本文以及相关工具和代码旨在为已上线的iOS项目提供一种快速支持多语言的解决方案。由于文案显示是通过hook实现的,因此对App的性能有一定影响;除了特殊场景的文案显示需要手动支持外,其他任务均已实现自动化。
本文中的部分脚本代码基于 ChatGPT4.0 和 Github Copilot 完成,文案翻译通过 Cloud Translation API 进行。若条件允许,建议进行人工二次确认以确保翻译质量。
对于大多数场景下,App向用户展示的文案或资料通常来自接口下发或本地代码内置(hardcode)。本文将重点介绍hardcode中的国际化解决方案。
整体的解决思路如下,以供大家参考:
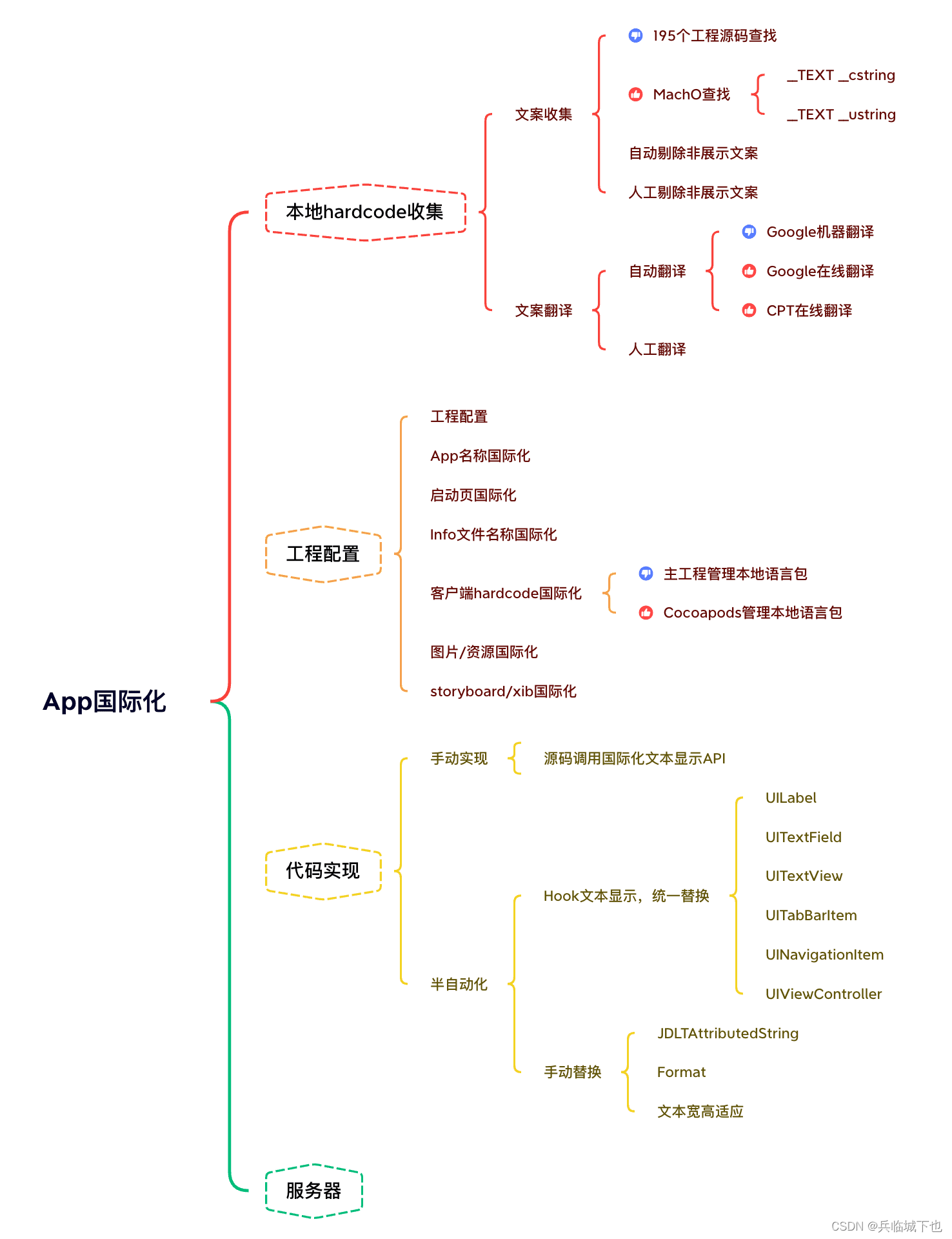
一、本地hardcode文案收集及翻译
1、文案收集
1.1、源码查找收集
收集文案最简单的方式就是全局代码搜索。对于一个工程管理良好的项目,这个过程可能相对简单。然而,对于包含195个模块的 京喜特价 这样的项目,特别是那些以二进制形式集成到主工程的项目,这将耗费大量的时间。
为了解决这个问题,我们可以使用一些自动化工具来辅助我们完成文案收集的工作。
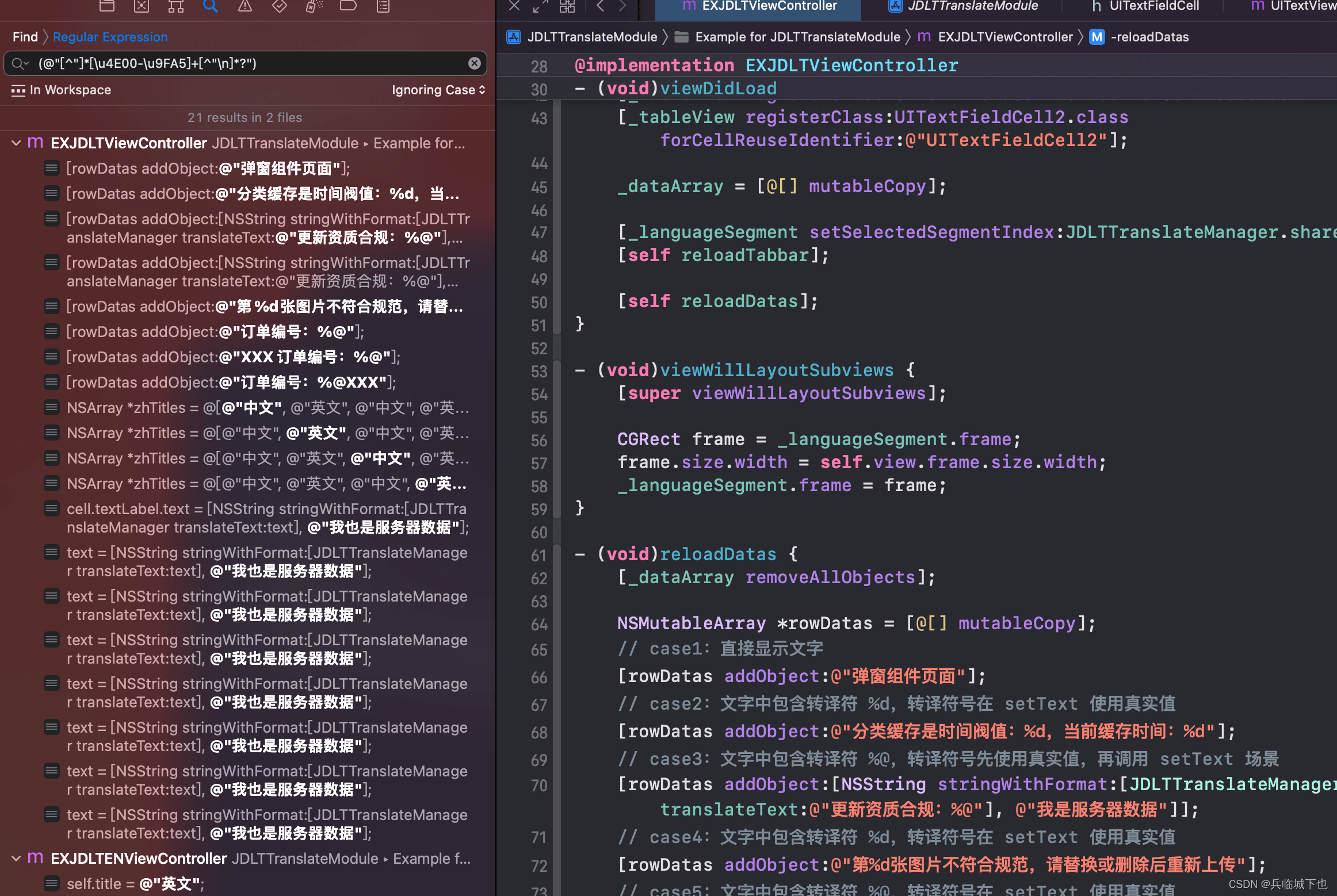
Step1、正则查找替换
使用正则表达式查找并替换客户端hardcode文案:
Objective-C 代码中:搜索条件里输入 (@"[^"]*[\u4E00-\u9FA5]+[^"\n]*?")
替换内容里输入 NSLocalizedString($0, nil)
Swift 代码中:搜索条件里输入("[^"]*[\u4E00-\u9FA5]+[^"\n]*?")、底部筛选过滤出 .swift 文件
替换内容里输入 NSLocalizedString($0, comment: "")
正则搜索查询:
替换效果如下:
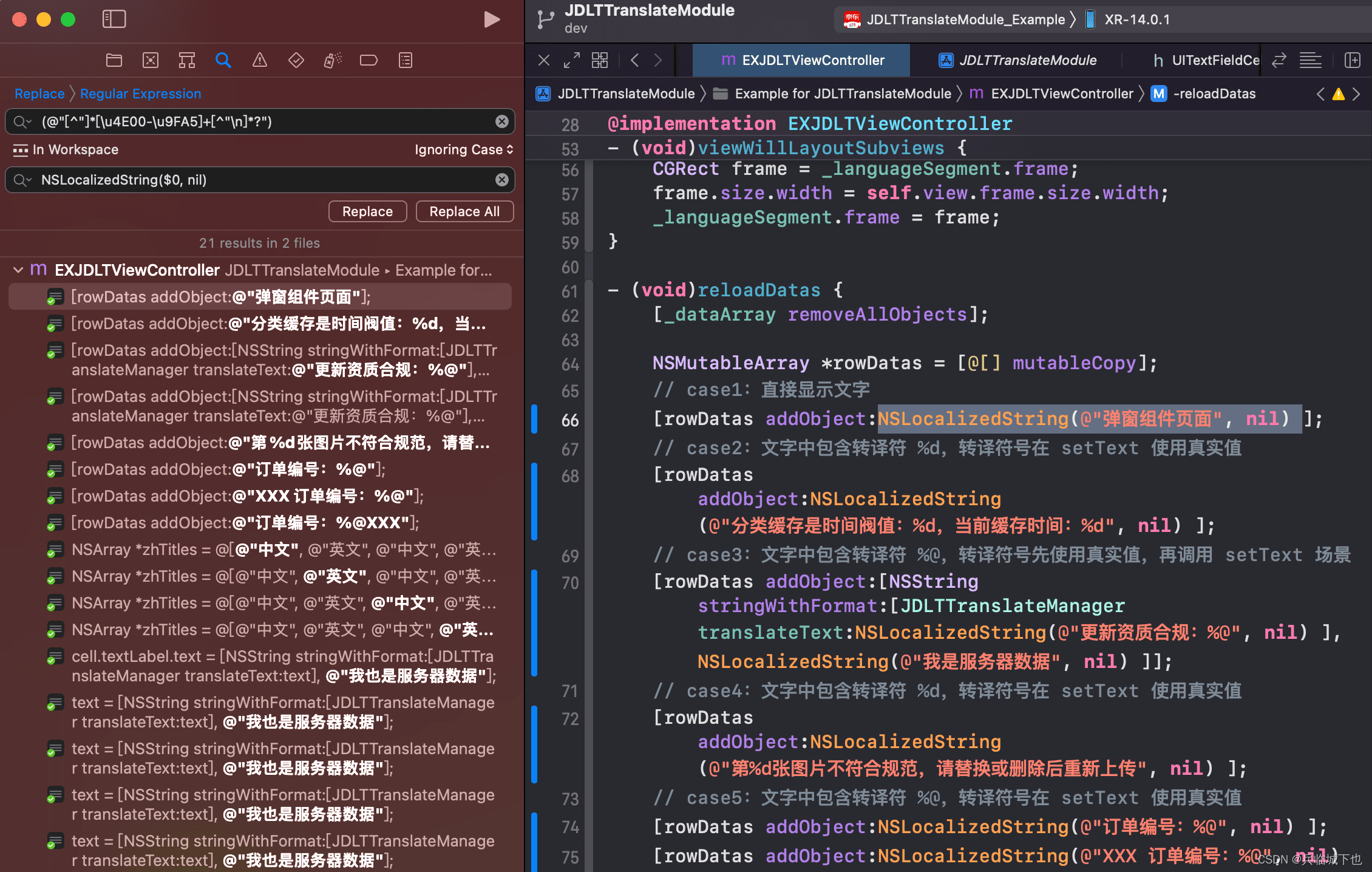
在本文中,我们提供了一种使用正则表达式查找并替换客户端hardcode文案的方法。这种方法在 Objective-C 代码中是有效的。然而,在 Swift 代码中,您需要使用不同的正则表达式进行查找。具体操作如下:
- 在搜索条件中输入
("[^"]*[\u4E00-\u9FA5]+[^"\n]*?")。 - 在底部的文件筛选输入
.swift进行过滤。
这样,您就可以在 Swift 代码中找到所有包含中文字符的字符串字面量,并使用 NSLocalizedString 进行替换,以实现多语言支持
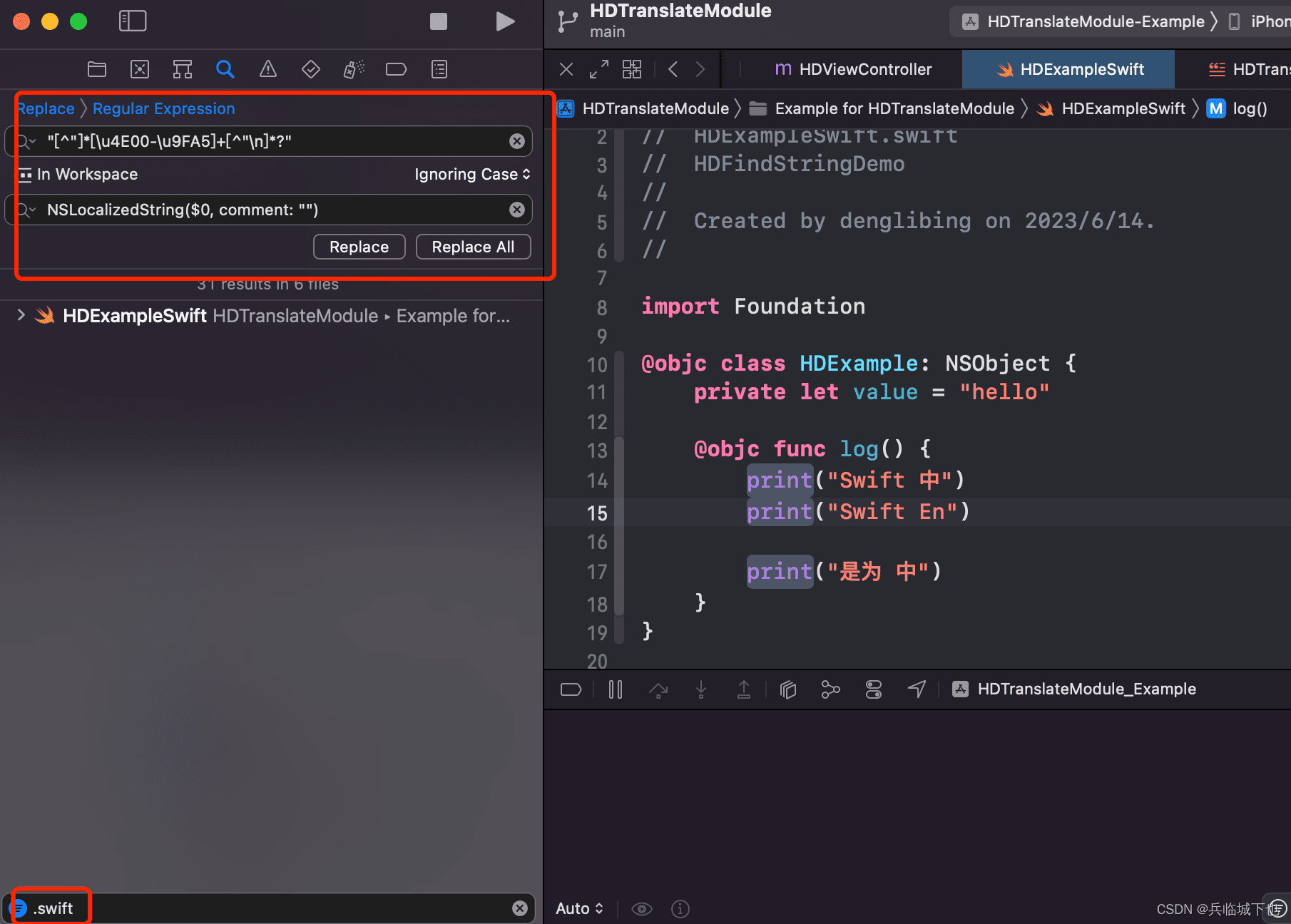
替换前后对比:
// 替换前:
@objc func log() {
print("Swift 中")
print("Swift En")
print("是为 中")
}
// 替换后:
@objc func log() {
print(NSLocalizedString("Swift 中", comment: "") )
print("Swift En")
print(NSLocalizedString("是为 中", comment: "") )
}
Step2、生成语言包
收集客户端hardcode中的中文并生成国际化语言包:
# 1、在项目的根路径下
➜ HDTranslateModule git:(main) ✗ tree -L 1
.
├── Assets
├── Example
├── HDTranslateModule
├── HDTranslateModule.podspec
├── LICENSE
├── README.md
└── _Pods.xcodeproj -> Example/Pods/Pods.xcodeproj
4 directories, 3 files
# 2、创建 en.lproj 多语言文件夹,保存多语言包
➜ HDTranslateModule git:(main) ✗ mkdir en.lproj
# genstrings工具用于从Objective-C或Swift源代码文件中提取本地化字符串。
# 3、因为我的测试代码在 Example/HDTranslateModule 中, 执行如下命令 从 .m 或者 .swift 文件中找到 本地化字符串
➜ HDTranslateModule git:(main) ✗ find Example/HDTranslateModule \( -name "*.m" -o -name "*.swift" \) -print0 | xargs -0 genstrings -o en.lproj
成功后,会在 en.lproj 路径下生成 Localizable.strings 文件:
/* No comment provided by engineer. */
"Swift 中" = "Swift 中";
/* No comment provided by engineer. */
"中文" = "中文";
/* No comment provided by engineer. */
"分类缓存是时间阀值:%d,当前缓存时间:%d" = "分类缓存是时间阀值:%1$d,当前缓存时间:%2$d";
/* No comment provided by engineer. */
"弹窗组件页面" = "弹窗组件页面";
/* No comment provided by engineer. */
"我也是服务器数据" = "我也是服务器数据";
/* No comment provided by engineer. */
"我是服务器数据" = "我是服务器数据";
/* No comment provided by engineer. */
"是为 中" = "是为 中";
/* No comment provided by engineer. */
"更新资质合规:%@" = "更新资质合规:%@";
/* No comment provided by engineer. */
"第%d张图片不符合规范,请替换或删除后重新上传" = "第%d张图片不符合规范,请替换或删除后重新上传";
/* No comment provided by engineer. */
"英文" = "英文";
/* No comment provided by engineer. */
"订单编号:%@" = "订单编号:%@";
现在,您已经成功生成了国际化语言包 Localizable.strings。接下来,您可以将其翻译成其他语言,并将其放入相应的 .lproj 文件夹中,以实现多语言支持。
多个 Localizable.strings 文件合并问题
genstrings 工具会在指定的输出目录中生成一个新的 Localizable.strings 文件,如果该文件已经存在,genstrings 会覆盖它。因此,你不能直接使用 genstrings 将数据追加到现有的 en.lproj/Localizable.strings 文件中。
**问:**xargs genstrings -o en.lproj 如何追加数据到 en.lproj 文件中
答(解决方案由 HiBox 中的GPT4.0 提供)
genstrings 工具会在指定的输出目录中生成一个新的 Localizable.strings 文件,如果该文件已经存在,genstrings 会覆盖它。因此,你不能直接使用 genstrings 将数据追加到现有的 en.lproj/Localizable.strings 文件中。
但是,你可以使用以下方法将新生成的 Localizable.strings 文件与现有的文件合并:
1、使用 genstrings 将新的本地化字符串输出到一个临时目录,例如temp.lproj:
# 本地化字符串写入在 en.lproj/Localizable.strings 文件中
➜ HDTranslateModule git:(main) ✗ find Example/HDTranslateModule -name "*.m" | xargs genstrings -o en.lproj
# swift 文件本地化字符串写入在 temp.lproj/Localizable.strings 文件中
➜ HDTranslateModule git:(main) ✗ mkdir temp.lproj
➜ HDTranslateModule git:(main) ✗ find Example/HDTranslateModule -name "*.swift" | xargs genstrings -o temp.lproj
2、使用 iconv 将 en.lproj/Localizable.strings 和 temp.lproj/Localizable.strings 文件转换为UTF-8编码,并将结果保存到临时文件:
✗ iconv -f UTF-16 -t UTF-8 en.lproj/Localizable.strings > en.lproj/Localizable.strings.utf8
✗ iconv -f UTF-16 -t UTF-8 temp.lproj/Localizable.strings > temp.lproj/Localizable.strings.utf8
3、使用awk命令将两个UTF-8编码的文件合并,并删除重复的键:
✗ awk -F= -v OFS== '!_[$1]++' en.lproj/Localizable.strings.utf8 temp.lproj/Localizable.strings.utf8 > en.lproj/Localizable.strings.merged.utf8
4、使用 iconv 将合并后的UTF-8编码的文件转换回UTF-16编码,并将结果保存到 en.lproj/Localizable.strings 文件:
✗ iconv -f UTF-8 -t UTF-16 en.lproj/Localizable.strings.merged.utf8 > en.lproj/Localizable.strings
5、删除临时文件:
✗ rm en.lproj/Localizable.strings.utf8 temp.lproj/Localizable.strings.utf8 en.lproj/Localizable.strings.merged.utf8
✗ rm -r temp.lproj
总结: 这个方案优点就是在 Objective-C、Swift 源码工程中将查找文案、使用国际代码(NSLocalizedString)一次性解决,并且输出 多语言包,即 Localizable.strings 文件。
1.2、Mach-O查找收集
Step1、Section- Segment查找
在这个场景中,我们将使用 Hopper Disassembler 工具来分析字符串在哪个 Section 中的哪个 Segment 中。Hopper Disassembler 是一个反汇编和反编译工具,可以帮助我们更好地理解二进制文件的结构和功能。
- 首先,打开 Hopper Disassembler 并加载你想要分析的 Mach-O 二进制文件。通常,这是一个 iOS 或 macOS 应用程序的主要可执行文件。
- 在 Hopper 的左侧窗格中,你会看到一个名为 “Segments and Sections” 的面板。这个面板显示了二进制文件中的所有 Segment 和 Section。
- 通过展开 Segment,你可以查看它们包含的各个 Section。通常,字符串数据存储在
__TEXTSegment 的__cstring或__objc_methnameSection 中。__TEXTSegment 包含了程序的只读数据,如代码和字符串常量。 - 单击你感兴趣的 Section,Hopper 将在右侧窗格中显示该 Section 的内容。你可以在这里查看和搜索字符串数据。
- 如果你想要查找特定的字符串,可以使用 Hopper 的搜索功能。在顶部菜单栏中,选择 “Edit” > “Find”,然后输入你要查找的字符串。Hopper 将高亮显示所有匹配的结果。
通过这种方法,你可以找到字符串在 Mach-O 二进制文件中的确切位置。这对于分析和调试应用程序非常有用,特别是当你需要了解字符串是如何在程序中使用的。
场景1(查找 __cstring 中的字符串):
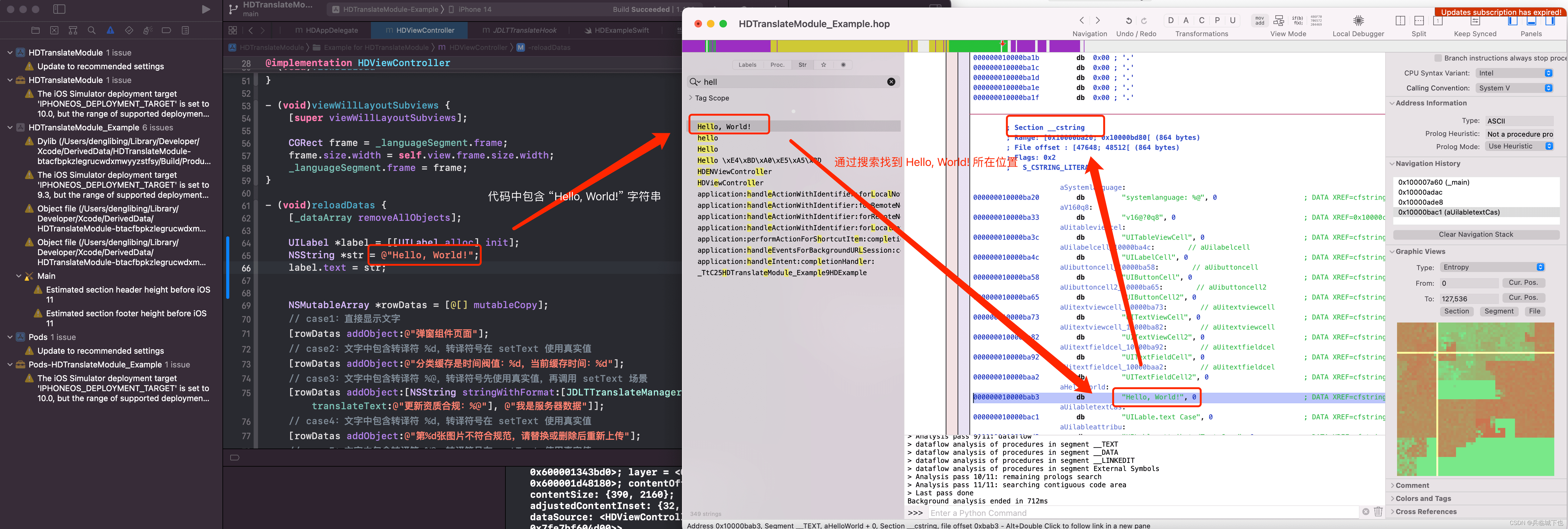
场景2(查找 __ustring 中的字符串):
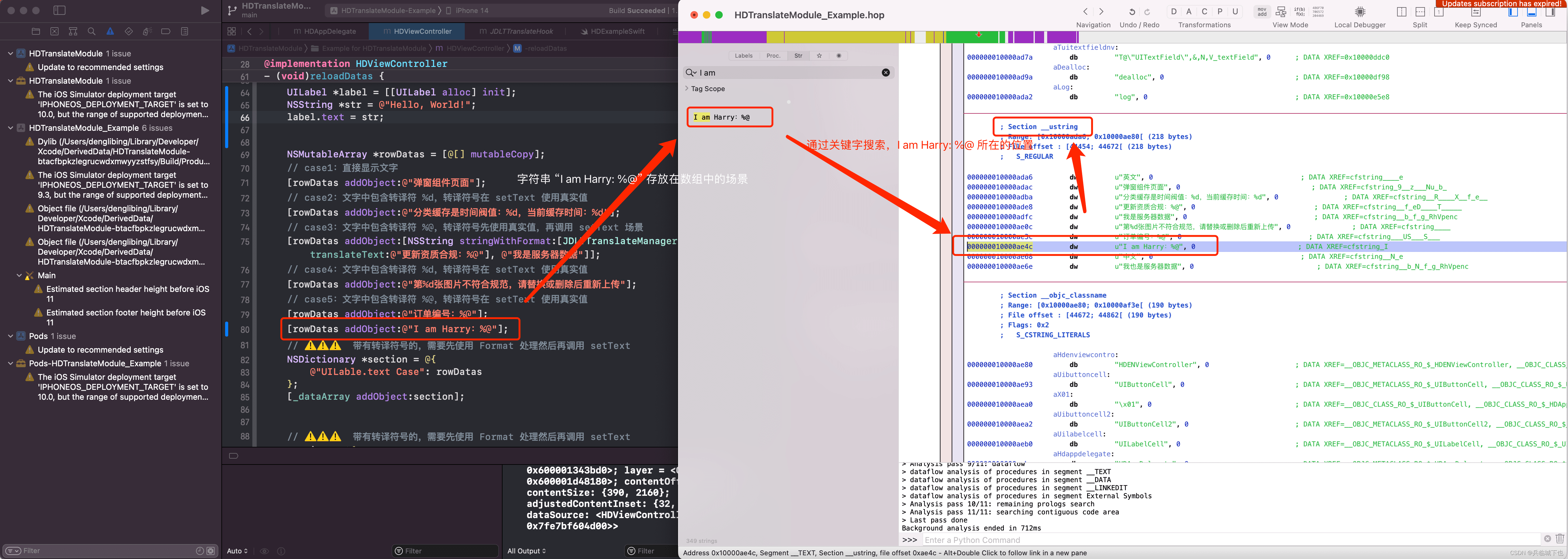
可以发现在 Mach-O 文件中存放 字符串主要是在 __TEXT __cstring、__TEXT __ustring 中。
问:请你总结一下 cstring 还是 ustring 分布存放哪些内容?最好有代码举例说明。
答(解决方案由 HiBox 中的GPT4.0 提供):
在 Objective-C 中,__cstring 和 __ustring 节分别用于存储 C 风格的字符串常量和 NSString 对象的字符串常量。以下是两者的区别和代码示例:
__cstring 节:存储 C 风格的字符串常量,即以 ‘\0’ 结尾的字符数组。
const char *cString = "Hello, World!";
在这个例子中,“Hello, World!” 是一个 C 风格的字符串常量,它将被存储在 __cstring 节中。
__ustring 节:存储 NSString 对象的字符串常量。
NSString *nsString = @"Hello, World!";
在这个例子中,“Hello, World!” 是一个 NSString 对象的字符串常量,它将被存储在 __ustring 节中。
需要注意的是,编译器可能会对字符串常量进行优化,因此在某些情况下,即使您使用的是 NSString 对象,字符串常量仍然可能被存储在 __cstring 节中。这种优化取决于编译器的实现,因此在不同的编译器或编译选项下,结果可能会有所不同。在实际编程中,您通常不需要关心字符串常量是存储在 __cstring 还是 __ustring 节中,因为这是编译器内部的优化细节。您只需要关注如何正确地使用字符串即可。
问:Swift也是类似的存放规则吗?
答:
是的,Swift 中的字符串常量存储规则与 Objective-C 类似。在 Swift 中,字符串常量通常存储在程序的常量区域,这个区域类似于 Objective-C 中的 __ustring 节。这有助于优化内存使用和提高程序运行效率。
