文章目录
- 第六章 Python面向对象
- 6.1. 面向对象基础
- 6.1.1. 面向对象与面向过程
- 6.1.2. 类与对象
- 6.1.3. 类的设计与对象的实例化
- 6.1.4. 构造方法
- 6.1.5. 魔术方法
- 6.1.6. 类与类的关系
- 使用到另一个类的对象完成需求
- 使用到另一个类的对象作为属性
- 6.2. 面向对象进阶
- 6.2.1. 封装
- 6.2.1.1. 可见性
- 6.2.1.2. 方法属性化
- 6.2.2. 继承
- 6.2.2.1. 继承的概述
- 6.2.2.2. 父类的提取
- 6.2.2.3. 继承的特点
- 6.2.2.4. 继承的基本语法
- 6.2.2.5. 重写
- 6.2.2.6. 调用父类中的函数
- 6.2.2.7. 继承中的构造函数
- 6.2.2.8. 多继承
- 6.2.3. 属性方法的动态绑定
- 6.2.3.1. 动态绑定
- 6.2.3.2. \__slots__
- 6.2.4. 类属性与类方法
- 6.2.4.1. 类属性
- 6.2.4.2. 类方法
- 6.2.4.3. 静态方法
- 6.3. 异常处理
- 6.3.1. 异常处理的介绍
- 6.3.2. 异常处理的语法
- 6.3.2.1. try-except
- 6.3.2.2. else
- 6.3.2.3. finally
- 6.3.3. 异常抛出
- 6.3.3.1. 抛出系统异常
- 6.3.3.2. 自定义异常
第六章 Python面向对象
6.1. 面向对象基础
6.1.1. 面向对象与面向过程
在我们编写程序的时候,经常性的会听说过“面向对象”这个词语。我们可能听说过Python是“面向对象”的编程语言,C是“面向过程”的编程语言,那么什么是“面向对象”,什么是“面向过程”呢?
- 面向过程
- 是一种看待问题、解决问题的思维方式。
- 着眼点在于问题是如何一步步的解决的,然后亲力亲为的解决问题。
- 面向对象
- 是一种看待问题、解决问题的思维方式。
- 着眼点在于找到一个能够帮助解决问题的实体,然后委托这个实体帮助解决问题。
案例分析1: 小明需要自己组装一台电脑
- 面向过程的思维方式:
- (小明)去市场买零配件
- (小明)将零配件运回家里
- (小明)将电脑组装起来
- 面向对象的思维方式:
- 小明找到一个朋友 – 老王
- (老王)去市场买零配件
- (老王)将零配件送回来
- (老王)将电脑组装起来
案例分析2: 小明需要把大象装进冰箱
- 面向过程的思维方式:
- (小明)打开冰箱门
- (小明)把大象赶进冰箱
- (小明)关上冰箱门
- 面向对象的思维方式:
- (冰箱)开门
- (大象)自己走进冰箱去
- (冰箱)关门
因此,无论是面向对象还是面向过程,其实都是一种编程思想,而并不是某一种语言。在很多的新手手中,用“面向对象的语言”写出的代码,仍然是面向过程思想的代码;在很多的大神手中,用“面向过程的语言”也能够写出面向对象思想的代码。那我们应该怎样理解“Python是面向对象的编程语言”这句话呢?
使用Python这门语言可以更加容易写出具有面向对象编程思想的代码!
