原理
1: 音视频同步判别器
常规SyncNet:
功能:音频和嘴唇同步
实质:判断音频和唇形在某个共同参数空间下的相似性。
网络结构:
一种伪孪生网络结构,分别提取嘴形特征和音频特征,然后通过对比损失计算两者之间的距离。
face_encoder ,audio_encoder,
(如果想要自己训练一个syncnet模型的话, 简单的从网上拉一些看似音视频已经对齐的资源是不够的, 有可能仍存在<100 ms的非同步, 所以需要干净的经过检查的数据. 作者的做法是先拿未筛选的数据训练一版模型, 然后通过卡阈值把训练集中一部分false positive (即假对齐)给抛弃掉, 从而达到非人工筛选的目的)
目前公开的训练SyncNet的数据集LRS2,处理过后:
1)裁剪人脸图片
是否可以只裁剪嘴部区域,训练SyncNet,这样网络理论收敛快一些。
2)比较模糊
是否可以用codeformer把输入图增强一下
1,expert lip-sync discriminator:
在传统SyncNet上做一下修改:
1)使用彩色图代替之前的灰度图
2)使用残差连接,把网络做的更深
3)使用不同loss函数:二进制互熵损失余弦相似性loss
论文中给出的数据:数据集LRS2,训练大约29小时,batchsize:64, 时间窗口Tv:5,优化器:Adam,初始化学习率:1e−3。。。在LRS2test上,准确率91%
在lrs2验证集上的得分情况:
论文中的表现:
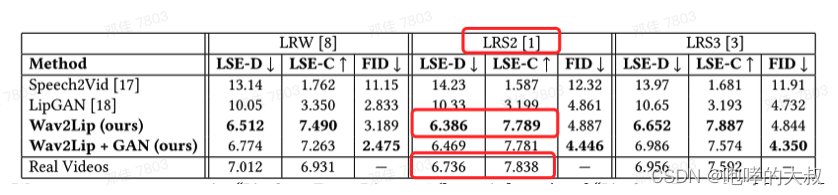
实际测试的表现:
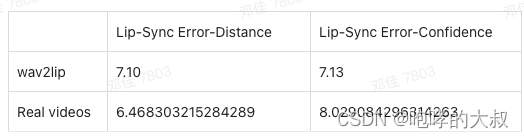
Lip-Sync Error-Distance:平均嘴唇和音频之间的误差距离,越小越好
Lip-Sync Error-Confidence:平均置信度得分,越大越好
2:视觉质量判别器
visual quality discriminator:由卷积块的堆叠组成。每个块由卷积层和Leaky ReLU激活组成。用来提升生成图片的质量(可加可不加)
3:wav2lip
网络分3个模块:1)Identity Encoder:身份编码器是对随机参考帧R进行编码的残差卷积层的堆叠,将其沿着通道轴与姿态先验P(下半部分被掩蔽的目标face)级联。
2)Speech Encoder:语音编码器是2D卷积的堆叠,以编码输入语音段S,然后将其与face representation级联
3)Face Decoder:face解码器也是卷积层的堆叠,沿着转置卷积上采样。
Loss :

损失有3部分:重建损失+同步损失+gan损失
