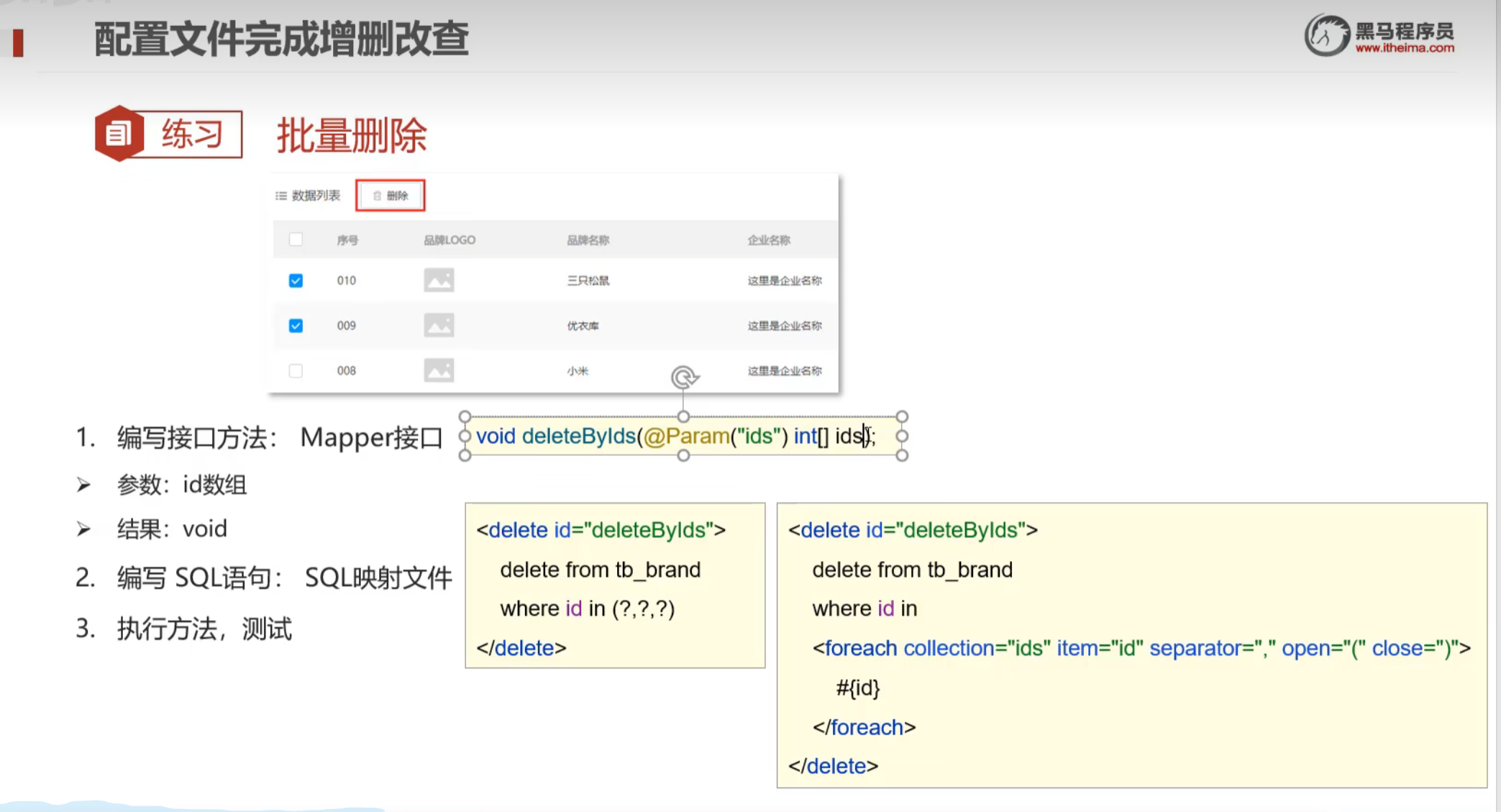
classifier guided diffusion model
背景
对于一般的DM(如DDPM, DDIM)的采样过程是直接从一个噪声分布,通过不断采样来生成图片。但这个方法生成的图片类别是随机的,如何生成特定类别的图片呢?这就是classifier guide需要解决的问题。
方法大意
为了实现带类别标签
y
y
y的DM的推导,进行了以下定义
q
^
(
x
0
)
:
=
q
(
x
0
)
q
^
(
y
∣
x
0
)
:
=
Know labels per sample
q
^
(
x
t
+
1
∣
x
t
,
y
)
:
=
q
(
x
t
+
1
∣
x
t
)
q
^
(
x
1
:
T
∣
x
0
,
y
)
:
=
∏
t
=
1
T
q
^
(
x
t
∣
x
t
−
1
,
y
)
(1)
\begin{aligned} \hat{q}(x_0) &:= q(x_0) \\ \hat{q}(y|x_0) &:= \text{Know labels per sample} \\ \hat{q}(x_{t+1}|x_{t}, y) &:= q(x_{t+1}|x_t) \\ \hat{q}(x_{1:T}|x_0, y)&:= \prod \limits_{t=1}^T\hat{q}(x_t|x_{t-1}, y) \\ \end{aligned} \tag{1}
q^(x0)q^(y∣x0)q^(xt+1∣xt,y)q^(x1:T∣x0,y):=q(x0):=Know labels per sample:=q(xt+1∣xt):=t=1∏Tq^(xt∣xt−1,y)(1)
虽然上式定义了以
y
y
y为条件的噪声过程
q
^
\hat{q}
q^,但我们还可以证明当
q
^
\hat{q}
q^不以
y
y
y为条件时的行为与
q
q
q完全相同,即
q
^
(
x
t
+
1
∣
x
t
)
=
∫
y
q
^
(
x
t
+
1
,
y
∣
x
t
)
d
y
=
∫
y
q
^
(
x
t
+
1
∣
x
t
,
y
)
q
^
(
y
∣
x
t
)
d
y
=
∫
y
q
(
x
t
+
1
∣
x
t
)
q
^
(
y
∣
x
t
)
d
y
=
q
(
x
t
+
1
∣
x
t
)
∫
y
q
^
(
y
∣
x
t
)
d
y
=
q
(
x
t
+
1
∣
x
t
)
=
q
^
(
x
t
+
1
∣
x
t
,
y
)
(2)
\begin{aligned} \hat{q}(x_{t+1}|x_t) &= \int_y \hat{q}(x_{t+1}, y| x_t)dy \\ &= \int_y \hat{q}(x_{t+1}|x_t, y)\hat{q}(y|x_t)dy \\ &= \int_y q(x_{t+1}|x_t)\hat{q}(y|x_t)dy \\ &= q(x_{t+1}|x_t) \int_y \hat{q}(y|x_t)dy \\ &= q(x_{t+1}|x_t) \\ &= \hat{q}(x_{t+1}|x_t, y) \\ \end{aligned}\tag{2}
q^(xt+1∣xt)=∫yq^(xt+1,y∣xt)dy=∫yq^(xt+1∣xt,y)q^(y∣xt)dy=∫yq(xt+1∣xt)q^(y∣xt)dy=q(xt+1∣xt)∫yq^(y∣xt)dy=q(xt+1∣xt)=q^(xt+1∣xt,y)(2)
同样的思路:
q
^
(
x
1
:
T
∣
x
0
)
=
∫
y
q
^
(
x
1
:
T
,
y
∣
x
0
)
d
y
=
∫
y
q
^
(
x
1
:
T
∣
y
,
x
0
)
q
(
y
∣
x
0
)
d
y
=
∫
y
∏
t
=
1
T
q
^
(
x
t
∣
x
t
−
1
,
y
)
⏟
q
(
x
t
∣
x
t
−
1
)
q
(
y
∣
x
0
)
d
y
=
∏
t
=
1
T
q
(
x
t
∣
x
t
−
1
)
⏟
q
(
x
1
:
T
∣
x
0
)
∫
y
q
(
y
∣
x
0
)
d
y
⏟
=
1
=
q
(
x
1
:
T
∣
x
0
)
(3)
\begin{aligned} \hat{q}(x_{1:T}|x_0) &= \int_y \hat{q}(x_{1:T}, y|x_0) d_y \\ &= \int_y \hat{q}(x_{1:T}|y, x_0)q(y| x_0) d_y \\ &= \int_y \prod \limits_{t=1}^T \underbrace{ \hat{q}(x_t|x_{t-1}, y)}_{q(x_t|x_t-1)} q(y| x_0) d_y \\ &= \underbrace{\prod \limits_{t=1}^Tq(x_t|x_{t-1})}_{q(x_{1:T}|x_0)} \underbrace{\int_y q(y| x_0)d_y}_{=1} \\ &= q(x_{1:T}|x_0) \end{aligned}\tag{3}
q^(x1:T∣x0)=∫yq^(x1:T,y∣x0)dy=∫yq^(x1:T∣y,x0)q(y∣x0)dy=∫yt=1∏Tq(xt∣xt−1)
q^(xt∣xt−1,y)q(y∣x0)dy=q(x1:T∣x0)
t=1∏Tq(xt∣xt−1)=1
∫yq(y∣x0)dy=q(x1:T∣x0)(3)
根据上式同样可以推导出
q
^
(
x
t
)
=
∫
x
0
:
t
−
1
q
^
(
x
0
,
⋯
,
x
t
)
d
x
0
:
t
−
1
=
∫
x
0
:
t
−
1
q
^
(
x
0
)
⏟
q
(
x
0
)
q
^
(
x
1
,
⋯
,
x
t
∣
x
0
)
⏟
q
(
x
1
:
T
∣
x
0
)
d
x
0
:
t
−
1
=
q
(
x
t
)
(4)
\begin{aligned} \hat{q}(x_t) &= \int_{x_{0:t - 1}} \hat{q}(x_0, \cdots, x_t)dx_{0:t-1} \\ &= \int_{x_{0:t - 1}} \underbrace{\hat{q}(x_0)}_{q(x_0)} \underbrace{\hat{q}(x_1, \cdots, x_t|x_0)}_{q(x_{1:T}|x_0)}dx_{0:t-1} \\ &= q(x_t) \end{aligned} \tag{4}
q^(xt)=∫x0:t−1q^(x0,⋯,xt)dx0:t−1=∫x0:t−1q(x0)
q^(x0)q(x1:T∣x0)
q^(x1,⋯,xt∣x0)dx0:t−1=q(xt)(4)
由上述推导可见带条件的DM的前向过程与DDPM完全相同。并且根据贝叶斯公式,不带逆向过程也满足
p
^
(
x
t
∣
x
t
+
1
)
=
p
(
x
t
∣
x
t
+
1
)
(5)
\hat{p}(x_t|x_{t+1}) = p(x_t|x_{t+1}) \tag{5}
p^(xt∣xt+1)=p(xt∣xt+1)(5)
与此同时我们可以证明分类分布
q
^
(
y
∣
x
t
)
\hat{q}(y|x_t)
q^(y∣xt)只和当前时刻的输入
x
t
x_t
xt有关,与
x
t
+
1
x_{t+1}
xt+1无关
q
^
(
y
∣
x
t
,
x
t
+
1
)
=
q
^
(
x
t
+
1
∣
x
t
,
y
)
⏞
q
^
(
x
t
+
1
∣
x
t
)
q
^
(
y
∣
x
t
)
q
^
(
x
t
+
1
∣
x
t
)
=
q
^
(
y
∣
x
t
)
(6)
\begin{aligned} \hat{q}(y|x_t, x_{t+1}) & = \frac{ \overbrace{ \hat{q}(x_{t+1}|x_t, y)}^{\hat{q}(x_{t+1}|x_t)} \hat{q}(y|x_t) } {\hat{q}(x_{t+1}|x_t )} \\ & = \hat{q}(y|x_t) \end{aligned} \tag{6}
q^(y∣xt,xt+1)=q^(xt+1∣xt)q^(xt+1∣xt,y)
q^(xt+1∣xt)q^(y∣xt)=q^(y∣xt)(6)
基于条件的去噪过程
将带类别信息的去噪过程定义为 p ^ ( x t ∣ x t + 1 , y ) \hat{p}(x_t|x_{t+1}, y) p^(xt∣xt+1,y)
p
^
(
x
t
∣
x
t
+
1
,
y
)
=
p
^
(
x
t
,
x
t
+
1
,
y
)
p
^
(
y
∣
x
t
+
1
)
p
^
(
x
t
+
1
)
=
p
^
(
x
t
,
y
∣
x
t
+
1
)
p
^
(
y
∣
x
t
+
1
)
=
p
^
(
y
∣
x
t
,
x
t
+
1
)
⏞
p
^
(
y
∣
x
t
)
p
^
(
x
t
∣
x
t
+
1
)
⏞
p
(
x
t
∣
x
t
+
1
)
p
^
(
y
∣
x
t
+
1
)
=
p
^
(
y
∣
x
t
)
p
(
x
t
∣
x
t
+
1
)
p
^
(
y
∣
x
t
+
1
)
(7)
\begin{aligned} \hat{p} (x_t| x_{t+1}, y) & = \frac{\hat{p} (x_t, x_{t+1}, y) }{\hat{p} (y|x_{t+1}) \hat{p} (x_{t+1}) } \\ & = \frac{\hat{p} (x_t, y | x_{t+1}) }{\hat{p} (y|x_{t+1}) } \\ & = \frac{\overbrace{\hat{p} (y|x_t, x_{t+1})}^{\hat{p}(y|x_t)} \overbrace{\hat{p}(x_t | x_{t+1})}^{p(x_t|x_{t+1})} }{\hat{p} (y|x_{t+1}) } \\ & = \frac{\hat{p} (y|x_t) p(x_t | x_{t+1}) }{\hat{p} (y|x_{t+1}) } \end{aligned} \tag{7}
p^(xt∣xt+1,y)=p^(y∣xt+1)p^(xt+1)p^(xt,xt+1,y)=p^(y∣xt+1)p^(xt,y∣xt+1)=p^(y∣xt+1)p^(y∣xt,xt+1)
p^(y∣xt)p^(xt∣xt+1)
p(xt∣xt+1)=p^(y∣xt+1)p^(y∣xt)p(xt∣xt+1)(7)
由于
x
t
+
1
x_{t+1}
xt+1是已知的,
p
^
(
y
∣
x
t
+
1
)
\hat{p} (y|x_{t+1})
p^(y∣xt+1)这个概率分布与
x
t
x_t
xt无关,可以将
p
^
(
y
∣
x
t
+
1
)
\hat{p} (y|x_{t+1})
p^(y∣xt+1)视为常数
Z
Z
Z。此时上式可以表述为
p
^
(
x
t
∣
x
t
+
1
,
y
)
=
Z
p
^
(
y
∣
x
t
)
p
(
x
t
∣
x
t
+
1
)
(8)
\hat{p} (x_t| x_{t+1}, y) = Z \hat{p} (y|x_t) p(x_t | x_{t+1}) \tag{8}
p^(xt∣xt+1,y)=Zp^(y∣xt)p(xt∣xt+1)(8)
上式的右边第二项
p
^
(
y
∣
x
t
)
\hat{p} (y|x_t)
p^(y∣xt)很容易得到,我们可以根据
x
t
,
y
x_t, y
xt,y的pair对训练一个分类模型
p
^
ϕ
(
y
∣
x
t
)
\hat{p}_\phi(y|x_t)
p^ϕ(y∣xt)
上式的右边第三项 p ( x t ∣ x t + 1 ) p(x_t | x_{t+1}) p(xt∣xt+1)在DDPM中也能够通过一个neural network进行估计 p ( x t ∣ x t + 1 ) ≈ p θ ( x t ∣ x t + 1 ) p(x_t | x_{t+1}) \approx p_\theta(x_t|x_{t+1}) p(xt∣xt+1)≈pθ(xt∣xt+1)
故采样分布
p
^
(
x
t
∣
x
t
+
1
,
y
)
≈
p
^
ϕ
,
θ
(
x
t
∣
x
t
+
1
,
y
)
=
Z
p
^
ϕ
(
y
∣
x
t
)
p
θ
(
x
t
∣
x
t
+
1
)
(9)
\begin{aligned} \hat{p} (x_t| x_{t+1}, y) &\approx \hat{p}_{\phi, \theta} (x_t| x_{t+1}, y) \\ &= Z \hat{p}_{\phi} (y|x_t) p_{\theta}(x_t | x_{t+1}) \end{aligned} \tag{9}
p^(xt∣xt+1,y)≈p^ϕ,θ(xt∣xt+1,y)=Zp^ϕ(y∣xt)pθ(xt∣xt+1)(9)
下面来看有了上面这个式子如何进行采样
直接对上面的式子进行采样是很难解决的。论文参考文献1将上式近似为perturbed Gaussian distribution。
根据前文DM的推导可知
p
θ
(
x
t
∣
x
t
+
1
)
=
N
(
μ
,
Σ
)
=
1
2
π
Σ
exp
(
−
(
x
−
μ
)
2
2
Σ
)
p_{\theta}(x_t | x_{t+1}) = \mathcal{N}(\mu, \Sigma)=\frac{1}{\sqrt{2\pi} \sqrt{\Sigma} } \exp \left ({- \frac{(x - \mu)^2}{2\Sigma}} \right)
pθ(xt∣xt+1)=N(μ,Σ)=2πΣ1exp(−2Σ(x−μ)2) ,对其取对数
log
p
θ
(
x
t
∣
x
t
+
1
)
=
−
1
2
(
x
t
−
μ
)
T
Σ
−
1
(
x
t
−
μ
)
+
C
(10)
\log p_{\theta}(x_t|x_{t+1}) = - \frac{1}{2} (x_t - \mu)^T \Sigma^{-1} (x_t - \mu) + C \tag{10}
logpθ(xt∣xt+1)=−21(xt−μ)TΣ−1(xt−μ)+C(10)
对于
log
p
^
ϕ
(
y
∣
x
t
)
\log \hat{p}_{\phi} (y|x_t)
logp^ϕ(y∣xt) 作者假设其curvature比
Σ
−
1
\Sigma^{-1}
Σ−1低。这个假设是合理的,对于当diffusion steps足够大时,
∥
Σ
∥
→
0
\parallel \Sigma \parallel \rightarrow 0
∥Σ∥→0。在该情况下,对
log
p
^
ϕ
(
y
∣
x
t
)
\log\hat{p}_{\phi} (y|x_t)
logp^ϕ(y∣xt)在
x
t
=
μ
x_t = \mu
xt=μ处进行泰勒展开
log
p
^
ϕ
(
y
∣
x
t
)
≈
log
p
^
ϕ
(
y
∣
x
t
)
∣
x
t
=
μ
+
(
x
t
−
μ
)
∇
x
t
log
p
ϕ
(
y
∣
x
t
)
∣
x
t
=
μ
=
(
x
t
−
μ
)
g
+
C
1
where:
g
=
∇
x
t
log
p
ϕ
(
y
∣
x
t
)
∣
x
t
=
μ
,
C
1
is a contant.
(11)