在 Swift 中,字符串常量是通过 String 类型表示的。例如:
let swiftString = "Hello, World!"
在这个例子中,“Hello, World!” 是一个字符串常量,它将被存储在类似于 Objective-C 中的 __ustring 节的内存区域中。需要注意的是,Swift 的 String 类型与 Objective-C 的 NSString 类型在底层实现上有所不同,但它们在存储字符串常量方面的规则是类似的。
问:测试发现,“Hello, World!” 是在 __cstring 节中
答:
抱歉之前的回答给您带来了困扰。经过进一步了解,我发现在 Swift 中,字符串常量实际上是存储在 __cstring 节中的。虽然这个字符串常量被视为一个 String 对象,但编译器会将其存储在 __cstring 节中以进行优化。
所以,在您的示例中:
let swiftString = "Hello, World!"
“Hello, World!” 字符串常量确实是存储在 __cstring 节中的。
总结: 从上面的一问一答看出,GPT4包含的知识面很全,上下文的理解能力也很强,但是很多问题的答案是有问题的,这里一定需要有自己的判断力和实践操作,避免被带入到坑中。
Step2、自动生成语言包
这部分的思路及流程为
Mach-O查找字符串 > 中文字符串查找收集 > 中文字符串编解码还原 > 制定格式输出到文件中
-
Mach-O查找字符串
使用 Hopper Disassembler 或类似工具分析 Mach-O 二进制文件,找到字符串所在的 Section 和 Segment。通常,字符串数据存储在 __TEXT Segment 的 __cstring 或 __objc_methname Section 中。
-
中文字符串查找收集
遍历 Section 中的字符串,使用正则表达式或其他方法筛选出中文字符串。
-
中文字符串编解码还原
对收集到的中文字符串进行编解码还原。这可能涉及到将 Unicode 转义序列(如 \u4e2d\u6587)转换为实际的中文字符(如 中文)。你可以使用 Python 或其他编程语言的内置函数来实现这个功能。
-
制定格式输出到文件中
将还原后的中文字符串按照指定的格式输出到文件中,你可以使用 JSON、XML 或其他格式来存储这个映射。
通过以上步骤,你可以自动从 Mach-O 二进制文件中提取中文字符串,并将它们输出到语言包文件中。这将大大简化本地化过程,提高工作效率。
以上流程的解决方案代码由 HiBox 中的GPT4.0 提供。
__ustring 中文字符串获取
问1:使用 otool 命令找到 _TEXT 中 __ustring 的数据
答1:
otool是一个用于显示Mach-O文件信息的命令行工具。要使用otool找到__TEXT段中__ustring部分的数据,您可以按照以下步骤操作:
首先,使用otool的-l选项列出Mach-O文件的所有段和节:
otool -l <Mach-O文件名>
这将显示Mach-O文件中的所有段和节的信息。找到_TEXT段中名为__ustring 的节。
记下__ustring节的addr(地址)和size(大小)。
使用otool的-s选项提取__ustring节的数据:
otool -s __TEXT __ustring <Mach-O文件名>
这将显示 __TEXT 段中__ustring节的原始数据。请注意,这些数据将以十六进制格式显示。
实践1:
✗ otool -s __TEXT __ustring HDTranslateModule_Example > ustring.txt
得到 ustring.txt 文件为:
HDTranslateModule_Example:
Contents of (__TEXT,__ustring) section
000000010000add6 f1 82 87 65 00 00 39 5f 97 7a c4 7e f6 4e 75 98
000000010000ade6 62 97 00 00 06 52 7b 7c 13 7f 58 5b 2f 66 f6 65
000000010000adf6 f4 95 00 96 3c 50 1a ff 25 00 64 00 0c ff 53 5f
000000010000ae06 4d 52 13 7f 58 5b f6 65 f4 95 1a ff 25 00 64 00
000000010000ae16 00 00 f4 66 b0 65 44 8d 28 8d 08 54 c4 89 1a ff
000000010000ae26 25 00 40 00 00 00 11 62 2f 66 0d 67 a1 52 68 56
000000010000ae36 70 65 6e 63 00 00 2c 7b 25 00 64 00 20 5f fe 56
000000010000ae46 47 72 0d 4e 26 7b 08 54 c4 89 03 83 0c ff f7 8b
000000010000ae56 ff 66 62 63 16 62 20 52 64 96 0e 54 cd 91 b0 65
000000010000ae66 0a 4e 20 4f 00 00 a2 8b 55 53 16 7f f7 53 1a ff
000000010000ae76 25 00 40 00 00 00 2d 4e 87 65 00 00 11 62 5f 4e
000000010000ae86 2f 66 0d 67 a1 52 68 56 70 65 6e 63 00 00
直接使用
# -X print no leading addresses or headers
✗ otool -X -s __TEXT __ustring HDTranslateModule_Example > ustring.txt
最终数据为:
000000010000add6 f1 82 87 65 00 00 39 5f 97 7a c4 7e f6 4e 75 98
000000010000ade6 62 97 00 00 06 52 7b 7c 13 7f 58 5b 2f 66 f6 65
000000010000adf6 f4 95 00 96 3c 50 1a ff 25 00 64 00 0c ff 53 5f
000000010000ae06 4d 52 13 7f 58 5b f6 65 f4 95 1a ff 25 00 64 00
000000010000ae16 00 00 f4 66 b0 65 44 8d 28 8d 08 54 c4 89 1a ff
000000010000ae26 25 00 40 00 00 00 11 62 2f 66 0d 67 a1 52 68 56
000000010000ae36 70 65 6e 63 00 00 2c 7b 25 00 64 00 20 5f fe 56
000000010000ae46 47 72 0d 4e 26 7b 08 54 c4 89 03 83 0c ff f7 8b
000000010000ae56 ff 66 62 63 16 62 20 52 64 96 0e 54 cd 91 b0 65
000000010000ae66 0a 4e 20 4f 00 00 a2 8b 55 53 16 7f f7 53 1a ff
000000010000ae76 25 00 40 00 00 00 2d 4e 87 65 00 00 11 62 5f 4e
000000010000ae86 2f 66 0d 67 a1 52 68 56 70 65 6e 63 00 00
问2:
得到的数据为:
“”"
000000010000add6 f1 82 87 65 00 00 39 5f 97 7a c4 7e f6 4e 75 98
000000010000ade6 62 97 00 00 06 52 7b 7c 13 7f 58 5b 2f 66 f6 65
000000010000adf6 f4 95 00 96 3c 50 1a ff 25 00 64 00 0c ff 53 5f
000000010000ae06 4d 52 13 7f 58 5b f6 65 f4 95 1a ff 25 00 64 00
000000010000ae16 00 00 f4 66 b0 65 44 8d 28 8d 08 54 c4 89 1a ff
000000010000ae26 25 00 40 00 00 00 11 62 2f 66 0d 67 a1 52 68 56
000000010000ae36 70 65 6e 63 00 00 2c 7b 25 00 64 00 20 5f fe 56
000000010000ae46 47 72 0d 4e 26 7b 08 54 c4 89 03 83 0c ff f7 8b
000000010000ae56 ff 66 62 63 16 62 20 52 64 96 0e 54 cd 91 b0 65
000000010000ae66 0a 4e 20 4f 00 00 a2 8b 55 53 16 7f f7 53 1a ff
000000010000ae76 25 00 40 00 00 00 2d 4e 87 65 00 00 11 62 5f 4e
000000010000ae86 2f 66 0d 67 a1 52 68 56 70 65 6e 63 00 00
“”"
如何将这个数据解析成中文字符串
答2:
了解您的需求。在这种情况下,我们可以修改脚本,以便它可以从otool输出的数据中提取十六进制字符串。以下是一个修改后的Python脚本,用于将otool输出的十六进制数据转换为字符串:
import sys
import re
def otool_hex_to_str(otool_output):
# 提取十六进制数据
hex_data = re.findall(r'\t([0-9a-fA-F ]+)', otool_output)
# 将十六进制数据连接成一个字符串
hex_str = ''.join(hex_data).replace(' ', '')
# 将十六进制数据转换为字节串
byte_data = bytes.fromhex(hex_str)
# 尝试以UTF-16编码解码字节串
decoded_str = byte_data.decode('utf-16', errors='ignore')
return decoded_str
if __name__ == '__main__':
if len(sys.argv) != 2:
print("用法: python otool_hex_to_str.py <otool输出>")
else:
print(otool_hex_to_str(sys.argv[1]))
将此代码保存为otool_hex_to_str.py,然后在命令行中运行:
python otool_hex_to_str.py "000000010000add6 f1 82 87 65 00 00 39 5f 97 7a c4 7e f6 4e 75 98
000000010000ade6 62 97 00 00 06 52 7b 7c 13 7f 58 5b 2f 66 f6 65
000000010000adf6 f4 95 00 96 3c 50 1a ff 25 00 64 00 0c ff 53 5f
000000010000ae06 4d 52 13 7f 58 5b f6 65 f4 95 1a ff 25 00 64 00
000000010000ae16 00 00 f4 66 b0 65 44 8d 28 8d 08 54 c4 89 1a ff
000000010000ae26 25 00 40 00 00 00 11 62 2f 66 0d 67 a1 52 68 56
000000010000ae36 70 65 6e 63 00 00 2c 7b 25 00 64 00 20 5f fe 56
000000010000ae46 47 72 0d 4e 26 7b 08 54 c4 89 03 83 0c ff f7 8b
000000010000ae56 ff 66 62 63 16 62 20 52 64 96 0e 54 cd 91 b0 65
000000010000ae66 0a 4e 20 4f 00 00 a2 8b 55 53 16 7f f7 53 1a ff
000000010000ae76 25 00 40 00 00 00 2d 4e 87 65 00 00 11 62 5f 4e
000000010000ae86 2f 66 0d 67 a1 52 68 56 70 65 6e 63 00 00 "
实践2:
得到的数据为
英文弹窗组件页面分类缓存是时间阀值:%d,当前缓存时间:%d更新资质合规:%@我是服务器数据第%d张图片不符合规范,请替换或删除后重新上传订单编号:%@中文我也是服务器数据
