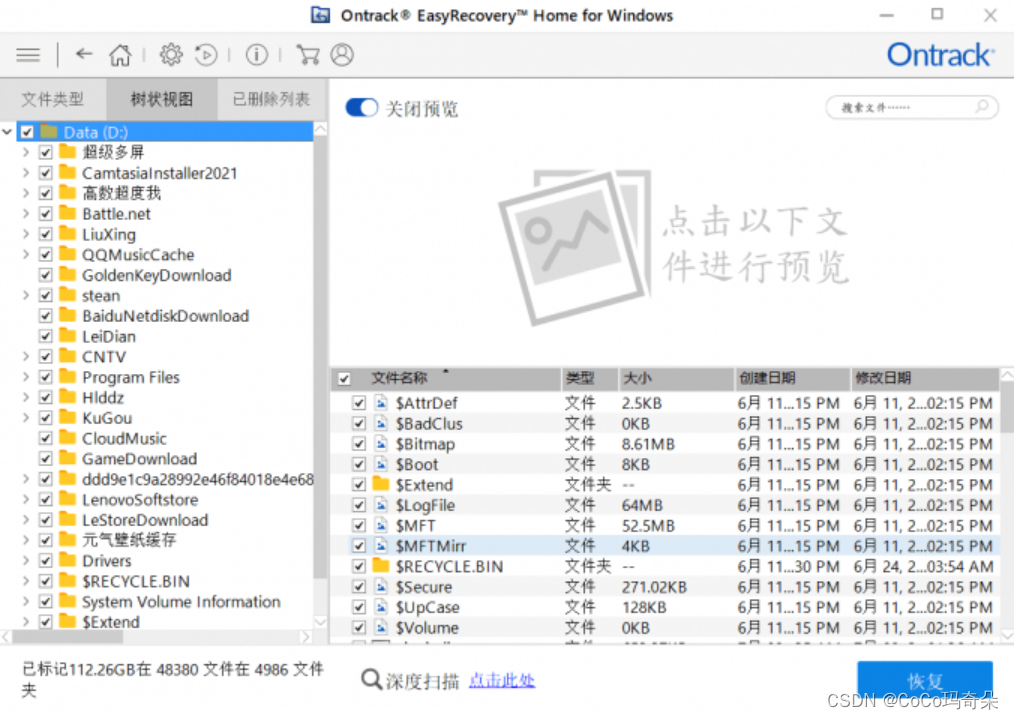
例子引入
值得注意的是,之前学习的 状态值和动作值 实际上都是以表格的形式表示的,他的好处是便于直观理解与分析,但缺点是难以处理大量的数据的或连续的状态或行动空间,表现在存储和泛化能力两个方面。如下:

为了解决上述的两个问题,我们引进值函数近似。我们通过一个例子来介绍一下值函数近视的基本的思想。假设存在一维状态空间
S
=
s
1
,
s
2
,
.
.
.
,
s
n
S={s_1, s_2, ..., s_n}
S=s1,s2,...,sn,其中 n 为非常大的数量。对于每个状态
s
i
s_i
si,在策略
π
π
π 下有一个对应的状态值
v
π
(
s
i
)
v_π(s_i)
vπ(si) ,由于数量较大,因此我们可以考虑用函数的形式将这些点统一表达出来,因为函数涉及的参数较少。

首先,我们使用最简单的直线来拟合这些点,假设直线的方程为
v
^
(
s
,
w
)
=
a
s
+
b
\hat v(s,w)=as+b
v^(s,w)=as+b ,也可以写成矩阵的形式,
w
w
w 是参数向量,
ϕ
(
s
)
\phi(s)
ϕ(s) 是状态
s
s
s 的特征向量,如下:

我们知道,如果用表格表示需要存储
n
n
n 个状态值。而现在,我们只需要存储两个参数
a
a
a 和
b
b
b。每次我们使用状态
s
s
s 的状态值就可以通过
ϕ
T
(
s
)
w
\phi^T(s)w
ϕT(s)w 计算得到
v
^
\hat v
v^。但这样就带来一个问题就是可能并不能准确表示状态值,这就是为什么被称为值近似的原因。
.
直线拟合准确度不够,那么我们可以使用更高阶的曲线函数,好处是可以更好地拟合。缺点是需要更多的参数。我们以二阶为例,如下:

在这种情况下, w w w 和 ϕ ( s ) \phi(s) ϕ(s) 的维度增加,拟合的精度提高;但值得注意的是, v ^ ( s , w ) \hat v(s, w) v^(s,w) 对于 s s s 是非线性的,但对于 w w w 是线性的,因为非线性部分包含在中了 ϕ ( s ) \phi(s) ϕ(s) 中。
值函数近似原理与目标函数
接下来,我们正式介绍值函数近似原理:设
v
π
(
s
)
v_π(s)
vπ(s) 代表真实的状态值,
v
^
(
s
,
w
)
\hat v(s, w)
v^(s,w) 是用于近似的函数。我们的目标是找到一个最佳的参数
w
w
w,使得
v
^
(
s
,
w
)
\hat v(s, w)
v^(s,w) 能够在所有状态
s
s
s 上更好地近似
v
π
(
s
)
v_π(s)
vπ(s) 。这个问题可以看作是策略评估,我们的目标是评估在给定策略下的状态值。随后,我们将扩展到策略改进。为了找到最优的
w
w
w,我们需要进行两个步骤:
定义目标函数:我们需要建立一个衡量
v
^
(
s
,
w
)
\hat v(s, w)
v^(s,w) 与
v
π
(
s
)
v_π(s)
vπ(s) 的近似好坏的度量标准,数量化近似值与真实值之间的误差。
推导优化目标函数的算法:一旦我们定义了目标函数,我们可以开发算法,通过迭代更新参数
w
w
w 来改进对
v
π
(
s
)
v_π(s)
vπ(s) 的近似,最小化误差。
.
我们定义的目标函数如下:

我们的目标是找到最佳的
w
w
w 能够最小化
J
(
w
)
J(w)
J(w) 。其中,期望是针对随机变量
s
∈
S
s∈S
s∈S 进行的。那么 S 的概率分布是什么?定义状态的概率分布有几种方法。
第一种是非常直观也最容易想到的,平均分布。通过设置每种状态的概率为 1 / n 1/n 1/n , ∣ S ∣ = n |S|=n ∣S∣=n,在这种情况下,目标函数为:

这也的缺点也是明显的,因为各个状态可能并不同等重要。例如,某些状态可能很少被策略访问到。因此,这种方式并没有考虑给定策略下马尔可夫过程的实际动态。状态的重要性可以通过其在马尔可夫过程中的访问频率来衡量。如果某个状态很少被访问,那么它对期望值的贡献可能较小。因此,在计算期望时,我们应该考虑状态的访问概率。这意味着我们需要根据给定策略下的马尔可夫链的转移概率来定义状态的概率分布。这样,我们可以根据状态的访问概率对期望进行加权,以更准确地反映真实动态。换句话说,我们需要考虑给定策略下的状态转移概率,以确定状态的实际分布,从而更准确地计算期望值。
.
因此,第二种方法是稳定分布(Stationary distribution)。稳定分布是指在马尔可夫链中,当经过足够长的时间后,状态的概率分布保持不变的分布。设
{
d
π
(
s
)
}
s
∈
S
{\{d_π(s)}\}_{s∈S}
{dπ(s)}s∈S 表示在策略
π
π
π 下的马尔可夫过程的稳定分布。根据定义,
d
π
(
s
)
≥
0
d_π(s)≥0
dπ(s)≥0,并且
∑
s
∈
S
d
π
(
s
)
=
1
\sum _{s∈S}d_π(s) = 1
∑s∈Sdπ(s)=1 ,在这种情况下,目标函数为:

这个函数是一个加权平方误差函数。由于经常访问的状态具有较高的 d π ( s ) d_π(s) dπ(s)值,所以它们在目标函数中的权重也比很少访问的状态高。这种加权的设计可以使得函数更加关注那些经常出现的状态,因为它们对系统的整体性能有更大的影响。而对于很少访问的状态,由于它们的权重较低,它们对目标函数的贡献较小。通过加权平方误差的方式,考虑了不同状态的访问频率,使得经常访问的状态在目标函数中具有更高的权重,从而更加准确地反映系统的性能。
.
我们通过一个例子来进行理解。我们给定一个策略 ,然后设置一个很长的 episode 去访问每个状态,按照如下公式计算:

最后的到的结果如下:

实际上,我们不用跑很多次仍然可以得到与理论值相近似的值,推导如下:

P
π
P_π
Pπ是状态转移概率,
P
π
=
P
(
s
′
∣
s
)
P_π=P(s'|s)
Pπ=P(s′∣s),在上面例子中,
P
π
P_π
Pπ 如下:

因此,可以计算出一个特征值的特征向量:

.
优化目标函数算法
提到优化,我们第一反应应该是梯度方法,因此我们很容易得到以下公式:

我们发现 求梯度 公式中需要计算一个期望,我们怎么样去避免呢?在实际当中我们是用随机梯度来代替求期望,得到的公式如下:

但上述这个算法并不可实现,因为它需要未知的真实状态值
v
π
v_π
vπ 进行估计,而
v
π
v_π
vπ 正是我们需要计算的,因此,我们可以用近似值替代
v
π
(
s
t
)
v_π(s_t)
vπ(st) 。我们有两种方法:
第一,使用MC 算法。设
g
t
g_t
gt 为在 episode 中从状态
s
t
s_t
st 开始的折扣回报。然后,我们可以使用
g
t
g_t
gt 来近似估计
v
π
(
s
t
)
v_π(s_t)
vπ(st) 。算法如下:

第二,使用 TD-learning 算法。将 r t + 1 + γ v ^ ( s t + 1 , w t ) r_{t+1} + γ \hat v(s_{t+1}, w_t) rt+1+γv^(st+1,wt) 作为 v π ( s t ) v_π(s_t) vπ(st) 的近似值,算法如下:


v ^ \hat v v^ 的选取
前面,我们用一个函数
v
^
\hat v
v^ 去逼近
v
π
v_π
vπ ,那么
v
^
\hat v
v^ 要怎么去选取合适呢? 基本上有两种方法:
第一种方法是使用线性方法,这是以前广泛使用的方法:

第二种方法是现在广泛使用的将神经网络作为一种非线性函数
。
例子分析
我们以一个 5x5 的网格世界为例,
r
f
o
r
b
i
d
d
e
n
=
r
b
o
u
n
d
a
r
y
=
−
1
r_{forbidden} = r_{boundary} = -1
rforbidden=rboundary=−1、
r
t
a
r
g
e
t
=
1
r_{target} = 1
rtarget=1,以及
γ
=
0.9
γ = 0.9
γ=0.9
首先,我们给定一个策略: 对于任何
(
s
,
a
)
(s,a)
(s,a) ,都有
π
(
a
∣
s
)
=
0.2
π(a|s)= 0.2
π(a∣s)=0.2
我们的目标是评估这个策略的状态值(策略评估问题),那么总共有25个状态值,接下来我们将展示可以使用少于25个参数来近似这些状态值。

根据给定的策略得到 500 条 episode 每条有500步,并且随机选择一个 状态-动作 开始,服从均匀分布。
首先,我们计算基于表格形式的 TD 算法,结果如下:

下面我们来看一下TD-L inear 是不是也能很好地去估计出来 state value呢?首先,我们选择特征向量,得到表达式,如下:

结果如下:

可以发现,得到的趋势是正确的,因此我们可以用更高阶的曲面来拟合。首先,我们选择特征向量,得到表达式,如下:

结果如下:

.
Sarsa + 值函数近似
将
v
^
\hat v
v^ 换成
q
^
\hat q
q^ ,得到具有数值函数逼近的Sarsa算法,如下:

实际上,上述算法是在做 策略评估,为了得到最优策略,我们可以将策略评估和优化策略结合,其伪代码如下:

Q-learning+ 值函数近似
相比与 Sarsa ,将
q
^
(
s
t
+
1
,
a
t
+
1
,
w
t
)
\hat q(s_{t+1},a_{t+1},w_t)
q^(st+1,at+1,wt) 换成
m
a
x
a
∈
A
(
s
t
+
1
)
q
^
(
s
t
+
1
,
a
t
+
1
,
w
t
)
max_{a∈A(s_{t+1})}\hat q(s_{t+1},a_{t+1},w_t)
maxa∈A(st+1)q^(st+1,at+1,wt) ,得到具有数值函数逼近的Q-learning 算法,如下:

on-policy 其伪代码如下:

Deep Q-learning
Deep Q-learning or deep Q-network (DQN) 是最成功的把深度神经网络引入到强化学习的一个算法。其中,神经网络的作用类似于非线性函数。其目标函数如下:

这实际上是Bellman 最优方程的误差,因为
R
+
γ
m
a
x
a
∈
A
(
s
′
)
q
ˉ
(
s
′
,
a
,
w
)
−
q
ˉ
(
S
,
A
,
w
)
R+γmax_{a∈A(s')}\bar q(s',a,w)-\bar q(S,A,w)
R+γmaxa∈A(s′)qˉ(s′,a,w)−qˉ(S,A,w) 的值应为零。

有了目标函数,那么接下来就是优化函数了——梯度下降!如何计算目标函数的梯度?但有一个问题目标函数两部分都包含有参数
w
w
w ,如下:

Deep Q-learning 的解决方法是将
R
+
γ
m
a
x
a
∈
A
(
s
′
)
q
ˉ
(
s
′
,
a
,
w
)
R+γmax_{a∈A(s')}\bar q(s',a,w)
R+γmaxa∈A(s′)qˉ(s′,a,w) 赋值给
y
y
y ,
y
y
y 含有
w
w
w ,然后假设
y
y
y 里边的
w
w
w 是一个常数。如下:

那么,目标函数
J
(
w
)
J(w)
J(w) 就只是一个
w
w
w 了,再去求解它的梯度就会相对简单一些,接下来我们来看一下具体的做法。为了实现这个技巧在 DeepQ-learning 当中引入了两个 network,第一个 network 就是叫 main network 对应的是
q
^
(
s
,
a
,
w
)
\hat q(s,a,w)
q^(s,a,w) 它的参数是
w
w
w ;第二个 network 是 target network ,对应的是
q
^
(
s
,
a
,
w
T
)
\hat q(s,a,w_T)
q^(s,a,wT) ,参数是
w
T
w_T
wT 下标 T 就代表 target 。这个main network实际上它的
w
w
w 一直在被更新,也就是有新的采样进来的时候
w
w
w 就会更新,但是target network它不是一直更新的,它是隔一段时间之后会把main network 的
w
w
w 给赋值给赋过来。得到的式子如下:

先假设
w
T
w_T
wT 是固定不动的,然后来计算对
w
w
w 的梯度然后我再去优化
J
J
J 。假设
w
T
w_T
wT 是固定不动,可能会觉得这是想不通的。但是这里面的逻辑是假设有一个
w
T
w_T
wT 是保持不动的,然后我可以去更新
w
w
w ,更新了一段时间,再继续更新这个
w
T
w_T
wT ,所以最后
w
T
w_T
wT 和
w
w
w 都能够收敛到最优的值。那么,很容易得到其梯度公式:

以上就是 Deep Q-learning 的基本思想:使用梯度下降算法来最小化目标函数。 Deep Q-learning 的优化过程不仅引入两个network,还有就是经验回放。
那么,经验回放是上什么呢?在收集经验样本之后,我们不会按照它们收集的顺序来使用这些样本,因为我们将它们存储在一个集合中,称为 回放缓冲区 replay buffer B = { ( s , a , r , s ′ ) } B = {\{(s, a, r, s')}\} B={(s,a,r,s′)} 每当我们训练神经网络时,我们就从回冲区中随机抽取一小批样本进行训练。抽取样本的过程称之为经验回放,而且抽取应该遵循均匀分布。遵循均匀分布的原因如下:

R
:
p
(
R
∣
S
,
A
)
R:p(R|S,A)
R:p(R∣S,A),
S
′
:
p
(
S
′
l
S
,
A
)
S' : p(S'lS,A)
S′:p(S′lS,A),
R
R
R 和
S
′
S'
S′ 的概率分布是由系统模型决定的。我们这里面把
(
S
,
A
)
(S, A)
(S,A) 当成一个索引,因为可以表示出是哪个状态采取的哪个行为,所以将
(
S
,
A
)
(S,A)
(S,A) 看作是一个单随机变量,假设服从的分布为
(
S
,
A
)
:
d
(S,A) :d
(S,A):d ,
d
d
d 是什么分布呢?我们来讨论一下:
有一个问题是,在数学上要求
(
S
,
A
)
(S,A)
(S,A) 是均匀分布,但是采集数据的时候一定是有先后顺序的,并且是按照其它的概率分布采集的。我们的方法是把所有的样本混合,打破续样本之间的相关性,然后一视同仁的均匀地进行采样。
.
我们现在给出 Deep Q-learning 的 off-policy 版本的伪代码:

因为是 off-policy ,我们假设已经有了一个行为策略
π
b
π_b
πb ,基于这个策略我们采样得到很大样本,把这些样本放在一个集合当作为 replay buffer。第一步,从 replay buffer 当中随机地均匀地采样;第二步是根据这些采样将
(
s
,
a
)
(s, a)
(s,a) 输入神经网络计算得到
y
T
y_T
yT ;第三步就是把
(
s
,
a
,
y
T
)
(s, a,y_T)
(s,a,yT) 这一批的数据全部输入 到神经网络里面去训练,去更新 main network 的 参数
w
w
w ;第四不重复上面步骤,循环
C
C
C 次后把
w
w
w 的值赋给
w
T
w_T
wT 就更新
w
T
w_T
wT 。
Deep Q-learning 实例分析
我们的目标是找到所有 ( s , a ) (s,a) (s,a) 所对应的最优 action value。得到了最优的 action value 的估计值后,那么 optima| greedy policy 就立刻就能得到了。
案例数据:
1、只用一个 episode 来训练Deep Q-learning
2、这个episode是由一个探索性的 behavior policy所得到的,每个 action 的概率都是相同,都是 0.2。
3、这个 episode 只有 1000 步,相对来说数据量是比较少的
4、用到的的神经网络是一个浅层的神经网络 ,隐藏层只有100 个神经元
得到的结果如下: