ArrayList
特点:元素有放入顺序,元素可重复
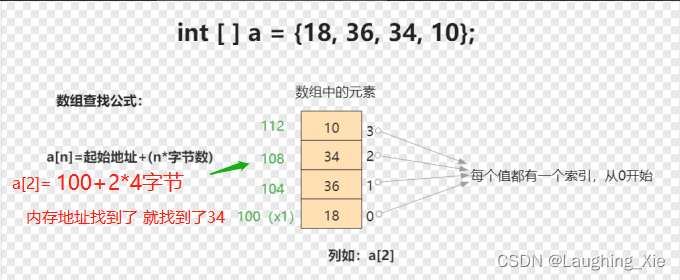
存储结构:底层采用数组来实现的,数组在内存中是需要连续的存储单元的
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
数组:采用一段连续的存储单元来存储数据。特点是查询的时间复杂度是O(1),删除插入为O(N),查询快,删除插入慢


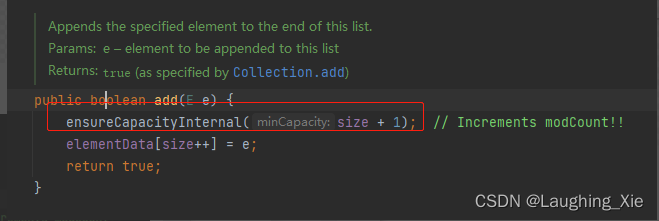
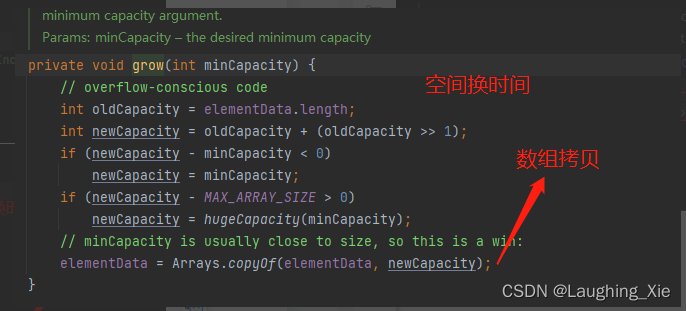
ArrayList 新增数据的时候,默认尾插法,同时还会有一个扩容方法,扩容后,将原有数据拷贝到新的数组之中
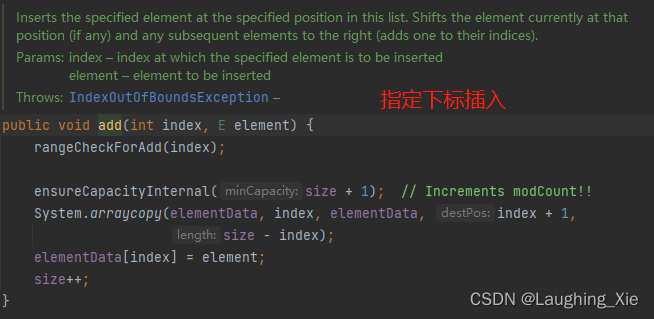
Cloneable:
ArrayList支持拷贝:实现Cloneable接口,重写clone方法、方法内容默认调用父类的clone方法
浅拷贝:基础类型的变量拷贝之后是独立的,不会随着源变量变动而变 ,String类型拷贝之后也是独立的;引用类型拷贝的是引用地址,拷贝前后的变量引用同一个堆中的对象
深拷贝: 变量的所有引用类型变量(除了String)都需要实现Cloneable(数组可以直接调用clone方法),clone方法中,引用类型需要各 自调用clone,重新赋值
浅拷贝深拷贝区别:主要针对于引用数据类型而言,浅拷贝只是拷贝了一份指针引用,其实源对象并没有新增,两份数据都是引用的一份数据。而深拷贝则会在内存中重新开辟一块空间,同时新增一份地址值,此时是两个不同的源数据。
java的传参,基本类型和引用类型传参:java在方法传递参数时,是将变量复制一份,然后传入方法体去执行。复制的是栈中的内容,所以基本类型是复制的变量名和值,值变了不影响源变量,引用类型复制的是变量名和值(引用地址),对象变了,会影响源变量(引用地址是一样的)
String:是不可变对象,重新赋值时,会在常量表新生成字符串(如果已有,直接取他的引用地址值),将新字符串的引用地址赋值给栈中的新变量,因此源变量不会受影响 。
------------------------------------------------------------------------
LinkedList
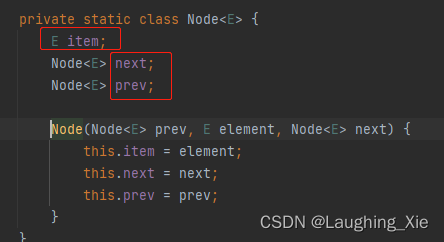
存储结构:底层采用链表来实现的(双向链表)
链表:是一种物理存储单元上非连续、非顺序的存储结构,不需要连续的内存空间
特点:插入、删除时间复杂度O(1)查找遍历时间复杂度O(N),插入快查找慢,查找的时候只能通过head节点一个一个往下查,需要对整个链表进行遍历。

public class LinkedList {
public class LinkedList {
public static void main(String[] args) {
Node head = new Node("Head");
Node zhang=new Node("张三");
Node li=new Node("李四");
head.next=zhang;
head.next.next=li;
System.out.println(head.data);
System.out.println(head.next.data);
System.out.println("============");
//删除张三,让第二个节点为李四
head.next=null;
head.next=li;
System.out.println(head.data);
System.out.println(head.next.data);
}
}
//节点
class Node {
public Node next;
public Object data;
public Node(Object data) {
this.data = data;
}
}



ArrayList 和 AinkedList同时add一个元素,都是默认从尾部新增一个元素,如果ArrayList指定 了容量那么ArrayList效率更高,否则LinkedList效率更高(未指定容量的时候,会存在扩容拷贝的性能损耗)。
------------------------------------------------------------------------
HashMap
特点: key,value存储,key可以为null,同样的key会被覆盖掉,后面的值会覆盖前面的值。
存储结构: 底层采用数组、链表、红黑树来实现的,数组是需要连续的存储单元