文章目录
- 一、torch.nn.utils.clip_grad_norm_
- 二、计算过程
- 三、确定max_norm
众所周知,梯度裁剪是为了防止梯度爆炸。在训练FCOS算法时,因为训练过程出现了损失为NaN的情况,在github issue有很多都是这种训练过程出现loss为NaN,作者也提出要调整梯度裁剪的超参数,于是理了理梯度裁剪函数torch.nn.utils.clip_grad_norm_ 的计算过程,方便调参。
一、torch.nn.utils.clip_grad_norm_
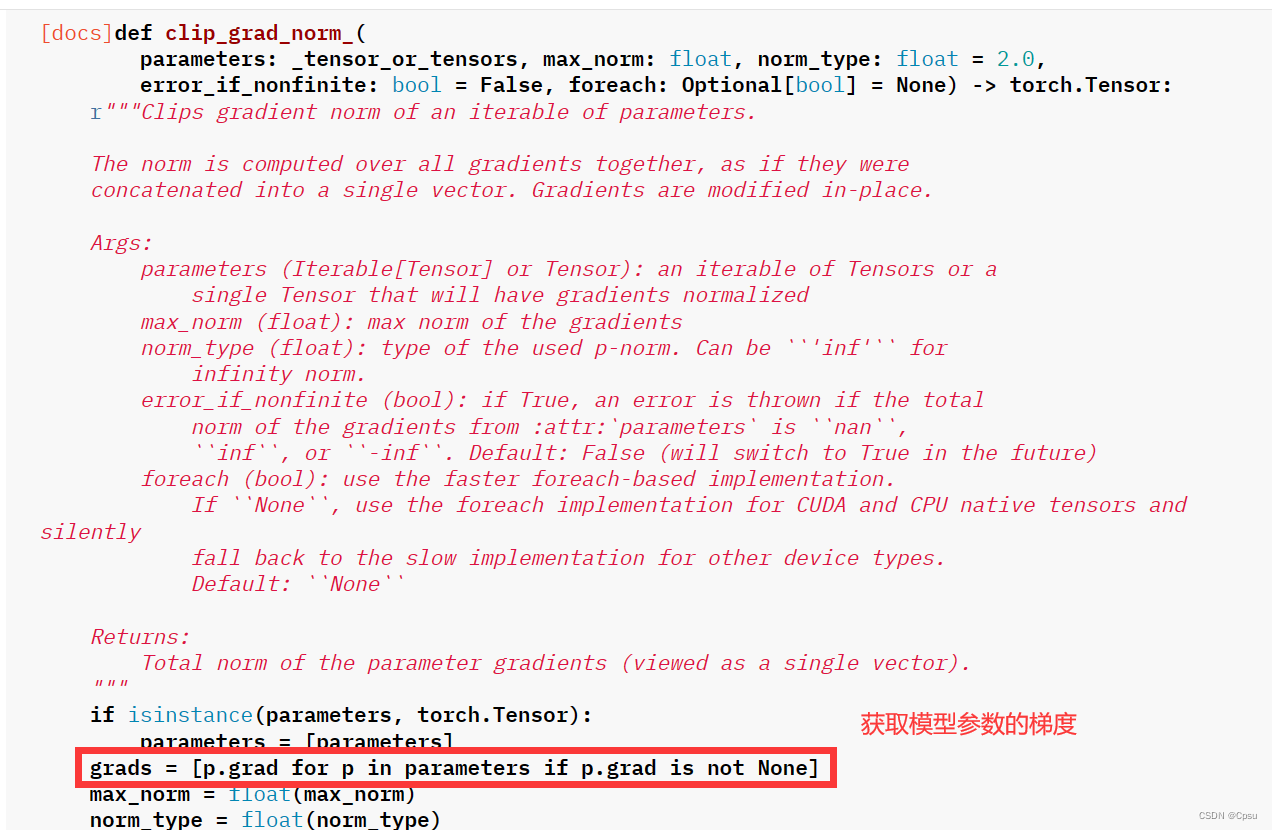
torch.nn.utils.clip_grad_norm_(parameters, max_norm, norm_type) ,这个梯度裁剪函数一般来说只需要调整max_norm 和norm_type这两个参数。
parameters参数是需要进行梯度裁剪的参数列表。通常是模型的参数列表,即model.parameters()
max_norm参数可以理解为梯度(默认是L2 范数)范数的最大阈值
norm_type参数可以理解为指定范数的类型,比如norm_type=1 表示使用L1 范数,norm_type=2 表示使用L2 范数。
同时,torch.nn.utils.clip_grad_norm_和torch.nn.utils.clip_grad_norm(该函数已被弃用)的区别就是前者是直接修改原Tensor,后者不会(在Pytorch中有很多这样的函数对均是如此,在函数最后多了下划线一般都是表示直接在原Tensor上进行操作)。
import torch
# 构造两个Tensor
x = torch.tensor([99.0, 108.0], requires_grad=True)
y = torch.tensor([45.0, 75.0], requires_grad=True)
# 模拟网络计算过程
z = x ** 2 + y ** 3
z = z.sum()
# 反向传播
z.backward()
# 得到梯度
print(f"gradient of x is:{x.grad}")
print(f"gradient of y is:{y.grad}")
# 梯度裁剪
torch.nn.utils.clip_grad_norm_([x, y], max_norm=100, norm_type=2)
