Xpath 插件下载及安装
下载地址:https://chrome.zzzmh.cn/info/hgimnogjllphhhkhlmebbmlgjoejdpjl
安装xpath
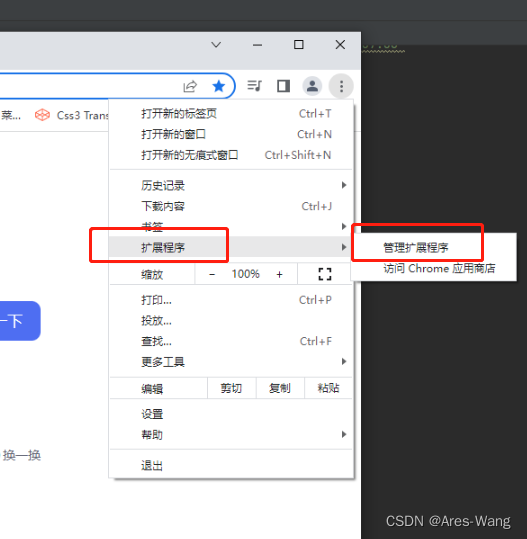
如果下载的xpath后缀是crx 格式的, 直接改成zip格式,然后直接拖拽到上面的界面中便可,
查看是否安装成功, ctrl+ shift +X 出现下面界面
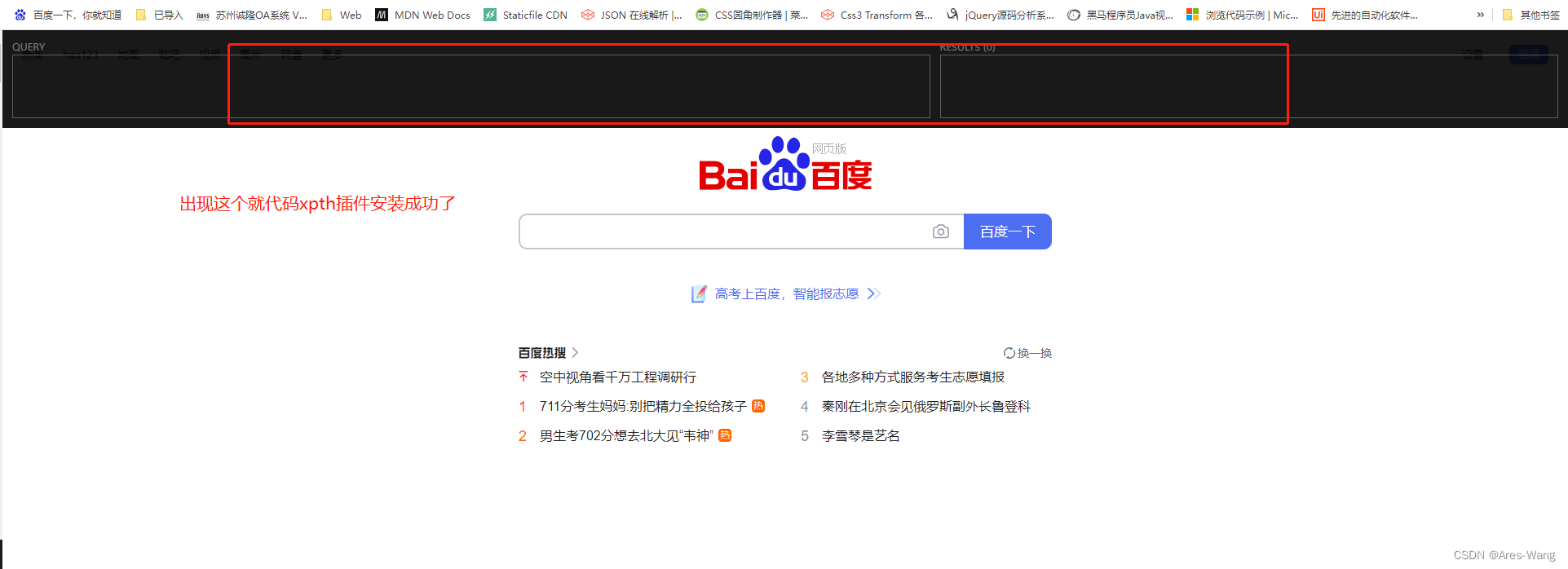
如果没有出现,请重启谷歌浏览器
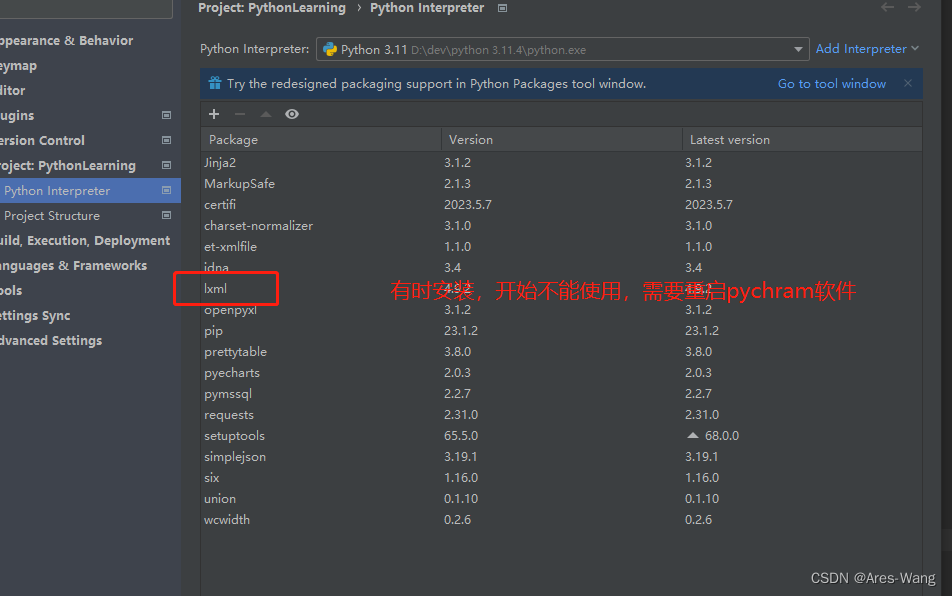
安装lxml