6.1.2. 类与对象
在面向对象的编程思想中,着眼点在于找到一个能够帮助解决问题的实体,然后委托这个实体解决问题。这个具有特定功能,能够帮助解决特定问题的实体,称为一个对象。而由若干个具有相同的特征和行为的对象组成的集合,称为一个类。
类是对象的集合,对象是类的个体
在程序中,我们需要先定义类,在类中定义该类的对象共有的特征和行为。
类是一种自定义的数据类型,通常用来描述生活中的一些场景
例如: Dog类用来描述狗类,
定义了特征: 姓名、性别、毛色
定义了行为: 吃饭、睡觉
那么,这个类的每一个对象都具备这些特征和行为。
6.1.3. 类的设计与对象的实例化
我们使用类来描述现实生活中的一些场景,这里我们以狗类为例
# 使用关键字class定义一个类
class Dog:
def __init__(self):
# 使用self.定义属性
self.name = None
self.age = None
self.kind = None
# 定义对象的行为,用方法来定义,又称为“成员方法”
# 成员方法的定义,参数必需添加self,表示对象本身
def bark(self):
# 在方法中,使用self.访问对象自己的属性和方法
print(f"{self.name} 在狗叫")
# 实例化对象
xiaobai = Dog()
# 访问类的属性
xiaobai.name = "xiaobai"
xiaobai.age = 1
print(xiaobai.name)
print(xiaobai.age)
# 访问类的方法
xiaobai.bark()
6.1.4. 构造方法
我们在一个类中可以定义很多的属性,在使用的时候一个个的进行赋值有点麻烦。因此我们就需要能够在创建对象的同时完成属性的初始化赋值操作,此时就可以使用“构造方法”
# 使用关键字class定义一个类
class Dog:
# __init__是初始化对象的时候自动调用的方法,称为“构造方法”
# 在构造方法中,也可以完成属性的定义与初始化赋值操作
def __init__(self, name, age, kind):
# 使用self.定义属性,后面直接使用形参完成初始化赋值
self.name = name
self.age = age
self.kind = kind
# 定义对象的行为,用方法来定义
# 成员方法的定义,参数必需添加self,表示对象本身
def bark(self):
# 在方法中,使用self.访问对象自己的属性和方法
print(f"{self.name} 在狗叫")
# 实例化对象
xiaobai = Dog("xiaobai", 1, "samo")
# 访问类的属性
print(xiaobai.name)
print(xiaobai.age)
# 访问类的方法
xiaobai.bark()
6.1.5. 魔术方法
在类中存在一些在方法名的前后都添加上__的方法,称为“魔术方法”。魔术方法不需要手动调用,而是在适当的时机自动调用。
| 魔术方法 | 调用时机 | 使用场景 |
|---|---|---|
| _new_ | 实例化对象,开辟内存空间的时候调用 | |
| _init_ | 初始化对象,属性初始化的时候调用 | 定义属性、完成属性的初始化赋值操作 |
| _del_ | 删除对象的时候调用 | 释放持有的资源等 |
| _cal_ | 对象函数,将对象当作函数调用的时候触发 | |
| _str_ | 将对象转成字符串的时候调用str() | 需要将对象转为自己希望的字符串表示形式 |
| _repr_ | 返回对象的规范字符串表示形式 | 透过容器看对象 |
| _add_ | 使用 + 对两个对象相加的时候调用 | 完成对象相加的逻辑 |
| _sub_ | 使用 - 对两个对象相减的时候调用 | 完成对象相减的逻辑 |
| _mul_ | 使用 * 对两个对象相乘的时候调用 | 完成对象的乘法逻辑 |
| _truediv_ | 使用 / 对两个对象相除的时候调用 | 完成对象的除法逻辑 |
| _floordiv_ | 使用 // 对两个对象相除的时候调用 | 完成对象的向下整除逻辑 |
| _mod_ | 使用 % 对两个对象求模的时候调用 | 完成对象的求模逻辑 |
| _pow_ | 使用 ** 对两个对象求幂的时候调用 | 完成对象的求幂逻辑 |
| _gt_ | 使用 > 对两个对象比较的时候调用 | 完成对象的大于比较 |
| _lt_ | 使用 < 对两个对象比较的时候调用 | 完成对象的小于比较 |
| _ge_ | 使用 >= 对两个对象比较的时候调用 | 完成对象的大于等于比较 |
| _le_ | 使用 <= 对两个对象比较的时候调用 | 完成对象的小于等于比较 |
| _eq_ | 使用 == 对两个对象比较的时候调用 | 完成对象的相等比较 |
| _ne_ | 使用 != 对两个对象比较的时候调用 | 完成对象的不等比较 |
| _contains_ | 使用 in 判断是否包含成员的时候调用 | 完成in判断包含的逻辑 |
# 定义一个点类
class Point:
# 完成属性的初始化赋值
def __init__(self, x, y):
self.x = x
self.y = y
# 完成两个点的相加,得到一个新的点
def __add__(self, other):
return Point(self.x + other.x, self.y + other.y)
# 完成两个点的相减,得到一个新的点
def __sub__(self, other):
return Point(self.x - other.x, self.y - other.y)
# 判断两个点是否相等,通过属性值是否相等的判断
def __eq__(self, other):
return self.x == other.x and self.y == other.y
# 判断两个点是否不等,通过属性值是否相等的判断
def __ne__(self, other):
return self.x != other.x or self.y != other.y
# 判断一个点的x和y坐标中,是否包含指定的值
def __contains__(self, elem):
return elem == self.x or elem == self.y
# 将一个点转为字符串表示形式
def __str__(self):
return "{%d, %d}"%(self.x, self.y)
# 定义一个矩形类
class Rect:
# 完成属性的初始化赋值
def __init__(self, length, width):
self.length = length
self.width = width
# 计算面积
def getArea(self):
return self.length * self.width
# 完成两个矩形的面积比较
def __gt__(self, other):
return self.getArea() > other.getArea()
def __lt__(self, other):
return self.getArea() < other.getArea()
def __ge__(self, other):
return self.getArea() >= other.getArea()
def __le__(self, other):
return self.getArea() <= other.getArea()
def __eq__(self, other):
return self.getArea() == self.getArea()
def __ne__(self, other):
return self.getArea() != self.getArea()
# 将一个矩形转为字符串表示形式
def __str__(self):
return f"length: {self.length}, width: {self.width}, area: {self.getArea()}"
