目录
1、Introduction
2、Related works
2.1 Named entity recognition
2.2 Relation classification
2.3 Joint entity and relation extraction
2.4 LSTM and CNN models On NLP
3、Our method
3.1 Bidirectional LSTM encoding layer
3.2 Named entity recogniton (NER) module (解码NER)
3.3 Relation classification (RC) module
3.4 Training and implementation
4 Experiment
4.1 Experimental setting
4.2 Result
5、Analysis and discussion
5.1 Analysis of named entity recognition module
5.2 Analysis of relation classification module
5.3 The effect of two entities' distance
5.4 Error analysis
6、Conclusion
摘要:
实体和关系提取是一项结合了检测实体提及和从非结构化文本中识别实体语义关系的任务。文中提出了一种混合神经网络模型来提取实体提及及其关系,而无需任何手工制作的特征。该混合神经网络包含用于实体提取的新型双向编码器-解码器LSTM模块(BiLSTM-ED)和用于关系分类的CNN模块。BiLSTM-ED中获得的实体的上下文信息进一步传递到CNN模块改进关系分类。我们在公共数据集ACE05(自动内容提取程序)上进行实验来验证我们方法的有效性。我们提取的方法在实体和关系提取任务上取得了最先进的结果。
1、Introduction
实体和关系提取是检测实体提及并从文本中识别它们的语义关系。它是知识抽取中的一个重要问题,对于知识库的自动构建起着至关重要的作用。
传统系统将此任务视为两个独立任务的管道,即命名实体识别(NER)[1]和关系分类(RC)[2]。这种分离的框架使得任务很容易处理,并且每个组件都可以更加灵活。但它很少关注两个子任务的相关性。联合学习框架是关联 NER 和 RC 的有效方法,也可以避免级联错误 [3]。然而,大多数现有的联合方法都是基于特征的结构化系统[3-7]。他们需要复杂的特征工程,并且严重依赖有监督的 NLP 工具包,这也可能导致错误传播。为了减少特征提取中的手工工作,最近,Miwa 和 Bansal [8] 提出了一种基于神经网络的端到端实体和关系提取方法。然而,在检测实体时,他们使用神经网络结构来预测实体标签,忽略了标签之间的长关系。(建议学习一下文献8)
