精选大厂可能会问的那些思维题和技术点
- 一、题目一
- 1.1、思路:
- 1.2、代码实现
- 二、题目二
- 三、const 的含义及实现机制, ,比如 : const int i, 是怎么做到 i 只可读的? ?
- 四、到商店里买 200 的商品返还 100 优惠券( ( 可以在本商店代替现金) ) 。请问实际上折扣是多少? ?
- 五、TCP 三次握手的过程t , accept 发生在三次握手哪个阶段?
- 六、 用 UDP 协议通讯时怎样得知目标机是否获得了数据包 ? ?
- 七、玩家有剪刀,石头,布(以 0 ,1 ,2表示)三种卡片无限出 张。现在玩家拿出 n 张排成一排。然后你也拿出 n 张牌一 一得 对应比对。若赢一局则获得一分。若你想得 k 分。现在输入n ,k 和牛妹的 n 张牌分别是什么,你想要恰好得 k 分,有多少种方法?
- 八、从10G 个数中找到中数
- 九、两个整数集合 A 和 B, 求 其交集。
- 十、有 1 到 10w 这 10w个数, , 去除 2 个并打乱次序, , 如何找出那两个数? ?
- 十一、有 1000 瓶水, 其中有一瓶有毒, 小白鼠只要尝一点带毒的水 24 小时后就会死亡, 至少要多少只小白鼠才能在 24 小时鉴别出那瓶水有毒? ?
- 十二、给 40 亿个不重复的 unsigned int 的整数, 没排过序的,然后再给几个数 , 如何快速判断这几个数是否在那 10 亿个数当中? ?
- 十三、爸爸妈妈妹妹小强,至少两个人同一生肖的概率是多少?
- 十四、计算a^b<<2
- 十五、如何输出源文件的标题和目前执行的行数?
- 十六、希尔,冒泡,快速,插入哪个平均速度最快?
- 十七、频繁的插入刪除操作使用什么结构比较合适,链表还是数组?
- 十八、 *p=NULL; *p= new charl[100]; sizeof(p)为多少?
- 十九、不能做 switch()的参数类型是?
- 二十、不使用其他变里,交换两个整型 a,b 的值?
- 二十一、IP 地址的编码分为哪俩部分?
- 二十一、 Internet 采用哪种网络协议?该协议的主要层次结构?
- 二十二、 Internet 物理地址和IP 地址转换采用什么协议?
- 二十三、 redis 的主从复制怎么做的?
- 23.1、命令
- 23.3、原理
一、题目一
一个数列:- 1 ,2 - 3, 4 ,- 5, 6 … 询问 q 次,每次询问区间 [l,r] 的区间和, , 输出每个询问的答案。
1.1、思路:
第 1 个和第 2 个加起来为 1,第 3,4 个加起来也为 1…;所以前 i 项和为:i/2+(i&1)*i。区间和可以用前 i 项和算出来了。
1.2、代码实现
class Solution
{
public:
int ranges(int start,int end)
{
return end/2+(end&1)*end - (start/2+(start&1)*start);
}
};
二、题目二
有n 种硬币,面额分别为 1~n ,每种硬币都有无限个,假设要付款的金额为 m ,最少的硬币数量是多少?
思路:
m/n+(m%n)
三、const 的含义及实现机制, ,比如 : const int i, 是怎么做到 i 只可读的? ?
思路:
const用来说明定义的变量是只读的。
在编译期间完成,编译器直接用常数直接替换掉对此变量的引用。
四、到商店里买 200 的商品返还 100 优惠券( ( 可以在本商店代替现金) ) 。请问实际上折扣是多少? ?
