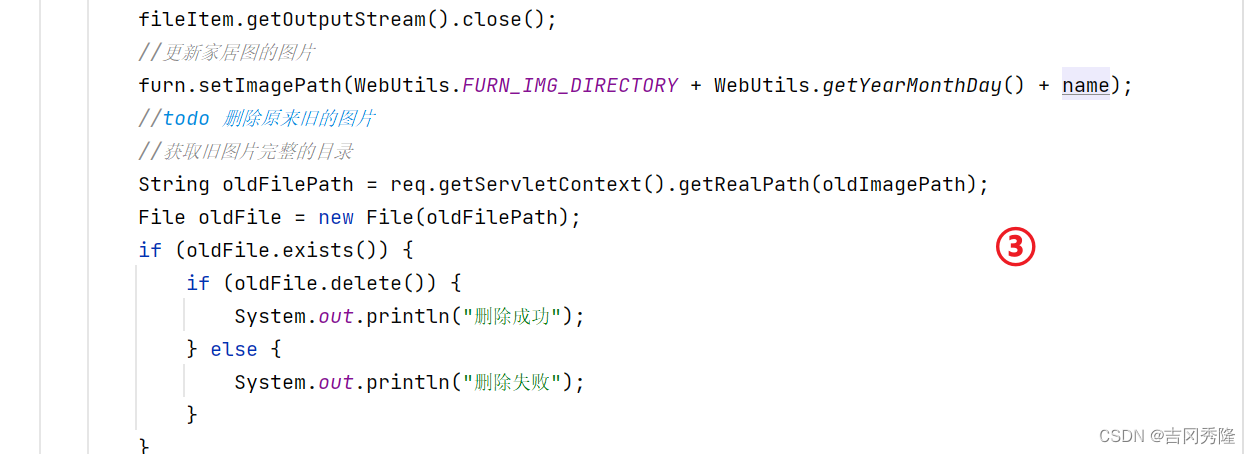
PaddleOCR 在其工具包中提供了多种模型,并且非常易于应用。根据准确性和速度比较模型始终是一个好习惯。在本节中,我们将比较 PaddleOCR 提供的四种模型,即 SRN、PP-OCRv2、PP-OCRv3 和 NRTR。比较将在 COCO-text 数据集上进行,该数据集是基于MSCOCO 的场景文本数据集,使用 Google Colab 上的 Tesla K80 GPU。这些模型将使用称为 Levenshtein 距离的字符串相似性度量来测试。Levenshtein 距离是一种距离度量,通过比较一个字符串中实现另一个字符串所需的更改来计算。在开始比较之前,让我们先大致了解一下数据集。
一、OCR模型对比
1.1 数据准备
COCO-文本数据集 :COCO-text 数据集是 ICDAR2017 的一部分,是基于 MSCOCO 数据集的数据集,包含日常场景的复杂图像。该数据集包含超过 63,686 张图像中超过 173,589 个标记的文本区域。该数据集可用于文本检测和文本识别的训练和评估。
如前所述,该数据集包含超过 63,686 张图像,其中 10,000 张分配给验证集,10,000 张分配给测试集。COCO-text 提供了 3 种不同的挑战和数据类型。
- 文本本地化
- 裁剪词识别
- 端到端识别
准备训练用的图像数据集。对于我们的任务,我们将下载裁剪词识别的数据集。实况标签包含在单个文本文件中,其中图像名称后跟新行中每个图像的标签。例如,
img1,label1
img2,label2
……
验证集包含大约 10,000 张图像,但我们将从该集中随机提取 500 张图像。通过在此处注册下载 数据集。如果从 Git 仓库获取的项目中已经包含或做好了随机图像数据集的抽取,则此步可跳过。本节我们所用到的图片皆来自于源码项目目录:Optical-Character-Recognition-using-PaddleOCR\COCO-text\COCO_test

1.2 脚本准备
有了训练数据集,我们将创建一个名为 display() 的辅助函数来显示图像及其标签。
脚本位置:.\PaddleOCR\applications\ocr_coco_disp.py
# Importing required libraries.
import os
import sys
import matplotlib.pyplot as plt
import matplotlib.image as img
# Function to display images along with labels.
# 显示图像和标签的功能。
def disp(pth, gt_annot = '', gt = False, out = False, num = 10):
# 用于存储图像数组的列表
img_arr = []
# 用于存储注释的列表
annot_arr = []
