只看语义分割。
# ---------------------------------------------------------------
# Copyright (c) 2021, NVIDIA Corporation. All rights reserved.
#
# This work is licensed under the NVIDIA Source Code License
# ---------------------------------------------------------------
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from functools import partial
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from .modules import ModuleParallel, LayerNormParallel, num_parallel, TokenExchange
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = ModuleParallel(nn.Linear(in_features, hidden_features))
self.dwconv = DWConv(hidden_features)
self.act = ModuleParallel(act_layer())
self.fc2 = ModuleParallel(nn.Linear(hidden_features, out_features))
self.drop = ModuleParallel(nn.Dropout(drop))
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x, H, W):
x = self.fc1(x)
x = [self.dwconv(x[0], H, W), self.dwconv(x[1], H, W)]
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = ModuleParallel(nn.Linear(dim, dim, bias=qkv_bias))
self.kv = ModuleParallel(nn.Linear(dim, dim * 2, bias=qkv_bias))
self.attn_drop = ModuleParallel(nn.Dropout(attn_drop))
self.proj = ModuleParallel(nn.Linear(dim, dim))
self.proj_drop = ModuleParallel(nn.Dropout(proj_drop))
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = ModuleParallel(nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio))
self.norm = LayerNormParallel(dim)
self.exchange = TokenExchange()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x, H, W, mask):
B, N, C = x[0].shape
q = self.q(x)
q = [q_.reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) for q_ in q]
if self.sr_ratio > 1:
x = [x_.permute(0, 2, 1).reshape(B, C, H, W) for x_ in x]
x = self.sr(x)
x = [x_.reshape(B, C, -1).permute(0, 2, 1) for x_ in x]
x = self.norm(x)
kv = self.kv(x)
kv = [kv_.reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) for kv_ in kv]
else:
kv = self.kv(x)
kv = [kv_.reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) for kv_ in kv]
k, v = [kv[0][0], kv[1][0]], [kv[0][1], kv[1][1]]
attn = [(q_ @ k_.transpose(-2, -1)) * self.scale for (q_, k_) in zip(q, k)]
attn = [attn_.softmax(dim=-1) for attn_ in attn]
attn = self.attn_drop(attn)
x = [(attn_ @ v_).transpose(1, 2).reshape(B, N, C) for (attn_, v_) in zip(attn, v)]
x = self.proj(x)
x = self.proj_drop(x)
if mask is not None:
x = [x_ * mask_.unsqueeze(2) for (x_, mask_) in zip(x, mask)]
x = self.exchange(x, mask, mask_threshold=0.02)
return x
class PredictorLG(nn.Module):
""" Image to Patch Embedding from DydamicVit
"""
def __init__(self, embed_dim=384):
super().__init__()
self.score_nets = nn.ModuleList([nn.Sequential(
nn.LayerNorm(embed_dim),
nn.Linear(embed_dim, embed_dim),
nn.GELU(),
nn.Linear(embed_dim, embed_dim // 2),
nn.GELU(),
nn.Linear(embed_dim // 2, embed_dim // 4),
nn.GELU(),
nn.Linear(embed_dim // 4, 2),
nn.LogSoftmax(dim=-1)
) for _ in range(num_parallel)])
def forward(self, x):
x = [self.score_nets[i](x[i]) for i in range(num_parallel)]
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=LayerNormParallel, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
# self.score = PredictorLG(dim)
self.attn = Attention(
dim,
num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = ModuleParallel(DropPath(drop_path)) if drop_path > 0. else ModuleParallel(nn.Identity())
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
# self.exchange = TokenExchange()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x, H, W, mask=None):
B = x[0].shape[0]
# norm1 = self.norm1(x)
# score = self.score(norm1)
# mask = [F.gumbel_softmax(score_.reshape(B, -1, 2), hard=True)[:, :, 0] for score_ in score]
# if mask is not None:
# norm = [norm_ * mask_.unsqueeze(2) for (norm_, mask_) in zip(norm, mask)]
f = self.drop_path(self.attn(self.norm1(x), H, W, mask))
x = [x_ + f_ for (x_, f_) in zip (x, f)]
f = self.drop_path(self.mlp(self.norm2(x), H, W))
x = [x_ + f_ for (x_, f_) in zip (x, f)]
# if mask is not None:
# x = self.exchange(x, mask, mask_threshold=0.02)
return x
class OverlapPatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=7, stride=4, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.H, self.W = img_size[0] // patch_size[0], img_size[1] // patch_size[1]
self.num_patches = self.H * self.W
self.proj = ModuleParallel(nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=stride,
padding=(patch_size[0] // 2, patch_size[1] // 2)))
self.norm = LayerNormParallel(embed_dim)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
x = self.proj(x)
_, _, H, W = x[0].shape
x = [x_.flatten(2).transpose(1, 2) for x_ in x]
x = self.norm(x)
return x, H, W
class MixVisionTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=LayerNormParallel,
depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1]):
super().__init__()
self.num_classes = num_classes
self.depths = depths
self.embed_dims = embed_dims
# patch_embed
self.patch_embed1 = OverlapPatchEmbed(img_size=img_size, patch_size=7, stride=4, in_chans=in_chans,
embed_dim=embed_dims[0])
self.patch_embed2 = OverlapPatchEmbed(img_size=img_size // 4, patch_size=3, stride=2, in_chans=embed_dims[0],
embed_dim=embed_dims[1])
self.patch_embed3 = OverlapPatchEmbed(img_size=img_size // 8, patch_size=3, stride=2, in_chans=embed_dims[1],
embed_dim=embed_dims[2])
self.patch_embed4 = OverlapPatchEmbed(img_size=img_size // 16, patch_size=3, stride=2, in_chans=embed_dims[2],
embed_dim=embed_dims[3])
predictor_list = [PredictorLG(embed_dims[i]) for i in range(len(depths))]
self.score_predictor = nn.ModuleList(predictor_list)
# transformer encoder
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
self.block1 = nn.ModuleList([Block(
dim=embed_dims[0], num_heads=num_heads[0], mlp_ratio=mlp_ratios[0], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i], norm_layer=norm_layer,
sr_ratio=sr_ratios[0])
for i in range(depths[0])])