思路:
(1)如果使用优惠券可以返回优惠卷(使用 200 元优惠券买东西,然后还可以获得 100 元的优惠券),那么花x的钱可以买到x+x/2+x/4+…的东西,那么实际折扣是50%,但是大部分时候很难一直兑换下去,所以 50%是折扣的上限。
(2)如果使用优惠券不可以返回优惠卷,那么实际折扣是200/300=67%。
五、TCP 三次握手的过程t , accept 发生在三次握手哪个阶段?
accept 发生在三次握手之后。
第一次握手:客户端发送 syn 包(syn=j)到服务器。
第二次握手:服务器收到 syn 包,必须确认客户的 SYN(ack=j+1),同时自己也发送一个
ACK 包(ack=k)。
第三次握手:客户端收到服务器的 SYN+ACK 包,向服务器发送确认包 ACK(ack=k+1)。
握手完成后,客户端和服务器就建立了 tcp 连接。这时可以调用 accept 函数获得此连接。
六、 用 UDP 协议通讯时怎样得知目标机是否获得了数据包 ? ?
可以在每个数据包中插入一个唯一的 ID,比如 timestamp 或者递增的 int。
发送方在发送数据时将此 ID 和发送时间记录在本地。
接收方在收到数据后将 ID 再发给发送方作为回应。
发送方如果收到回应,则知道接收方已经收到相应的数据包;如果在指定时间内没有收到回应,则数据包可能丢失,需要重复上面的过程重新发送一次,直到确定对方收到。
七、玩家有剪刀,石头,布(以 0 ,1 ,2表示)三种卡片无限出 张。现在玩家拿出 n 张排成一排。然后你也拿出 n 张牌一 一得 对应比对。若赢一局则获得一分。若你想得 k 分。现在输入n ,k 和牛妹的 n 张牌分别是什么,你想要恰好得 k 分,有多少种方法?
答案跟每一张牌是什么没有关系。没一张牌只需要考虑赢、不赢。
赢 k 分,那就是从 n 张牌中拿出 k 张赢,其他输,所以组合数 c(n,k)。对于赢了答 k 张,只有一种方法,但是对于剩下的 n-k张,都有平局和输掉两种情况,所以是 2 的 n-k 次方。两者相乘就是答案。
结果很大对 mod=1e9+7 取余,用到同余定理。
求 2 的幂直接暴力求(当然也可以快速幂)求组合数的时候用到除法,又要取余,所以用到逆元。所以用到逆元公式(当然还有其他求法):pow(x,mod-2)%mod;但是 mod=1e9+7,所以暴力求幂会超时,方法是用快速求幂法压缩时间。
八、从10G 个数中找到中数
在一个文件中有 10G 个整数, , 乱序排列, ,要求找出中位数。内存限制为 2G。
思路:
假设 10G 个整数是64bit的,2G内存可以存放256M个64bit整数。可以将整数空间平均分成256M个取值范围,用2G的内存空间对每个取值范围内出现的整数个数进行统计。这样遍历一遍10G整数后,我们便知道中数在那个范围出现,以及这个范围内总共出现了多少个整数。
如果中数所在范围出现的整数比较少,我们就可以对这个范围内的整数进行排序,找到中数。如果这个范围还可以采用同样的方法将此范围再次分成多个更小的范围(256M-228,所以最多需要 3 次就可以将此范围缩小到 1,也就找到了中数)。
九、两个整数集合 A 和 B, 求 其交集。
- 读取整数集合 A 中的整数,将读到的整数插入到 mp 中,并将对应的值设为 1。
- 读取整数集合 B 中的整数,如果该整数在 map 中并且值为 1,则将此数加入到交集当中,并将在 map 中的对应值改为 2。
通过更改 map 中的值,避免了将同样的值输出两次。
代码实现:
class Solution {
public:
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
map<int,int> mp;
vector<int> res;
int len=nums1.size();
int i=0;
for(i=0;i<len;i++)
mp[nums1[i]]=1;
len=nums2.size();
for(i=0;i<len;i++)
{
if(mp[nums2[i]]==1)
{
mp[nums2[i]]+=1;
res.emplace_back(nums2[i]);
}
}
return res;
}
};
十、有 1 到 10w 这 10w个数, , 去除 2 个并打乱次序, , 如何找出那两个数? ?
思路一:
申请10W个bit的空间,每个bit代表数字是否出现过,开始时将这10W个bit都初始化为0,表示所有数字都没出现过,然后依次读入已经打乱次序的的数字,并将对应bit设为1。处理完之后根据为0的bit得出没有出现的数字。
思路二:
- 先算出1到10w的和、平方和;
- 在算出给定数字的和、平方和;
- 两次数字相减,可以得到这两个数字的和、平方和;
- 得到如下的公式:
x + y = m x+y=m x+y=m;
x 2 + y 2 = n x^2+y^2=n x2+y2=n;
解方程即可得到结果x、y。
十一、有 1000 瓶水, 其中有一瓶有毒, 小白鼠只要尝一点带毒的水 24 小时后就会死亡, 至少要多少只小白鼠才能在 24 小时鉴别出那瓶水有毒? ?
最容易想到的就是用 1000 只小白鼠,每只喝一瓶。但显然这不是最好答案。
既然每只小白鼠喝一瓶不是最好答案,那就应该每只小白鼠喝多瓶。那每只应该喝多少瓶呢?
首先让我们换种问法,如果有 x 只小白鼠,那么 24 小时内可以从多少瓶水中找出那瓶有毒的?
由于每只小白鼠都只有死或者活这两种结果,所以 x 只小白鼠最大可以表示 2^x 种结果。如果让每种结果都对应到某瓶水有毒,那么也就可以从 2^x 瓶水中找到有毒的那瓶水。那如何来实现这种对应关系呢?
第一只小白鼠喝第 1 到 2^(x-1)瓶,第二只小白鼠喝第 1 到第 2^(x-2)和第 2^(x-1)+1
到第 2^(x-1)+2(x-2)瓶…以此类推。
回到此题,总过 1000 瓶水,所以需要最少 10 只小白鼠。
十二、给 40 亿个不重复的 unsigned int 的整数, 没排过序的,然后再给几个数 , 如何快速判断这几个数是否在那 10 亿个数当中? ?
unsigned int 的取值范围是 0 到 2^32-1。我们可以申请连续的 232/8-512M 的内存,用每一个 bit 对应个 unsigned int 数字。首先将 51M 内存都初始化为 0,然后每处理一个数字就将其对应的 bit 设置为 1。当需要查询时,直接找到对应 bit,看其值是 0 还是1 即可。
十三、爸爸妈妈妹妹小强,至少两个人同一生肖的概率是多少?
1 − ( 12 × 11 × 10 × 9 ) ÷ ( 1 2 4 ) = 0.427 1-(12\times 11\times 10\times 9)\div (12^4)=0.427 1−(12×11×10×9)÷(124)=0.427
十四、计算a^b<<2
- 运算符优先级:括号,下标,->和(.成员)最高;
- 单目的比双目的高;
- 算术双目的比其他双目的高;
- 位运算高于关系运算;
- 关系运算高于按位运算(与,或,异或);
- 按位运算高于逻辑运算;
- 目的只有一个条件的运算低于逻辑运算;
- 赋值运算仅比(顺序运算)高;
思路:在此题中,位左移<<”优先级高于按位异或"^"所以 b 先左移两位(相当于乘以 4)再与 a 异或。
十五、如何输出源文件的标题和目前执行的行数?
printf("The file name:%dn", __FILE__);
printf("The current line No: %d\n", __LINE__);
ANSI C 标准预定义宏:
- LINE 。
- FILE 。
- DATE 。
- TIME 。
- STDC 当要求程序严格遵循 ANSC 标准时该标识符被赋值为 1 。
- cplusplus 当编写 C+程序时该标识符被定义。
十六、希尔,冒泡,快速,插入哪个平均速度最快?
快速排序 。
快速排序、归并排序和基数排序在不同情况下都是最快最有用的。
十七、频繁的插入刪除操作使用什么结构比较合适,链表还是数组?
链表。
十八、 *p=NULL; *p= new charl[100]; sizeof§为多少?
都为 4。因为都是指针类型,所占存储空间必然为 4。
十九、不能做 switch()的参数类型是?
switch 的参数不能为浮点型。
二十、不使用其他变里,交换两个整型 a,b 的值?
a=a+b;
b=a-b;
a=a-b;
二十一、IP 地址的编码分为哪俩部分?
主机号和网络号,不过是要和子网掩码按位与上之后才能区分哪些是网络位哪些是主机位。
二十一、 Internet 采用哪种网络协议?该协议的主要层次结构?
TCP协议。
应用层、传输层、网络层、数据链路层、物理层。
二十二、 Internet 物理地址和IP 地址转换采用什么协议?
地址解析协议ARP( address resolution protocol)
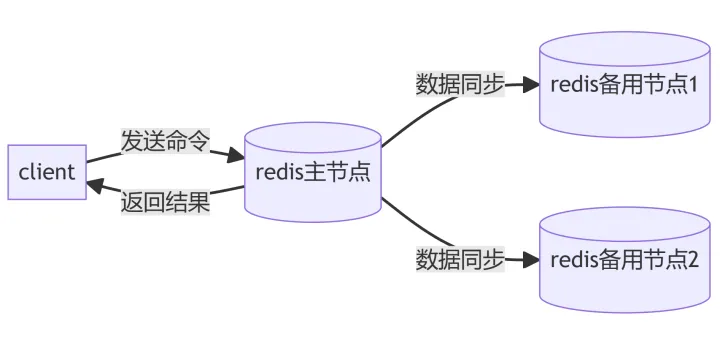
二十三、 redis 的主从复制怎么做的?
主从复制主要用来实现 redis 数据的可靠性;防止主 redis 所在磁盘损坏 或redis宕机,造成数据永久丢失。
主从复制是高可用的基础。
redis通常是一主二从的备份方式,而且是在不同的机器中,即异地备份。对于redis而言,是由备份节点连接主节点,而且由备份节点从主节点拉取数据。
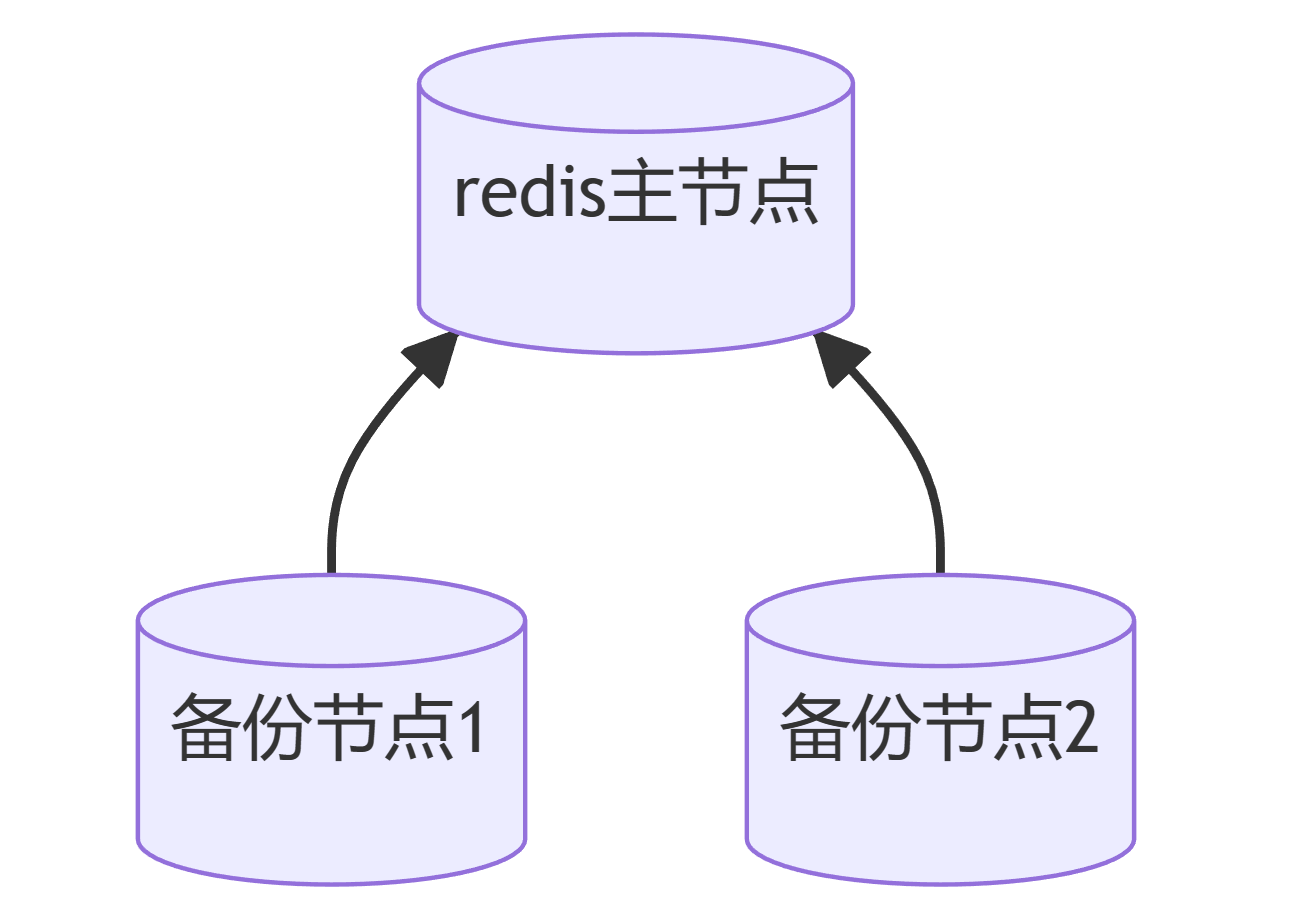
也就是,redis是采用异步复制的方式,因为redis要提供高效的key-value存储。
所说的数据同步主要是rdb的数据同步,也就是内存的二进制数据。
23.1、命令
命令:
redis-server --replicaof 127.0.0.1 7001
在 redis 5.0 以前使用 slaveof ;redis 5.0 之后使用replicaof。
# redis.conf
replicaof 127.0.0.1 7002