# 关于__str__和__repr__
# __str__: 在使用str(obj)的时候触发
# __repr__: 官方的描述是返回对象的规范字符串表示形式
# 两者都是将对象转成字符串的。
# 如果是直接用print打印的话,会自动的调用str()方法,因此会触发__str__
# 但是如果需要透过容器看对象的时候,是以__repr__为准的
# 那么我们应该写__str__还是__repr__呢?
# 推荐__repr__,因为如果只定义了__repr__,没有定义__str__。此时__str__是与__repr__相同的!
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return f"str: name = {self.name}, age = {self.age}"
def __repr__(self):
return f"repr: name = {self.name}, age = {self.age}"
xiaobai = Person("xiaobai", 18)
# 直接打印
print(xiaobai) # str: name = xiaobai, age = 18
# 放入容器
arr = [xiaobai]
print(arr) # repr: name = xiaobai, age = 18
6.1.6. 类与类的关系
我们在一个程序中,可能会设计很多的类,而类与类之间的关系可以分为3种:
- 类中使用到另外一个类的对象来完成对应的需求
- 类中使用到另外一个类的对象作为属性
- 继承
使用到另一个类的对象完成需求
"""
案例: 上课了,老师让学生做自我介绍
分析:
1、需要设计两个类: 老师类 和 学生类
2、老师类的功能: 让学生做自我介绍
3、学生类的功能: 自我介绍
"""
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def introduce(self):
print(f"大家好,我叫{self.name},我今年{self.age}岁了!")
class Teacher:
def __init__(self, name):
self.name = name
def make_introduce(self, student):
print(f"{self.name}说: 各位同学安静一下,我们听{student.name}来做自我介绍")
print(f"{student.name}: ", end="")
student.introduce()
# 实例化老师和学生的对象
xiaoming = Student("xiaoming", 19)
laowang = Teacher("laowang")
laowang.make_introduce(xiaoming)
使用到另一个类的对象作为属性
"""
案例: 判断一个圆是否包含一个点
分析:
需要设计的类: 圆类、点类
点类需要设计的属性: x, y坐标
圆类需要设计的属性: 圆心(点类型), 半径
"""
# 定义点类
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
def __repr__(self):
return "{%d, %d}"%(self.x, self.y)
# 定义圆类
class Circle:
def __init__(self, center, radius):
self.center = center
self.radius = radius
# 判断是否包含一个点
def contains_point(self, point):
distance = (self.center.x - point.x) ** 2 + (self.center.y - point.y) ** 2
return distance <= self.radius ** 2
def __contains__(self, item):
return self.containsPoint(item)
# 创建点对象
point = Point(10, 20)
# 创建圆对象
circle = Circle(Point(5, 18), 8)
# 判断圆是否包含点
print(circle.contains_point(point))
print(point in circle)
6.2. 面向对象进阶
6.2.1. 封装
我们在类中可以定义一些属性、方法,对于有些属性来说,我们可能不希望暴露给外界,因为在外界直接访问的时候(主要是直接修改的时候)可能设置的值并不是我们想要的一些值,可能会对我们的逻辑产生影响。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
# 创建Person对象
x = Person('xiaobai', 19)
# 类外直接访问属性,修改
x.age = 2000
在上述代码中可以看到,在类外访问x对象的age属性,并且将值修改为2000。这个操作并没有什么语法错误,可以成功的将age属性设置为2000。从语法的角度出发没有错,可是从我们的逻辑出发却是有问题的,因为我希望一个人类的年龄应该限制在[0, 150]的范围之内的!此时,我就非常不希望外面直接修改age属性的值
如何解决上述的问题呢?
6.2.1.1. 可见性
在类中定义的属性、方法都是有一定的可见性的,也就是在哪里可以看到、可以访问。在Python中,可见性分为三种: 公共的、保护的、私有的。
| 可见性 | 可见性描述 | 可见性修饰 |
|---|---|---|
| 公共的 | 在任何的位置都可以访问,默认 | 默认创建的属性、方法都是公共的可见性,不需要什么操作 |
| 保护的 | 只能够在当前的模块中访问 | 使用一个下划线开头,例如: _age |
| 私有的 | 只能够在当前的类中访问 | 使用两个下划线开头,例如: __age |
class Person:
# 为了不让外界直接访问到age属性,这里将名字设置为了 __age
def __init__(self, name, age):
self.name = name
self.__age = age
x = Person('xiaobai', 18)
# print(x.__age) 这里会报错,因为找不到这个属性
这样一来,我们就可以将属性私有化起来,不让外界直接访问了!
