文章目录
- 一、源码网址
- 1. 硬件设施:
- 2. INT4 量化示例
- 二、重要的开源社区
- 功能:
- 网址:
- 使用方法:
- 利用方法:
- 对 NLP 工作者的作用:
- 对大模型工程师的用处:
- 三、重要的开源库
- 四、提示词工程
- 五、进行分类任务微调
- 1. 数据示例
- 2. prompt工程设计
- 3. 完整代码
一、源码网址
ChatGLM2-6B
1. 硬件设施:
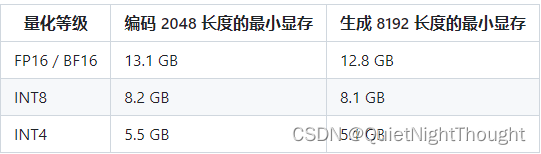
2. INT4 量化示例
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().quantize(4).cuda()
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
二、重要的开源社区
关于 Hugging Face 社区
功能:
Hugging Face 社区主要提供了以下功能和资源:
预训练模型:社区提供了大量高质量的预训练模型,用户可以基于这些模型进行微调或者在其上进行迁移学习。
数据集:社区提供了多个数据集,覆盖了各种自然语言处理任务,包括文本分类、命名实体识别、语义理解等。
代码库:社区提供了多个开源的代码库,方便用户快速实现各种自然语言处理任务。
论坛:社区拥有一个活跃的论坛,研究者和开发者可以在这里分享经验、提出问题、求助答案等。
网址:
Hugging Face 社区的网址为:https://huggingface.co/,您可以在该网站上找到社区提供的全部资源。
使用方法:
使用 Hugging Face 社区的方法如下:
注册账号:在 Hugging Face 社区上注册一个账号,即可开始使用社区提供的各种资源。
下载模型:从社区提供的模型库中下载需要的预训练模型。
微调模型:基于已有的预训练模型,在自己的数据集上进行微调,得到适用于自己应用场景的模型。
使用代码库:从社区提供的代码库中找到适用于自己应用场景的代码,快速实现自然语言处理任务。
利用方法:
利用 Hugging Face 社区可以帮助您:
提高工作效率:社区提供了大量高质量的预训练模型、数据集和代码库,可以帮助您快速搭建自然语言处理应用程序。
降低开发成本:直接使用已有的预训练模型和数据集,不需要从头开始构建自然语言处理应用程序,可以大大降低开发成本。
提高准确性:使用社区提供的预训练模型可以显著提高自然语言处理的准确性。
对 NLP 工作者的作用:
Hugging Face 社区对 NLP 工作者的作用是:
提供了大量的预训练模型和数据集,方便研究者和开发者进行实验和研究。
可以与其他 NLP 工作者交流经验、分享最新技术和趋势,共同推动领域的发展。
对大模型工程师的用处:
Hugging Face 社区对大模型工程师的用处在于:
提供了大量高质量的预训练模型,可以直接使用已有的模型进行微调或者迁移学习。
提供了代码库和论坛,在开发大模型时可以方便地获取支持和帮助。
三、重要的开源库
Transformers是一个Python库,它提供了各种自然语言处理(NLP)任务的预训练模型和工具。该库使用深度学习算法,并旨在使研究人员和开发人员能够轻松地开发和部署自然语言处理系统。
Transformers的主要作用是提供针对不同NLP任务的预训练模型,例如文本分类、命名实体识别、情感分析和机器翻译等。这些模型可以直接在用户的应用程序中使用,也可以通过微调进行定制和优化以适应特定的任务。
该库包含许多参数,其具体含义取决于正在使用的模型和任务。一些通用的参数包括:
batch_size:每个训练批次中的样本数量。
max_seq_length:输入序列的最大长度。
num_train_epochs:训练迭代的次数。
learning_rate:模型权重更新的速率。
举例来说,如果您使用BertForSequenceClassification模型进行文本分类任务,则可能需要设置以下参数值:
batch_size:32
max_seq_length:128
num_train_epochs:3
learning_rate:2e-5
使用Transformers时,用户可以根据需要选择适当的模型和参数,并按照提供的示例代码进行操作。例如,下面是一个简单的示例,演示如何使用BertForSequenceClassification模型对情感分析任务进行微调:
from transformers import BertTokenizer, BertForSequenceClassification
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
# Load and tokenize the data
texts = ['I love this movie!', 'This movie is terrible.']