self.norm1 = norm_layer(embed_dims[0])
cur += depths[0]
self.block2 = nn.ModuleList([Block(
dim=embed_dims[1], num_heads=num_heads[1], mlp_ratio=mlp_ratios[1], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i], norm_layer=norm_layer,
sr_ratio=sr_ratios[1])
for i in range(depths[1])])
self.norm2 = norm_layer(embed_dims[1])
cur += depths[1]
self.block3 = nn.ModuleList([Block(
dim=embed_dims[2], num_heads=num_heads[2], mlp_ratio=mlp_ratios[2], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i], norm_layer=norm_layer,
sr_ratio=sr_ratios[2])
for i in range(depths[2])])
self.norm3 = norm_layer(embed_dims[2])
cur += depths[2]
self.block4 = nn.ModuleList([Block(
dim=embed_dims[3], num_heads=num_heads[3], mlp_ratio=mlp_ratios[3], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i], norm_layer=norm_layer,
sr_ratio=sr_ratios[3])
for i in range(depths[3])])
self.norm4 = norm_layer(embed_dims[3])
# classification head
# self.head = nn.Linear(embed_dims[3], num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
'''
def init_weights(self, pretrained=None):
if isinstance(pretrained, str):
logger = get_root_logger()
load_checkpoint(self, pretrained, map_location='cpu', strict=False, logger=logger)
'''
def reset_drop_path(self, drop_path_rate):
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(self.depths))]
cur = 0
for i in range(self.depths[0]):
self.block1[i].drop_path.drop_prob = dpr[cur + i]
cur += self.depths[0]
for i in range(self.depths[1]):
self.block2[i].drop_path.drop_prob = dpr[cur + i]
cur += self.depths[1]
for i in range(self.depths[2]):
self.block3[i].drop_path.drop_prob = dpr[cur + i]
cur += self.depths[2]
for i in range(self.depths[3]):
self.block4[i].drop_path.drop_prob = dpr[cur + i]
def freeze_patch_emb(self):
self.patch_embed1.requires_grad = False
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed1', 'pos_embed2', 'pos_embed3', 'pos_embed4', 'cls_token'} # has pos_embed may be better
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x[0].shape[0]
outs0, outs1 = [], []
masks = []
# stage 1
x, H, W = self.patch_embed1(x)
for i, blk in enumerate(self.block1):
score = self.score_predictor[0](x)
mask = [F.softmax(score_.reshape(B, -1, 2), dim=2)[:, :, 0] for score_ in score] # mask_: [B, N]
masks.append(mask)
x = blk(x, H, W, mask)
x = self.norm1(x)
x = [x_.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() for x_ in x]
outs0.append(x[0])
outs1.append(x[1])
# stage 2
x, H, W = self.patch_embed2(x)
for i, blk in enumerate(self.block2):
score = self.score_predictor[1](x)
mask = [F.softmax(score_.reshape(B, -1, 2), dim=2)[:, :, 0] for score_ in score] # mask_: [B, N]
masks.append(mask)
x = blk(x, H, W, mask)
x = self.norm2(x)
x = [x_.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() for x_ in x]
outs0.append(x[0])
outs1.append(x[1])
# stage 3
x, H, W = self.patch_embed3(x)
for i, blk in enumerate(self.block3):
score = self.score_predictor[2](x)
mask = [F.softmax(score_.reshape(B, -1, 2), dim=2)[:, :, 0] for score_ in score] # mask_: [B, N]
masks.append(mask)
x = blk(x, H, W, mask)
x = self.norm3(x)
x = [x_.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() for x_ in x]
outs0.append(x[0])
outs1.append(x[1])
# stage 4
x, H, W = self.patch_embed4(x)
for i, blk in enumerate(self.block4):
score = self.score_predictor[3](x)
mask = [F.softmax(score_.reshape(B, -1, 2), dim=2)[:, :, 0] for score_ in score] # mask_: [B, N]
masks.append(mask)
x = blk(x, H, W, mask)
x = self.norm4(x)
x = [x_.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() for x_ in x]
outs0.append(x[0])
outs1.append(x[1])
return [outs0, outs1], masks
def forward(self, x):
x, masks = self.forward_features(x)
return x, masks
class DWConv(nn.Module):
def __init__(self, dim=768):
super(DWConv, self).__init__()
self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, bias=True, groups=dim)
def forward(self, x, H, W):
B, N, C = x.shape
x = x.transpose(1, 2).view(B, C, H, W)
x = self.dwconv(x)
x = x.flatten(2).transpose(1, 2)
return x
class mit_b0(MixVisionTransformer):
def __init__(self, **kwargs):
super(mit_b0, self).__init__(
patch_size=4, embed_dims=[32, 64, 160, 256], num_heads=[1, 2, 5, 8], mlp_ratios=[4, 4, 4, 4],
qkv_bias=True, norm_layer=LayerNormParallel, depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1],
drop_rate=0.0, drop_path_rate=0.1)
class mit_b1(MixVisionTransformer):
def __init__(self, **kwargs):
super(mit_b1, self).__init__(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[4, 4, 4, 4],
qkv_bias=True, norm_layer=LayerNormParallel, depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1],
drop_rate=0.0, drop_path_rate=0.1)
class mit_b2(MixVisionTransformer):
def __init__(self, **kwargs):
super(mit_b2, self).__init__(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[4, 4, 4, 4],
qkv_bias=True, norm_layer=LayerNormParallel, depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1],
drop_rate=0.0, drop_path_rate=0.1)
class mit_b3(MixVisionTransformer):
def __init__(self, **kwargs):
super(mit_b3, self).__init__(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[4, 4, 4, 4],
qkv_bias=True, norm_layer=LayerNormParallel, depths=[3, 4, 18, 3], sr_ratios=[8, 4, 2, 1],
drop_rate=0.0, drop_path_rate=0.1)
class mit_b4(MixVisionTransformer):
def __init__(self, **kwargs):
super(mit_b4, self).__init__(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[4, 4, 4, 4],
qkv_bias=True, norm_layer=LayerNormParallel, depths=[3, 8, 27, 3], sr_ratios=[8, 4, 2, 1],
drop_rate=0.0, drop_path_rate=0.1)
class mit_b5(MixVisionTransformer):
def __init__(self, **kwargs):
super(mit_b5, self).__init__(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[4, 4, 4, 4],
qkv_bias=True, norm_layer=LayerNormParallel, depths=[3, 6, 40, 3], sr_ratios=[8, 4, 2, 1],
drop_rate=0.0, drop_path_rate=0.1)
就拿b0为例吧:假设输入的大小为rgb=(1,3,480,640),depth=(1,1,480,640)。