拓展知识点:
Python中所谓的“私有化”,其实是“防君子,不防小人”。Python的研发人员遵循的原则是“大家都是成年人,知道事情的轻重,知道有些事情可以做,有些事情不能做”。**Python中并没有真正的私有化,之所以访问不到了,是因为在存储的时候修改了名字!**这些被私有化的成员的名字被定义为 _类名__特征名
# 在上述的代码中,直接访问__age是访问不到的 # 因为Python在存储这个属性的时候,并不是按照__age来存储的,而是按照 _Person__age 来存储的 # 使用下面的访问,访问属性,看看是不是成功的访问到了! print(x._Person__age)
6.2.1.2. 方法属性化
我们已经成功的将某些属性隐藏起来了,外界不能直接访问到了。可是别忘了我们的初衷。我们为什么要隐藏起来这个属性的?其实就是因为外界直接去修改的时候,可能会设置一些“逻辑错误”的值,给我们带来麻烦。但是私有化起来之后,外界就彻底无法访问了,这样也是不妥的。因此我们就需要提供这些私有属性的对应的访问的方法,并且在这些方法中,添加我们自己的过滤的条件。
class Person:
def __init__(self, name, age):
self.name = name
self.set_age(age)
# 提供set方法,可以让外界通过调用这个方法,来修改属性__age的值
# 在这个方法中,可以添加上自己的业务逻辑,实现对外界修改值的过滤
def set_age(self, age):
if 0 <= age <= 150:
self.__age = age
# 提供get方法,可以让外界通过调用这个方法,来获取属性__age的值
def get_age(self):
return self.__age
# 创建对象
x = Person('xiaobai', 18)
# 通过方法访问属性
x.set_age(2000)
print(x.get_age())
通过上述的方式,的确可以实现属性的私有化,并且也可以在类外通过特定的方式访问到属性。但是使用起来其实是不方便的。出于方便性的考虑,我们可以将set/get方法属性化,使得在类外使用的时候,有着跟访问属性一样的便利性,同时还能在类内保持自己的业务逻辑处理。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
# get方法属性化,添加@property
@property
def age(self):
return self.__age
# set方法属性化,添加@属性.setter
# 这里需要提前给属性添加@property属性,单独写这个是会出错的
@age.setter
def age(self, age):
if 0 <= age <= 150:
self.__age = age
#
p = Person('xiaobai', 19)
# 访问“属性”
p.age = 19
print(p.age)
6.2.2. 继承
6.2.2.1. 继承的概述
在现实生活中,我们与父母之间存在着“继承”的关系。在Python中,也存在着“继承”的思想,来提高代码的复用性、代码的拓展性。
程序中的继承,是类与类之间的特征和行为的一种赠予和获取的关系。一个类可以将自己的属性和行为赠予其他的类,一个类也可以从其他的类中获取到他们的属性和方法。但是两个类之间必需满足 is a 的关系。
在两个类之间,A类将自己的属性和行为赠予B类,B类从A类获取属性和行为。此时,A类被称为是父类,B类被称为是子类。他们之间的关系就是继承。

6.2.2.2. 父类的提取
在设计类的时候,可以根据程序中需要使用到的多个具体的类,进行共性的提取,定义为父类。将多个具体的类中,相同的属性和行为提取出来到一个类中。
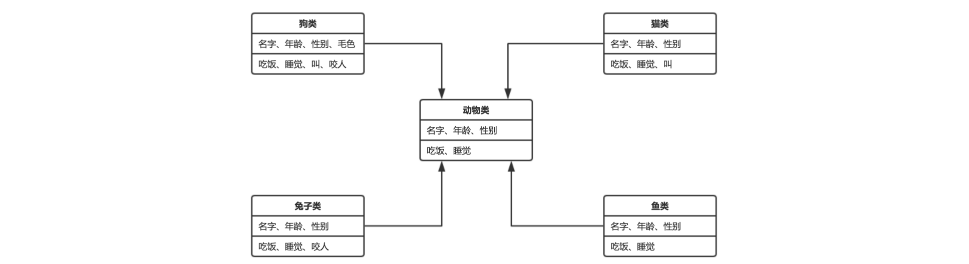
6.2.2.3. 继承的特点
- 产生继承关系后,子类可以使用父类中的属性和方法,也可以定义子类独有的属性和方法。
- 使用继承,可以简化代码,提高代码的复用性,提高代码的拓展性,增强代码的健壮性。最重要的是使类与类之间产生了继承的关系,是多态的前提。
- 在Python中,所有的类都直接或者间接的继承自 object 类。
6.2.2.4. 继承的基本语法
# 定义动物类,其中定义动物共有的属性和行为
# 属性使用成员变量来表示
# 行为使用函数来表示
class Animal:
def __init__(self, name, age, gender):