虽然能正常将十六进制转成中文,但是所有的中文字符串都集合成一个字符串,显然也不符合我们的诉求。
问3:
使用你的代码输出的结果为:
“”“英文弹窗组件页面分类缓存是时间阀值:%d,当前缓存时间:%d更新资质合规:%@我是服务器数据第%d张图片不符合规范,请替换或删除后重新上传订单编号:%@中文我也是服务器数据”“”
这里只是一个字符串,但是实际上应该有多个中文字符串
答3:
非常抱歉,我之前的理解有误。现在我明白您的需求是将原始的6个字符串分别打印出来。以下是修改后的脚本:
import sys
import re
def otool_hex_to_str(otool_output):
# 提取十六进制数据
hex_data = re.findall(r'\t([0-9a-fA-F ]+)', otool_output)
# 将十六进制数据连接成一个字符串
hex_str = ''.join(hex_data).replace(' ', '')
# 将十六进制数据转换为字节串
byte_data = bytes.fromhex(hex_str)
# 尝试以UTF-16编码解码字节串
decoded_str = byte_data.decode('utf-16', errors='ignore')
# 使用正则表达式匹配所有非空字符
all_strings = re.findall(r'[^\x00]+', decoded_str)
return all_strings
if __name__ == '__main__':
if len(sys.argv) != 2:
print("用法: python otool_hex_to_str.py <otool输出>")
else:
all_strings = otool_hex_to_str(sys.argv[1])
for s in all_strings:
print(s)
将此代码保存为otool_hex_to_str.py,然后在命令行中运行:
python otool_hex_to_str.py "000000010000add6 f1 82 87 65 00 00 39 5f 97 7a c4 7e f6 4e 75 98
000000010000ade6 62 97 00 00 06 52 7b 7c 13 7f 58 5b 2f 66 f6 65
000000010000adf6 f4 95 00 96 3c 50 1a ff 25 00 64 00 0c ff 53 5f
000000010000ae06 4d 52 13 7f 58 5b f6 65 f4 95 1a ff 25 00 64 00
000000010000ae16 00 00 f4 66 b0 65 44 8d 28 8d 08 54 c4 89 1a ff
000000010000ae26 25 00 40 00 00 00 11 62 2f 66 0d 67 a1 52 68 56
000000010000ae36 70 65 6e 63 00 00 2c 7b 25 00 64 00 20 5f fe 56
000000010000ae46 47 72 0d 4e 26 7b 08 54 c4 89 03 83 0c ff f7 8b
000000010000ae56 ff 66 62 63 16 62 20 52 64 96 0e 54 cd 91 b0 65
000000010000ae66 0a 4e 20 4f 00 00 a2 8b 55 53 16 7f f7 53 1a ff
000000010000ae76 25 00 40 00 00 00 2d 4e 87 65 00 00 11 62 5f 4e
000000010000ae86 2f 66 0d 67 a1 52 68 56 70 65 6e 63 00 00"
这将按照原始顺序分别打印出多个字符串。希望这次的解决方案能满足您的需求。如果您有任何问题,请随时告诉我。
实践3:
使用最新的代码输出为:
英文
弹窗组件页面
分类缓存是时间阀值:%d,当前缓存时间:%d
更新资质合规:%@
我是服务器数据
第%d张图片不符合规范,请替换或删除后重新上传
订单编号:%@
中文
我也是服务器数据
已经是符合预期的答案了
问4:
请将最终打印的数据,以json数组的形式写入translate.txt中
答4:
以下是修改后的脚本,可以将otool输出的十六进制数据转换为多个字符串,并将它们作为JSON数组写入translate.txt文件:
import sys
import re
import json
def otool_hex_to_str(otool_output):
# 提取十六进制数据
hex_data = re.findall(r'\t([0-9a-fA-F ]+)', otool_output)
# 将十六进制数据连接成一个字符串
hex_str = ''.join(hex_data).replace(' ', '')
# 将十六进制数据转换为字节串
byte_data = bytes.fromhex(hex_str)
# 尝试以UTF-16编码解码字节串
decoded_str = byte_data.decode('utf-16', errors='ignore')
# 使用正则表达式匹配所有非空字符
all_strings = re.findall(r'[^\x00]+', decoded_str)
return all_strings
if __name__ == '__main__':
with open('ustring.txt', 'r') as f:
otool_output = f.read()
all_strings = otool_hex_to_str(otool_output)
with open('translate.txt', 'w', encoding='utf-8') as f:
json.dump(all_strings, f, ensure_ascii=False, indent=4)
print("已将字符串以JSON数组形式写入translate.txt文件")
将此代码保存为otool_hex_to_str.py,然后确保ustring.txt文件包含以下内容:
000000010000add6 f1 82 87 65 00 00 39 5f 97 7a c4 7e f6 4e 75 98
000000010000ade6 62 97 00 00 06 52 7b 7c 13 7f 58 5b 2f 66 f6 65
000000010000adf6 f4 95 00 96 3c 50 1a ff 25 00 64 00 0c ff 53 5f
000000010000ae06 4d 52 13 7f 58 5b f6 65 f4 95 1a ff 25 00 64 00
000000010000ae16 00 00 f4 66 b0 65 44 8d 28 8d 08 54 c4 89 1a ff
000000010000ae26 25 00 40 00 00 00 11 62 2f 66 0d 67 a1 52 68 56
000000010000ae36 70 65 6e 63 00 00 2c 7b 25 00 64 00 20 5f fe 56
000000010000ae46 47 72 0d 4e 26 7b 08 54 c4 89 03 83 0c ff f7 8b
000000010000ae56 ff 66 62 63 16 62 20 52 64 96 0e 54 cd 91 b0 65
000000010000ae66 0a 4e 20 4f 00 00 a2 8b 55 53 16 7f f7 53 1a ff
000000010000ae76 25 00 40 00 00 00 2d 4e 87 65 00 00 11 62 5f 4e
000000010000ae86 2f 66 0d 67 a1 52 68 56 70 65 6e 63 00 00
在命令行中运行python otool_hex_to_str.py,它将从ustring.txt文件中读取数据并将结果作为JSON数组写入translate.txt文件。希望这次的解决方案能满足您的需求。如果您有任何问题,请随时告诉我。
__cstring 中文字符串获取
问1:
使用 otool 命令找到 _TEXT 中 __cstring 的数据
答1:
要使用otool命令找到__TEXT段中的__cstring数据,请在命令行中运行以下命令:
otool -V -X -s __TEXT __cstring HDTranslateModule_Example
这里的 HDTranslateModule_Example 是您要分析的可执行文件的名称。请确保将其替换为您实际要分析的文件名。
这个命令的解释如下:
otool: macOS上的一个命令行工具,用于显示Mach-O文件(macOS可执行文件格式)的信息。
-V: 以详细模式显示输出。
-X: 以十六进制格式显示输出。
-s __TEXT __cstring: 提取__TEXT段中的__cstring部分。
HDTranslateModule: 要分析的可执行文件的名称。
运行此命令后,您将在命令行中看到__TEXT段中__cstring部分的数据。如果您希望将输出保存到文件中,可以将输出重定向到文件,如下所示:
otool -V -X -s __TEXT __cstring HDTranslateModule_Example > cstring.txt
这将把输出保存到名为cstring.txt的文件中。
实践1:
执行上面的命令后,得到的 cstring.txt 数据如下:
systemlanguage: %@
v16@?0q8
UITableViewCell
UILabelCell
UIButtonCell
UIButtonCell2
UITextViewCell
UITextViewCell2
UITextFieldCell
UITextFieldCell2
UILable.text Case
UILable.attributedText Case
UIButton.setTitle Case
UIButton.setAttributedTitle Case
UITextView.text Case
UITextView.attributedText Case
UITextField.text Case
UITextField.attributedText Case
v32@?0@"UITabBarItem"8Q16^B24
UILable.text
%d
%@
UILable.attributedText
UIButton.setTitle
UIButton.setAttributedTitle
UITextView.text
UITextView.attributedText
UITextField.text
UITextField.attributedText
hello
Swift \37777777744\37777777670\37777777655
Swift En
\37777777746\37777777630\37777777657\37777777744\37777777670\37777777672 \37777777744\37777777670\37777777655
Hello
\37777777744\37777777675\37777777640\37777777745\37777777645\37777777675
Hello \37777777744\37777777675\37777777640\37777777745\37777777645\37777777675
_TtC25HDTranslateModule_Example9HDExample
v16@0:8
@16@0:8
value
\n
__TEXT
swift_getObjCClassMetadata
_TtCs12_SwiftObject
swift_getTypeContextDescriptor
swift_getExistentialTypeMetadata
objc_addLoadImageFunc
__swift5_proto
通过源码和输出产物对比,可以大胆猜测 \37777777 前缀的字符串为中文字符串,那么接下来的目标就是将其转成中文字符串。
问2:
cstring.txt 部分数据如下:
“”"
Swift \37777777744\37777777670\37777777655
Swift En
\37777777746\37777777630\37777777657\37777777744\37777777670\37777777672 \37777777744\37777777670\37777777655
“”"
上面一些乱码字符,可能是编码错误或者其他原因导致的。应该是一种 特殊的编码方式,你可以帮忙转成中文吗?