基于上述分析,我们提出了一种混合神经网络模型来解决这些问题,其中包含命名实体识别(NER)模块和关系分类(RC)模块。 NER 和 RC 共享相同的双向 LSTM 编码层,该层用于通过考虑单词两侧的上下文来对每个输入单词进行编码。虽然双向 LSTM 可以捕获单词之间的长距离交互,但每个输出实体标签都是独立预测的。因此,我们还采用 LSTM 结构来显式地建模标签交互。与NN解码方式相比,它可以捕获标签之间的长距离关系[8]。对于关系分类,两个实体之间的子句已被证明可以有效地反映实体关系[9,10]。此外,双向LSTM编码层可以获得实体的上下文信息,这也有利于识别实体之间的关系。因此,我们采用在关系提取方面取得巨大成功的CNN模型,根据实体的编码信息和子句信息来提取关系。
与经典的管道方法相比,我们的模型不仅考虑了NER模块和RC模块的相关性,而且与现有的联合学习方法相比,还考虑了实体标签之间的长距离关系,并且无需复杂的特征工程。我们在公共数据集 ACE05(自动内容提取程序,Information Technology Laboratory | NIST)上进行了实验。我们的方法在实体和关系提取任务上取得了最先进的结果。此外,我们还单独分析了两个模块的性能。在实体检测任务上,我们的NER模块与不同类型的LSTM结构相比实现了2%的改进,这验证了NER模块的有效性。在关系分类任务上,它表明在编码过程中获得的实体上下文信息可以提高关系分类的准确性。
在本文的其余结构如下。在第二节中,我们回顾了本文中使用的命名实体识别、关系分类和神经网络的相关工作。第 3 节详细介绍了我们的混合神经网络。在第 4 节中,我们描述了实验设置的详细信息并展示了实验结果。最后,我们分析第 5 节中的模型并在第 6 节中得出结论。
2、Related works
章节综述:
实体和关系提取是构建知识库的重要步骤,这对于许多 NLP 任务 [11] 和社交媒体分析任务 [12,13] 有益。解决实体及其关系的提取问题主要有两种框架:管道方法和联合学习模型。管道方法将此任务视为两个独立任务的管道,即命名实体识别(NER)[14-17]和关系分类(RC)[2,9,10,18,19]。联合模型同时提取实体和关系。因此,在本文中,我们关注的问题与命名实体识别、关系分类以及联合实体和关系提取有关。我们使用的方法与长短期记忆网络(LSTM)和卷积神经网络(CNN)有关。
2.1 Named entity recognition
此段描述NER的相关工作,点出其属于经典NLP任务,并且传统是都是线性的统计模型,如HMM,CRF等。线性统计模型在一定程度上依赖NLP工具和外部知识资源提取的手工特征。紧接着又描述了神经网络在NER任务中的应用情况。
文献21,CNN+CRF;
文献15,通过学习字符级和单词级特征提取一种混合模型;
文献16,17,22 提出了一个BiLSTM和一个CRF的联合标签解码。
文献8 提出一种用于编码的BiLSTM和一个用于联合解码标签的单一增量神经网络结构。
上述RNN模型均采用BiLSTM作为编码模型,但解码方式不同。
2.2 Relation classification
关系分类是NLP界广泛研究的任务。已经提出了各种方法来完成该任务。现有的关系分类方法可分为基于手工特征的方法【2,23】,基于神经网络的方法【19,24-27】和其他有价值的方法【25,28】。