# 再次打印裁剪后的梯度
# 直接修改了原x.grad的值
print("---clip_grad---")
print(f"clip_grad of x is:{x.grad}")
print(f"clip_grad of y is:{y.grad}")
# 输出如下
"""
gradient of x is:tensor([198., 216.])
gradient of y is:tensor([ 6075., 16875.])
---clip_grad---
clip_grad of x is:tensor([1.1038, 1.2042])
clip_grad of y is:tensor([33.8674, 94.0762])
"""
上例中可以看出,裁剪后的梯度远小于原来的梯度。一开始变量x的梯度是tensor([198., 216.]),这个很好计算,就是求z对x的偏导,也就是2*x 。变量y同理。裁剪后的梯度远小于原来的梯度,所以可以缓解梯度爆炸的问题。
二、计算过程
梯度裁剪的计算过程参考源码是不难的,
SOURCE CODE FOR TORCH.NN.UTILS.CLIP_GRAD
结合代码转换成数学公式,计算过程如下:
第一步:依然以上面的代码为例,构造Tensor反向传播,得到参数x、y 的梯度,也就是torch.nn.utils.clip_grad_norm_(parameters, max_norm, norm_type) 中的parameters参数。
import torch
# 构造两个Tensor
x = torch.tensor([99.0, 108.0], requires_grad=True)
y = torch.tensor([45.0, 75.0], requires_grad=True)
# 模拟网络计算过程
z = x ** 2 + y ** 3
z = z.sum()
# 反向传播
z.backward()
# 得到梯度
print(f"gradient of x is:{x.grad}")
print(f"gradient of y is:{y.grad}")
# 输出
"""
gradient of x is:tensor([198., 216.])
gradient of y is:tensor([ 6075., 16875.])