我们先从 “”" \37777777744\37777777670\37777777655 “”" 开始。
答2:
这些乱码字符可能是八进制的 Unicode 编码。我可以尝试将它们转换为中文:
原始字符串:\37777777744\37777777670\37777777655
转换为八进制:344 270 255
将八进制转换为 Unicode 字符:
344 -> Ą
270 -> Ű
255 -> ÿ
经过转换,我们得到的字符串是 "ĄŰÿ"。看起来这并不是中文字符。这可能是因为原始数据编码有误,或者这些字符本身就不是中文。
结论显然是不符合预期,只能接着问。
问3:
这些字符串看着八进制的,你先转成16进制,然后想办法转成中文试试看
答3:
首先,将八进制转换为十六进制:
八进制:37777777744 37777777670 37777777655
十进制:4294967244 4294967192 4294967175
十六进制:FFFFFFC4 FFFFFFD2 FFFFFFAD
接下来,尝试将十六进制转换为中文字符。由于这些十六进制数值超出了 Unicode 的范围,我们需要将它们转换为有效的 Unicode 编码。我们可以尝试将这些数值与有效 Unicode 范围内的数值进行按位与操作:
FFFFFFC4 & 0x10FFFF = C4
FFFFFFD2 & 0x10FFFF = D2
FFFFFFAD & 0x10FFFF = AD
将十六进制转换为 Unicode 字符:
C4 -> Ä
D2 -> Ò
AD -> 173 (软连字符)
经过转换,我们得到的字符串是 "ÄÒ"。看起来这并不是中文字符。这可能是因为原始数据编码有误,或者这些字符本身就不是中文。
这里 GPT4 犯了一个常见的错误,在进行进制转换的时候,会经常出现误差,这里在认真比较好,发现八进制转十六进制答案有误,只能接着问。
问4:
请检查8进制转16进制是否有误
答4:
抱歉刚刚的回答中,我在将八进制转换为十六进制时出现了错误。现在我将重新进行转换:
原始字符串:\37777777744\37777777670\37777777655
八进制:344 270 255
八进制:344 270 255
十六进制:E4 B8 AD
经过一次次确认,它给出了预期的结果,但是还是没有得到最终的中文字符串,只能接着再问。
问5:
请将如下字符串转译成中文: “”“E4 B8 AD”“”
答5:
def hex_to_chinese(hex_str):
hex_numbers = hex_str.split()
byte_array = bytearray()
for hex_number in hex_numbers:
byte_array.append(int(hex_number, 16))
return byte_array.decode('utf-8')
input_str = "E4 B8 AD"
result = hex_to_chinese(input_str)
print(result)
这段代码将输出:
中
终于能实现特殊编码转成中文的能力了。趁着上下文还在,继续往完整的方案实施。
问6:
现在我们一步步来解决问题:
首先你想办法从 “Swift \37777777744\37777777670\37777777655” 找到 “\37777777744\37777777670\37777777655”
然后将 “\37777777744\37777777670\37777777655” 作为八进制,转成 十六进制
最后调用 printChinese 方法得到中文。
答6:
import re
from urllib import parse
def octal_to_hex(octal_str):
decimal_num = int(octal_str, 8)
hex_num = hex(decimal_num)[2:]
return hex_num.zfill(2)
def printChinese(x):
y = x.encode('unicode_escape')
z = y.decode('utf-8').replace('\\x', '%')
un = parse.unquote(z)
return un
input_str = "Swift \37777777744\37777777670\37777777655"
# 1. 从 "Swift \37777777744\37777777670\37777777655" 找到 "\37777777744\37777777670\37777777655"
octal_str = re.findall(r'(\\[0-7]{3})+', input_str)[0]
# 2. 将 "\37777777744\37777777670\37777777655" 作为八进制,转成 十六进制
octal_list = re.findall(r'\\([0-7]{3})', octal_str)
hex_list = [octal_to_hex(octal_str) for octal_str in octal_list]
hex_str = ''.join(hex_list)
# 3. 调用 printChinese 方法得到中文
chinese_str = printChinese(hex_str)
# 替换原始字符串中的八进制编码
output_str = input_str.replace(octal_str, chinese_str)
print(output_str)
# 这个脚本首先从输入字符串中找到八进制编码,然后将其转换为十六进制编码,最后调用 printChinese 函数将十六进制编码转换为中文字符。运行此代码后,将输出 "Swift 中"。
现在的脚本也能完成从 一行混合中字符串中,通过特定的规则找到编码前的中文字符串,然后通过之前的步骤替换然后输出完整的一行带有中文的字符串:Swift 中。但是还是不够,因为还存在其他场景没有考虑清楚,接着问。
问7:
这个字符串是有空格的,但是用上面的脚本执行,空格消失了,请提供新的兼容代码
“”"
\37777777746\37777777630\37777777657\37777777744\37777777670\37777777672 \37777777744\37777777670\37777777655
“”"
(备注 \37777777672 和 \37777777744 中间有一个空格)
答7:
import re
def octal_to_hex(octal_str):
decimal_num = int(octal_str, 8)
hex_num = hex(decimal_num)[2:]
return hex_num.zfill(2)
def convert_octal_to_hex(input_str):
octal_numbers = re.findall(r'\\37777777\d{3}', input_str)
for octal_number in octal_numbers:
octal_number = octal_number[1:] # 去掉开头的反斜杠
hex_number = octal_to_hex(octal_number)
hex_str = "\\x" + hex_number
input_str = input_str.replace("\\" + octal_number, hex_str)
return input_str
input_str = "\37777777746\37777777630\37777777657\37777777744\37777777670\37777777672 \37777777744\37777777670\37777777655"
output_str = convert_octal_to_hex(input_str)
print("output_str:", output_str)
这个代码会将原始数据中的八进制数字转换为十六进制数字,并保留其中的空格。输出结果为:
output_str: \x7e\x18\x19\x7c\x1e\x1e \x7c\x1e\x1d
问8:
请将最后输出的中文写入到 cstring_output.json 文件中,并且以 json 数组的方式。
答8:
以下是修改后的代码,将输出的中文写入到 cstring_output.json 文件中,并以 JSON 数组的方式存储:
import re
from urllib import parse
import json
def octal_to_hex(octal_number):
# 八进制转成十进制数据
decimal_number = int(octal_number, 8)
# Unicode 字符串按位运算
valide_number = decimal_number & 0xFF
# 转成可用的十六进制数据
hex_number = f"{valide_number:02x}"
return hex_number
def hex_to_chinese(x):
y = x.encode('unicode_escape')
z = y.decode('utf-8').replace('\\x', '%')
# 兼容多余的 \\ 符号
z = z.replace('\\', '')
un = parse.unquote(z)
return un
def convert_octal_to_hex(input_str):
octal_numbers = re.findall(r'\\37777777\d{3}', input_str)
for octal_number in octal_numbers:
octal_number = octal_number[1:] # 去掉开头的反斜杠
hex_number = octal_to_hex(octal_number)
hex_str = "\\" + hex_number
input_str = input_str.replace("\\" + octal_number, hex_str)
return input_str
def dispose_line(input_str):
start_index = input_str.find(r"\37777777")
if start_index < 0:
return None
octal_str = input_str[start_index:]
output_str = convert_octal_to_hex(input_str)
return hex_to_chinese(output_str)
print("start")
file_path = 'cstring.txt'
output_file_path = 'cstring_output.json'
output_data = []
with open(file_path, 'r') as f:
for line in f:
line = line.strip() # 去掉换行符
value = dispose_line(line)
if value:
output_data.append(value)
with open(output_file_path, 'w', encoding='utf-8') as f:
json.dump(output_data, f, ensure_ascii=False, indent=4)
print("end")
这段代码将读取 cstring.txt 文件中的每一行,并使用 dispose_line 函数处理每一行。处理后的中文字符串将添加到 output_data 列表中。最后,将 output_data 列表以 JSON 数组的形式写入到 cstring_output.json 文件中。
总结: 本文通过几个问题和答案的形式,简要介绍了如何利用 GPT 的广泛知识面来解决跨领域问题。虽然这些步骤已经过简化,但实际操作过程中可能会遇到更多挑战。GPT 能够在给定适当提示和引导的情况下,迅速提供实际方法。然而,这些方法可能并不完善,因此在实际应用中,开发者仍需进行多次实践和验证,以确保解决方案的有效性。
2、文案翻译
问1:
使用python代码,调用google的接口将中文翻译成英文
答1:
# 要使用Python调用Google翻译接口,您可以使用googletrans库。首先,确保您已经安装了这个库。在命令行中运行以下命令进行安装:
pip install googletrans==4.0.0-rc1
# 然后,使用以下代码将中文翻译成英文:
from googletrans import Translator
def translate_text(text, src_lang='zh-CN', dest_lang='en'):
translator = Translator(service_urls=['translate.google.com'])
result = translator.translate(text, src=src_lang, dest=dest_lang)
return result.text
if __name__ == "__main__":
chinese_text = "你好,世界!"
english_text = translate_text(chinese_text)
print(english_text)
# 这段代码首先导入Translator类,然后定义一个translate_text函数,该函数接受要翻译的文本、源语言和目标语言作为参数。在__main__部分,我们将一段中文文本传递给translate_text函数,并打印翻译后的英文文本。
这里的方案是可行,但是因为是第三方对google翻译接口进行封装,导致有使用次数的限制。
问2:
申请 api_key 然后使用python代码调用 翻译接口
答2:
# 根据您提供的错误信息,您可能在使用google-cloud-translate库。为了解决这个问题,请按照以下步骤操作:
# 首先,确保您已经安装了google-cloud-translate库。在命令行中运行以下命令进行安装:
pip install google-cloud-translate
# 设置环境变量GOOGLE_APPLICATION_CREDENTIALS,指向包含您的API密钥的JSON文件。在命令行中运行以下命令(替换/path/to/your/credentials.json为实际路径):
export GOOGLE_APPLICATION_CREDENTIALS="/path/to/your/credentials.json"
# 为了减少每次都需要执行上面的命令,可以在 .bash_profile 文件中添加即可
# 使用以下代码将中文翻译成英文:
from google.cloud import translate_v2 as translate
def translate_text(text, src_lang='zh-CN', dest_lang='en'):
translate_client = translate.Client()
result = translate_client.translate(text, target_language=dest_lang, source_language=src_lang)
return result['translatedText']
if __name__ == "__main__":
chinese_text = "你好,世界!"
english_text = translate_text(chinese_text)
print(english_text)
# 这段代码首先导入translate_v2模块,然后定义一个translate_text函数,该函数接受要翻译的文本、源语言和目标语言作为参数。在__main__部分,我们将一段中文文本传递给translate_text函数,并打印翻译后的英文文本。
# 请注意,您不再需要在translate.Client()中提供api_key参数。相反,库将从环境变量GOOGLE_APPLICATION_CREDENTIALS中读取API密钥。
这里不推荐使用api_key的方法,需要从配置文件来获取相关 api_key 等数据。
问3:
GOOGLE_APPLICATION_CREDENTIALS 文件内容,可以举例说明下吗?怎么获取它?
答3:
# GOOGLE_APPLICATION_CREDENTIALS文件是一个包含Google Cloud服务帐户密钥的JSON文件。这个文件通常由Google Cloud Console生成,用于对您的应用程序进行身份验证。文件内容包括项目ID、私钥、客户端ID等信息。
# 以下是一个示例GOOGLE_APPLICATION_CREDENTIALS文件的内容:
{
"type": "service_account",
"project_id": "your_project_id",
"private_key_id": "your_private_key_id",
"private_key": "-----BEGIN PRIVATE KEY-----\nYOUR_PRIVATE_KEY\n-----END PRIVATE KEY-----\n",
"client_email": "your_service_account_email",
"client_id": "your_client_id",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/your_service_account_email"
}
# 请注意,您需要使用您自己的项目ID、私钥ID、私钥、服务帐户电子邮件和客户端ID替换示例中的占位符。
# 要生成这个文件,请按照以下步骤操作:
访问Google Cloud Console:https://console.cloud.google.com/。
选择您的项目。
在左侧菜单中,点击"IAM & Admin",然后点击"Service Accounts"。
点击"创建服务帐户",输入服务帐户的详细信息,然后点击"创建"。
在"授予此服务帐户访问权限"部分,选择适当的角色(例如,对于翻译API,您可以选择"Cloud Translation API Editor"角色),然后点击"继续"。
在"授予用户访问权限"部分,您可以选择向其他用户授予访问权限,或者跳过这一步。
点击"完成"以创建服务帐户。
返回服务帐户列表,找到您刚刚创建的服务帐户,然后点击右侧的"操作"列中的铅笔图标。
在"密钥"选项卡下,点击"添加密钥",然后选择"JSON"。
JSON密钥文件将自动下载到您的计算机。这就是您需要设置为GOOGLE_APPLICATION_CREDENTIALS环境变量的文件。
设置环境变量后,您的应用程序将能够使用这个文件中的凭据访问Google Cloud服务。
教程非常详细简单,但是需要提前预备好 支持外汇信用卡。对于 python 小白来说,如何实现并发调用翻译API有点难度,只好继续求助。
问4:
translate_text 翻译串行太慢,可以支持并发吗,请提供相关代码
答4:
# 可以使用Python的concurrent.futures库实现并发翻译。以下是一个使用ThreadPoolExecutor实现并发翻译的示例:
import concurrent.futures
from google.cloud import translate_v2 as translate
def translate_text(text, src_lang='zh-CN', dest_lang='en'):
translate_client = translate.Client()
result = translate_client.translate(text, target_language=dest_lang, source_language=src_lang)
return result['translatedText']
def translate_concurrently(text_list, src_lang='zh-CN', dest_lang='en', max_workers=5):
with concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_text = {executor.submit(translate_text, text, src_lang, dest_lang): text for text in text_list}
translated_texts = []
for future in concurrent.futures.as_completed(future_to_text):
translated_texts.append(future.result())
return translated_texts
if __name__ == "__main__":
chinese_texts = ["你好,世界!", "我喜欢编程", "Python是一门很好的编程语言"]
translated_texts = translate_concurrently(chinese_texts)
print(translated_texts)
# 在这个示例中,我们定义了一个新的函数translate_concurrently,它接受一个文本列表、源语言、目标语言和最大工作线程数作为参数。这个函数使用ThreadPoolExecutor并发地调用translate_text函数,并将翻译后的文本添加到translated_texts列表中。
# 在__main__部分,我们创建了一个包含多个中文文本的列表,并调用translate_concurrently函数进行并发翻译。最后,我们打印翻译后的英文文本列表。
# 请注意,由于翻译API可能有请求限制,过高的并发量可能导致请求被拒绝。您可以根据需要调整max_workers参数以控制并发量。
翻译过程中,会将字符串本身包含的的 \n 符号转译了,导致在实现国际化出现了问题。
问5:
中文包含 \n 换行符号,导致翻译的时候转译了,如何解决
答5:
# 在您提供的代码中,您使用了repr()函数来获取all_strings[index]和all_translate_strings[index]的可打印表示。这将确保\n不被转义。但是,repr()函数还会在字符串的开头和结尾添加额外的单引号。为了避免这个问题,您可以在format()函数中使用切片操作来去掉这些额外的单引号。
以下是修改后的write_final_ustring_local_file函数:
def write_final_ustring_local_file(file_final_path, all_strings, all_translate_strings):
with open(file_final_path, 'w', encoding='utf-8') as f:
for index in range(len(all_strings)):
# 使用原始字符串表示法,repr(),以便在all_translate_strings中的\n不被转义
f.write(r'"{}" = "{}";'.format(
repr(all_strings[index])[1:-1], repr(all_translate_strings[index])[1:-1]) + '\n')
在这个修改后的版本中,我们使用切片操作[1:-1]来去掉repr()函数添加的额外单引号。这样,您将获得一个包含未转义的\n的字符串,而不会有额外的单引号。
def write_final_ustring_local_file(file_final_path, all_strings, all_translate_strings):
with open(file_final_path, 'w', encoding='utf-8') as f:
for index in range(len(all_strings)):
# 使用原始字符串表示法,repr(),以便在all_translate_strings中的\n不被转义
f.write(r'"{}" = "{}";'.format(
repr(all_strings[index])[1:-1], repr(all_translate_strings[index])[1:-1]) + '\n')
3、最佳实践
在前面的文案收集和文案翻译自动化基础上,我提供了一个完整的自动化收集翻译脚本及代码注释。以下是脚本的详细内容及使用说明
3.1、处理 __ustring 节数据
__ustring 节是用于存储 Unicode 字符串的数据段。为了实现中文字符串的查找、收集和翻译自动化,我们可以编写一个名为 find_chinese_ustrings.py 的脚本。以下是一个完整的实现示例:
import re
import sys
from urllib import parse
import json
import os
from google.cloud import translate_v2 as translate
from concurrent.futures import ThreadPoolExecutor
# 已经翻译好的个数
completed_translations = 0
# 总的需要翻译的个数
translations = 0
# 使用google进行私钥翻译:pip install google-cloud-translate
def translate_text(text, src_lang='zh-CN', dest_lang='en'):
translate_client = translate.Client()
result = translate_client.translate(
text, target_language=dest_lang, source_language=src_lang)
return result['translatedText']
# 翻译指令
def translate_worker(value):
if adjustChinese(value):
translated_text = translate_text(value)
if translated_text:
# 使用global关键字指示我们要使用和修改全局变量
global completed_translations
global translations
completed_translations += 1
# print(value+"翻译成功")
print("翻译进度:", completed_translations, "/", translations)
return (value, translated_text)
else:
print(value+"翻译失败")
return None
# 八进制转成十六进制
def octal_to_hex(octal_number):
# 八进制转成十进制数据
decimal_number = int(octal_number, 8)
# Unicode 字符串按位运算
valide_number = decimal_number & 0xFF
# 转成可用的十六进制数据
hex_number = hex(valide_number)[1:]
return hex_number
# 十六进制转成中文
def hex_to_chinese(x):
y = x.encode('unicode_escape')
z = y.decode('utf-8').replace('\\x', '%')
# 兼容多余的 \\ 符号
z = z.replace('\\', '')
un = parse.unquote(z)
return un
# 处理一行数据,找到中文的特殊字符,转成中文
def convert_octal_to_hex(input_str):
octal_numbers = re.findall(r'\\37777777\d{3}', input_str)
# print(octal_numbers)
for octal_number in octal_numbers:
octal_number = octal_number[1:] # 去掉开头的反斜杠
# print("octal_number", octal_number)
# 八进制转成十进制数据,并且转成可用的十六进制数据
hex_number = octal_to_hex(octal_number)
hex_str = "\\" + hex_number
# 这里是做替换操作,避免丢失空格
input_str = input_str.replace("\\" + octal_number, hex_str)
return input_str
# 处理一行数据,找到中文的特殊字符,转成中文
def dispose_line(input_str):
# 1. 从 "Swift \37777777744\37777777670\37777777655" 找到 "\37777777744\37777777670\37777777655"
start_index = input_str.find(r"\37777777")
if start_index < 0:
return None
octal_str = input_str[start_index:]
# print("octal_str", octal_str)
# 2. 将 "\37777777744\37777777670\37777777655" 作为八进制,转成 十六进制
output_str = convert_octal_to_hex(input_str)
# print("output_str", output_str)
return hex_to_chinese(output_str)
# 判断value是否是中文
def adjustChinese(value):
if value:
if len(value) > 0:
for s in value:
if u'\u4e00' <= s <= u'\u9fff':
return True
return False
# 使用otool命令,将二进制文件中的__cstring段落,导出到文件中
def otool_to_file(macho_file, cstring_file):
os.system(
f"otool -V -X -s __TEXT __cstring {macho_file} > {cstring_file}")
# 从文件中读取数据,进行翻译
def translate_cstring(cstring_file):
all_strings = []
with open(cstring_file, 'r') as f:
for line in f:
# 去掉换行符
line = line.strip()
value = dispose_line(line)
if adjustChinese(value):
all_strings.append(value)
global translations
translations = len(all_strings)
# 这个修改后的代码使用了ThreadPoolExecutor来实现多线程翻译。translate_worker函数是一个新的辅助函数,
# 它接受一个字符串并尝试翻译。otool_hex_to_str函数中的循环被替换为一个executor.map调用,
# 它将translate_worker应用于all_strings中的每个元素。这将并行执行翻译任务,从而加快速度。
with ThreadPoolExecutor() as executor:
results = list(executor.map(translate_worker, all_strings))
output_datas = []
output_translate_datas = []
for result in results:
if result is not None:
output_datas.append(result[0])
output_translate_datas.append(result[1])
return output_datas, output_translate_datas
# 将翻译好的数据,写入到文件中
def write_to_file(output_data, output_file_path):
with open(output_file_path, 'w', encoding='utf-8') as f:
json.dump(output_data, f, ensure_ascii=False, indent=2)
