一:自定义序列类
1、序列类型的分类
容器序列: list 、 tuple、deque
扁平序列: str 、bytes、bytearray、arry.array
可变序列: list 、deque、bytearray、array
不可变: str、tuple、bytes
容器序列表示可以放置任意类型的数据。
扁平序列要求存储的数据类型一致
2、list中extend和append方法的区别
extend()的参数是一个可迭代序列,会进行for循环
a = [1,2]
a.extend([3,4])
print(a)
输出结果:
[1, 2, 3, 4]
append()的参数是一个可迭代序列,会把整个序列当做一个整体添加进去。
输出结果:
[1, 2, [3, 4]]
3、切片
切片操作都会返回一个新的列表
模式[start: end: step]
其中,第一个数字start表示切片开始位置,默认为0 ;
第二个数字end表示切片截止(但不包含)位置(默认为列表长度);
第三个数字step表示切片的步长(默认为1)。
当start为0时可以省略,当end为列表长度时可以省略,
当step为1时可以省略,并且省略步长时可以同时省略最后一个冒号。
另外,当step为负整数时,表示反向切片,这时start应该比end的值要大才行
aList = [3,4,5,6,7,9,11,13,15,17]
aList[::] #返回包含原列表中所有元素的新列表
aList[::-1] #返回包含原列表中所有元素的逆序列表
print(aList[ ::2]) #隔一个取一个,获取偶数位置的元素
print(aList[1::2]) #隔一个取一个,获取奇数位置的元素
print(aList[3:6]) #指定切片的开始和结束位置
aList[0:100] #切片结束位置大于列表长度时,从列表尾部截断
aList[100:] #切片开始位置大于列表长度时,返回空列表
alist[len(aList):] = [9] #在列表尾部增加元素
aList[:0] = [1,2] #在列表头部插入元素
alist[3:3] = [4] #在列表中间位置插入元素
aList[:3] = [1,2] #替换列表元素,等号两边的列表长度相等
aList[3:] = [4,5,6] #等号两边的列表长度也可以不相等
下面来定义一个类,并且实现切片操作,并且是一个不可修改的序列
#--coding:utf-8--
import numbers
class Group:
"""
实现支持切片操作,并且是一个不可修改的序列
"""
def __init__(self,group_name,company_name,staffs):
"""
:param group_name: 小组名称
:param company_name: 小组所在的公司名称
:param staffs: 组员列表,希望是一个数组
"""
self.group_name = group_name
self.company_name = company_name
self.staffs = staffs
def __getitem__(self, item):
"""
是实现切片的关键,希望切片之后还是一个Group
:param item:
:return:
"""
cls = type(self)
if isinstance(item,slice):
return cls(group_name=self.group_name,company_name=self.company_name,staffs=self.staffs[item])
elif isinstance(item,numbers.Integral):
return cls(group_name=self.group_name,company_name=self.company_name,staffs=[self.staffs[item]])
def __len__(self):
return len(self.staffs)
def __iter__(self):
return iter(self.staffs)
def __contains__(self, item):
if item in self.staffs:
return True
else:
return False
if __name__ == '__main__':
staff = ["网三","景天","雪剑"]
cgroup = Group(group_name="研发1组",company_name="中南科技",staffs=staff)
# sub = cgroup[:2]
# sub2 = cgroup[0]
# print(cgroup[:2])
# print(cgroup[0])
print(len(cgroup))
if "景天" in cgroup:
print("yes")
for user in cgroup:
print(user)
4、bisect维护已排序序列
bisect 用来处理已排序的序列,用来维持已排序的序列,升序
使用的二分查找,效率高,案例如下:
import bisect
inter_list = []
bisect.insort(inter_list,3)
bisect.insort(inter_list,1)
bisect.insort(inter_list,5)
bisect.insort(inter_list,4)
print(inter_list)
输出:
[1, 3, 4, 5]
5、array
array 是一个数组,array和list的一个重要区别,array只能存放指定的数据类型,他的效率比list高
import array
my_array = array.array("i")
my_array.append(2)
my_array.append(3)
print(my_array)
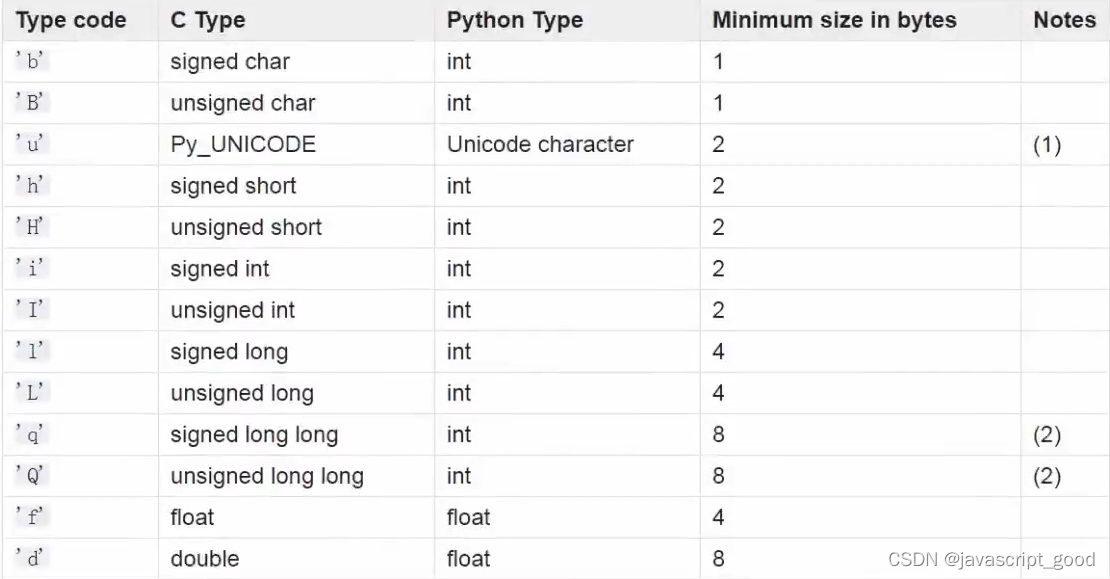
array需要一个参数来指定数据库类型,下表是支持的数据类型。
6、列表推导式、生成器表达式、字典推导式
- 列表推导式
列表推导式也就是列表生成式,他可以简化代码
列表生成式(列表推导式)
#1、提取出1-20之间的奇数,普通写法
odd_list = []
for i in range(21):
if i%2 ==1:
odd_list.append(i)
#2、使用列表生成式,会简单很多
odd_list = [i for i in range(21) if i%2==1 ]
#3、如果要实现逻辑复杂的情况,可以定义一个方法
def hadle_item(item):
return item*item
odd_list = [hadle_item(i) for i in range(21) if i%2==1]
print(odd_list)
- 生成器表达式
生成器表达式,将方括号改成圆括号,生成的是一个generator的生成器
odd_gen = (i for i in range(21) if i%2==1 )
print(odd_gen)
#生成器可以通过for循环查看
for i in odd_gen:
print(i)
#可以通过list转换成list类型
odd_list = list(odd_gen)
print(type(odd_list))
输出结果:
<generator object <genexpr> at 0x0000026B29C907C8>
1
3
5
7
9
11
13
15
17
19
<class 'list'>
- 字典推导式
#字典推导式
my_dict = {"hanory":20,"tomy":17,"marry":28}
#要把my_dict的key和value的值交换
reversed_dict = {value:key for key,value in my_dict.items()}
print(reversed_dict)
输出结果:
<class 'list'>
{20: 'hanory', 17: 'tomy', 28: 'marry'}
- 集合推导式
my_dict = {"hanory":20,"tomy":17,"marry":28}
my_set = {key for key,value in my_dict.items()}
print(type(my_set))
print(my_set)
输出结果:
<class 'set'>
{'tomy', 'marry', 'hanory'}