我们直接跳到MixvisionTransformer类的forward函数,再跳到forward feature中:根据文中我们可知backbone采用的segformer。
这里用到了索引x[0],说明x不只是一个变量,应该是两个输入。
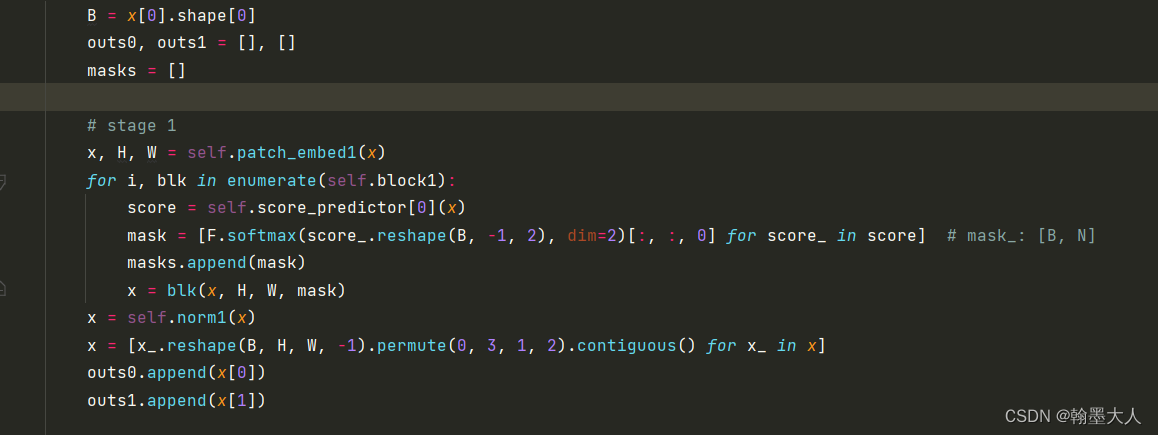
x首先经过patch_embed1,我们再跳到patch_embed1中:
步长为4,卷积核为7,embeddim=32,这里采用的重叠的卷积,和之前segformer一样,目的是替代位置编码。