# 将翻译后的all_strings、all_translate_strings写入output_file、file_translate_path文件
def write_ustring_local_file(output_file, file_translate_path, all_strings, all_translate_strings):
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(all_strings, f, ensure_ascii=False, indent=2)
with open(file_translate_path, 'w', encoding='utf-8') as f:
json.dump(all_translate_strings, f, ensure_ascii=False, indent=2)
# 将all_strings、all_translate_strings 以 "中文"="English" 的形式写入file_final_path.json文件
def write_final_ustring_local_file(file_final_path, all_strings, all_translate_strings):
with open(file_final_path, 'w', encoding='utf-8') as f:
for index in range(len(all_strings)):
# 使用原始字符串表示法,repr(),以便在all_translate_strings中的\n不被转义
# 使用了repr()函数来获取all_strings[index]和all_translate_strings[index]的可打印表示。
# 这将确保\n不被转义。但是,repr()函数还会在字符串的开头和结尾添加额外的单引号。
# 为了避免这个问题,您可以在format()函数中使用切片操作来去掉这些额外的单引号。
f.write(r'"{}" = "{}";'.format(
repr(all_strings[index])[1:-1], repr(all_translate_strings[index])[1:-1]) + '\n')
# 读取file_path、file_translate_path文件,并将其json数组以 如下格式写入ustring_output.json文件
def read_ustring_local_file(file_path, file_translate_path):
with open(file_path, 'r', encoding='utf-8') as f:
file_path_data = json.load(f)
with open(file_translate_path, 'r', encoding='utf-8') as f:
file_translate_path_data = json.load(f)
return file_path_data, file_translate_path_data
# python3 find_chinese_cstrings.py HDFindStringDemo
if __name__ == '__main__':
print("start")
macho_file = sys.argv[1]
cstring_file = f"{macho_file}_cstring.txt"
output_file = f"{macho_file}_cstring_output.json"
file_translate_path = f"{macho_file}_cstring_output_translate.json"
file_final_path = f"{macho_file}_cstring_output_final.json"
########## 翻译+读写全流程 ##########
# 翻译+读写全流程 1. 使用otool命令,将二进制文件中的__cstring段落,导出到文件中
otool_to_file(macho_file, cstring_file)
# 翻译+读写全流程 2. 从文件中读取数据,转成中文后,再进行翻译
all_strings, all_translate_strings = translate_cstring(cstring_file)
# 翻译+读写全流程 3. 将翻译好的数据,写入到文件中
write_ustring_local_file(
output_file, file_translate_path, all_strings, all_translate_strings)
# # 翻译+读写全流程 4. 将all_strings、all_translate_strings 以 "中文"="English" 的形式写入file_final_path.json文件
write_final_ustring_local_file(
file_final_path, all_strings, all_translate_strings)
########## 翻译+读写全流程 ##########
### 因为在线调用google翻译api一定量会收费,所以当执行完【翻译+读写全流程】后,读取本地文件来生成想要的格式文件 ###
########## 本地文件读取翻译 ##########
# 本地文件读取翻译 1. 读取file_path、file_translate_path文件
# all_strings, all_translate_strings = read_ustring_local_file(
# output_file, file_translate_path)
# 本地文件读取 2. 将all_strings、all_translate_strings 以 "中文"="English" 的形式写入file_final_path.json文件
# write_final_ustring_local_file(
# file_final_path, all_strings, all_translate_strings)
########## 本地文件读取翻译 ##########
print("end")
使用说明: 请确保二进制文件 HDTranslateModule_Example 和脚本位于同一目录下,然后按照以下步骤操作:
- 打开命令行工具(如:终端、命令提示符等)。
- 使用
cd命令切换到包含二进制文件和脚本的目录。 - 执行相应的命令来运行脚本。
注意: 由于脚本需要实时调用 Google 翻译 API,请确保在执行脚本时能正常访问以下网址:https://cloud.google.com/docs/authentication/external/set-up-adc
在使用过程中,如果遇到任何问题或需要进一步的帮助,请随时提问,我会竭诚为你提供支持。
✗ ls
HDTranslateModule_Example find_chinese_cstrings.py find_chinese_ustrings.py
✗ python3 find_chinese_ustrings.py HDTranslateModule_Example
start
翻译进度: 1 / 9
翻译进度: 2 / 9
翻译进度: 3 / 9
翻译进度: 4 / 9
翻译进度: 5 / 9
翻译进度: 6 / 9
翻译进度: 7 / 9
翻译进度: 8 / 9
翻译进度: 9 / 9
end
✗ ls
HDTranslateModule_Example # 二进制文件
HDTranslateModule_Example_ustring.txt # otools得到的十六进制数据
HDTranslateModule_Example_ustring_output.json # 从ustring.txt中提炼出中文字符串,并输出成json数组
HDTranslateModule_Example_ustring_output_translate.json #从ustring_output.json翻译成英文
HDTranslateModule_Example_ustring_output_final.json #将ustring_output.json和ustring_output_final.json 按照iOS所需要的语言包格式输出成最终文件
find_chinese_cstrings.py # 处理 __cstring 节中的中文字符串的脚本
find_chinese_ustrings.py # 处理 __ustring 节中的中文字符串的脚本
# 最终的输出数据
✗ cat HDTranslateModule_Example_ustring_output_final.json
"英文" = "English";
"弹窗组件页面" = "Popup component page";
"分类缓存是时间阀值:%d,当前缓存时间:%d" = "Category cache is time threshold: %d, current cache time: %d";
"更新资质合规:%@" = "Update qualification compliance: %@";
"我是服务器数据" = "i am server data";
"第%d张图片不符合规范,请替换或删除后重新上传" = "The %d image does not meet the specifications, please replace or delete it and upload it again";
"订单编号:%@" = "Order number: %@";
"中文" = "Chinese";
"我也是服务器数据" = "I am also server data";
3.2、处理 __cstring 节数据
__cstring 节是用于存储 C 风格字符串的数据段。为了实现中文字符串的查找、收集和翻译自动化,我们可以编写一个名为 find_chinese_cstrings.py 的脚本。以下是一个简单的实现示例:
import sys
import re
import json
import os
from google.cloud import translate_v2 as translate
from concurrent.futures import ThreadPoolExecutor
completed_translations = 0
translations = 0
# 使用google进行私钥翻译:pip install google-cloud-translate
def translate_text(text, src_lang='zh-CN', dest_lang='en'):
translate_client = translate.Client()
result = translate_client.translate(
text, target_language=dest_lang, source_language=src_lang)
return result['translatedText']
# 翻译指令
def translate_worker(value):
if adjustChinese(value):
translated_text = translate_text(value)
if translated_text:
# 使用global关键字指示我们要使用和修改全局变量
global completed_translations
global translations
completed_translations += 1
# print(value+"翻译成功")
print("翻译进度:", completed_translations, "/", translations)
return (value, translated_text)
else:
print(value+"翻译失败")
return None
# 十六进制转成中文,并且中英文翻译
def otool_hex_to_str(otool_output):
# 提取十六进制数据
hex_data = re.findall(r'\t([0-9a-fA-F ]+)', otool_output)
# print("hex_data", hex_data)
# 将十六进制数据连接成一个字符串
hex_str = ''.join(hex_data).replace(' ', '')
# print("hex_str", hex_str)
# 将十六进制数据转换为字节串
byte_data = bytes.fromhex(hex_str)
# print("byte_data", byte_data)
# 尝试以UTF-16编码解码字节串
decoded_str = byte_data.decode('utf-16', errors='ignore')
# print("decoded_str", decoded_str)
# 使用正则表达式匹配所有非空字符
all_strings = re.findall(r'[^\x00]+', decoded_str)
# print("all_strings", all_strings)
# all_strings可能有非中文,请过滤掉
output_datas = []
output_translate_datas = []
total_texts = len(all_strings)
global translations
translations = len(all_strings)
# 这个修改后的代码使用了ThreadPoolExecutor来实现多线程翻译。translate_worker函数是一个新的辅助函数,
# 它接受一个字符串并尝试翻译。otool_hex_to_str函数中的循环被替换为一个executor.map调用,
# 它将translate_worker应用于all_strings中的每个元素。这将并行执行翻译任务,从而加快速度。
with ThreadPoolExecutor() as executor:
results = list(executor.map(translate_worker, all_strings))
for result in results:
if result is not None:
output_datas.append(result[0])
output_translate_datas.append(result[1])
return output_datas, output_translate_datas
# 判断是否包含中文
def adjustChinese(value):
if value:
if len(value) > 0:
for s in value:
if u'\u4e00' <= s <= u'\u9fff':
return True
return False
# 将otool命令输出的内容写入文件
def otool_to_file(macho_file, ustring_file):
# 将otool命令输出的内容写入文件
os.system(f"otool -X -s __TEXT __ustring {macho_file} > {ustring_file}")
# 读取ustring_file文件,并将其json数组,然后翻译,返回原始数据和翻译后数据
def read_ustring_file(ustring_file):
with open(ustring_file, 'r') as f:
otool_output = f.read()
return otool_hex_to_str(otool_output)
# 将翻译后的all_strings、all_translate_strings写入file_path、file_translate_path文件
def write_ustring_local_file(file_path, file_translate_path, all_strings, all_translate_strings):
with open(file_path, 'w', encoding='utf-8') as f:
json.dump(all_strings, f, ensure_ascii=False, indent=2)