"""
第二步:计算每个变量梯度的L2 范数(以L2 范数为例)
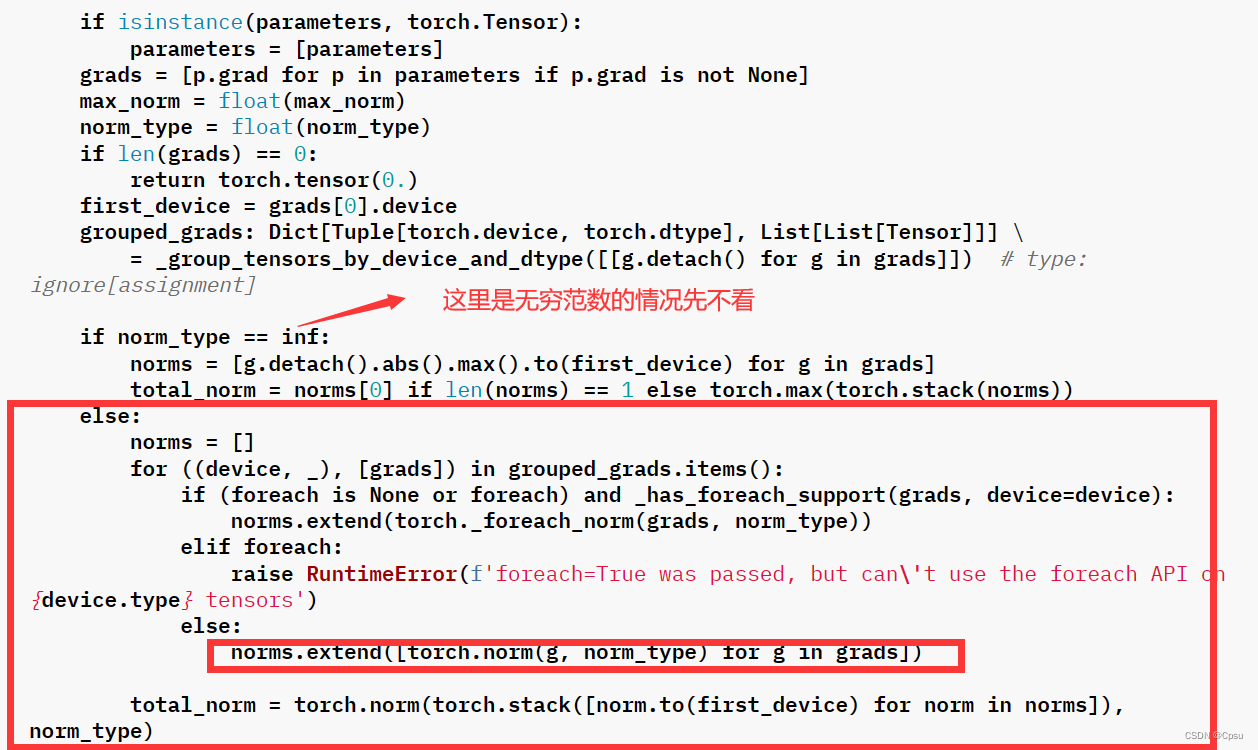
这段代码的意思就是定义一个空列表norms ,用来存储每个参数梯度的L2 范数。随后利用torch.stack把norms中的所有Tensor(计算所得的L2 范数)合并成一个Tensor,最后又再求合并后Tensor的L2 范数得到total_norm(总范数)。
当
norm_type是inf即无穷范数时,total_norm会直接取参数梯度最大的那一个
# 相当于把x_L2norm、y_L2norm放入代码中的norms空列表
# x的梯度的L2 范数
x_L2norm = torch.sum(x.grad ** 2) ** 0.5
# y的梯度的L2 范数
y_L2norm = torch.sum(y.grad ** 2) ** 0.5
# 相当于遍历norms列表合并成一个Tensor
total_norm = torch.sum(torch.stack([x_L2norm, y_L2norm]) ** 2) ** 0.5
"""
等价过程
x_L2norm = sum([198 ** 2, 216 ** 2]) ** 0.5
y_L2norm = sum([6075 ** 2, 16875 ** 2]) ** 0.5
total_norm = sum([x_L2norm ** 2, y_L2norm ** 2]) ** 0.5
"""
第三步:计算梯度裁剪系数
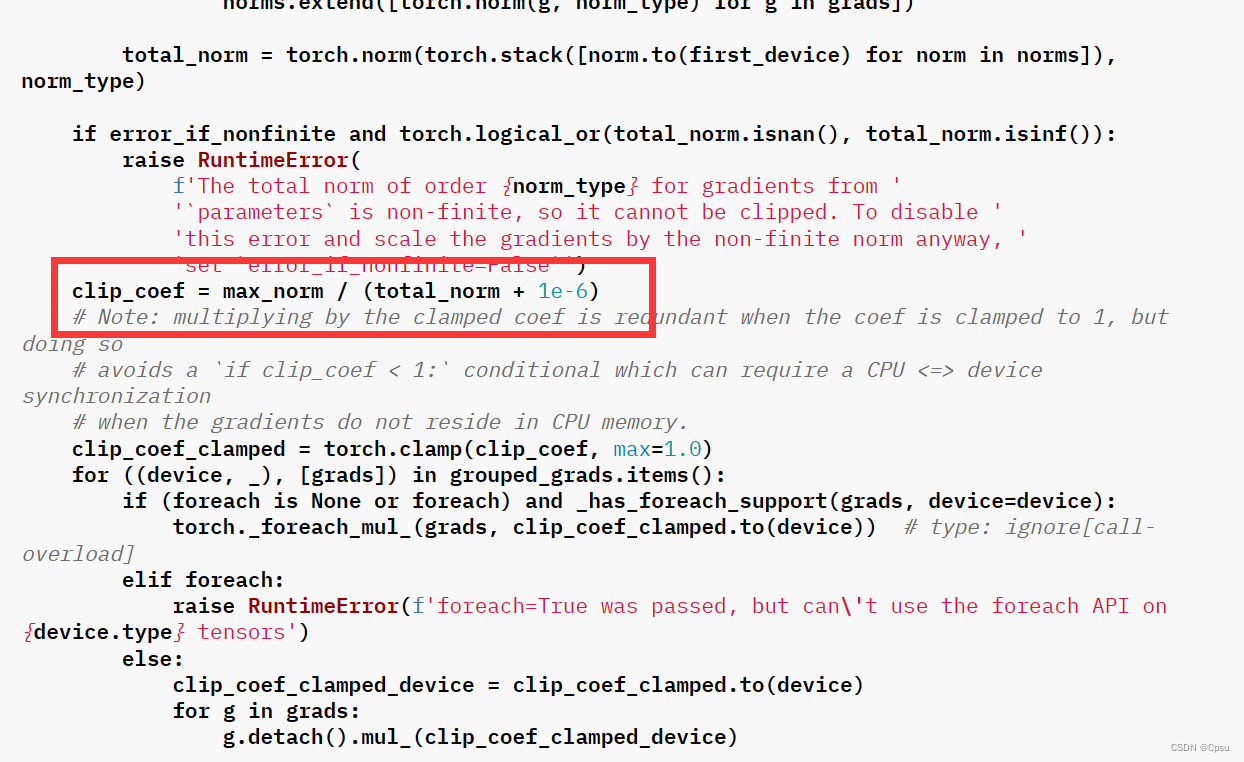
# 1e-6防止分母为0
# clip_coef = max_norm / (total_norm + 1e-6)
max_norm = 100