"""
Animal类的构造函数,实现实例化对象的同时,完成属性的初始化赋值操作
:param name:
:param age:
:param gender:
"""
self.name = name
self.age = age
self.gender = gender
def bark(self):
print("animal bark")
def __repr__(self):
return "Animal: {name = %s, age = %d, gender = %s}" % (self.name, self.age, self.gender)
# 定义动物的子类,Dog
# 在类的后面添加小括号,小括号中写父类
# 此时,Dog类继承自Animal类。Animal是父类、Dog是子类
class Dog(Animal):
def walk(self):
print(f"{self.name} 会走路了")
# 实例化Dog对象的时候,由于继承到的父类的构造函数中包含有三个参数,因此,Dog对象也必需使用三个参数的构造函数
d = Dog("xiaobai", 1, "male")
# 子类中虽然没有定义bark函数,但是仍然可以调用,因为可以从父类继承到
d.bark()
# 子类中虽然没有定义name、age、gender属性,但是仍然可以调用,因为可以从父类继承到
print(d.name)
print(d.age)
print(d.gender)
# 子类虽然没有写__repr__或者__str__,仍然可以调用,因为可以从父类继承到
print(d)
# 子类在继承到父类成员的同时,还可以自己添加功能
d.walk()
6.2.2.5. 重写
我们可以通过继承的方式,让子类继承到父类中定义的成员。在父类中定义的所有的成员变量和函数,都可以原封不动的继承给子类,让子类直接使用。可是在实际需求中,有时候会遇到子类需要自己独特的实现的情况。
例如:我们定义了一个Animal类,其中定义了函数bark,来描述了所有的动物都会叫。可是Animal的不同的子类,在具体实现“叫”这个功能的时候,实现的方式是不一样的。狗是“汪汪汪”的叫,猫是“喵喵喵”的叫。
子类可以继承到父类中的成员变量和函数,但是有些函数,子类的实现与父类的方式可能不同。当父类提供的实现方式已经不能满足子类的需求的时候,子类就可以定义与父类中同名字的函数!此时在子类中,使用这样的函数完成了对父类功能的覆盖,对于这种现象,我们称为“覆盖”,又叫做重写!
# 定义动物类
class Animal:
# 父类中定义"叫"的功能
def bark(self):
print("animal bark")
class Dog(Animal):
# 对从父类继承到的函数进行重新实现
def bark(self):
print("汪汪汪!")
class Cat(Animal):
# 对从父类继承到的函数进行重新实现
def bark(self):
print("喵喵喵!")
# 子类对象在调用bark函数的时候,实现的是自己的功能
d = Dog()
d.bark() # 汪汪汪!
c = Cat()
c.bark() # 喵喵喵!
6.2.2.6. 调用父类中的函数
我们可以通过重写,在子类中完全覆盖掉父类中的实现,从而达到子类自己的个性化需求。但是有些时候,子类在进行重写父类函数的时候,需要在父类的功能基础上进行增的操作,需要添加新的功能。那么此时总不能把父类中的函数的功能再写一遍吧!这个时候就需要手动调用父类中的功能!
# 定义员工类
class Employee:
def work(self):
print("员工需要努力搬砖哦!")
# 定义经理类
class Manager(Employee):
def work(self):
print("开个早会")
# 调用父类函数方式一:父类.需要调用的函数(self, 其他参数)
# Employee.work(self)
# 调用父类函数方式二:super(当前类, self).需要调用的函数(其他参数)
# super(Manager, self).work()
# 调用父类函数方式三:super().需要调用的函数(其他参数)
super().work()
print("开个晚会")
# 使用子类对象,调用功能
m = Manager()
m.work()
6.2.2.7. 继承中的构造函数
在Python中,如果子类中没有写构造函数的话,子类是可以从父类中继承到实现的!