# Appending image array into a list.
# 将图像数组添加到列表中
for fimg in sorted((os.listdir(pth))):
# 如果是jpg 或 png 图像文件
if fimg.endswith('.jpg') or fimg.endswith('.png'):
# 读取图像
demo = img.imread(pth+fimg)
img_arr.append(demo)
# Appending dataset output into a list (OCR outputs are stored in different text files for every image).
# 将数据集输出附加到列表中(OCR 输出存储在每个图像的不同文本文件中)
if out:
with open(pth + ''.join(fimg.split())[:-8]+ '.txt') as f:
# 读取 OCR 输出
out = f.read()
f.close()
annot_arr.append(out.lower())
# Appending ground truth annotations into a list (Ground truth of all images are stored in a single text file).
# 将真实标签添加到列表中(所有图像的真实标签存储在单个文本文件中)
if gt:
with open(gt_annot) as f:
for line in f:
if line.split(',')[0] == fimg.split('.')[0]:
# 读取真实标签
gt = line.split(',')[1].lower()
annot_arr.append(gt)
break
if len(img_arr) == num:
break
# Displaying the images along with labels.
# 显示图像及其标签
_, axs = plt.subplots(2, 5, figsize=(25, 14))
axs = axs.flatten()
for cent, ax,val in zip(img_arr, axs, annot_arr):
ax.imshow(cent)
ax.set_title(val,fontsize=25)
plt.show()
调用 disp() 函数来显示测试图片和正确值:
# 调用 disp() 函数来显示测试图片和正确值
input_org = '../COCO-text/COCO_test/'
annot = '../COCO-text/gt-test.txt'
disp(input_org, annot, gt = True, num = 10)
执行脚本,可以看到我们已经将抽样的原始图像和其原本的标签(值)做了一对一显示:

准备模型训练结果输出。PP-OCR 是一系列高质量的预训练 OCR 模型,提供端到端的文本识别管道。为了比较,我们将比较 PP-OCRv3 和 PP-OCRv2 这两个超轻量级模型,支持英文和中文。
注:
(1) 如果本地之前还未安装依赖项和库,现在可 CMD 执行如下命令,进行依赖项和库安装。
pip install -r requirements.txt
(2) 如果代码提示 Levenshtein 包找不到,需要先用 CMD 手动下载一下包:
pip install python-Levenshtein

1.3 开始训练
1)PP-OCRv3
PaddleOCR 最近推出了其旗舰 PP-OCR 的新版本,即第 3 版。PP-OCRv3 声称比其先前版本的英语 PP-OCRv2 准确 11%。这是一个超轻量级的模型,大小接近 17Mb。使用浏览器打开下面地址即可下载:
https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar
下载后,将文件解压到目标:.\PaddleOCR\inference\ch_PP-OCRv3_rec_infer
注:文件夹 \inference 的名称无要求,可自定义,如果没有可自行创建。
是时候在 COCO 文本数据集上测试旗舰 PP-OCR 了。
完整案例脚本位置:.\PaddleOCR\applications\pp_ocr_v3.py
# Importing required libraries.
import os
import numpy as np
import sysimport matplotlib.pyplot as plt
import time
# 将当前脚本文件所在的目录路径添加到Python的模块搜索路径中,以便能够导入同一目录下的其他模块。
# # 获取当前脚本文件的所在目录路径,并将其赋值给变量 __dir__。
# __dir__ = os.path.dirname(__file__)
# # 将当前脚本文件所在的目录路径添加到Python的模块搜索路径中。os.path.join(__dir__, '') 用于获取完整的目录路径。
# sys.path.append(os.path.join(__dir__, ''))
# 获取当前脚本文件的绝对路径所在的目录路径,并将其赋值给变量 __dir__。
__dir__ = os.path.dirname(os.path.abspath(__file__))
# 将当前脚本文件的绝对路径所在的目录路径添加到Python的模块搜索路径中。
sys.path.append(__dir__)
# 将当前脚本文件的上一级目录路径添加到Python的模块搜索路径中。os.path.join(__dir__, '..') 用于获取上一级目录的路径,os.path.abspath() 用于获取绝对路径。
sys.path.insert(0, os.path.abspath(os.path.join(__dir__, '..')))
import importlib
tools = importlib.import_module('.', 'tools')
ppocr = importlib.import_module('.', 'ppocr')
import tools.infer.utility as utility
from tools.infer.predict_rec import *
from ppocr.utils.utility import check_and_read_gif, get_image_file_list
from ppocr.utils.logging import get_logger
logger = get_logger()
from ppocr.postprocess import build_post_process
# 通过获取多个参数并输出 OCR 结果
def rec(args, out_path, input, rec_model_dir, rec_image_shape="3, 32, 320", rec_char_type="ch", rec_algorithm="CRNN", show=True, save=True):
# 为args赋值,因为代码不是从控制台运行的
args.rec_model_dir = rec_model_dir
args.rec_image_shape = rec_image_shape
args.rec_char_type = rec_char_type
args.rec_algorithm = rec_algorithm
# 初始化一些辅助变量
t1 = 0
t2 = 0
tot = []
os.chdir('../PaddleOCR')
# 将所需的值传递给args变量
if rec_algorithm == "SRN":
print('yes')
args.rec_char_dict_path = './ppocr/utils/ic15_dict.txt'
args.use_space_char = False
if rec_algorithm == 'NRTR':
args.rec_char_dict_path = './ppocr/utils/EN_symbol_dict.txt'
args.rec_image_shape = "1,32,100"
# 初始化识别器
image_file_list = get_image_file_list(input)
text_recognizer = TextRecognizer(args)
valid_image_file_list = []
img_list = []
# 预热GPU,以充分发挥其性能
if args.warmup:
image = np.random.uniform(0, 255, [32, 320, 3]).astype(np.uint8)
for i in range(10):
res = text_recognizer([image])
# 读取并将所有图像的数组添加到列表中
for image_file in image_file_list:
image, flag = check_and_read_gif(image_file)
if not flag:
image = cv2.imread(image_file)
if image is None:
logger.info("error in loading image:{}".format(image_file))
continue
valid_image_file_list.append(image_file)
img_list.append(image)
# 对图像应用OCR
t1 = time.time()
try:
rec_res, _ = text_recognizer(img_list)
except Exception as E:
logger.info(traceback.format_exc())
logger.info(E)
exit()
# 计算FPS并打印信息
t2 = time.time()
fps = str(t2 - t1)
for ino in range(len(img_list)):
logger.info("Predicts of {}:{}".format(valid_image_file_list[ino], rec_res[ino]))
if save:
cv2.imwrite(os.path.join(out_path, valid_image_file_list[ino].split('/')[-1].split('.')[0] + '_rec' + '.jpg'), img_list[ino])
with open(os.path.join(out_path, valid_image_file_list[ino].split('/')[-1].split('.')[0] + '.txt'), 'w') as f:
f.write(str(rec_res[ino]))
logger.info("Time taken recognize all images : {}".format(fps))
print(len(image_file_list))
logger.info("Average fps : {}".format(1 / (float(fps) / len(image_file_list))))
# 显示和保存输出,根据设置的参数
if show:
plt.figure(figsize=(25, 14))
plt.imshow(image)
plt.show()
# 计算与输出和真实文本的编辑距离的度量
def score_calc(pth, annot):
# 导入距离度量方法
from Levenshtein import distance
score_all = []
# 循环遍历输出文本文件,并将OCR输出存储在变量中
for out_file in os.listdir(pth):
if out_file.endswith('.txt'):
with open(os.path.join(pth, out_file), 'rb') as f:
out = f.read()
f.close()
# 清理OCR输出文本
try:
out = str(out).split(',')[1].split(',')[0].replace("'", '').lower()
except:
print('OCR output does not exist')
# 打开真实标签文件并计算真实标签与OCR输出之间的距离
with open(annot) as f:
for line in f:
if line.split(',')[0] == out_file.split('.')[0]:
gt = line.split(',')[1].lower()
score = distance(str(out), str(gt))/len(gt)
score_all.append(score)
break
# 打印平均得分
print("final score:", sum(score_all)/len(score_all))
# --- 实验测试 -------------------------------------------------------------------------------------------
input_org = '../COCO-text/COCO_test'
out_path = './inference_results/result_ppocrv3/'
rec_model_dir = './inference/ch_PP-OCRv3_rec_infer'
sys.argv = ['']
start_time = time.time()
logger.info('开始 ...')
rec(utility.parse_args(), out_path, input_org, rec_model_dir, show = False)
end_time = time.time()
execution_time = end_time - start_time
logger.info('结束,[PP-OCRv3] 实验 500 张图像耗时 %s 秒', execution_time)
from ocr_coco_disp import disp
# 调用 disp() 函数来显示测试图片和正确值
# pth_org = '../COCO-text/COCO_test/'
annot = '../COCO-text/gt-test.txt'
# disp(input_org, annot, gt = True, num = 10)
# 调用 disp() 函数来显示测试图片和检测识别值
pth_rst = '../PaddleOCR/inference_results/result_ppocrv3/COCO_test/'
disp(pth_rst, out = True, num = 10)
# 显示得分
score_calc(pth_rst, annot)
脚本中有2个函数:
(1) 一个 rec() 函数,该函数将负责通过获取多个参数并输出 OCR 结果。
(2) 一个 score_calc() 函数,计算与输出和真实文本的编辑距离的度量,也叫置信度。
开始实验测试吧。执行上述脚本。
速度非常惊人。该管道以 15.41 的 FPS 运行,并在将近 32.44 秒钟内识别出所有 500 张图像。输出图像和预测保存在 out_path 下指定的路径中。它将在文本文件中包含输出图像及其相应的预测。

[2023/06/09 16:10:13] ppocr INFO: Predicts of ../COCO-text/COCO_test\1239241.jpg:('Crieket', 0.8044114112854004)
[2023/06/09 16:10:13] ppocr INFO: Predicts of ../COCO-text/COCO_test\1239554.jpg:('', 0.0)
[2023/06/09 16:10:13] ppocr INFO: Predicts of ../COCO-text/COCO_test\1239559.jpg:('', 0.0)
[2023/06/09 16:10:13] ppocr INFO: Predicts of ../COCO-text/COCO_test\1239825.jpg:('', 0.0)
[2023/06/09 16:10:13] ppocr INFO: Predicts of ../COCO-text/COCO_test\1240486.jpg:('koppdelney', 0.70953768491745)
[2023/06/09 16:10:13] ppocr INFO: Predicts of ../COCO-text/COCO_test\1240603.jpg:('MICEVERSA', 0.521608829498291)
[2023/06/09 16:10:13] ppocr INFO: Time taken recognize all images : 32.43732690811157
500
[2023/06/09 16:10:13] ppocr INFO: Average fps : 15.41434044230585

准确性与速度同样重要。让我们看看模型在准确性方面的表现。

从上面的代码片段中,我们可以得到指标来判断我们的 PP-OCRv3 在 COCO-text 数据集上的表现。PP-OCRv3 的表现非常惊人,得分为 2.39,而且速度也非常快。在以下部分中,我们将了解其他模型的表现。
2)PP-OCRv2
PP-OCRv2 也是一个非常准确的模型,但理论上不如最新的版本3。我们来验证一下,在下面的代码片段中,我们将计算 PP-OCRv2 的分数并查看它的表现。
浏览器打开 URL 下载模型:
https://paddleocr.bj.bcebos.com/dygraph_v2.1/chinese/ch_PP-OCRv2_rec_infer.tar
解压后位置:.\PaddleOCR\inference\ch_PP-OCRv2_rec_infer
脚本内容与基本类似,但有个地方需要注意,如果出现异常:
UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘\xae’ in position 2: illegal multibyte sequence
侧需要对 open() 函数加个入参:encoding=‘utf-8’
本地脚本位置:.\PaddleOCR\applications\pp_ocr_v3.py。完整代码如下:
import os
import numpy as np
import sys
import matplotlib.pyplot as plt
import time
# 将当前脚本文件所在的目录路径添加到Python的模块搜索路径中,以便能够导入同一目录下的其他模块。
# # 获取当前脚本文件的所在目录路径,并将其赋值给变量 __dir__。
# __dir__ = os.path.dirname(__file__)
# # 将当前脚本文件所在的目录路径添加到Python的模块搜索路径中。os.path.join(__dir__, '') 用于获取完整的目录路径。
# sys.path.append(os.path.join(__dir__, ''))
# 获取当前脚本文件的绝对路径所在的目录路径,并将其赋值给变量 __dir__。
__dir__ = os.path.dirname(os.path.abspath(__file__))
# 将当前脚本文件的绝对路径所在的目录路径添加到Python的模块搜索路径中。
sys.path.append(__dir__)
# 将当前脚本文件的上一级目录路径添加到Python的模块搜索路径中。os.path.join(__dir__, '..') 用于获取上一级目录的路径,os.path.abspath() 用于获取绝对路径。
sys.path.insert(0, os.path.abspath(os.path.join(__dir__, '..')))