基于手工制作特征的方法侧重于使用不同的自然语言处理NLP工具和知识资源来获得有效的手工制作特征。Kambhatla [23] 采用最大熵模型来结合从文本中得出的各种词汇、句法和语义特征。这是关系分类的早期工作。他们使用的功能并不全面。Rink [2]设计了16种特征,使用许多有监督的NLP工具包和资源(包括POS、WordNet、依存解析等)提取。与其他基于手工特征的方法相比,它可以在SemEval2010 Task 8中获得最佳结果。然而,它严重依赖其他 NLP 工具,并且还需要大量的工作来设计和提取特征。
近年来,深度神经模型在关系分类任务中取得了重大进展。这些模型可以从给定的句子中学习有效的关系特征,而无需复杂的特征工程。此任务中应用的最常见的基于神经网络的模型是卷积神经网络(CNN)[18,19,27,29,30]和顺序(序列)神经网络,例如递归神经网络(RNN)[31]、递归神经网络(RecNN) [24,32]和长短期记忆网络(LSTM)[26,33]。还存在其他有价值的方法,例如基于核的方法[28,34]和组合模型[25]。 Nguyen 等人 [28] 探索使用基于句法和语义结构的创新内核来完成任务,Sun 和 Han [34] 提出了一种新的树内核,称为特征丰富树内核(FTK),用于关系提取。组合模型 FCM [25] 学习带注释的句子的子结构的表示。与现有的组合模型相比,FCM 可以轻松处理任意类型的输入和全局信息进行组合。
2.3 Joint entity and relation extraction
虽然流水线方法(pipeline method)可以更灵活地设计系统,但它忽略了子任务的相关性,也可能导致错误传播[3]。大多数现有的联合方法都是基于特征的结构化系统[3,4,35-37],需要复杂的特征工程。 [35,36]提出了一种联合模型,利用子任务的最优结果并寻求全局最优解。 Singh 等人[37]提出了一个单一的联合图形模型,表示子任务之间的各种依赖关系。 Li和Ji [3]提出了第一个使用单一联合模型增量预测实体和关系的模型,这是一种具有高效波束搜索的结构化感知器。 Miwa和Sasaki[4]引入了一个表(表结构)来表示句子中的实体和关系结构,并提出了一种基于历史的集束搜索结构化学习模型。最近,Miwa 和 Bansal [8] 使用基于 LSTM 的模型来提取实体和关系,这可以减少手动工作。
2.4 LSTM and CNN models On NLP
本文使用的方法基于神经网络模型:卷积神经网络CNN和长短期记忆LSTM。CNN最初是为计算视觉而发明的【38】,它总是被用来提取图像的特征【39,40】
近年来,CNN已成功应用于不同的NLP任务,并且在提取句子语义和关键词信息方法也显示出了有效性【27,41-43】。长短期记忆LSTM模型是一种特殊的循环神经网络RNN。LSTM用利用装置门的记忆存储块取代了RNN的隐藏向量。它可以通过训练适当的门权重来保持长期记忆【44,45】。LSTM在许多NLP任务上也表现出了强大的能力,例如机器翻译【46】,句子表示【47】和关系提取【26】。
在本文中,我们提出了一种基于联合学习实体及其关系的混合神经网络。与手工制作的基于特征的方法相比,它可以从给定的句子中学习相关特征,而无需复杂的特征工程工作。与其他基于神经网络的方法[8]相比,我们的方法考虑了实体标签之间的长距离关系。
3、Our method
混合神经网络的框架如图1所示。混合神经网络的第一层是双向LSTM编码层,由命名实体识别NER模块和关系分类RC模块共享。编码层之后有两个通道一个链接到NER模块(LSTM解码层),另一个输入CNN层以提取关系。在以下部分中,将详细描述.

3.1 Bidirectional LSTM encoding layer
本节通用知识描述
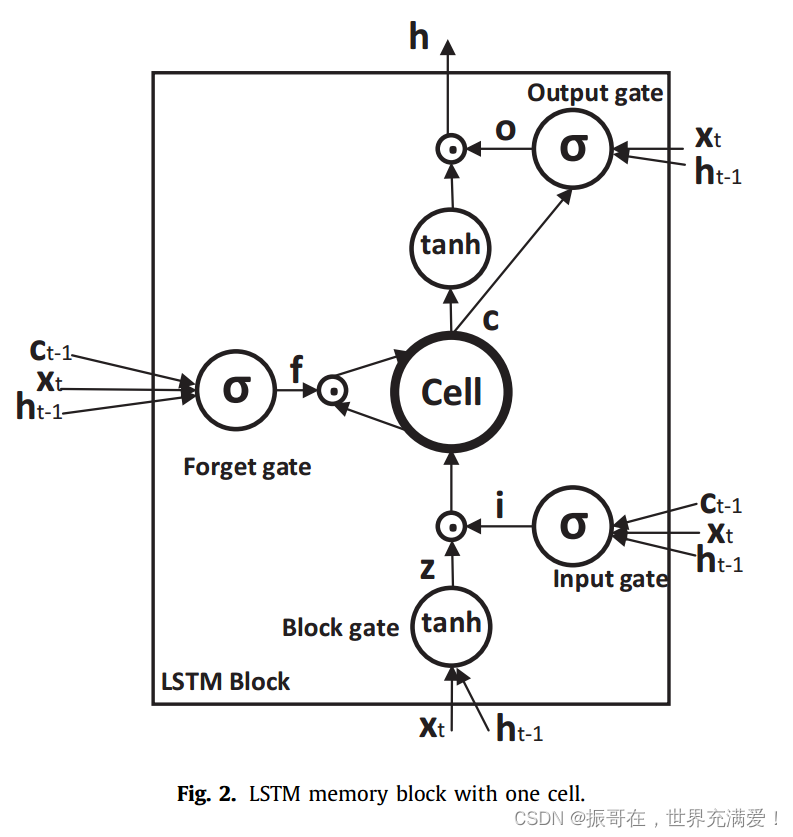
3.2 Named entity recogniton (NER) module (解码NER)
每个单词都会被分配一个实体标签。标签常用的编码方案为:BILOS(Begin, Inside, Last, Outside, Single)[22,48]。每个标签包含一个词在实体中的位置信息。

针对该部分的核心描述:解码LSTM(LSTM Decode)的每个单元除了输入门之外都与编码LSTM记忆块相同,可以重写为:


3.3 Relation classification (RC) module
在识别实体的语义关系时,我们将实体的编码信息和实体之间的字句合并,然后将它们输入到CNN模块中【49】。
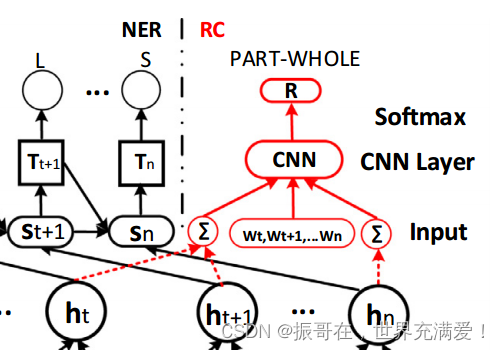
关系分类模块的核心就是CNN(卷积运算),利用CNN和Softmax来获取最后的关系。唯一比较明显的地方就是输入层(Input),将BiLSTM的结果和句子向量进行进行拼接,如上图中两个Sum和之间Wt...
![]()
其中,R是关系标签,he是实体的编码信息,w是词嵌入。特别地,一个实体可能包含两个或多个单词,文中将这些单词的编码信息相加来表示整个实体信息。如下图3:
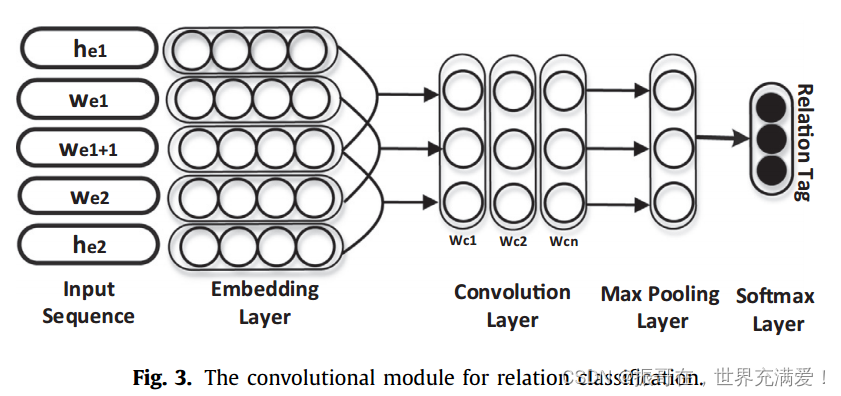
下面主要是描述CNN卷积操作的公式和softmax的应用。
3.4 Training and implementation
文中训练模型以最大化数据的对数似然,使用的优化方法是Hinton在【52】中提出的RMSprop。NER模块的目标函数定义:
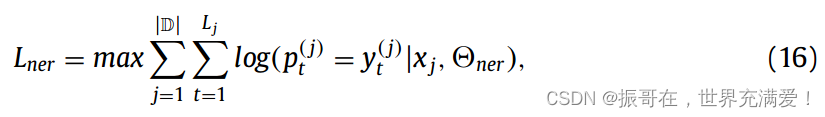
其中|D|是数据集的大小,L_j是句子x_j的长度,y(j)_t 是句子x_j 中单词t的标签,p(j)_t 是公式10中定义的归一化实体标签概率。
RC模块的目标函数是:
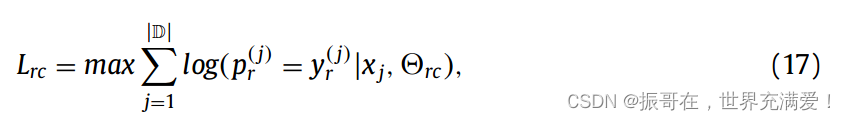
我们首先训练NER模块来识别实体并获取实体的编码信息,然后进一步训练RC模块根据编码信息和实体组合对关系进行分类。
特别地,发现两个实体之间存在关系,两个实体的距离总是小于约20个词,如图4所示。因此,在确定两个实体之间的关系时,文中也充分考虑利用这个性质,如果两个实体的距离大于Lmax,就认为它们之间不存在关系。根据图4的统计结果,ACE05数据集中的Lmax约为20.

4 Experiment
4.1 Experimental setting
数据集:ACE05
文中使用公共数据集ACE05进行实体和关系提取,其中包含6中粗粒度关系类型和一个附加的“other”关系来表示非实体或非关系类。The 6 coarse-grained relation types are “ART (artifact)”, “GA (Gen-affiliation)”, “O-A (Org-affiliation)”, “P-W (PART-WHOLE)”,
“P-S (person-social)” and “PHYS (physical)”.
具有相反方向的相同关系类型被认为是两个类。例如,“PART-WHOLE (e1,e2)”和“PART-WHOLE(e2,e1)”是不同的关系。 “PART-WHOLE(e1,e2)”表示e1是e2的一部分,“PART-WHOLE(e2,e1)”表示e1包含e2。因此,总共有 13 个关系类。实验中的数据预处理和设置与[文献3]相同。
Baselines. 文中使用的基线是ACE05数据集的最新方法,其中包括经典管道模型【文献3】、称为joint w/Global 【文献3】的基于联合特征的模型,以及端到端NN的模型SPTree【文献8】。
pipeline(CRF+ME)【3】训练了用于实体提及提取的线性链条件随机场【53】和用于关系提取的最大熵模型【54】。这是该任务的经典管道方法。
Joint w/Global【3】联合使用单个模型逐步提取实体提及和关系。他们开发了许多新的、有效的全局特征作为软约束,以捕获实体提及和关系之间的相互依赖关系。
SPTree[8] 提出了一种新颖的端到端关系提取模型,该模型通过使用双向顺序和双向树结构LSTM-RNN来表示单词序列和依存树结构。
Metric,为了将我们的模型与基线比价,我们在联合实体和关系提取的任务中使用精度P,召回率R和F-Measure F1。当一个关系实例的关系类型和两个对应实体的头部偏移量都正确时,该关系实例被认为是正确的。
Hyper parameters。在本文中提出了一种混合神经网络来提取实体及其关系。模型中使用的超参数总结如下表:

4.2 Result
测试集上的预测结果如表2所示。文中的方法实现了52.1%的F1,这是与现有方法相比的最好结果。它说明了我们提出的混合神经网络在联合提取实体及其关系的任务上的有效性。
