深度学习,活动,python,等方面的知识,爱笑的男孩。关注算法,python,计算机视觉,图像处理,深度学习,pytorch,神经网络,opencv领域.
https://blog.csdn.net/Code_and516?type=blog个人简介:打工人。
持续分享:机器学习、深度学习、python相关内容、日常BUG解决方法及Windows&Linux实践小技巧。
如发现文章有误,麻烦请指出,我会及时去纠正。有其他需要可以私信我或者发我邮箱:zhilong666@foxmail.com
作为一种先进的学习方法,强化学习已经在许多应用领域得到了广泛的应用,如机器人控制、自动驾驶、游戏策略等。强化学习是在不断与环境交互的过程中,根据奖励与惩罚的反馈信息,来自主学习的一种方法。
本文将详细讲一下什么是“强化学习”

目录
强化学习简介:
强化学习发展史:
强化学习算法:
1. Q-learning算法
2. SARSA算法
3. Policy Gradient算法
4. Actor-Critic算法
强化学习总结:
强化学习简介:
强化学习是机器学习领域的一种重要方法,主要通过使用环境的反馈信息来指导智能体的行为,并且通过智能体收集的经验数据对自身策略进行优化。在强化学习中,我们通常用“智能体”来表示学习机器或者一个决策实体。这个智能体在某个环境中采取行动,然后收到环境的反馈信号(奖励或者惩罚),从而逐渐学习到一个最优的行动策略。
在强化学习中,主要涉及到一些概念,如状态、行动、奖励、策略等等。状态指的是输入进入智能体算法的集合,行动指的是智能体做出的反应,奖励通常是指环境给予智能体的反馈信息,策略指的是智能体在某种状态下选择的行为。
强化学习的主要优势在于它适用于没有标准答案的问题中,比如模拟人类思维和行为、自我驾驶汽车、人工智能机器人、游戏目标等。总而言之,强化学习是使得机器能够通过独立的学习从而达成目标的最有效方法之一。
强化学习发展史:
强化学习的历史可以追溯到1958年,Sutton和Barto 1958年提出的一个最初的强化学习方法,他们研究了在一个简单的迷宫环境下,如何让学习的智能体找到最快捷的路径。最初的方法是使用策略梯度,但由于不易收敛,所以更高效的方法很快被提出。
之后,基于值函数的方法(如Sarsa和Q学习)出现了,这两种方法具有广泛的适用性和良好的性能。同时,伴随着深度学习技术的发展,强化学习也得到了广泛的发展。DeepMind的AlphaGo便是杰出的例子之一。此外,强化学习在自动驾驶、机器人控制和游戏策略等领域也得到了广泛的应用。强化学习还可以同其他学习方法相结合,比如监督式学习和半监督式学习,以提高分类和推荐等任务的性能。
强化学习算法:
1. Q-learning算法
Q-learning算法是一种基于值函数(Value Function)来进行决策的强化学习算法,它通过计算每个状态-动作对(State-Action Pair)的Q值,来评估决策的优劣程度,最终选择最优决策。
Q-learning算法的发展历程可以追溯到上世纪的80年代,由Watkins和Dayan提出并经过多年的完善。该算法的核心定义如下:
对于当前状态St和可选的动作集合A,在执行动作后,可观测到下一个状态St+1和此刻的奖励信号Rt+1,则:
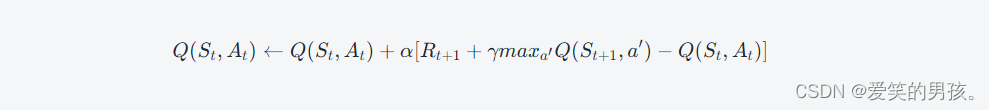
其中,α代表学习率(Learning Rate),γ代表折扣率(Discount Factor),此处的maxa′Q(St+1,a′)是为了确定在下一动作中选择最佳的行为。
Q-learning算法的优点在于它对最优决策的逼近与收敛有很好的理论保证,但它也存在着高度依赖价值函数的局限性。
2. SARSA算法