info replication
2、同步复制和异步复制
(1)同步复制。向redis发送命令时不能立即返回,而是要等redis将数据同步到备份节点后才返回。
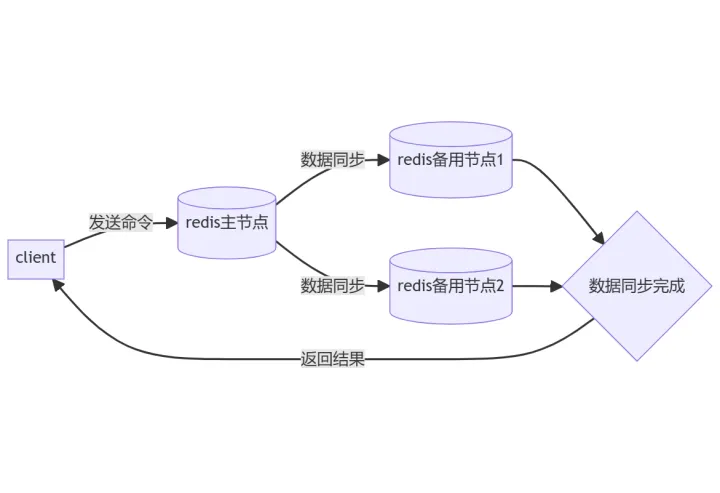
(2)异步复制。向redis发送命令立即返回结果,redis内部将数据写到堆积缓冲区中,redis备份节点会发送offset到主节点;如果offset存在,就根据offset把数据同步到备用节点。这个过程是异步的,和命令没有关系。
注意,分布式一致性中,半数以上节点数据同步成功就算数据同步完成。比如raft一致性。
异步数据的缺点就是存在数据丢失风险。比如主节点宕机了,堆积缓冲区还有数据没有同步到备用节点,这部分数据就丢失了。这样就使得主从之间存在一段时间的数据差异,而且数据差异是不可逆的。
异步复制有全量数据同步和增量数据同步。
(1)全量数据同步:直接把主数据库的全部rdb文件(即整个内存中所有的数据)都同步过来。
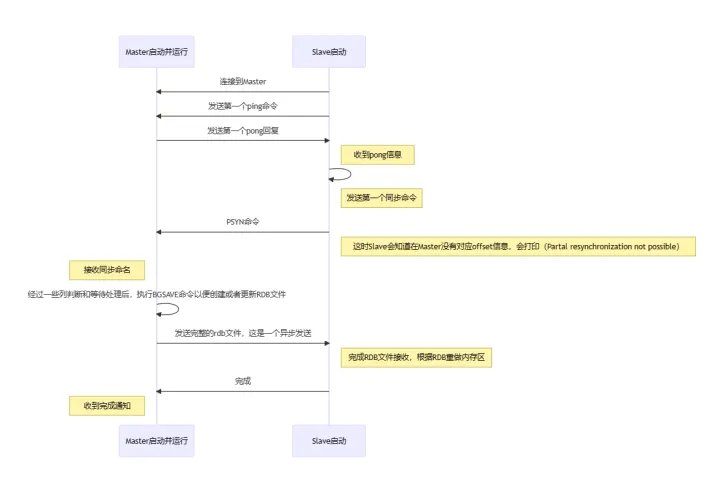
(2)增量数据同步:从数据库会记录一个偏移量offset(即记录同步到哪里了),如果offset在环形缓冲区当中,从数据库就会将offset后面的那部分数据同步过了;如果offset不在环形缓存区中,就会全量同步,把主数据库内部所有数据都同步过来。