此外,联合全局[3]方法优于流水线方法,并且基于神经网络的方法(SPTree[8]和我们的模型)可以比这些基于特征的方法[3]获得更高的F1结果。这表明神经网络模型结合联合学习方式是提取实体及其关系的可行方法。
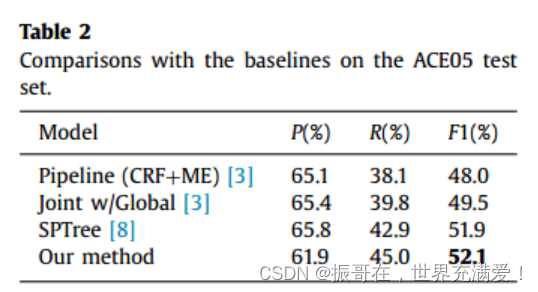
特别地,这些方法的精度结果相似,差异主要集中在召回率结果上。文中的方法可以平衡精度和召回率,从而获得更好的F1值。
5、Analysis and discussion
5.1 Analysis of named entity recognition module
NER模块包含双向LSTM编码层和LSTM解码层。文中使用BiLSTM-ED来表示NER模块的结构。为了进一步说明BiLSTM-ED在实体提取任务上的有效性,文中将BiLSTM-ED与其不同变体和其他有效的序列标记模型进行比较。对比方法如下:
Forward-LSTM
Backward-LSTM
BiLSTM-NN
BiLSTM-NN-2
CRF
文中使用标准 F1 来评估这些方法的性能,并在实体的类型和头部区域正确时将其视为正确的实体。表3显示了上述方法在名称实体识别任务上的结果。与Forward-LSTM和Backward-LSTM相比,双向LSTM编码方式可以有显着的改进。与 ui-LSTM 编码相比,Bi-LSTM 编码考虑了整个句子信息,因此在标注任务中可以获得更高的准确率。 BiLSTM-NN-2优于BiLST-NN,这说明需要考虑标签之间的关系。此外,BiLSTM-ED 比 BiLSTM-NN-2 更好,这意味着考虑标签之间的长距离关系比仅考虑相邻标签信息更好。我们还将 BiLSTM-ED 与著名的 CRF 序列模型进行了比较。结果也显示了 BiLSTM-ED 的有效性。
5.2 Analysis of relation classification module
在关系分类模块中,使用两种信息:实体之间的句子和从双向LSTM层获得实体的编码信息。为了说明文中考虑的这些信息的有效性,文中将其方法与其不同的变体进行比较。首先使用NER模块来检测句子中的实体,然后使用步骤1的正确实体识别结果来测试RC模块。我们报告了这些信息对关系分类任务的影响,如表 4 所示。 Full-CNN 使用整个句子来识别实体之间的关系。 Sub-CNN 仅使用两个实体之间的子句。 Sub-CNN-H 使用从双向编码层获得的实体的子句和编码信息。当比较 Full-CNN 和 SubCNN 时,结果表明 sub-sentence 可以实现 +20% 的改进。这个结果与[9]的分析相匹配,即大多数关系可以通过给定两个实体之间的子句而不是完整的句子来反映。当将实体的编码信息添加到Sub-CNN中时,Sub-CNN-H可以进一步提升关系分类的准确性。它验证了实体的上下文信息也有利于识别实体之间的关系。