with open(file_translate_path, 'w', encoding='utf-8') as f:
json.dump(all_translate_strings, f, ensure_ascii=False, indent=2)
# 读取file_path、file_translate_path文件,并将其json数组以 如下格式写入ustring_output.json文件
def read_ustring_local_file(file_path, file_translate_path):
with open(file_path, 'r', encoding='utf-8') as f:
file_path_data = json.load(f)
with open(file_translate_path, 'r', encoding='utf-8') as f:
file_translate_path_data = json.load(f)
return file_path_data, file_translate_path_data
# 将all_strings、all_translate_strings 以 "中文"="English" 的形式写入file_final_path.json文件
def write_final_ustring_local_file(file_final_path, all_strings, all_translate_strings):
with open(file_final_path, 'w', encoding='utf-8') as f:
for index in range(len(all_strings)):
# 使用原始字符串表示法,repr(),以便在all_translate_strings中的\n不被转义
# 使用了repr()函数来获取all_strings[index]和all_translate_strings[index]的可打印表示。
# 这将确保\n不被转义。但是,repr()函数还会在字符串的开头和结尾添加额外的单引号。
# 为了避免这个问题,您可以在format()函数中使用切片操作来去掉这些额外的单引号。
f.write(r'"{}" = "{}";'.format(
repr(all_strings[index])[1:-1], repr(all_translate_strings[index])[1:-1]) + '\n')
# python3 find_chinese_utrings.py HDFindStringDemo
if __name__ == '__main__':
print("start")
macho_file = sys.argv[1]
ustring_file = f"{macho_file}_ustring.txt"
output_file = f"{macho_file}_ustring_output.json"
file_translate_path = f"{macho_file}_ustring_output_translate.json"
file_final_path = f"{macho_file}_ustring_output_final.json"
########## 翻译+读写全流程 ##########
# 翻译+读写全流程step1:将otool命令输出的内容写入文件
otool_to_file(macho_file, ustring_file)
# 翻译+读写全流程step2:读取ustring_file文件,并将其json数组,然后翻译,返回原始数据和翻译后数据
all_strings, all_translate_strings = read_ustring_file(ustring_file)
# 翻译+读写全流程step3:将翻译后的all_strings、all_translate_strings写入output_file、file_translate_path文件
write_ustring_local_file(
output_file, file_translate_path, all_strings, all_translate_strings)
# 翻译+读写全流程step4:将all_strings、all_translate_strings 以 "中文"="English" 的形式写入file_final_path.json文件
write_final_ustring_local_file(
file_final_path, all_strings, all_translate_strings)
########## 翻译+读写全流程 ##########
### 因为在线调用google翻译api一定量会收费,所以当执行完【翻译+读写全流程】后,读取本地文件来生成想要的格式文件 ###
########## 本地文件读取翻译 ##########
# 本地文件读取step1 读取output_file、file_translate_path文件,并将其json数组以 如下格式写入ustring_output.json文件
# all_strings, all_translate_strings = read_ustring_local_file(
# output_file, file_translate_path)
# 本地文件读取step2:将all_strings、all_translate_strings 以 "中文"="English" 的形式写入file_final_path.json文件
# write_final_ustring_local_file(
# file_final_path, all_strings, all_translate_strings)
########## 本地文件读取翻译 ##########
print("end")
使用说明: 请确保二进制文件 HDTranslateModule_Example 和脚本位于同一目录下,然后按照以下步骤操作:
- 打开命令行工具(如:终端、命令提示符等)。
- 使用
cd命令切换到包含二进制文件和脚本的目录。 - 执行相应的命令来运行脚本。
注意: 由于脚本需要实时调用 Google 翻译 API,请确保在执行脚本时能正常访问以下网址:https://cloud.google.com/docs/authentication/external/set-up-adc
在使用过程中,如果遇到任何问题或需要进一步的帮助,请随时提问,我会竭诚为你提供支持。
✗ python3 find_chinese_cstrings.py HDTranslateModule_Example
start
翻译进度: 1 / 4
翻译进度: 2 / 4
翻译进度: 3 / 4
翻译进度: 4 / 4
end
✗ ls
HDTranslateModule_Example # 二进制文件
HDTranslateModule_Example_cstring.txt # otools得到的十六进制数据
HDTranslateModule_Example_cstring_output.json # 从cstring.txt中提炼出中文字符串,并输出成json数组
HDTranslateModule_Example_cstring_output_translate.json #从cstring_output.json翻译成英文
HDTranslateModule_Example_cstring_output_final.json #将cstring_output.json和cstring_output_final.json 按照iOS所需要的语言包格式输出成最终文件
find_chinese_cstrings.py # 处理 __cstring 节中的中文字符串的脚本
find_chinese_ustrings.py # 处理 __ustring 节中的中文字符串的脚本
# 最终的输出文件
✗ cat HDTranslateModule_Example_cstring_output_final.json
"Swift 中" = "in Swift";
"是为 中" = "is for the";
"你好" = "Hello";
"Hello 你好" = "hello hello";
恭喜你完成了第一部分的工作!在实践中需要任何帮助或建议,请随时向我提问讨论交流。
二、工程配置
本部分的工作相对常规且简单,网络上的相关资料也较为丰富。以下是一些建议的参考资料和大致的工作内容:
参考资料:
- 3分钟实现iOS语言本地化/国际化(图文详解):本文详细介绍了如何实现 iOS 项目的本地化和国际化。
- iOS开发 国际化/多语言适配:本文讨论了在进行国际化过程中可能遇到的一些问题及其解决方案。
工作内容:
- 项目支持国际化:为项目添加多语言支持,包括在项目设置中启用国际化选项以及创建对应的本地化文件。
- App 名称国际化:根据不同的语言环境,为 App 设置不同的显示名称。
- 启动页国际化:根据不同的语言环境,为 App 提供不同的启动页。
- Info 文件名称国际化:为 Info.plist 文件中的各项设置提供多语言支持。
- 字符串国际化:使用 NSLocalizedString 函数将代码中的字符串进行本地化处理,以适应不同的语言环境。
- 图片/资源国际化:为不同的语言环境提供相应的图片和资源文件。
- Storyboard/XIB 国际化:为 Storyboard 和 XIB 文件中的 UI 元素提供多语言支持。
通过以上步骤,您可以为您的 iOS 项目实现本地化和国际化,以适应全球不同地区的用户需求。
三、代码实现
HDTranslateModule 是一个用于实现多语言支持、语言切换以及翻译后文案处理的组件化库。以下是该库的主要特性,具体细节不再展开。
- 多语言支持:HDTranslateModule 支持多种语言,可以根据用户的需求和设备设置自动适应不同的语言环境。
- 语言切换:HDTranslateModule 提供了简单易用的 API,可以在运行时动态切换 App 的显示语言,无需重启应用。
- 翻译后文案处理:HDTranslateModule 可以处理翻译后的文案,确保在不同语言环境下,文案的显示效果和语义都能符合预期。
- 组件化:HDTranslateModule 将多语言支持、语言切换和翻译后文案处理等功能封装成了一个独立的组件,可以方便地集成到现有的 iOS 项目中。
- 易于扩展:HDTranslateModule 的设计允许开发者根据自己的需求轻松地添加新的语言支持和功能。
在使用过程中,如果遇到任何问题或需要进一步的帮助,请随时反馈。
#import <Foundation/Foundation.h>
typedef NS_ENUM(NSInteger, JDLTLanguageMode) {
JDLTLanguageSyetem = 0,
JDLTLanguageEN,
JDLTLanguageZH
};
NS_ASSUME_NONNULL_BEGIN
@interface JDLTTranslateManager : NSObject
+ (instancetype)shared;
/// 自定义设置本地语言包的资源路径
/// - Parameters:
/// - bundle: 语言包所在的bundle
/// - tableName: 语言包所在的bundle的文件名称
- (void)customTranslateBundle:(NSBundle *)bundle tableName:(NSString *)tableName;
// 获取用户在App内选中的语言,如果用户未选中默认是System,则使用系统语言
- (JDLTLanguageMode)selectedLanguage;
- (void)updateLanguage:(JDLTLanguageMode)mode;
// 获取用户在系统选中的语言
- (JDLTLanguageMode)systemSelectedLanguage;
// 根据selectedLanguage和systemSelectedLanguage最终使用到的语言,只能可能是EN和ZH
// 如果用户在App选择优先使用,否则使用系统语言
- (JDLTLanguageMode)realUsedLanguage;
// 将 text 翻译成对应的语言
+ (NSString *)translateText:(NSString *)text;
@end
1、手动实现
使用 Foundation 框架自带的 NSLocalizedString(key, comment) 宏根据 Key 获取对应的字符串,然后赋值给代码中的字符串。这种方法需要手动为每个需要国际化的字符串添加对应的 Key 和翻译。
2、半自动化实现
-
Hook 文本显示,统一替换
在前面收集了多语言包的基础上,通过 AOP(面向切面编程)来 Hook 常用文本显示的 API,然后自动使用国际化文案进行替换。这里收集了常用的文案显示控件:UILabel、UITextField、UITextView、UITabBarItem、UINavigationItem、UIViewController ,然后分别对显示文案的 API 进行 hook,具体实现参考 JDLTTranslateHook 类。
-
手动替换
- JDLTAttributedString:富文本支持,可以处理富文本中的国际化文案。
- Format 适应:参考 HDTranslateModule 中的 demo 代码,处理字符串格式化时的国际化问题。
- 文本对应控件的宽高适应:根据不同语言环境下的文案长度和显示效果,调整控件的宽高以适应国际化文案。
通过以上方法,可以实现 iOS 项目的国际化支持,使得 App 在不同语言环境下都能正常显示对应的文案。同时,半自动化实现可以减轻开发者的工作量,提高开发效率。
四、服务器
对于一个完整的项目来说,除了本地 hardcode 需要国际化外,服务器下发的数据也需要支持国际化。虽然服务器内部的多语言配置这里不展开,但我们可以讨论一下如何在 App 内或手机系统切换语言时,将当前选择的语言告知服务器,以便使用对应的语言化数据展示。
以下是一些建议:
- 在 API 请求中添加语言参数:为了让服务器知道客户端当前使用的语言,可以在每个 API 请求中添加一个表示当前语言的参数。例如,可以在请求的 URL 中添加一个
lang参数,或者在请求头中添加一个Accept-Language字段。这样,服务器就可以根据这个参数返回对应语言的数据。 - 在用户登录或注册时发送语言信息:如果你的应用需要用户登录或注册,可以在用户登录或注册时将当前使用的语言发送给服务器。服务器可以将这个信息保存在用户的账户信息中,以便在后续的请求中使用。
- 监听语言切换事件:当用户在 App 内或手机系统中切换语言时,可以监听这个事件,并将新的语言信息发送给服务器。这样,服务器就可以实时更新用户的语言设置,并在后续的请求中返回正确的语言数据。
- 缓存服务器下发的多语言数据:为了提高性能和减少网络请求,可以在客户端缓存服务器下发的多语言数据。当用户切换语言时,可以优先从缓存中获取对应的数据,如果缓存中没有,则向服务器请求。
- 处理服务器返回的多语言数据:在客户端,需要正确处理服务器返回的多语言数据。例如,可以使用类似于本地化字符串的方法来处理服务器返回的文本,以确保在不同语言环境下都能正常显示。
通过以上方法,可以实现服务器下发数据的国际化支持,使得 App 在不同语言环境下都能正常显示服务器返回的数据。同时,这些方法可以与本地的国际化实现相结合,提供一个完整的多语言支持方案。
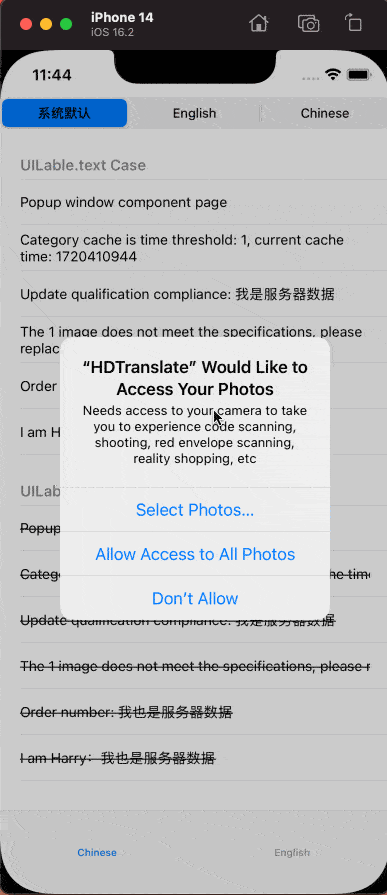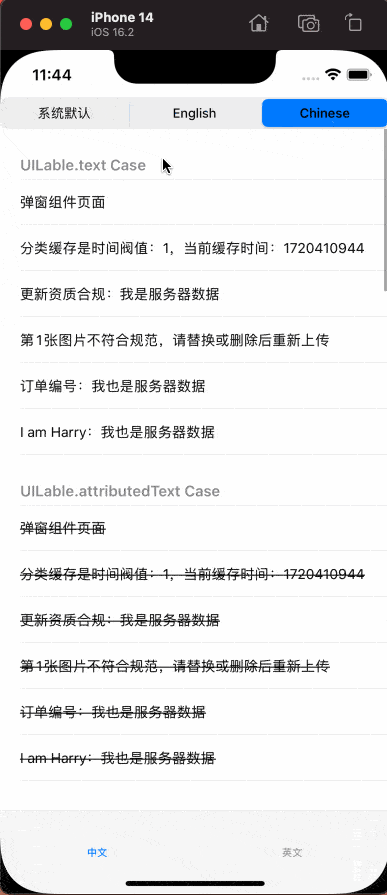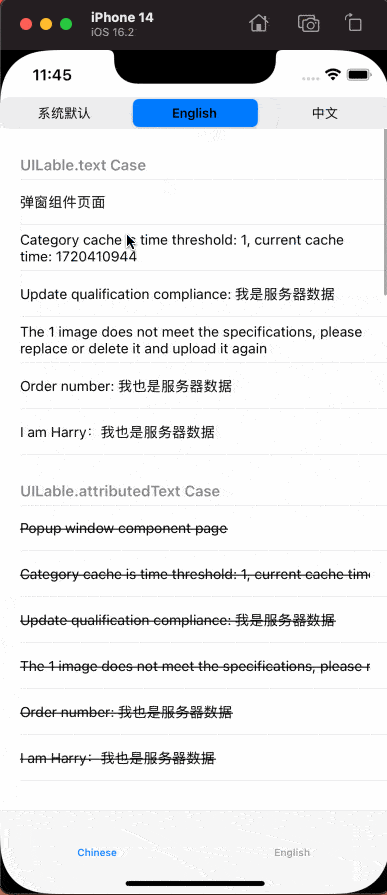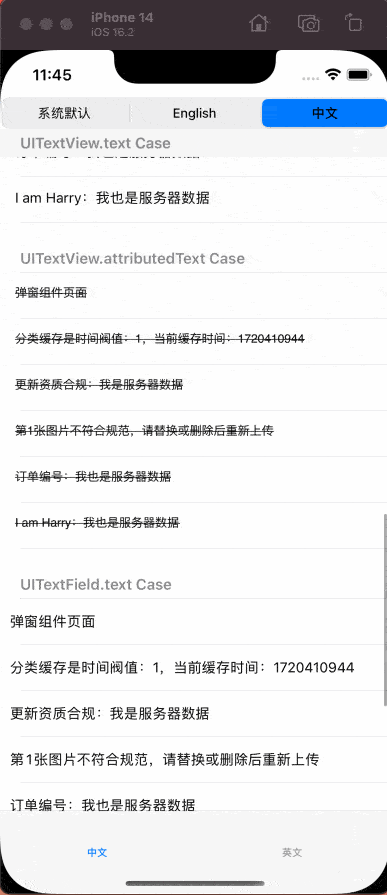
五、示例效果
本文中提到的脚本、国际化API的AOP功能以及相应的示例代码已经开源。请访问 HDTranslateModule 了解更多。如有疑问或在使用过程中遇到问题,请在 issues 中提出。
六、参考资料
iOS开发 国际化/多语言适配
3分钟实现iOS语言本地化/国际化(图文详解)
iOS文本的多语言适配和实践
Mach-O学习
HiBox
otools简介
Google Clound Console
github-copilot