import importlib
tools = importlib.import_module('.', 'tools')
ppocr = importlib.import_module('.', 'ppocr')
import tools.infer.utility as utility
from tools.infer.predict_rec import *
from ppocr.utils.utility import check_and_read_gif, get_image_file_list
from ppocr.utils.logging import get_logger
logger = get_logger()
from ppocr.postprocess import build_post_process
# 通过获取多个参数并输出 OCR 结果
def rec(args, out_path, input, rec_model_dir, rec_image_shape="3, 32, 320", rec_char_type="ch", rec_algorithm="CRNN", show=True, save=True):
# 为args赋值,因为代码不是从控制台运行的
args.rec_model_dir = rec_model_dir
args.rec_image_shape = rec_image_shape
args.rec_char_type = rec_char_type
args.rec_algorithm = rec_algorithm
# 初始化一些辅助变量
t1 = 0
t2 = 0
tot = []
os.chdir('../PaddleOCR')
# 将所需的值传递给args变量
if rec_algorithm == "SRN":
print('yes')
args.rec_char_dict_path = './ppocr/utils/ic15_dict.txt'
args.use_space_char = False
if rec_algorithm == 'NRTR':
args.rec_char_dict_path = './ppocr/utils/EN_symbol_dict.txt'
args.rec_image_shape = "1,32,100"
# 初始化识别器
image_file_list = get_image_file_list(input)
text_recognizer = TextRecognizer(args)
valid_image_file_list = []
img_list = []
# 预热GPU,以充分发挥其性能
if args.warmup:
image = np.random.uniform(0, 255, [32, 320, 3]).astype(np.uint8)
for i in range(10):
res = text_recognizer([image])
# 读取并将所有图像的数组添加到列表中
for image_file in image_file_list:
image, flag = check_and_read_gif(image_file)
if not flag:
image = cv2.imread(image_file)
if image is None:
logger.info("error in loading image:{}".format(image_file))
continue
valid_image_file_list.append(image_file)
img_list.append(image)
# 对图像应用OCR
t1 = time.time()
try:
rec_res, _ = text_recognizer(img_list)
except Exception as E:
logger.info(traceback.format_exc())
logger.info(E)
exit()
# 计算FPS并打印信息
t2 = time.time()
fps = str(t2 - t1)
for ino in range(len(img_list)):
logger.info("Predicts of {}:{}".format(valid_image_file_list[ino], rec_res[ino]))
if save:
cv2.imwrite(os.path.join(out_path, valid_image_file_list[ino].split('/')[-1].split('.')[0] + '_rec' + '.jpg'), img_list[ino])
with open(os.path.join(out_path, valid_image_file_list[ino].split('/')[-1].split('.')[0] + '.txt'), 'w', encoding='utf-8') as f:
f.write(str(rec_res[ino]))
logger.info("Time taken recognize all images : {}".format(fps))
print(len(image_file_list))
logger.info("Average fps : {}".format(1 / (float(fps) / len(image_file_list))))
# 显示和保存输出,根据设置的参数
if show:
plt.figure(figsize=(25, 14))
plt.imshow(image)
plt.show()
# 计算与输出和真实文本的编辑距离的度量
def score_calc(pth, annot):
# 导入距离度量方法
from Levenshtein import distance
score_all = []
# 循环遍历输出文本文件,并将OCR输出存储在变量中
for out_file in os.listdir(pth):
if out_file.endswith('.txt'):
with open(os.path.join(pth, out_file), 'rb') as f:
out = f.read()
f.close()
# 清理OCR输出文本
try:
out = str(out).split(',')[1].split(',')[0].replace("'", '').lower()
except:
print('OCR output does not exist')
# 打开真实标签文件并计算真实标签与OCR输出之间的距离
with open(annot) as f:
for line in f:
if line.split(',')[0] == out_file.split('.')[0]:
gt = line.split(',')[1].lower()
score = distance(str(out), str(gt))/len(gt)
score_all.append(score)
break
# 打印平均得分
print("final score:", sum(score_all)/len(score_all))
# --- 实验测试 -------------------------------------------------------------------------------------------
input_org = '../COCO-text/COCO_test'
out_path = './inference_results/result_ppocrv2/'
rec_model_dir = './inference/ch_PP-OCRv2_rec_infer'
sys.argv = ['']
start_time = time.time()
logger.info('开始 ...')
rec(utility.parse_args(), out_path, input_org, rec_model_dir, show = False)
end_time = time.time()
execution_time = end_time - start_time
logger.info('结束,[PP-OCRv3] 实验 500 张图像耗时 %s 秒', execution_time)
from ocr_coco_disp import disp
# 调用 disp() 函数来显示测试图片和正确值
# pth_org = '../COCO-text/COCO_test/'
annot = '../COCO-text/gt-test.txt'
# disp(input_org, annot, gt = True, num = 10)
# 调用 disp() 函数来显示测试图片和检测识别值
pth_rst = '../PaddleOCR/inference_results/result_ppocrv2/COCO_test/'
disp(pth_rst, out = True, num = 10)
# 显示得分
score_calc(pth_rst, annot)

[2023/06/12 15:00:43] ppocr INFO: Time taken recognize all images : 35.80784869194031
500
[2023/06/12 15:00:43] ppocr INFO: Average fps : 13.963419145941065
final score: 3.1595520470270504
哇!!整个数据集在 35.8 秒内处理完毕,平均 FPS 为 13.96。
我们得到了指标,上面的代码片段输出了 3.16 的置信度分数,这意味着 500 张图像的平均 Levenshtein 距离为 3.16。两相对比,PP-OCRv2 在速度和准确性方面稍逊于 PP-OCRv3。
3)SRN
SRN 是 PaddleOCR 支持的另一种模型。它代表语义推理网络,它克服了类似 RNN 结构的缺点。SRN 是一个非常庞大的模型,大小超过 900 MB。SRN 声称非常准确,但以速度为代价。让我们在数据集上对其进行测试,看看它的表现如何。
先下载模型:
https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_r50_vd_srn_train.tar
解压后位置:.\PaddleOCR\inference\rec_r50_vd_srn_train
使用 CMD 执行如下命令,将保存的模型转换为推理模型:
python tools/export_model.py -c configs/rec/rec_r50_fpn_srn.yml -o Global.pretrained_model=./inference/rec_r50_vd_srn_train/best_accuracy Global.save_inference_dir=./inference/rec_r50_vd_srn_train
这一步是将保存的模型转换为推理模型("Converting saved model to inference model" )。
在机器学习和深度学习中,训练模型和推理模型是不同的。训练模型是在训练阶段使用训练数据进行模型的训练和参数优化,以便模型能够学习并适应数据的模式和特征。而推理模型则是在训练完成后,用于对新的输入数据进行预测或推理的模型。
当你训练完成一个模型后,通常会将其保存为一个文件或目录,包含了模型的参数、权重以及其他必要的信息。这个保存的模型可以被加载到程序中,用于进行预测任务。
“Converting saved model to inference model” 的过程就是将保存的训练模型进行一些处理或转换,以便它可以被用于推理任务。这可能涉及到模型的格式转换、优化、裁剪或其他必要的操作,以确保模型在推理阶段具有更高的效率和性能。

这样,我们就得到了一个从训练模型 rec_r50_vd_srn_train 转换过来的 推理模型(运行成功后,存放训练模型的目录会多三个推理模型文件):

SRN 在不同的图像尺寸上进行训练,因此,输入图像需要调整到该尺寸,即“1, 64, 256”。因此,我们需要传递一些参数来获得 SRN 所需的功能。
- rec_image_shape = ‘1, 64, 256’
- rec_char_type = ‘en’,
- rec_algorithm = ‘SRN’
这里可以使用 PP-OCRv3的脚本,只是我将输出目录做了调整。
脚本位置:\PaddleOCR\applications\pp_ocr_srn.py,完整脚本如下:
# Importing required libraries.
import os
import numpy as np
import sys
import matplotlib.pyplot as plt
import time
# 将当前脚本文件所在的目录路径添加到Python的模块搜索路径中,以便能够导入同一目录下的其他模块。
# # 获取当前脚本文件的所在目录路径,并将其赋值给变量 __dir__。
# __dir__ = os.path.dirname(__file__)
# # 将当前脚本文件所在的目录路径添加到Python的模块搜索路径中。os.path.join(__dir__, '') 用于获取完整的目录路径。
# sys.path.append(os.path.join(__dir__, ''))
# 获取当前脚本文件的绝对路径所在的目录路径,并将其赋值给变量 __dir__。
__dir__ = os.path.dirname(os.path.abspath(__file__))
# 将当前脚本文件的绝对路径所在的目录路径添加到Python的模块搜索路径中。
sys.path.append(__dir__)
# 将当前脚本文件的上一级目录路径添加到Python的模块搜索路径中。os.path.join(__dir__, '..') 用于获取上一级目录的路径,os.path.abspath() 用于获取绝对路径。
sys.path.insert(0, os.path.abspath(os.path.join(__dir__, '..')))
import importlib
tools = importlib.import_module('.', 'tools')
ppocr = importlib.import_module('.', 'ppocr')
import tools.infer.utility as utility
from tools.infer.predict_rec import *
from ppocr.utils.utility import check_and_read_gif, get_image_file_list
from ppocr.utils.logging import get_logger
logger = get_logger()
from ppocr.postprocess import build_post_process
# from ppocr.utils.logging import get_logger
# from PaddleOCR.ppocr.utils.utility import get_image_file_list, check_and_read_gif
def rec(args, out_path, input, rec_model_dir, rec_image_shape="3, 32, 320", rec_char_type="ch", rec_algorithm="CRNN", show=True, save=True):
# 为args赋值,因为代码不是从控制台运行的
args.rec_model_dir = rec_model_dir
args.rec_image_shape = rec_image_shape
args.rec_char_type = rec_char_type
args.rec_algorithm = rec_algorithm
# 初始化一些辅助变量
t1 = 0
t2 = 0
tot = []
os.chdir('../PaddleOCR')
# 将所需的值传递给args变量
if rec_algorithm == "SRN":
print('yes')
args.rec_char_dict_path = './ppocr/utils/ic15_dict.txt'
args.use_space_char = False
if rec_algorithm == 'NRTR':
args.rec_char_dict_path = './ppocr/utils/EN_symbol_dict.txt'
args.rec_image_shape = "1,32,100"
# 初始化识别器
image_file_list = get_image_file_list(input)
text_recognizer = TextRecognizer(args)
valid_image_file_list = []
img_list = []
# 预热GPU,以充分发挥其性能
if args.warmup:
image = np.random.uniform(0, 255, [32, 320, 3]).astype(np.uint8)
for i in range(10):
res = text_recognizer([image])
# 读取并将所有图像的数组添加到列表中
for image_file in image_file_list:
image, flag = check_and_read_gif(image_file)
if not flag:
image = cv2.imread(image_file)
if image is None:
logger.info("error in loading image:{}".format(image_file))
continue
valid_image_file_list.append(image_file)
img_list.append(image)
# 对图像应用OCR
t1 = time.time()
try:
rec_res, _ = text_recognizer(img_list)
except Exception as E:
logger.info(traceback.format_exc())
logger.info(E)
exit()
# 计算FPS并打印信息
t2 = time.time()
fps = str(t2 - t1)
for ino in range(len(img_list)):
logger.info("Predicts of {}:{}".format(valid_image_file_list[ino], rec_res[ino]))
if save:
cv2.imwrite(os.path.join(out_path, valid_image_file_list[ino].split('/')[-1].split('.')[0] + '_rec' + '.jpg'), img_list[ino])
with open(os.path.join(out_path, valid_image_file_list[ino].split('/')[-1].split('.')[0] + '.txt'), 'w') as f:
f.write(str(rec_res[ino]))
logger.info("Time taken recognize all images : {}".format(fps))
print(len(image_file_list))
logger.info("Average fps : {}".format(1 / (float(fps) / len(image_file_list))))
# 显示和保存输出,根据设置的参数
if show:
plt.figure(figsize=(25, 14))
plt.imshow(image)
plt.show()
def score_calc(pth, annot):
# 导入距离度量方法
from Levenshtein import distance
score_all = []
# 循环遍历输出文本文件,并将OCR输出存储在变量中
for out_file in os.listdir(pth):
if out_file.endswith('.txt'):
with open(os.path.join(pth, out_file), 'rb') as f:
out = f.read()
f.close()
# 清理OCR输出文本
try:
out = str(out).split(',')[1].split(',')[0].replace("'", '').lower()
except:
print('OCR output does not exist')
# 打开真实标签文件并计算真实标签与OCR输出之间的距离
with open(annot) as f:
for line in f:
if line.split(',')[0] == out_file.split('.')[0]:
gt = line.split(',')[1].lower()
score = distance(str(out), str(gt))/len(gt)
score_all.append(score)
break
# 打印平均得分
print("final score:", sum(score_all)/len(score_all))
# --- 实验测试 -------------------------------------------------------------------------------------------
input_org = '../COCO-text/COCO_test'
out_path = './inference_results/result_srn/'
rec_model_dir = './inference/rec_r50_vd_srn_train'
sys.argv = ['']
start_time = time.time()
logger.info('开始 ...')
rec(utility.parse_args(), out_path, input_org, rec_model_dir, rec_image_shape = '1, 64, 256', rec_char_type = 'en', rec_algorithm = 'SRN', show = False)
end_time = time.time()
execution_time = end_time - start_time
logger.info('结束,[PP-OCRv3] 实验 500 张图像耗时 %s 秒', execution_time)
from ocr_coco_disp import disp
# 调用 disp() 函数来显示测试图片和正确值
# pth_org = '../COCO-text/COCO_test/'
annot = '../COCO-text/gt-test.txt'
# disp(input_org, annot, gt = True, num = 10)
# 调用 disp() 函数来显示测试图片和检测识别值
pth_rst = '../PaddleOCR/inference_results/result_srn/COCO_test/'
disp(pth_rst, out = True, num = 10)
# 显示得分
score_calc(pth_rst, annot)
执行脚本,跑起来了,但运行速度有点慢,整个检测过程耗时137.35 秒,大约 3.64 FPS。


置信度分数得分为 3.05,与之前看到的 PP-OCRv2 非常接近。因此,PP-OCRv3 仍然是测试算法中最好的。
4)NRTR
NRTR 是 PaddleOCR 支持的最准确的模型之一。NRTR 代表无重复序列到序列文本识别器。根据其论文,NRTR 遵循编码器-解码器方法,其中编码器使用堆叠式自注意力来提取图像特征,解码器使用堆叠式自注意力来识别基于编码器输出的文本。是时候看看它的实际应用了。
下载模型,大小 372M 左右:
https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_mtb_nrtr_train.tar
解压后目录:.\PaddleOCR\inference\rec_mtb_nrtr_train
使用 CMD 执行如下命令,将保存的模型转换为推理模型:
python tools/export_model.py -c configs/rec/rec_mtb_nrtr.yml -o Global.pretrained_model=./inference/rec_mtb_nrtr_train/best_accuracy Global.save_inference_dir=./inference/rec_mtb_nrtr_train
但是遗憾的是,这个算法未能成功转换成推理模型。这个问题可能是由于 PaddlePaddle 版本不兼容或代码中的某些错误导致的。尝试后目前未能成功解决。
按官方的分析,NRTR 的距离度量(置信度得分)可与 PP-OCRv3 相媲美,但速度也是所有速度中最低的。这种准确性是以速度为代价实现的,这是不值得的,因为我们有 PP-OCRv3,它可以更好地工作并且速度更快。
二、结果分析
从上面的实验我们可以得出结论,PP-OCR 在速度和准确性方面都是一种非常强大的算法。PP-OCRv3 在所有实施的算法中表现最好,在速度和准确性方面都表现出色。作为轻量级模型,PP-OCRv2 和 v3 的性能与最新的大型模型(如 SRN 和 NRTR)相当甚至更好。整个实验总结在下表中。
| Model | Average FPS | time(second) | Distance score | Result |
|---|---|---|---|---|
| PP-OCRv3 | 15.41 | 32.44 | 2.39 | 速度非常快,置信度高 |
| PP-OCRv2 | 13.96 | 35.8 | 3.16 | 较PP-OCRv3,置信度稍低 |
| SRN | 3.64 | 137.35 | 3.05 | 重量级算法,置信度与PP-OCRv2相差接近,但速度较慢 |
| NRTR | - | - | - | 重量级算法,置信度与PP-OCRv3相差不太,但速度较慢 |
在速度和准确性方面与官方实验结果一致:

三、实验结论
在这篇博文中,我们看到了 PaddleOCR 的强大功能。从其旗舰 PP-OCR 到最新的高级算法,PaddleOCR 表现出色。在某些情况下,PP-OCR 表现不佳,例如小文本、弯曲文本和手写文本。别担心,如果使用适当的数据进行训练,这些问题是可以解决的。
我们还测试了 PaddleOCR 提供的一些模型。总之,我们已经看到,PP-OCRv3 是一种非常强大的算法,可以提供与 NRTR 相当的结果,但速度非常快。SRN 是一种重量级算法,但与 PP-OCR 相比表现不佳。PaddleOCR 还提供了许多其他算法,如 SAR、RARE 等,你也可以自己尝试。
四、参考文献
opencv开源项目:https://github.com/spmallick/learnopencv/tree/master/Optical-Character-Recognition-using-PaddleOCR
opencv官方文档:https://learnopencv.com/optical-character-recognition-using-paddleocr/
paddlepaddle官方文档:https://www.paddlepaddle.org.cn/documentation/docs/zh/install/pip/windows-pip.html
系列攻略:
PaddleOCR #hello paddle: 从普通程序走向机器学习程序 - 初识机器学习
PaddleOCR #使用PaddleOCR进行光学字符识别(PP-OCR文本检测识别)