在OverlapPatchEmbed:

首先经过一个卷积:这里是并行的。这里有个小问题,inchannel是固定的为3,那么如何处理depth呢?
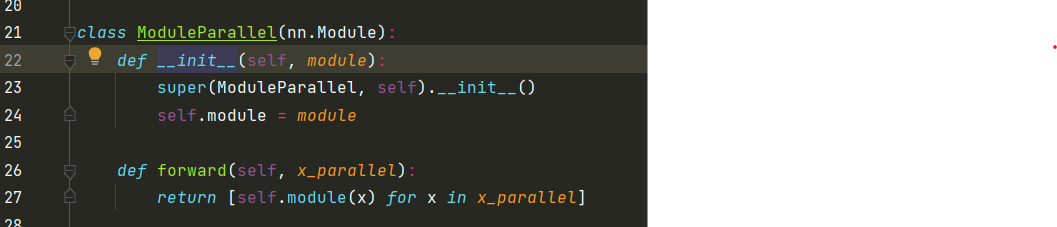
我们看ModuleParallel类,再对应到proj中,module就是卷积,proj用来处理x,所以x_parallel就是x,这里使用了一个循环,for x in x_parallel是因为x是两个输入,即rgb和depth。所以返回的是一个列表。
然后看卷积的参数,输出通道为32,
再回到OverlapPatchEmbed中,获取x[0]的大小,然后将hw展开为N,并与c交换顺序,则维度变为(B,N,C)。然后进行layernorm,也是并行的。
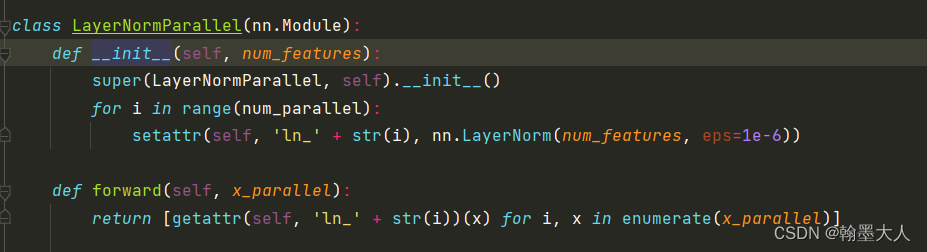
注意num_feature和num_parallel不一样,num_parallel = 2,那么i循环两次,当i为0,1时,分别得到两个layernorm。