class Employee:
def __init__(self, empno, name, sal):
self.empno = empno
self.name = name
self.sal = sal
print("Employee.__init__")
class Manager(Employee):
pass
# 子类中没有定义构造函数,对象在实例化的时候,需要使用从父类中继承到的构造函数
m = Manager(101, 'zhangsanfeng', 9900) # Employee.__init__
当然,在子类中也是可以写自己的构造函数的,此时就完成了一个构造函数的重写
class Employee:
def __init__(self, empno, name, sal):
self.empno = empno
self.name = name
self.sal = sal
print("Employee.__init__")
class Manager(Employee):
def __init__(self, award):
self.award = award
print("Manager.__init__")
# 子类中定义了自己的构造函数,此时就可以使用子类中自己的构造函数来实现对象的实例化
m = Manager(9000) # Manager.__init__
print(m.award) # 9000
print(m.name) # AttributeError: 'Manager' object has no attribute 'name'
如上所示,因为没有执行父类中的构造函数,因此并没有完成对empno、name、sal的创建,因此现在的子类Manager在访问这些属性的时候是会出问题的!此时可以在子类的构造函数中,通过调用父类的构造函数来实现!
class Employee:
def __init__(self, empno, name, sal):
self.empno = empno
self.name = name
self.sal = sal
print("Employee.__init__")
class Manager(Employee):
def __init__(self, empno, name, sal, award):
# 添加对父类的构造函数的调用
super().__init__(empno, name, sal)
self.award = award
print("Manager.__init__")
# 子类中定义了自己的构造函数,此时就可以使用子类中自己的构造函数来实现对象的实例化
m = Manager(111, 'zhangsan', 9000, 2000) # Manager.__init__
print(m.award) # 9000
print(m.name) # zhangsan
6.2.2.8. 多继承
与大多数的面向对象的编程语言不同,Python是多继承的。也就是说,在Python中,一个类可以有多个父类!
市面上绝大多数的面向对象的编程语言都是单继承的,只有少部分的几种语言是多继承的,例如Python、C++。在多继承中,可能会存在“二义性”的问题,其他的单继承的编程语言也都会使用一些其他的方式来解决这样的问题,并间接的实现多继承。例如Java采用的是接口、Scala采用的是特质等。
# 定义父类1
class Father:
def test_function(self):
print("father function impl")
def test1(self):
print("test1")
# 定义父类2
class Mother:
def test_function(self):
print("mother function impl")
def test2(self):
print("test2")
# 定义子类,同时继承自两个父类
class Son(Father, Mother):
def test_function(self):
# 调用父类中的实现,区分父类调用的时候,只能使用父类名字来区分
# Father.test_function(self)
Mother.test_function(self)
# 1. 由于Son有两个父类,因此可以继承到两个父类中的所有的成员
s = Son()
s.test1() # test1
s.test2() # test2
# 2. 但是子类的多个父类中,包含了相同的函数 test_function,并且实现的方式不同。那么子类该何去何从?该继承哪个父类中的函数呢?这样的问题就是"二义性"
# Python作为一门多继承的编程语言,自然是考虑到这个问题了。在Python中,如果出现这种情况,继承到的是小括号中写的第一个类!
s.test_function()
6.2.3. 属性方法的动态绑定
6.2.3.1. 动态绑定
Python是一个动态的语言,一个类在定义完成之后,在运行的过程中,可以随时动态的给某一个对象绑定新的属性和方法:
class Person:
def __init__(self, name, age):
"""
在Person类的构造方法中,只是定义了属性name和age
:param name:
:param age:
"""
self.name = name
self.age = age
# 实例化Person的对象
xiaoming = Person("xiaobai", 12)
# 为xiaoming绑定一个新的属性
xiaoming.gender = "male"
xiaoming.score = 99
# 可以发现,xiaoming这个对象已经绑定上了新的属性
print(xiaoming.gender) # male
print(xiaoming.score) # 99
# 但是,实例化一个新的对象的时候,新的对象是没有这些属性的
xiaobai = Person("xiaobai", 20)
# print(xiaobai.gender) # AttributeError: 'Person' object has no attribute 'gender'
# print(xiaobai.score) # AttributeError: 'Person' object has no attribute 'score'
总结来说就是,在构造方法中,定义了属性name和age,是可以被所有的对象所访问的。但是为某一个对象绑定上新的属性的时候,就只有这个对象可以访问,其他的对象都是无法访问的。方法也是这样的
import types
class Person:
def walk(self):
print("person walk")
# 在类外定义一个方法
def sleep(self):
print(f"{id(self)} 睡觉!")