要安装在pycharm解释器对应的位置,查看pycharm解释器的位置
方法1,pycharm右下角 
方法2.pycharm 菜单 File 》》 settings
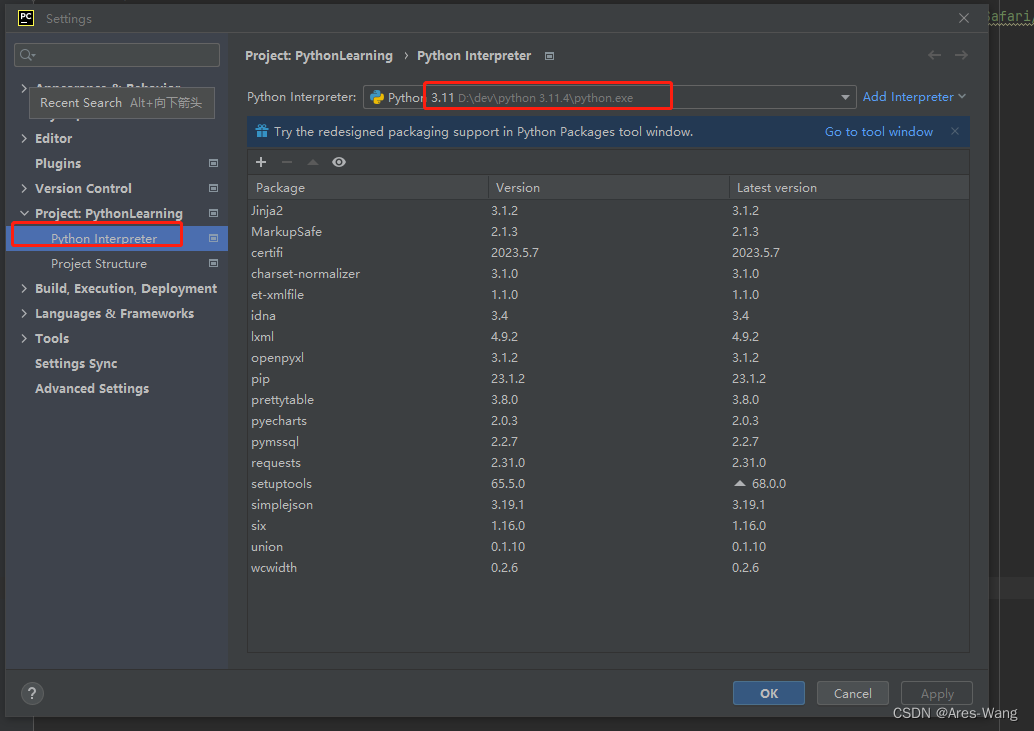
知道python 解释器安装的位置。
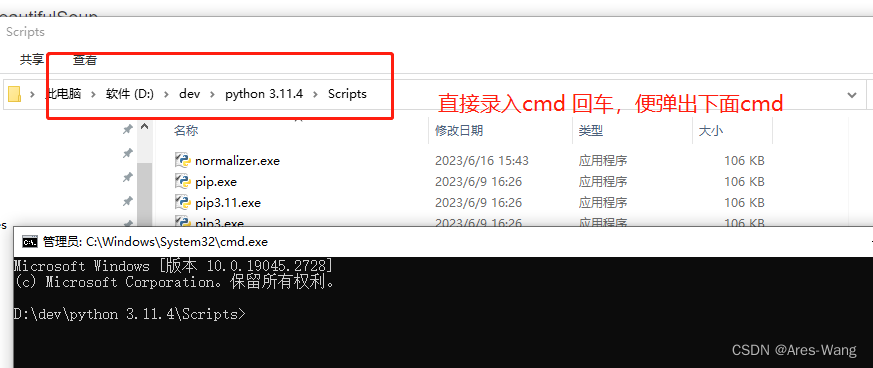
通过cmd命令进入对应位置
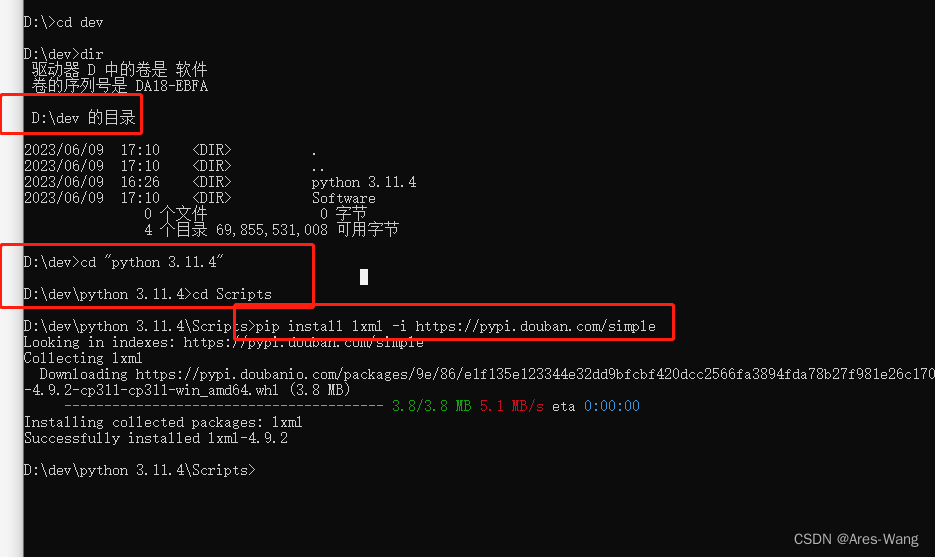
4.9.2 版本的lxml版本,没有etree,可以安装制定版本
pip install lxml==4.2.5
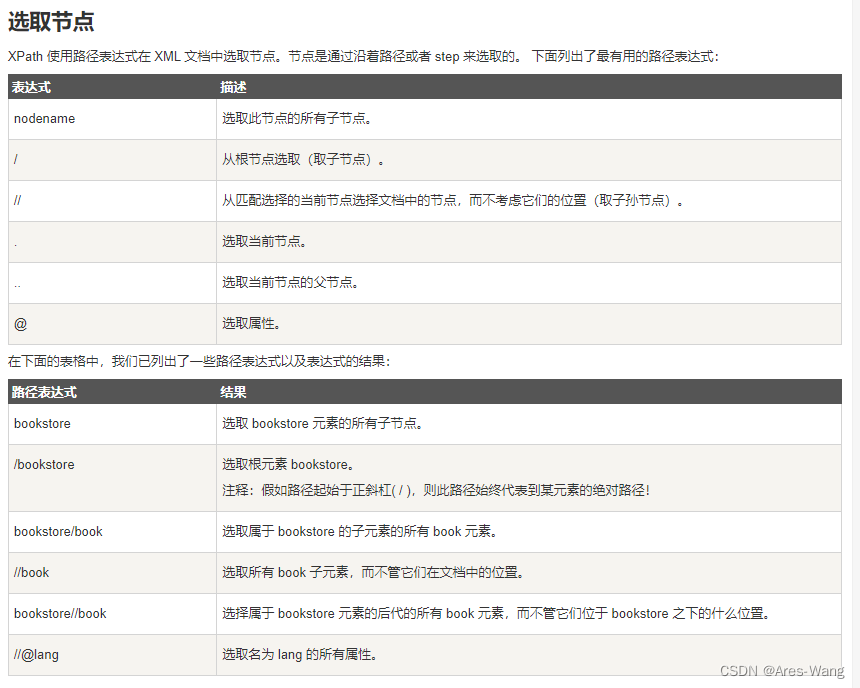