然后self.norm实例化LayerNormParallel,而x作为self.norm输入,即x为x_parallel,由前面知道x是由rgb和depth组成的列表,所以在LayerNormParallel的forward函数中使用了enumerate,获得索引和对应的值。然后x再经过getattr(self, ‘ln_’ + str(i))(x)处理,大小不变。
最后返回x和进过重叠卷积后的h,w。这样patch_embed1计算完毕。x是一个list包含两个(1,19200,32),h为120,w为160。
然后看下一个循环:

我们进入self.block:遍历depth[0]次,即3次。

我们看block的构成,因为输入参数中有mask,我们先看mask是如何获得的。

首先x输入到得分预测函数中:由一系列的predictorlg组成的。注意看里面是由i个predictorlg组成的列表。

我们进入到predictorlg中:num_parallel=2
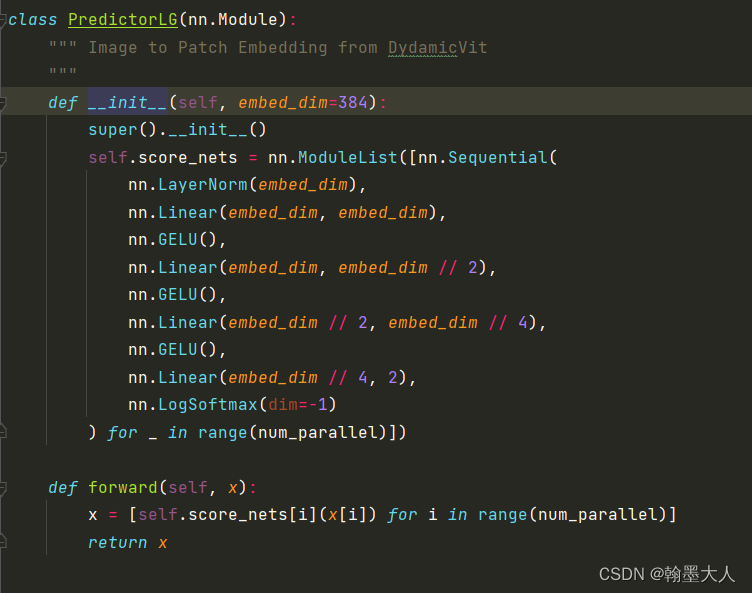
直接看forward函数:当i=0时,x=self.score_nets[0] (x[0]),即对其中一个模态求得分。在self.score_nets中也有两个nn.Sequential,一个模态对应一个。最后放在列表中。
我们看如何求score的,三个linear,gelu,最后再经过一个linear,输出通道为2,再进过一个logsoftmax函数。logsoftmax就是对softmax的结果进行log。维度由32变为2。那么x变为[(1,19200,2),(1,19200,2)]。
代码中直接将四个predictorlg全部放在一个列表中,然后每个stage取一个。
我们将x输入到score = self.score_predictor[0] (x)中得到一个列表,下一步将得分转换为mask。

score_遍历两次,首先将score_reshape,维度是不变的,然后对第二个维度即通道进行softmax,最后取前两个维度,即将c去掉,mask即为(1,19200)。
接着将x, H, W, mask共同输入到block中。首先对x进行layernorm处理。
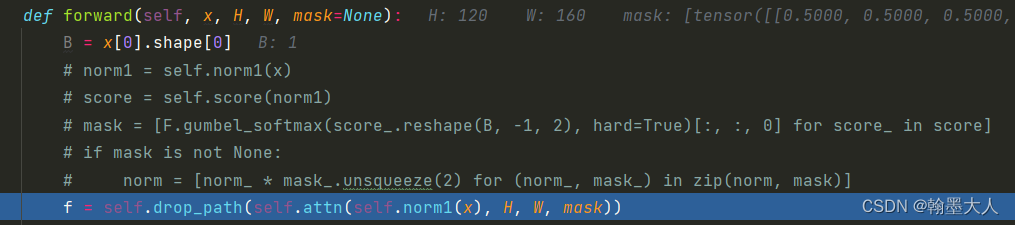
接着输入到attn中,我们跳到attn中看一下:
首先对x进行linear处理,获得q和普通的transformer过程类似。

接着对q进行reshape:和vit类似,(1,19200,32)—>(1,19200,1,32)—>(1,1,19200,32)。

接着将x进行reshape:将x reshape为图片(1,32,120,160)。

下一步来获得k和v:通过一个卷积核为8,卷积核为8的卷积。


x变为[(1,32,15,20),(1,32,15,20)]。再将x转换为b,n,c大小。(1,300,32)。

然后进行kv的计算:将维度升高两倍。(1,300,64)。


再reshape为多头形式。(2,1,1,300,32)。
下一步根据索引取kv。第一个索引取列表中的哪一个,第二个索引取哪一个维度,这样rgb和depth都有一个k和一个v。k=list[(1,1,300,32),(1,1,300,32)],v=list[(1,1,300,32),(1,1,300,32)]。

然后进行qk相乘:(1,1,19200,300)。接着softamx,drop。

再接着与v相乘,帮助那换为(b,n,c)形式。[1,19200,32]。这里和之前的transformer不一样的是这里是图像进行相乘再转换为序列,普通的transformer是直接序列进行相乘。
接着对(x,mask)进行循环遍历,x是[(1,19200,32),(1,19200,32)],mask是[(1,19200),(1,19200)]。首先将mask增加一个维度。再与x相乘。结果为[(1,19200,32),(1,19200,32)]。

再将x,mask,阈值仪器输入到exchange函数中。

首先返回x大小的两个全0矩阵x0,x1,接着x[0][mask[0] >= mask_threshold],x[0]中,mask[0]大于阈值的值设置为true。
这里可以试验一下:x[0][mask[0] >= mask_threshold]会选出y0中mask大于阈值所对应的行。
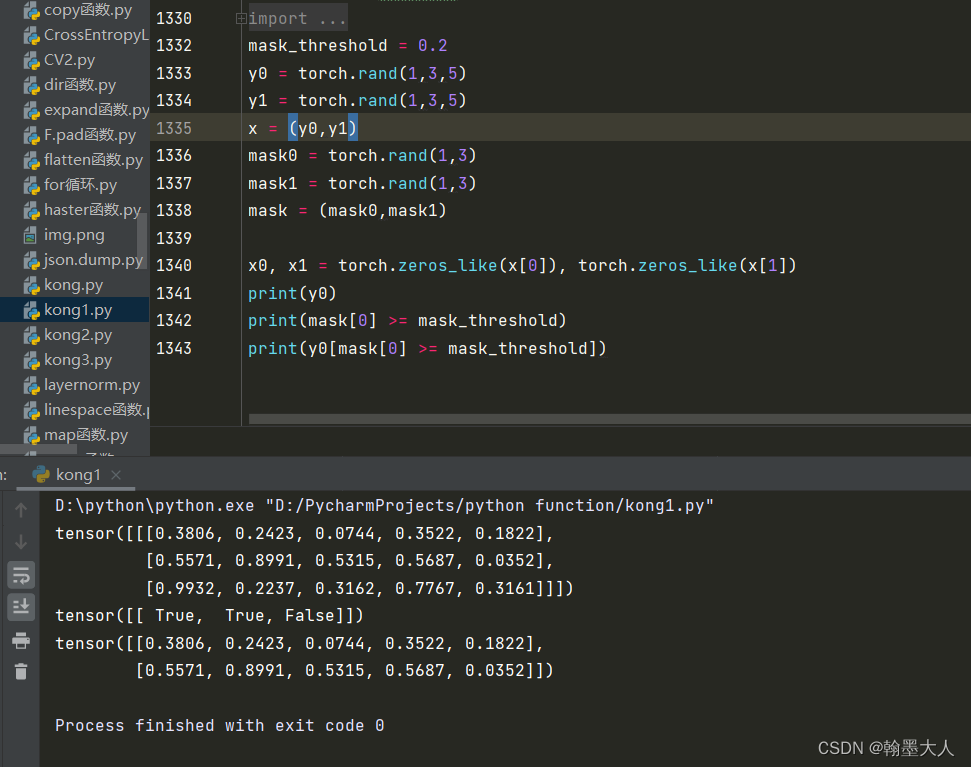
同理x0[mask[0] >= mask_threshold]会选出对应的大于0.02的行。然后将0用x[0]选出的填充。这里相当于x0和x1分别用rgb和depth进行填充。最后返回x0,x1。都为(1,19200,32)。x即为包含两个输出的list。这样attention就计算完毕了。
剩下的就是transformer的mlp,norm计算。
接着将x reshape为图片大小[(1,32,120,160),(1,32,120,160)]。