clip_coef = max_norm / total_norm
第四步:将原始梯度乘以梯度裁剪系数得到裁剪后的梯度,这与函数计算的结果是一致的。
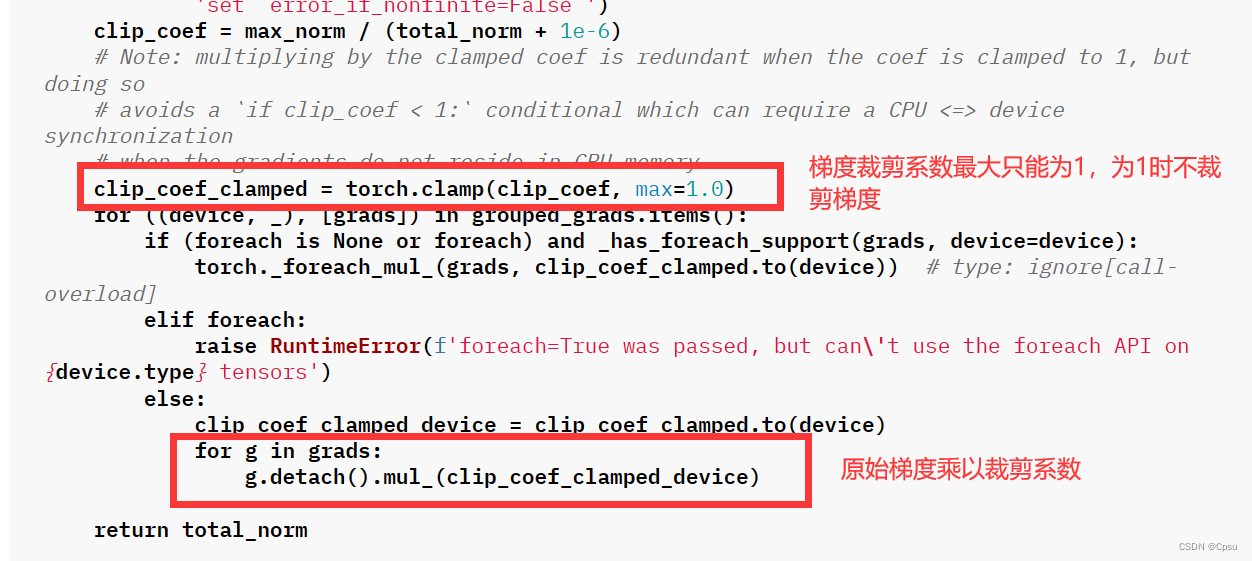
print(f"clip_grad of x is: is {x.grad * clip_coef }")
print(f"clip_grad of x is: is {y.grad * clip_coef }")
# 输出
"""
clip_grad of x is: is tensor([1.1038, 1.2042])
clip_grad of x is: is tensor([33.8674, 94.0762])
"""
整合一下代码:
import torch
# 构造两个Tensor
x = torch.tensor([99.0, 108.0], requires_grad=True)
y = torch.tensor([45.0, 75.0], requires_grad=True)
# 模拟网络计算过程
z = x ** 2 + y ** 3
z = z.sum()
# 反向传播
z.backward()
# 得到梯度
print(f"gradient of x is:{x.grad}")
print(f"gradient of y is:{y.grad}")
x_L2norm = torch.sum(x.grad ** 2) ** 0.5
y_L2norm = torch.sum(y.grad ** 2) ** 0.5
total_norm = torch.sum(torch.stack([x_L2norm, y_L2norm]) ** 2) ** 0.5
max_norm = 100
clip_coef = max_norm / total_norm