\begin{aligned} \log \hat{p}_{\phi} (y|x_t) & \approx \log \hat{p}_{\phi} (y|x_t) | _{x_t = \mu} + (x_t - \mu) \nabla_{x_t} \log p_{\phi} (y|x_t)|_{x_t = \mu} \\ &= (x_t - \mu) g + C_1 \\ \text{where: } g &= \nabla_{x_t} \log p_{\phi} (y|x_t)|_{x_t = \mu}, C_1\text{ is a contant.} \end{aligned} \tag{11}
logp^ϕ(y∣xt)where: g≈logp^ϕ(y∣xt)∣xt=μ+(xt−μ)∇xtlogpϕ(y∣xt)∣xt=μ=(xt−μ)g+C1=∇xtlogpϕ(y∣xt)∣xt=μ,C1 is a contant.(11)
log ( p ^ ϕ ( y ∣ x t ) p θ ( x t ∣ x t + 1 ) ) = − 1 2 ( x t − μ ) T Σ − 1 ( x t − μ ) + ( x t − μ ) g + C 2 = − 1 2 ( x t − μ − Σ g ) T Σ − 1 ( x t − μ − Σ g ) + 1 2 g T Σ g + C 2 = − 1 2 ( x t − μ − Σ g ) T Σ − 1 ( x t − μ − Σ g ) + C 3 = log p ( z ) + C 4 , z ∼ N ( μ + Σ g , Σ ) (12) \begin{aligned} \log (\hat{p}_{\phi} (y|x_t) p_{\theta}(x_t | x_{t+1})) & = - \frac{1}{2} (x_t - \mu)^T \Sigma^{-1} (x_t - \mu) + (x_t - \mu) g + C_2 \\ & = - \frac{1}{2} (x_t - \mu - \Sigma g)^T \Sigma^{-1} (x_t - \mu- \Sigma g) + \frac{1}{2}g^T\Sigma g + C_2 \\ & = - \frac{1}{2} (x_t - \mu - \Sigma g)^T \Sigma^{-1} (x_t - \mu- \Sigma g) + C_3 \\ & = \log p(z) + C_4, z \sim \mathcal{N}(\mu + \Sigma g, \Sigma) \end{aligned} \tag{12} log(p^ϕ(y∣xt)pθ(xt∣xt+1))=−21(xt−μ)TΣ−1(xt−μ)+(xt−μ)g+C2=−21(xt−μ−Σg)TΣ−1(xt−μ−Σg)+21gTΣg+C2=−21(xt−μ−Σg)TΣ−1(xt−μ−Σg)+C3=logp(z)+C4,z∼N(μ+Σg,Σ)(12)
(附录给出了验证性证明)
通过上述推导,我们得到了带类别条件的采样过程也可以用高斯分布来近似,只是均值需要加上
Σ
g
\Sigma g
Σg。具体的算法如下

代码实现
p_mean_var_ddpm是DDPM对高斯分布均值、方差的计算函数
p_mean_var_ddpm_with_classifier是引入类别控制后的对高斯分布均值、方差的计算函数
有了均值方差就可以进行采样了
def p_mean_var_ddpm(self, noise_model, x, t):
"""
Math:
\mu_\theta(x_t, t) = \frac{1}{\sqrt{\alpha_t}} x_t -
\frac{1 - \alpha_t }{\sqrt{\alpha_t}\sqrt{1 - \overline{\alpha}_t}}f_\theta(x_t, t) \tag{30}
"""
betas_t = extract(self.betas, t, x.shape)
sqrt_one_minus_alphas_cumprod_t = extract(
self.sqrt_one_minus_alphas_cumprod, t, x.shape
)
sqrt_recip_alphas_t = extract(self.sqrt_recip_alphas, t, x.shape)
model_mean_t = sqrt_recip_alphas_t * (
x - betas_t * noise_model(x, t) / sqrt_one_minus_alphas_cumprod_t
)
posterior_variance_t = extract(self.posterior_variance, t, x.shape)
return model_mean_t, posterior_variance_t
def p_mean_var_ddpm_with_classifier(classifier, noise_model, x, t, y=None, cfs=1):
def cond_fn(x: torch.Tensor, t: torch.Tensor, y: torch.Tensor):
assert y is not None
with torch.enable_grad():
x_in = x.detach().requires_grad_(True)
logits = classifier(x_in, t)
log_probs = F.log_softmax(logits, dim=-1)
