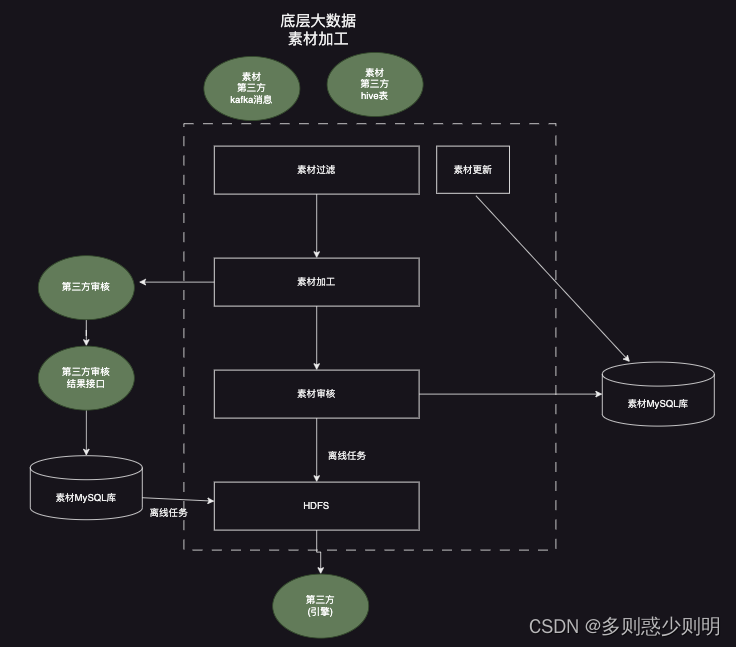
概述
一般地,在进行数据库设计时,应遵循三大原则,也就是我们通常说的三大范式,即第一范式要求确保表中每列的原子性,也就是不可拆分;第二范式要求确保表中每列与主键相关,而不能只与主键的某部分相关(主要针对联合主键),主键列与非主键列遵循完全函数依赖关系,也就是完全依赖;第三范式确保主键列之间没有传递函数依赖关系,也就是消除传递依赖。
第一范式
定义: 属于第一范式关系的所有属性都不可再分,即数据项不可分。
理解: 第一范式强调数据表的原子性,是其他范式的基础。例如下表
第一种表设计

第二种表设计

分析
第一种表设计不满足第一范式,为什么不满足第一范式?因为region列不具有原子性,能拆分成省份、市和具体地址;
第二范式
定义: 要求数据库表中的每个实例或行必须可以被唯一的区分。
通常在实现来说,需要为表加上一个列,以存储各个实例的唯一标识
例子引入:
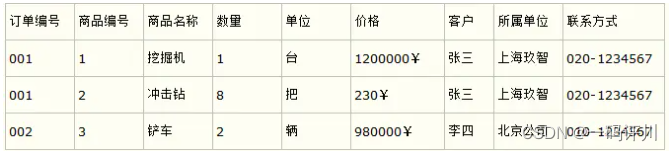
需求描述:设计一个订单信息表,订单有多种商品,将订单编号和商品编号作为联合主键。
第一种表设计
第二种表设计
分析
第一种表设计不满足第二范式 ,订单编号和商品编号作为联合主键,由于商品名称,单位,价格这几列只与商品编号有关,与订单编号无关,因此与主键(联合主键)无关,违反范式第二原则;
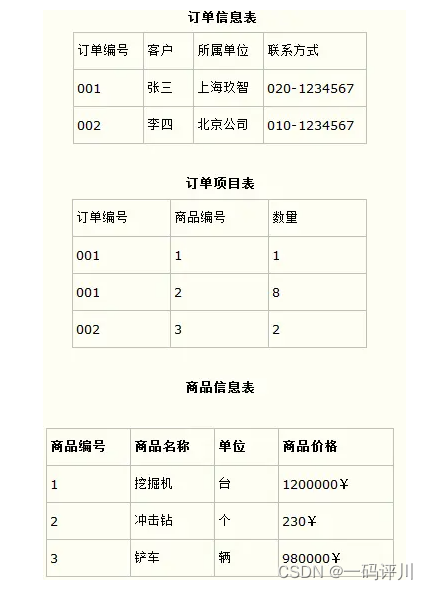
第二种表设计满足第二范式,把第一种设计表进行拆分,把商品信息分离到另一个表中,把订单项目表也分离到另一个表中。
第三范式
定义:第三范式指每一个非主属性既不部分依赖于也不传递依赖于业务主键,也就是在第
二范式的基础上消除了非主键对主键的传递依赖
例子引入:
需求描述:
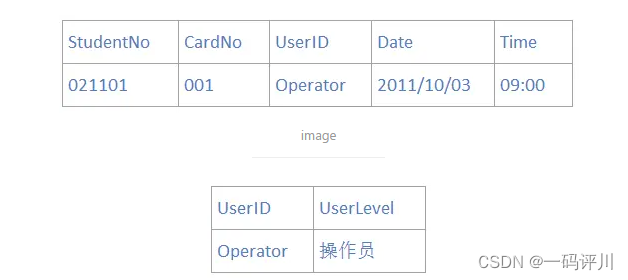
1 需要在数据库中存储如下信息:
2 学生编号;学生卡号;用户ID号;操作员级别;操作日期;操作时间;
第一种表设计

第二种表设计
分析
第一种表设计不满足第三范式,在表中,一个UserID能确定一个UserLevel。这样,UserID依赖于StudentNo和CardNo,而UserLevel又依赖于UserID,这就导致了传递依赖,3NF就是消除这种依赖。
第二种表设计满足第三范式,将第一种表格拆分成成两个表格。
范式优点与缺点
范式优点
- 范式化的更新操作通常比非范式更快。
- 数据较好的范式化 只是用较少或者没有重复数据,所以执行操作会更快。
- 范式化的表会更小,可以更好的放在内存里,所以执行操作会更快。
- 很少有多余的数据意味着检索列表数据时更少需要distinct或者group by语句。
范式化缺点
- 范式化意味着更多的join 这会导致代价昂贵并且导致一些索引无效。
反范式的优点与缺点
优点
- 反范式的schema因为在同一张表中 可以很好的避免关联
混用范式与反范式
范式与反范式一般混合使用。反范式化数据的方法是复制或者缓存,在不同表存储同样的特定列。