# 实例化Person对象
p = Person()
# 动态绑定新的方法
p.sleep = types.MethodType(sleep, p)
# 调用绑定的新的方法
p.sleep()
# 实例化新的对象
p2 = Person()
# 使用新的对象调用的时候,访问不到这个方法
# p2.sleep() # AttributeError: 'Person' object has no attribute 'sleep'
6.2.3.2. _slots_
Python是一个动态的语言,对象可以动态的绑定属性,那么这是怎么做到的呢?其实Python会为每一个对象分配一个__dict__属性,这是一个字典,存储的就是每一个对象的属性和值的键值对。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def walk(self):
pass
# 实例化对象
p1 = Person("tom", 11)
print(p1.__dict__) # {'name': 'tom', 'age': 11}
# 动态添加属性
p1.gender = "male"
print(p1.__dict__) # {'name': 'tom', 'age': 11, 'gender': 'male'}
这样做可以保证Python的一个动态的特性,可以随时为每一个对象绑定新的属性,使其更加灵活。但是对于属性在最开始设计类的时候就已经确定的、后续不会再新增的类来说,将会是一个比较大的内存开销。特别是当需要创建大量的这样的类的对象的时候。从内存上来说,每一个对象都会分配一个__dict__字典,而字典底层采用的数据结构是哈希表,是一种以空间换时间的数据结构。因此带来的内存的开销比较大。为了解决这样的问题,我们可以在类中定义__slots__来解决这样的问题!
__slots__是一个不可变的容器,通常我们将需要为这个类设计的属性,以元组的形式表示。在进行空间分配的时候,Python解释器直接会开辟合适的、固定的内存空间来存储每一个属性的值,从而达到节省空间的目的。
注意事项:
- 如果给一个类设置了_slots_,那么将不会再为每一个属性提供__dict__
- 设置了__slots__之后,将无法再给这个对象动态绑定其他的属性
# memory_profiler模块可以进行内存占用的分析,需要手动安装这个模块
# pip install memory_profiler
from memory_profiler import profile
import sys
class Person:
__slots__ = ('name', 'age')
def __init__(self, name, age):
self.name = name
self.age = age
@profile
def test():
l = [Person("p", x) for x in range(1000000)]
if __name__ == '__main__':
test()
6.2.4. 类属性与类方法
6.2.4.1. 类属性
顾名思义,就是属于“类”的属性。我们之前在类中定义的属性都是属于“对象“的,随着对象的创建而创建,随着对象的销毁而销毁。并且不同的对象是互不干扰的。但是类属性不然,类属性是属于类的,随着类的定义加载到静态池中,被所有的对象所共享!
类属性与对象属性的区别:
- 开辟时机不同:
- 对象属性是随着对象的实例化而开辟在堆中的,随着对象的销毁而销毁的。
- 类属性是随着类的定义被开辟在静态池中的。
- 所属主体不同:
- 对象属性是属于对象的,不同的对象的属性彼此独立,互不影响。
- 类属性是被所有的对象共享的。
# @Author : 大数据章鱼哥
# @Company : 北京千锋互联科技有限公司
class Person:
# 直接在类内写的属性,就是类属性
# 这个属性,被所有的对象共享
# 不可变的数据类型
count = 0
# 可变的数据类型
friends = []
# 创建类的对象
p1 = Person()
print(id(p1.count))
p2 = Person()
print(id(p2.count))
# 尝试使用对象来修改类属性(不可变的类型)
# p1.count = 10
# print(id(p1.count)) # 其实是对p1开辟了一个新的空间,修改了p1.count的地址指向
# print(id(p2.count))
p1.friends.append('zhangsan') # 其实这里并没有对属性进行修改,存储的依然是指向一个数据容器内存空间的地址
print(id(p1.friends), p1.friends)
print(id(p2.friends), p2.friends)
# 正确的类属性访问方式:使用类来访问
Person.count = 20
print(p1.count, p2.count)
6.2.4.2. 类方法
类方法就是“属于类”的方法,在定义的时候需要使用**@classmethod**来修饰,同时必须要有一个特殊的参数cls。调用方法的时候,可以使用类来调用,也可以使用对象来调用。但是更加推荐使用类来调用。
需要注意:在类方法中,由于没有对象传入,因此无法直接访问到当前类的对象属性,只能够访问到类属性。
class Person:
# 定义类属性
__count = 0
def __init__(self, name, age):
self.name = name
self.age = age
@classmethod
def count_of_person(cls):
"""
类方法使用 @classmethod 修饰
在调用的时候,cls表示调用的类,注意不是对象!