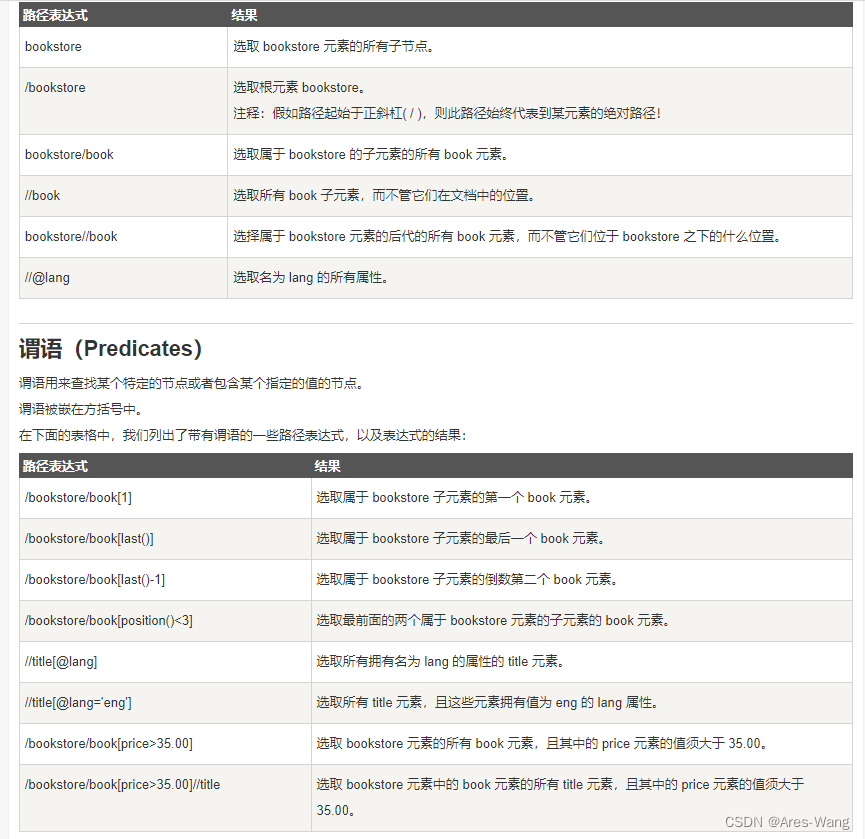
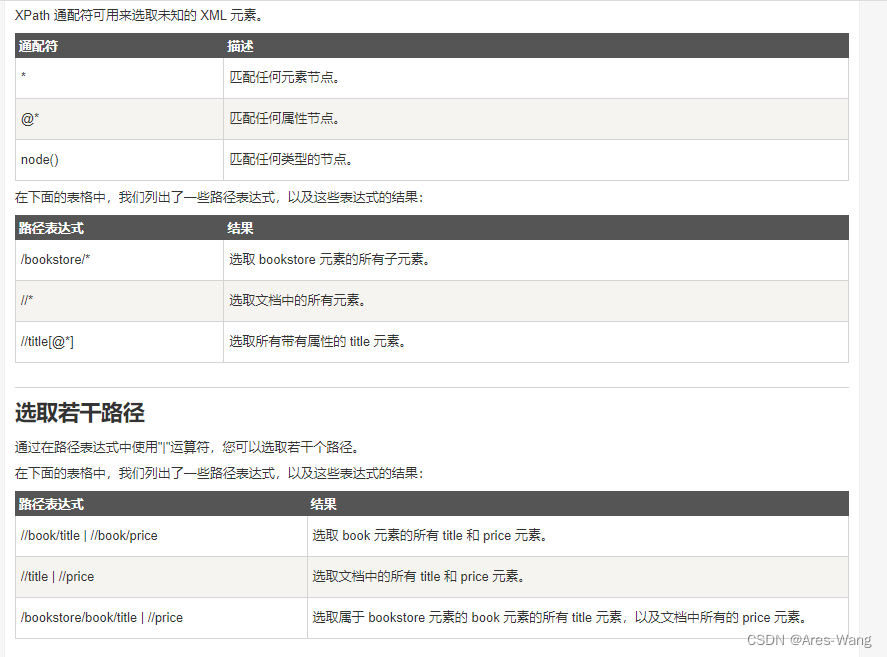

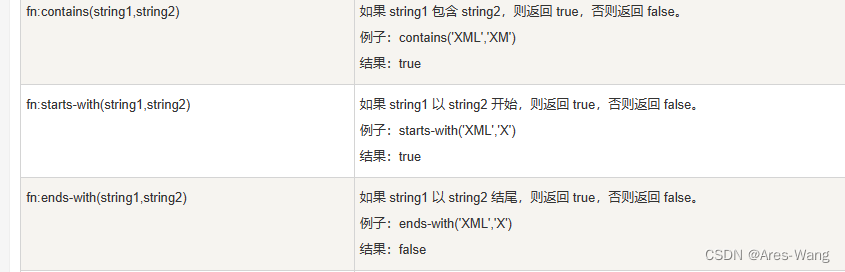
| 或运算, 针对元素 非属性
from lxml import etree
# 解析本地文件
html_tree = etree.parse("xxx.html")
# 解析服务端文件
html_tree = etree.HTML(response.read().decode('UTF-8'))
# xpath 路径
html_tree.xpath(xpath路径)
# 查找id为l1的标签的class的属性值
html_tree.xpath('//ul/li[@id="l1"]/@class')