23.3、原理
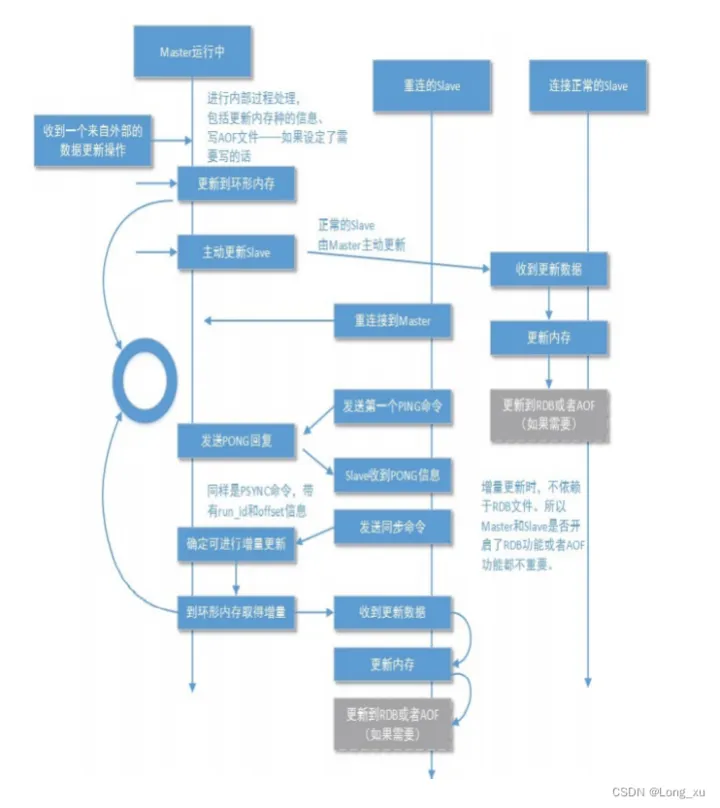
主从复制主要由环形缓冲区、复制偏移量、RUN ID三个部分组成。
(1)RUNID用于构建主从的关系,无论主库还是从库都有自己的 RUNID,RUNID 启动时自动产生,RUNID 由 40 个随机的十六进制字符组成;当从库对主库初次复制时,主库将自身的 RUNID 传送给从库,从库会将 RUNID 保存;当从库断线重连主库时,从库将向主库发送之前保存的 RUNID。
从数据库同步的时候,先发送RUNID,验证自己是否是目标的从数据库; 如果是就开始同步;如果不是就同步主数据的RUNID,然后把自己的数据丢失,再去拉取主数据库的所有数据。
(2)环形缓冲区(复制积压缓冲区)本质是固定长度先进先出队列。环形缓冲区决定是全量数据同步还是增量数据同步。使用环形是为了防止数据的遗漏,同时避免数据移动和能覆盖过旧的数据。
(3)主从都会维护一个复制偏移量。从数据库使用偏移量和环形缓冲区验证,如果offset在环形缓冲区当中,增量数据同步;如果offset不在环形缓存区中,全量数据同步。
(4)主从复制不能保证高可用,只解决了单点故障问题。