:return:
"""
print(Person.__count) # 可以访问到类属性
# print(Person.name) # 因为没有对象传入,因此无法直接访问到对象的属性
# 使用类来调用,Python解释器会自动的将Person类传递给参数cls
Person.count_of_person()
# 使用对象来调用,Python解释器会自动的将对象所对应的类传递给参数cls【不推荐】
x = Person("xiaoming", 12)
x.count_of_person()
6.2.4.3. 静态方法
静态方法也是属于类的方法,与类方法类似,但是在定义和使用的时候与类方法还是有点区别的:
- 使用 @staticmethod 装饰器来修饰
- 不需要特殊的参数,例如cls、self等
class Person:
# 定义类属性
__count = 0
def __init__(self, name, age):
self.name = name
self.age = age
@staticmethod
def count_of_person():
"""
静态方法使用 @staticmethod 修饰
:return:
"""
print(Person.__count) # 可以访问到类属性
# print(Person.name) # 因为没有对象传入,因此无法直接访问到对象的属性
# 使用类来调用
Person.count_of_person()
# 使用对象来调用
x = Person("xiaoming", 12)
x.count_of_person()
静态方法常见于工具类的封装
class Tool:
@staticmethod
def get_sum(*args, **kwargs):
# 将所有的数字合并到一个元组中
data = args + tuple(kwargs.values())
# 定义变量,用来记录累加的结果
res = 0
# 累加
for ele in data:
res += ele
return res
@staticmethod
def is_prime_number(number):
if number < 2:
return False
for i in range(2, (number // 2) + 1):
if number % i == 0:
return False
return True
# 工具类的使用
print(Tool.get_sum(99, 100, 98, chinese=99, math=89, english=100, mysql=90, python=90))
print(Tool.is_prime_number(99))
6.3. 异常处理
6.3.1. 异常处理的介绍
所谓“异常”,其实就是程序在运行过程中,由于某些逻辑问题而出现的不正常的情况。异常的出现会终止程序的运行。
例如:在使用int()将其他的数据类型转成整型的时候,如果我们要转的是一个非数字的字符串,可能就会出现这个问题。
int(“abc”)
常见的异常:
- ValueError
- TypeError
- NameError
- IndexError
- KeyError
- ZeroDivisionError
- 等
而“异常处理”就是我们将可能出现异常的代码,使用try代码块包含,使用except列出可能出现的异常进行捕获,为这种异常情况设置一个预备方案,以保证程序可以正常运行,不会中断。
6.3.2. 异常处理的语法
异常处理的流程:
- 解释器逐行执行代码
- 如果发现错误,解析错误类型,生成一个对应的异常对象,将异常抛出
- 检查周围有没有处理这种类型的代码块
- 如果周围有处理这种类型异常的代码块,执行对应的程序逻辑
- 如果周围没有处理这种类型异常的代码块,中断程序
6.3.2.1. try-except
try:
# 让用户在控制台输入数字,输入的可能不正确
number = int(input("please input a number: "))
except ValueError as v:
print("输入的不是数字!")
6.3.2.2. else
else用在try结构的后面,在try的代码段中没有异常出现的时候会执行
try:
# 让用户在控制台输入数字,输入的可能不正确
number = int(input("please input a number: "))
except ValueError as v:
print("输入的不是数字!")
else:
print("用户的输入没有问题")
6.3.2.3. finally
finally用在try结构的后面,无论try的代码段中有没有出现异常,finally代码段中的代码始终都会执行
try:
# 让用户在控制台输入数字,输入的可能不正确
number = int(input("please input a number: "))
except ValueError as v:
print("输入的不是数字!")
finally:
print("finally")
6.3.3. 异常抛出
6.3.3.1. 抛出系统异常
我们在设计某些函数的时候,有时候需要对外界传入的数据进行逻辑上的判断,对于判断结果不成立的数据,我们可以适当的抛出异常,让调用方必须要处理这样的问题,才能够继续使用这些功能。起到一个约束的作用。
抛出异常,其实就是实例化一个异常类的对象,然后使用raise关键字抛出,使其生效。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
@property
def age(self):
return self.__age
@age.setter
def age(self, age):
if 1 <= age <= 150:
self.__age = age
else:
raise ValueError("年龄异常")
p = Person(19, 200)
6.3.3.2. 自定义异常
系统给我们提供了很多的异常类,但是这些异常类并不能够满足我们所有的需求。对于有些功能,在实现的时候我们希望能够对数据进行逻辑处理,处理结果不正确的,及时抛出异常,让调用方去处理。调用方在处理的时候,需要使用指定的异常类型来捕获。可是如果都是用到系统的异常类型的话,那么语义表达上面会有问题。因此
自定义异常类,只需要设计一个类去继承Exception类即可。
# 自定义异常类
class AgeError(Exception):
pass
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
@property
def age(self):
return self.__age
@age.setter
def age(self, age):
if 1 <= age <= 150:
self.__age = age
else:
# 抛出自定义的异常
raise AgeError("年龄异常")
try:
p = Person(19, 200)
except AgeError as a:
print("年龄有问题,需要重新实例化对象")




![[Leetcode] 0026. 删除有序数组中的重复项](https://img-blog.csdnimg.cn/img_convert/67b14865db339149200dfad6fc2e0f76.png)