重建损失:L1范
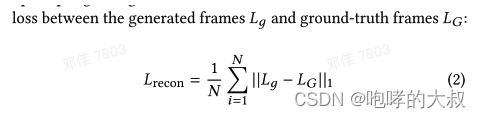
推理
推理过程:
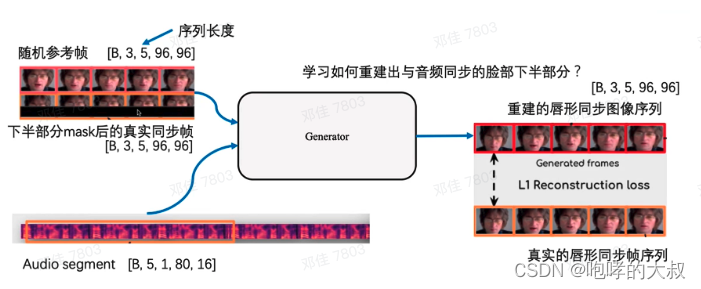
1)对输入语音提取Mel特征,得到语音特征块
2)对全脸+去掉下半张脸(6* 96* 96)两组人脸提取图片特征
3)将上面两种特征输入到wav2lip网络,生成带口型的人脸
4)将带口型的人脸贴回原图,逐帧写成纯图像视频
5)用ffmpeg合成带语音的视频
在使用原工程run Inference,需要注意的地方:
1:如果嘴超出检测出的脸部框,需要调–pads,比如–pads 0 20 0 0
2:如果您看到口腔位置脱臼或一些怪异的伪影,例如两个嘴,可能是因为过度平滑的面部检测。使用-nosmooth参数,然后再尝试。
3:尝试 - resize_factor参数,以获取较低的分辨率视频。因为这些模型是在分辨率较低的面孔上训练的。与1080p视频相比,您可能会获得720p视频的更好。
4:没有GAN的WAV2LIP模型通常需要对以上两个进行更多实验,以获得最理想的结果,有时也可以为您带来更好的结果。
训练
训练之前,需要注意的几个地方:
1:可能无法通过在单个人的几分钟视频训练/微调来获得良好的结果。
2:在训练wav2lip之前,需要用你自己的数据集训练expert discriminator
3:如果是您自己从Web下载的数据集,则在大多数情况下需要sync-corrected同步校正。
4:FPS的更改将需要重大的代码更改。
5:expert discriminator的评估损失应降至约0.25,wav2lip评估同步损失应降至〜0.2,以获得良好的结果。
expert lip-sync discriminator英文训练
数据处理:
syncnet_mel_step_size=16。#mel图谱的长度
syncnet_T = 5。 #窗口步长,5帧
在一段短视频中,抽取随机参考帧,然后,基于这帧随机参考帧,向后步长为5,获取连续5帧视频图片,作为图像输入,基于这帧随机参考帧,向后步长16,获取视频图片对应的mel图谱。
使用官方的filelists(train.txt,val.txt,test.txt)索引文件:
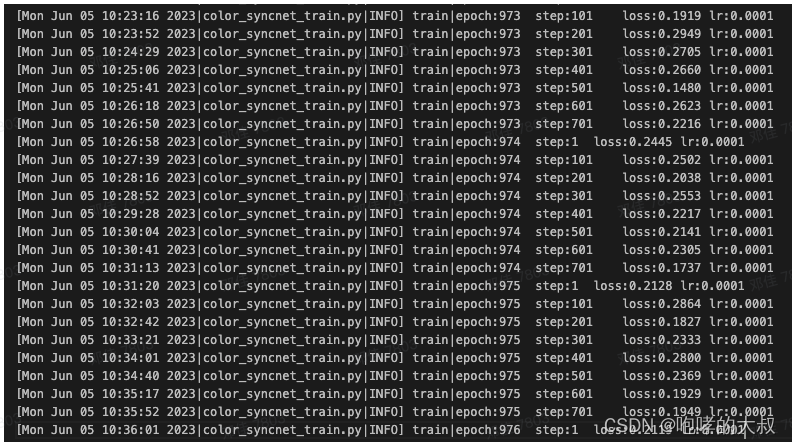
训练集上的平均loss=0.19
Val上情况:
从头重训的syncnet,未加预训练模型:
均值:0.3478966458918365
test上情况:
从头重训的syncnet,未加预训练模型:
平均loss=0.35438132368961206
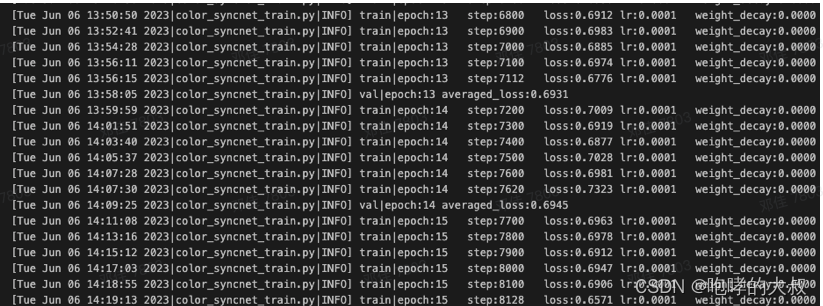
训练中文syncnet:
1)从头使用中文数据集训,不加载预训练模型
训练集loss和验证集loss都在0.69,没有一点要降的趋势。
2)加载英文预训练模型
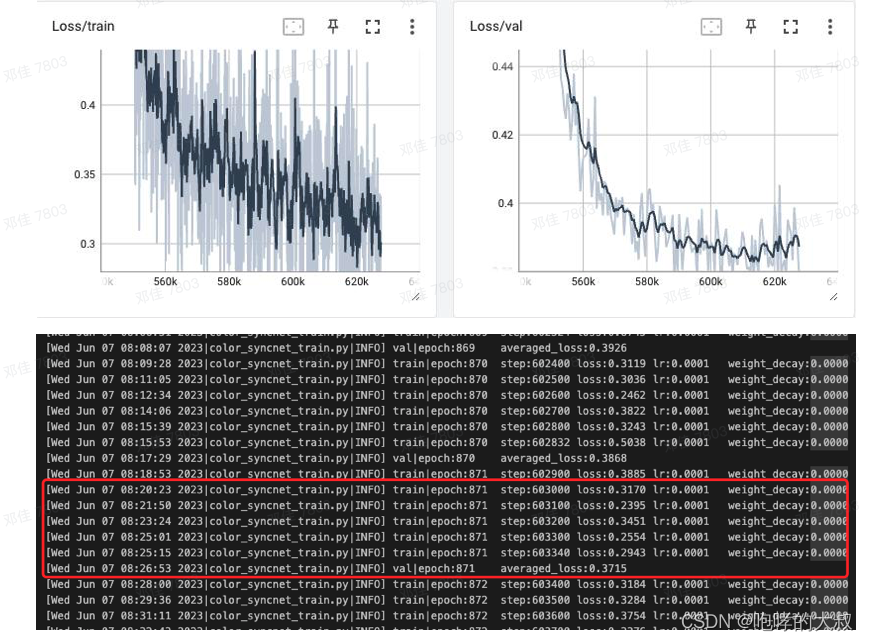
迭代104次epoch后,在验证集上达到最小Loss=0.371,此时在训练集上的loss=0.3左右。继续训,模型开始过拟合。
2:Train the Wav2Lip model(s).
训练流程:
- 前向:使用语音特征块+图片特征送到wav2lip网络,生成带口型的人脸g;
初期:syncnet_wt=0,sync_loss=0。(同步损失=0)
l1loss = recon_loss(g, gt)。#gt是有口型的标签图 ,(重建loss)
总 loss:
loss = hparams.syncnet_wt * sync_loss + (1 - hparams.syncnet_wt) * l1loss
(如果是训练高清Wav2Lip ,还有一个gan loss
loss = hparams.syncnet_wt * sync_loss + hparams.disc_wt * perceptual_loss +
(1. - hparams.syncnet_wt - hparams.disc_wt) * l1loss
这里的gan loss(perceptual_loss),是指使用视觉质量判别器对g进行一次重建,然后用重建的结果与g计算二元交叉熵,比较两者之间的分布差异,
false_pred_loss = F.binary_cross_entropy(self.binary_pred(false_feats).view(len(false_feats), -1),
torch.ones((len(false_feats), 1)).cuda())
用来增强唇形生成的质量。)
2)loss.backward()
optimizer.step()
3)测试:
跑测试集测试本次训练的wav2lip模型效果,就是用syncnet测试。sync_loss = get_sync_loss(mel, g),mel:原音频,g:wav2lip模型生成的人脸图,送到syncnet模型中,输出对应特征向量,然后计算两者之间的cosine_similarity。
4)一直迭代训练,当测试集的cos相似度小于 .75时,syncnet_wt置0.01,启动syncnet loss,指导训练。