print(f"clip_grad of x is: is {x.grad * clip_coef }")
print(f"clip_grad of x is: is {y.grad * clip_coef }")
# 输出如下
"""
gradient of x is:tensor([198., 216.])
gradient of y is:tensor([ 6075., 16875.])
clip_grad of x is:tensor([1.1038, 1.2042])
clip_grad of y is:tensor([33.8674, 94.0762])
"""
三、确定max_norm
根据上述计算过程,梯度裁剪最主要的就是计算出裁剪系数得出裁剪后的梯度。clip_coef = max_norm / total_norm 公式中,clip_coef 越小,裁剪的梯度越大。即
max_norm越小,裁剪的梯度越大,得到的梯度就越小,防止梯度爆炸的效果越明显。
在训练模型时,我们可以根据total_norm的值大概确定max_norm的一个取值范围。调用torch.nn.utils.clip_grad_norm_([x, y], max_norm=100, norm_type=2)函数时,该函数会返回total_norm的值。比如最开始参数x、y,这时的total_norm为17937.5879,值非常大,那么为了防止梯度爆炸我们就可以把max_norm设置得稍微小一些。
# 以最开始的x、y为例
total_norm = torch.nn.utils.clip_grad_norm_([x, y], max_norm=100, norm_type=2)
print(total_norm)
#输出
# tensor(17937.5879)