# 查找所有有id数学的li标签 text() 获取标签的内容
html_tree.xpath('//ul/li[@id="l1"]/text()')

获取百度上面的 高考上百度,智能报志愿
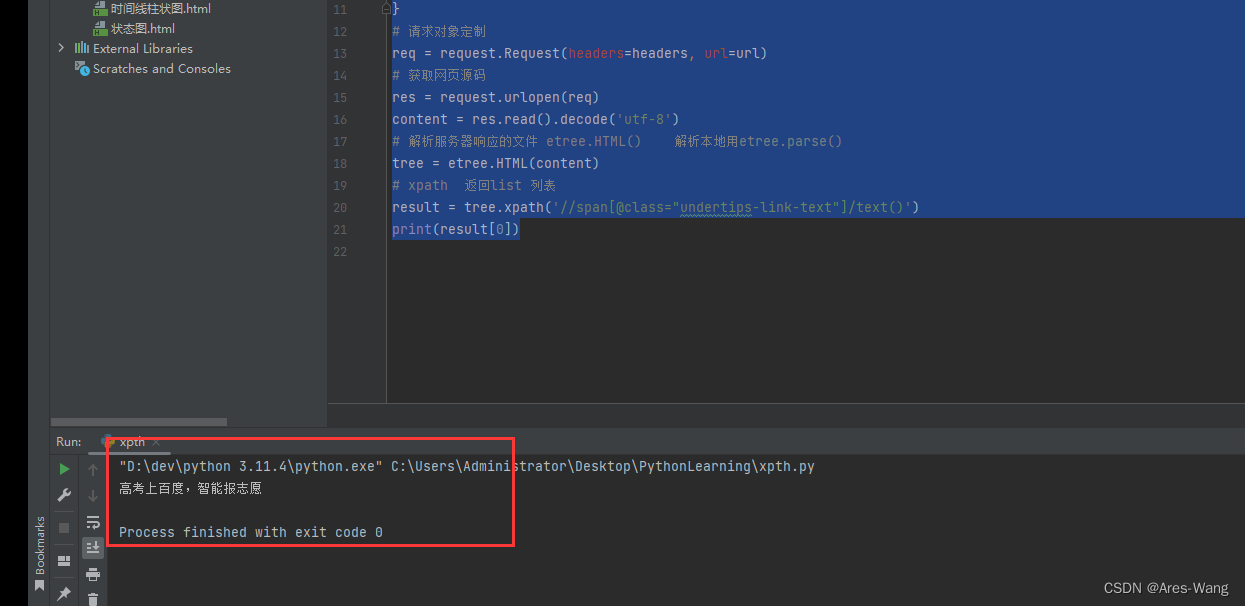
# 获取百度上面的 高考上百度,智能报志愿
from urllib import request
from lxml import etree
url = "https://www.baidu.com"
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
# 请求对象定制
req = request.Request(headers=headers, url=url)
# 获取网页源码
res = request.urlopen(req)
content = res.read().decode('utf-8')
# 解析服务器响应的文件 etree.HTML() 解析本地用etree.parse()
tree = etree.HTML(content)
# xpath 返回list 列表
result = tree.xpath('//span[@class="undertips-link-text"]/text()')
print(result[0])
可以结合 urllib.request.urlretrieve 下载 照片 等