SARSA算法是另一种基于值函数的强化学习算法,它跟Q-learning的不同之处在于,它采用了一种在状态-动作对上的全面搜索策略(Simultaneous Action and Reward expecation),考虑了在每一次决策中都能看到整个决策序列的特点。
SARSA算法的核心定义如下:
对于每个状态-动作对(St,At),在执行动作后可观测到下一个状态(St+1,At+1)和此刻的奖励信号Rt+1,则:
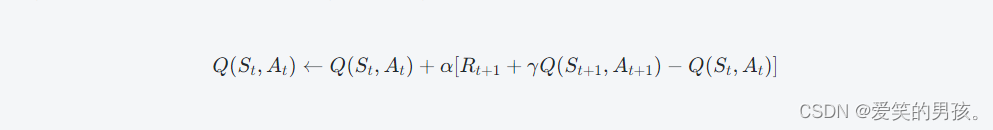
SARSA算法能极大地提高模型基于在线实验的学习效率,但也存在着过度在轨迹中学习的缺点,同时会出现过估计真实Q值的现象。
3. Policy Gradient算法
Policy Gradient算法是一种基于策略函数(Policy Function)的强化学习算法,它能够直接优化策略函数,而不是优化Q值等价价值函数,也因此被称为直接策略优化算法(Direct Policy Optimization)。
Policy Gradient算法的核心思想在于,通过梯度上升的方法来最大化策略函数的总回报(reward),从而达到最优策略的目标。
考虑在给定策略函数π(a∣s;θ)的情况下,显示地定义策略相关的状态值函数 J 如下:
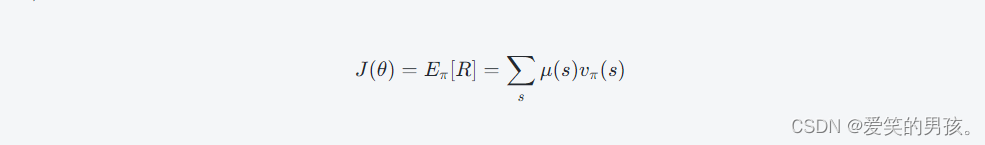
其中:
μ(s)表示模型在稳态下访问每个状态的概率
vπ(s)表示在当前策略下,从状态s出发的长期回报期望值。
Policy Gradient算法的关键步骤是通过对策略函数进行梯度上升优化,求解最大化 J(θ) 的策略函数参数 θ:
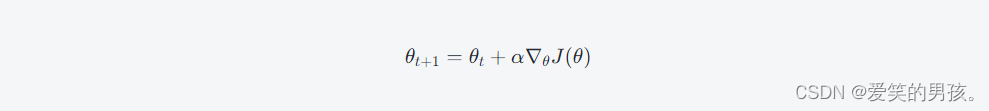
其中,学习率(learning rate) \alphaα决定了学习过程的速度。
Policy Gradient算法相比其他基于值函数方法,在探索过程中更加稳定,且能够直接处理连续动作空间的问题。
4. Actor-Critic算法
Actor-Critic算法是既包含了策略函数优化,又具备了价值函数优化的强化学习算法,它的中心思想在于,由一名演员(Actor)来生成决策,同时由一位评论家(Critic)来评估演员的表现,进而实现对策略函数和状态值函数的联合优化。
Actor-Critic算法本质上是结合了Policy Gradient算法与Q-learning算法的思想,用Critic来估计状态价值函数V(s)或Q(s,a),根据当前策略和估值函数之间的差异调整策略,使得当前策略下估值更高,然后再通过策略来选择下一步的操作。
由于Actor-Critic总结了Policy Gradient与Q-learning各自的优点,能够更加有效地处理连续动作空间或者非线性动力学模型的优化问题,因此被广泛应用在各种强化学习的场景之中。
以上四种强化学习算法各有其优缺点,根据不同的问题与应用场景,需要综合考虑它们的特性与实现难易程度,选用最合适的算法来进行决策建模。强化学习作为一种新兴的人工智能技术,对于智能化决策的推进具有非常重要的意义,相信在不久的将来,强化学习算法会得到更加广泛的应用与完善。
强化学习总结:
随着技术的发展和应用场景的拓展,强化学习是机器学习领域最受欢迎和值得关注的研究领域之一。它的应用范围广泛,包括自动驾驶、机器人操作、游戏策略等。强化学习目前的发展一直是快速的,不断地探索新的方法和技术。基于强化学习的算法将有望实现机器学习领域的长期目标,不断推进人工智能的发展,为我们的生活带来更多的便利与创造力。






![[Selenium] 通过Java+Selenium查询某个博主的Top100文章质量分](https://img-blog.csdnimg.cn/cf61ca69b9c6496a9e2e1c9f53b5ca42.png)