selected = log_probs[range(len(logits)), y.view(-1)]
return torch.autograd.grad(selected.sum(), x_in)[0].float() # gradient descend
grad = cond_fn(x_temp, t, y=y) * cfs
model_mean_t, posterior_variance_t = p_mean_var_ddpm(noise_model, x, t)
new_mean = model_mean_t + posterior_variance_t * grad
return new_mean, posterior_variance_t
DDIM 中基于条件的去噪过程
上述条件抽样推导仅对随机扩散采样过程有效,不能应用于DDIM2等确定性采样方法(因为DDIM中设定了方差为0,故无法推导出式19)。为此,作者在研究中采用score-based的思路,参考了Song等人[^ 3]的方法,并利用了扩散模型和score matching之间的联系3。
首先根据贝叶斯公式
p
(
x
t
∣
y
)
=
p
(
y
∣
x
t
)
p
(
x
t
)
p
(
y
)
⇒
log
p
(
x
t
∣
y
)
=
log
p
(
y
∣
x
t
)
+
log
p
(
x
t
)
−
log
p
(
y
)
⇒
对
x
t
求导
∇
x
t
log
p
(
x
t
∣
y
)
=
∇
x
t
log
p
(
y
∣
x
t
)
+
∇
x
t
log
p
(
x
t
)
−
∇
x
t
log
p
(
y
)
⏟
=
0
⇒
∇
x
t
log
p
(
x
t
∣
y
)
=
∇
x
t
log
p
(
y
∣
x
t
)
+
∇
x
t
log
p
(
x
t
)
(13)
\begin{aligned} p (x_t| y) & = \frac{p (y|x_t) p(x_t) }{p (y) } \\ \Rightarrow \log{p (x_t| y) } &= \log{p (y|x_t)} + \log{p(x_t)} - \log{p (y) } \\ \stackrel{对x_t求导} \Rightarrow \nabla_{x_t}\log{p (x_t|y)} &= \nabla_{x_t}\log{p (y|x_t)} + \nabla_{x_t}\log{p(x_t)} - \underbrace{\nabla_{x_t}\log{p(y) }}_{=0} \\ \Rightarrow \nabla_{x_t}\log{p(x_t| y)} &= \nabla_{x_t}\log{p(y|x_t)} + \nabla_{x_t}\log{p(x_t)} \\ \end{aligned} \tag{13}
p(xt∣y)⇒logp(xt∣y)⇒对xt求导∇xtlogp(xt∣y)⇒∇xtlogp(xt∣y)=p(y)p(y∣xt)p(xt)=logp(y∣xt)+logp(xt)−logp(y)=∇xtlogp(y∣xt)+∇xtlogp(xt)−=0
∇xtlogp(y)=∇xtlogp(y∣xt)+∇xtlogp(xt)(13)
具体来说,如果我们有一个模型
ϵ
θ
(
x
t
)
\epsilon_\theta(x_t)
ϵθ(xt)来预测添加到样本中的噪声,那么可以利用它来推导出一个score function:
∇
x
t
log
p
θ
(
x
t
)
=
−
1
1
−
α
‾
t
ϵ
θ
(
x
t
)
(14)
\nabla_{x_t} \log p_\theta (x_t) = - \frac{1}{\sqrt{1 - \overline{\alpha}_t}} \epsilon_\theta(x_t) \tag{14}
∇xtlogpθ(xt)=−1−αt1ϵθ(xt)(14)
代入式(20)得
∇
x
t
log
p
(
x
t
∣
y
)
=
∇
x
t
log
p
(
y
∣
x
t
)
−
1
1
−
α
‾
t
ϵ
θ
(
x
t
)
⇒
1
−
α
‾
t
∇
x
t
log
p
(
x
t
∣
y
)
=
1
−
α
‾
t
∇
x
t
log
p
(
y
∣
x
t
)
−
ϵ
θ
(
x
t
)
(15)
\begin{aligned} \nabla_{x_t}\log{p(x_t| y)} &= \nabla_{x_t}\log{p(y|x_t)} - \frac{1}{\sqrt{1 - \overline{\alpha}_t}} \epsilon_\theta(x_t) \\ \Rightarrow \sqrt{1 - \overline{\alpha}_t} \nabla_{x_t}\log{p(x_t| y)} &= \sqrt{1 - \overline{\alpha}_t} \nabla_{x_t}\log{p(y|x_t)} - \epsilon_\theta(x_t) \end{aligned} \tag{15}
∇xtlogp(xt∣y)⇒1−αt∇xtlogp(xt∣y)=∇xtlogp(y∣xt)−1−αt1ϵθ(xt)=1−αt∇xtlogp(y∣xt)−ϵθ(xt)(15)
定义在条件
y
y
y下的估计噪声
ϵ
^
(
x
t
∣
y
)
\hat{\epsilon}(x_t|y)
ϵ^(xt∣y)为:
ϵ
^
(
x
t
∣
y
)
:
=
ϵ
θ
(
x
t
)
−
1
−
α
‾
t
∇
x
t
log
p
ϕ
(
y
∣
x
t
)
(16)
\hat{\epsilon}(x_t|y) := \epsilon_\theta(x_t) - \sqrt{1 - \overline{\alpha}_t}\nabla_{x_t} \log{p_\phi(y|x_t)} \tag{16}
ϵ^(xt∣y):=ϵθ(xt)−1−αt∇xtlogpϕ(y∣xt)(16)
只需将DDIM中的$ \epsilon_\theta(x_t)
替换为
替换为
替换为\hat{\epsilon}(x_t|y)$就得到了基于条件的去噪过程。

代码上也很直观
def p_sample_ddim(self, model, x, t):
"""
x_{t-1} &= \sqrt{\overline{\alpha}_{t-1}} \frac{x_t - \sqrt{1 - \overline{\alpha}_{t}}\boldsymbol{\epsilon}_\theta(x_t, t)}
{\sqrt{\overline{\alpha}_{t}}} + \sqrt{1 - \overline{\alpha}_{t-1} } \boldsymbol{\epsilon}_\theta(x_t, t)
"""
sqrt_alphas_cumprod_prev_t = extract(self.sqrt_alphas_cumprod_prev, t, x.shape)
sqrt_one_minus_alphas_cumprod_t = extract(self.sqrt_one_minus_alphas_cumprod, t, x.shape)
sqrt_one_minus_alphas_cumprod_prev_t = extract(self.sqrt_one_minus_alphas_cumprod_prev, t, x.shape)
sqrt_alphas_cumprod_t = extract(self.sqrt_alphas_cumprod, t, x.shape)
pred_noise = model(x, t)
pred_x0 = sqrt_alphas_cumprod_prev_t * (x - sqrt_one_minus_alphas_cumprod_t * pred_noise) / sqrt_alphas_cumprod_t
x0_direction = sqrt_one_minus_alphas_cumprod_prev_t * pred_noise
return pred_x0 + x0_direction
def p_sample_with_classifier(self, model, x, t, t_index, y=None, **kwargs):
if y is None:
return self.p_sample_ddim(model, x, t, t_index=t_index)
cfs = kwargs.get("cfs", 1)
sqrt_alphas_cumprod_prev_t = extract(self.sqrt_alphas_cumprod_prev, t, x.shape)
sqrt_one_minus_alphas_cumprod_t = extract(self.sqrt_one_minus_alphas_cumprod, t, x.shape)
sqrt_one_minus_alphas_cumprod_prev_t = extract(self.sqrt_one_minus_alphas_cumprod_prev, t, x.shape)
sqrt_alphas_cumprod_t = extract(self.sqrt_alphas_cumprod, t, x.shape)
pred_noise = model(x, t)
score = self.cond_fn(x, t, y=y) * cfs
pred_noise = pred_noise - sqrt_one_minus_alphas_cumprod_t * score # update noise
pred_x0 = sqrt_alphas_cumprod_prev_t * (x - sqrt_one_minus_alphas_cumprod_t * pred_noise) / sqrt_alphas_cumprod_t
x0_direction = sqrt_one_minus_alphas_cumprod_prev_t * pred_noise
return pred_x0 + x0_direction
一些细节
classifier的训练
classifier的训练与扩散模型的训练可以是独立的。在训练classifier的时候可以噪声预测模型(Unet)的encode部分作为主干,在后面接了一个分类层。并且需要与相应的扩散模型相同的噪声分布对classifier进行训练。训练数据集如 [ ( x 1 t , t , y 1 ) , ( x 2 t , t , y 2 ) , . . . , ( x N t , t , y N ) ] [(x_1^t,t, y_1), (x_2^t,t, y_2), ..., (x_N^t,t, y_N)] [(x1t,t,y1),(x2t,t,y2),...,(xNt,t,yN)]。 t t t是对时间步的采样, x t x^t xt是 x x x在时间步 t t t的输出。训练完成后,采用上面的算法集成到采样过程中。
gradient score的作用
在上面的采样算法我们看到有一个gradient scale s s s来对梯度进行拉伸。
实验视角
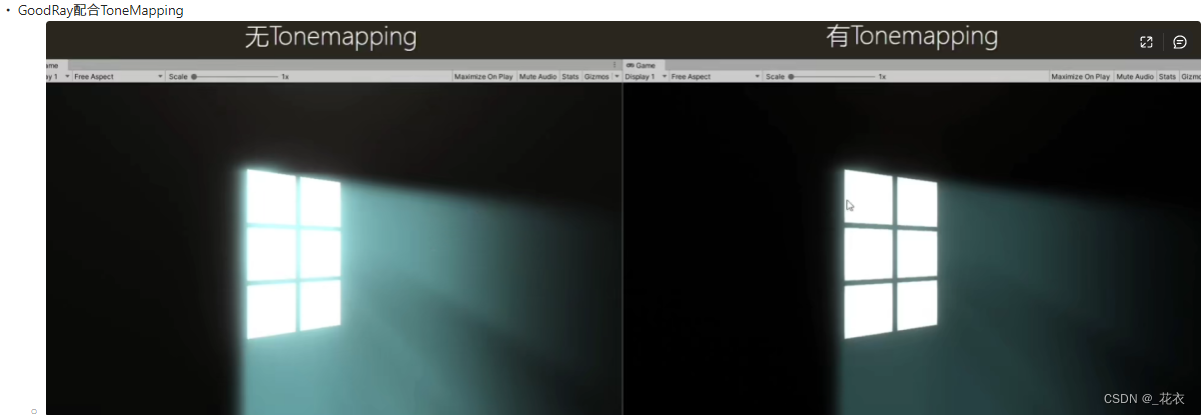
一般来说当
s
=
1
s=1
s=1时,大约能保证生成的图片50%是想要的类别4,随着
s
s
s的增大,这个比例也能够增加。如下图,当
s
s
s增加到10,此时生成的图片都是期望的类别。因此
s
s
s也称之为guidance scale。

其实理解这个scale还有另一个视角
s ∇ x t log ( p ϕ ( y ∣ x t ) ) = ∇ x t log ( p ϕ ( y ∣ x t ) s ) s\nabla_{x_t} \log (p_\phi(y|x_t)) = \nabla_{x_t} \log (p_\phi(y|x_t)^s) s∇xtlog(pϕ(y∣xt))=∇xtlog(pϕ(y∣xt)s),当 s > 1 s>1 s>1他相当于对分布 p ϕ ( y ∣ x t ) p_\phi(y|x_t) pϕ(y∣xt)进行了一个指数拉升,从而带来更大的梯度更新收益。
根据DM的采样过程,当没有classifier guided时,在时刻
t
t
t,的采样过程应当是
x
t
−
1
=
μ
θ
(
x
t
,
t
)
+
σ
(
t
)
ϵ
,
其中
ϵ
∈
N
(
ϵ
;
0
,
I
)
=
1
α
t
(
x
t
−
1
−
α
t
1
−
α
‾
t
ϵ
θ
(
x
t
,
t
)
)
⏟
μ
θ
(
x
t
,
t
)
+
σ
(
t
)
ϵ
(17)
\begin{aligned} x_{t-1} &= \mu_{\theta}(x_t, t) + \sigma(t) \epsilon,其中 \epsilon \in \mathcal{N}(\epsilon; 0, \textbf{I}) \\ & = \underbrace{\frac{1}{\sqrt{\alpha_t}} (x_t - \frac{1 - \alpha_t }{\sqrt{1 - \overline{\alpha}_t}}\epsilon_\theta(x_t, t))}_{\mu_\theta(x_t, t)} + \sigma(t) \epsilon \end{aligned} \tag{17}
xt−1=μθ(xt,t)+σ(t)ϵ,其中ϵ∈N(ϵ;0,I)=μθ(xt,t)
αt1(xt−1−αt1−αtϵθ(xt,t))+σ(t)ϵ(17)
当加了classifier guided相当于将
μ
θ
(
x
t
,
t
)
\mu_{\theta}(x_t, t)
μθ(xt,t)向预测类别为
y
y
y的方向更新了一小步。
s
s
s是控制更新的幅值。
x
t
−
1
=
μ
θ
(
x
t
,
t
)
+
s
∇
x
t
log
p
ϕ
(
y
∣
x
t
)
∣
x
t
=
μ
θ
(
x
t
,
t
)
+
σ
(
t
)
ϵ
,
其中
ϵ
∈
N
(
ϵ
;
0
,
I
)
\begin{align} x_{t-1} &=& \mu_{\theta}(x_t, t) + s\nabla_{x_t} \log p_{\phi} (y|x_t)|_{x_t = \mu_{\theta}(x_t, t)} + \sigma(t) \epsilon,其中 \epsilon \in \mathcal{N}(\epsilon; 0, \textbf{I}) \tag{18} \end{align}
xt−1=μθ(xt,t)+s∇xtlogpϕ(y∣xt)∣xt=μθ(xt,t)+σ(t)ϵ,其中ϵ∈N(ϵ;0,I)(18)
参考文献
附录
式12推导验证
−
1
2
(
x
t
−
μ
−
Σ
g
)
T
Σ
−
1
(
x
t
−
μ
−
Σ
g
)
+
1
2
g
T
Σ
g
+
C
2
=
−
1
2
(
x
t
T
−
μ
T
−
g
T
Σ
T
)
Σ
−
1
(
x
t
−
μ
−
Σ
g
)
+
1
2
g
T
Σ
g
+
C
2
=
−
1
2
(
x
t
T
−
μ
T
−
g
T
Σ
T
)
Σ
−
1
(
x
t
−
μ
−
Σ
g
)
+
1
2
g
T
Σ
g
+
C
2
=
−
1
2
(
x
t
T
Σ
−
1
−
μ
T
Σ
−
1
−
g
T
Σ
T
Σ
−
1
⏟
g
T
)
(
x
t
−
μ
−
Σ
g
)
+
1
2
g
T
Σ
g
+
C
2
=
−
1
2
(
x
t
T
Σ
−
1
(
x
t
−
μ
−
Σ
g
)
−
μ
T
Σ
−
1
(
x
t
−
μ
−
Σ
g
)
−
g
T
(
x
t
−
μ
−
Σ
g
)
)
+
1
2
g
T
Σ
g
+
C
2
=
−
1
2
(
x
t
T
Σ
−
1
(
x
t
−
μ
)
−
μ
T
Σ
−
1
(
x
t
−
μ
)
)
⏟
(
x
t
−
μ
)
T
Σ
−
1
(
x
t
−
μ
)
−
1
2
(
−
g
T
(
x
t
−
μ
−
Σ
g
)
+
(
−
x
t
T
Σ
−
1
Σ
g
)
⏟
−
x
t
T
g
+
μ
T
Σ
−
1
Σ
g
⏟
μ
T
g
)
+
1
2
g
T
Σ
g
+
C
2
=
−
1
2
(
x
t
−
μ
)
T
Σ
−
1
(
x
t
−
μ
)
+
(
x
t
−
μ
)
g
+
C
2
\begin{align*} &- \frac{1}{2} (x_t - \mu - \Sigma g)^T \Sigma^{-1} (x_t - \mu- \Sigma g) + \frac{1}{2}g^T\Sigma g + C_2 \\ = &- \frac{1}{2} (x_t^T - \mu^T - g^T \Sigma^T) \Sigma^{-1} (x_t - \mu - \Sigma g) + \frac{1}{2}g^T\Sigma g + C_2 \\ = &- \frac{1}{2} (x_t^T - \mu^T - g^T \Sigma^T) \Sigma^{-1} (x_t - \mu - \Sigma g) + \frac{1}{2}g^T\Sigma g + C_2 \\ \\ = & - \frac{1}{2} (x_t^T \Sigma^{-1} - \mu^T \Sigma^{-1} - \underbrace{g^T \Sigma^T \Sigma^{-1}}_{g^T} )(x_t - \mu - \Sigma g) + \frac{1}{2}g^T\Sigma g + C_2 \\ = & - \frac{1}{2} (x_t^T \Sigma^{-1} (x_t - \mu - \Sigma g) - \mu^T \Sigma^{-1} (x_t - \mu - \Sigma g) - g^T (x_t - \mu - \Sigma g)) + \frac{1}{2}g^T\Sigma g + C_2 \\ = & - \frac{1}{2} \underbrace{(x_t^T \Sigma^{-1} (x_t - \mu ) - \mu^T \Sigma^{-1} (x_t - \mu))}_{(x_t - \mu)^T \Sigma^{-1} (x_t - \mu)} - \frac{1}{2} ( - g^T (x_t - \mu - \Sigma g) + \underbrace{(- x_t^T \Sigma^{-1}\Sigma g)}_{-x_t^Tg} + \underbrace{\mu^T \Sigma^{-1}\Sigma g}_{\mu^Tg}) + \frac{1}{2}g^T\Sigma g + C_2 \\ = & - \frac{1}{2} (x_t - \mu)^T \Sigma^{-1} (x_t - \mu) + (x_t - \mu) g + C_2 \\ \end{align*}
======−21(xt−μ−Σg)TΣ−1(xt−μ−Σg)+21gTΣg+C2−21(xtT−μT−gTΣT)Σ−1(xt−μ−Σg)+21gTΣg+C2−21(xtT−μT−gTΣT)Σ−1(xt−μ−Σg)+21gTΣg+C2−21(xtTΣ−1−μTΣ−1−gT
gTΣTΣ−1)(xt−μ−Σg)+21gTΣg+C2−21(xtTΣ−1(xt−μ−Σg)−μTΣ−1(xt−μ−Σg)−gT(xt−μ−Σg))+21gTΣg+C2−21(xt−μ)TΣ−1(xt−μ)
(xtTΣ−1(xt−μ)−μTΣ−1(xt−μ))−21(−gT(xt−μ−Σg)+−xtTg
(−xtTΣ−1Σg)+μTg
μTΣ−1Σg)+21gTΣg+C2−21(xt−μ)TΣ−1(xt−μ)+(xt−μ)g+C2
Deep unsupervised learning using nonequilibrium thermodynamics ↩︎
[Denoising Diffusion Implicit Models (DDIM) Sampling](https://arxiv.org/abs/2010.02502) ↩︎
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. arXiv:arXiv:1907.05600, 2020. ↩︎
Diffusion Models Beat GANs on Image Synthesis ↩︎
![前沿重器[35] | 提示工程和提示构造技巧](https://img-blog.csdnimg.cn/img_convert/7e58021e19c2a1fd75a3989cf3729549.png)










![[JVM]再聊 CMS 收集器](https://img-blog.csdnimg.cn/a4fe8c81a83745e8bf7d9c1cf60639d9.png)