将上一层的输出,作为下一个阶段的输入。过程一样就不一一看了。
x, H, W = self.patch_embed2(x)
for i, blk in enumerate(self.block2):
score = self.score_predictor[1](x)
mask = [F.softmax(score_.reshape(B, -1, 2), dim=2)[:, :, 0] for score_ in score] # mask_: [B, N]
masks.append(mask)
x = blk(x, H, W, mask)
x = self.norm2(x)
x = [x_.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() for x_ in x]
outs0.append(x[0])
outs1.append(x[1])
# stage 3
x, H, W = self.patch_embed3(x)
for i, blk in enumerate(self.block3):
score = self.score_predictor[2](x)
mask = [F.softmax(score_.reshape(B, -1, 2), dim=2)[:, :, 0] for score_ in score] # mask_: [B, N]
masks.append(mask)
x = blk(x, H, W, mask)
x = self.norm3(x)
x = [x_.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() for x_ in x]
outs0.append(x[0])
outs1.append(x[1])
# stage 4
x, H, W = self.patch_embed4(x)
for i, blk in enumerate(self.block4):
score = self.score_predictor[3](x)
mask = [F.softmax(score_.reshape(B, -1, 2), dim=2)[:, :, 0] for score_ in score] # mask_: [B, N]
masks.append(mask)
x = blk(x, H, W, mask)
x = self.norm4(x)
x = [x_.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() for x_ in x]
outs0.append(x[0])
outs1.append(x[1])
最后输出包含四个tensor的列表。
rgb.size=depth.size=[(1,32,120,160),(1,64,60,80),(1,160,30,40),(1,256,15,20)]。
然后在segformer文件中:
class WeTr(nn.Module):
def __init__(self, backbone, num_classes=20, embedding_dim=256, pretrained=True):
super().__init__()
self.num_classes = num_classes
self.embedding_dim = embedding_dim
self.feature_strides = [4, 8, 16, 32]
self.num_parallel = num_parallel
#self.in_channels = [32, 64, 160, 256]
#self.in_channels = [64, 128, 320, 512]
self.encoder = getattr(mix_transformer, backbone)()
self.in_channels = self.encoder.embed_dims
## initilize encoder
if pretrained:
state_dict = torch.load('pretrained/' + backbone + '.pth')
state_dict.pop('head.weight')
state_dict.pop('head.bias')
state_dict = expand_state_dict(self.encoder.state_dict(), state_dict, self.num_parallel)
self.encoder.load_state_dict(state_dict, strict=True)
self.decoder = SegFormerHead(feature_strides=self.feature_strides, in_channels=self.in_channels,
embedding_dim=self.embedding_dim, num_classes=self.num_classes)
self.alpha = nn.Parameter(torch.ones(self.num_parallel, requires_grad=True))
self.register_parameter('alpha', self.alpha)
def get_param_groups(self):
param_groups = [[], [], []]
for name, param in list(self.encoder.named_parameters()):
if "norm" in name:
param_groups[1].append(param)
else:
param_groups[0].append(param)
for param in list(self.decoder.parameters()):
param_groups[2].append(param)
return param_groups
def forward(self, x):
x, masks = self.encoder(x)
x = [self.decoder(x[0]), self.decoder(x[1])]
ens = 0
alpha_soft = F.softmax(self.alpha)
for l in range(self.num_parallel):
ens += alpha_soft[l] * x[l].detach()
x.append(ens)
return x, masks
mix_transformer作为encoder处理完之后,开始输入到decoder处理。
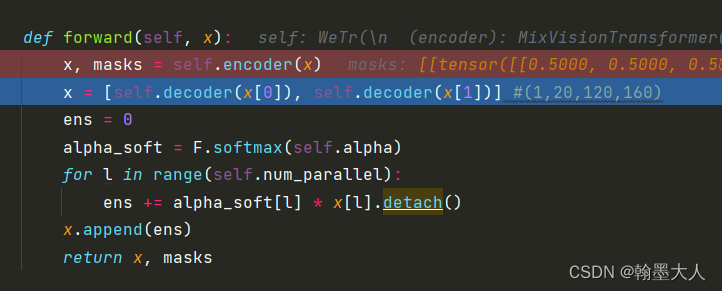
输出的rgb和depth分别输入到decoder中进行处理。将x[l]设置为不进行反向更新。最后输出x,x就有三个输出。