labels = [1, 0]
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
# Fine-tune the model
outputs = model(**inputs, labels=labels)
loss = outputs.loss
该代码加载了一个预训练的BertForSequenceClassification模型和一个预处理器(tokenizer),然后使用文本和标签来训练该模型。在微调之后,模型可以用于对新文本进行情感分析。
四、提示词工程
提示词工程(Prompt Engineering)是一种新兴的自然语言处理技术,它旨在通过为预训练语言模型提供特定的文本提示或“提示词”,来改进模型的性能和适应性。这些提示词可以是人为指定的关键词、短语、句子或段落,也可以根据特定任务的要求自动生成。
提示词工程的重要性在于,即使在具有数十亿个参数的大型语言模型中,仍可能存在一些问题,例如出现偏差或过度拟合等。在这种情况下,使用提示词可以帮助模型更好地理解和推断特定语境下的文本,从而提高其性能和准确性。
此外,在当下大模型时代,提示词工程作用尤为突出。随着深度学习算法和计算能力的不断发展,越来越多的领域开始使用大型预训练语言模型,例如BERT、GPT-2和RoBERTa等。然而,这些模型可能无法完全适应某些具体任务的需求,因此需要使用提示词来进行微调和优化。
提示词工程还可以帮助加快自然语言处理应用程序的开发速度。通过使用预先定义好的提示词和相应的模型,可以缩短从想法到生产的时间,同时减少开发和调试过程中的错误和不确定性。
五、进行分类任务微调
1. 数据示例
class_examples = {
'人物': '秦始皇(259BC – 210BC),又称嬴政,是中国历史上著名的政治家和军事家。他是秦国的君主,统一了六国之后建立了中国的第一个中央集权制度的封建王朝——秦朝。',
'书籍': '论语》是中国古代文化经典之一,由春秋时期的著名思想家孔子及其弟子们的言行录成。全书共20篇,收录孔子及其弟子的言论和事迹,它主要关注人的品德、修养和社会伦理。',
'电影': '《忠犬八公》是一部由拉斯·哈尔斯特朗执导,理查·基尔、琼·艾伦等主演的电影,于2009年上映。该电影改编自真实故事',
'都市': '郑州是中国河南省的省会城市,位于中部地区。它是中国的重要交通枢纽和工商业中心,也是中原地区的政治、经济、文化和教育中心之一。郑州有着悠久的历史,是中国的八大古都之一。',
'国家': '中国是位于亚洲东部的一个大国,拥有悠久的历史文化和丰富的自然资源。中国的首都是北京,人口超过14亿人,是世界上最大的国家之一。中国的经济实力也非常强大,在全球范围内拥有很高的影响力。中文是中国的官方语言,中国也拥有丰富多彩的饮食、艺术、体育和娱乐活动等文化特色。'
}
2. prompt工程设计
对于大模型来讲,prompt 的设计是重要一步
在该任务的 prompt 简单进行示例:
- 告诉模型解释什么叫作‘’文本分类任务‘’
- 指定模型按照我们想要格式输出
后面咱们专门搞篇文章说prompt
3. 完整代码
from rich import print
from rich.console import Console
from transformers import AutoTokenizer, AutoModel
# 提供所有类别以及每个类别下的样例
class_examples = {
'人物': '秦始皇(259BC – 210BC),又称嬴政,是中国历史上著名的政治家和军事家。他是秦国的君主,统一了六国之后建立了中国的第一个中央集权制度的封建王朝——秦朝。',
'书籍': '论语》是中国古代文化经典之一,由春秋时期的著名思想家孔子及其弟子们的言行录成。全书共20篇,收录孔子及其弟子的言论和事迹,它主要关注人的品德、修养和社会伦理。',
'电影': '《忠犬八公》是一部由拉斯·哈尔斯特朗执导,理查·基尔、琼·艾伦等主演的电影,于2009年上映。该电影改编自真实故事',
'都市': '郑州是中国河南省的省会城市,位于中部地区。它是中国的重要交通枢纽和工商业中心,也是中原地区的政治、经济、文化和教育中心之一。郑州有着悠久的历史,是中国的八大古都之一。',
'国家': '中国是位于亚洲东部的一个大国,拥有悠久的历史文化和丰富的自然资源。中国的首都是北京,人口超过14亿人,是世界上最大的国家之一。中国的经济实力也非常强大,在全球范围内拥有很高的影响力。中文是中国的官方语言,中国也拥有丰富多彩的饮食、艺术、体育和娱乐活动等文化特色。'
}
def init_prompts():
"""
初始化前置prompt,便于模型做 incontext learning。
"""
class_list = list(class_examples.keys())
pre_history = [
(
f'现在你是一个文本分类器,你需要按照要求将我给你的句子分类到:{class_list}类别中。',
f'好的。'
)
]
for _type, exmpale in class_examples.items():
pre_history.append((f'“{exmpale}”是 {class_list} 里的什么类别?', _type))
return {'class_list': class_list, 'pre_history': pre_history}
def inference(
sentences: list,
custom_settings: dict
):
"""
推理函数。
Args:
sentences (List[str]): 待推理的句子。
custom_settings (dict): 初始设定,包含人为给定的 few-shot example。
"""
for sentence in sentences:
with console.status("[bold bright_green] Model Inference..."):
sentence_with_prompt = f"“{sentence}”是 {custom_settings['class_list']} 里的什么类别?"
response, history = model.chat(tokenizer, sentence_with_prompt, history=custom_settings['pre_history'])
print(f'>>> [bold bright_red]sentence: {sentence}')
print(f'>>> [bold bright_green]inference answer: {response}')
# print(history)
if __name__ == '__main__':
console = Console()
device = 'cuda:0'
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half()
model.to(device)
sentences = [
"日本是一个位于亚洲东部的岛国,由4个主要岛屿和数百个小岛组成。它与韩国、中国、俄罗斯等国接壤或隔海相望。日本是一个高度现代化和发达的经济体,其科技产业和文化艺术在世界范围内具有重要影响力。该国拥有丰富的文化遗产,如传统建筑、传统艺术、武士文化等等。此外,日本还以其美食文化、时尚产业、动漫游戏等受到了全球年轻人的喜爱。",
"《亮剑》是一部中国电视剧,于2005年首播。该剧以解放战争时期的中国为背景,讲述了一群革命军人在战火纷飞的年代里,奋勇杀敌、坚守阵地、保卫家园的故事。该剧具有广泛的社会影响力和高度的观赏性,其高超的制作水平、优秀的演员阵容、感人至深的情节和深刻的思想内涵都受到了观众的普遍认可和喜爱。",
]
custom_settings = init_prompts()
inference(
sentences,
custom_settings
)