5.3 The effect of two entities' distance
从图4(如下图,第二次出现)中我们知道,当横轴为两个实体之间的距离时,数据分布表现出长尾特性。因此,我们设置一个阈值Lmax来过滤数据。如果两个实体的距离大于Lmax,我们认为这两个实体没有关系。为了分析阈值Lmax的影响,我们使用Sub-CNN根据不同的Lmax值来预测实体关系。效果如图5所示。Lmax越小,过滤的数据越多。所以如果Lmax太小,可能会过滤掉正确的数据,导致F1结果下降。如果Lmax太大,则无法过滤掉噪声数据,这也可能会影响最终结果。图5表明,当Lmax在10到25之间时,它可以表现良好。该范围也与图4的统计结果相符。

5.4 Error analysis
为了分析方法的错误,文中将模型在关系分类任务上的预测结果进行可视化,如图6所示。对角线区域表示正确的预测结果,其他区域反映错误样本的分布。突出显示的对角线区域意味着我们的方法可以在除关系P-S之外的每个关系类上表现良好。由于测试数据集中包含少量关系标签为P-S的样本,因此P-S的预测分布不能完全反映真实情况。此外P-S表示人与社会的关系。实体Person和实体Social在数据集中始终是代词,因此很难根据这些代词识别P-S关系。
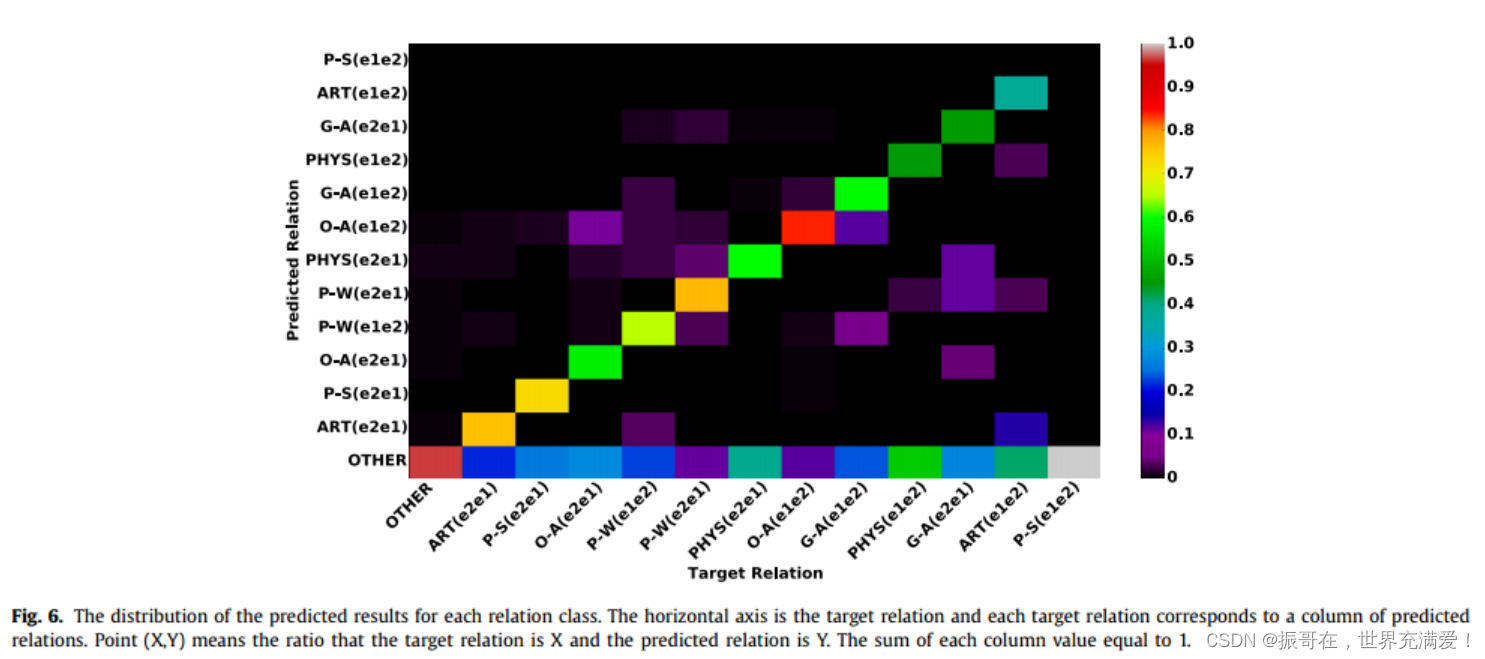
此外,图6中可知,预测关系的分布在Other的第一行上相对分散,这意味着大多数特定关系类型可以被预测为OTHER。即我们无法识别某些关系,直接导致召回率较低。从OTHER的第一列可以看出,如果两个实体之间没有关系,则模型可以有效区分。
除了OTHER之外,另一个问题是方向相反的相同的关系类型很容易混淆,例如:P-W(e2e1)和P-W(e1e2)、ART(e1e1)和ART(e2e1)、OA(e1e1)和O-A(e2e1)。原因是相同的关系类型总是具有相似的描述,即使它们不在同一方向。
6、Conclusion
实体和关系抽取是知识抽取中的一个重要问题,在知识库的自动构建中起着至关重要的作用。在本文中,我们提出了一种混合神经网络模型来提取实体及其语义关系,而无需任何手工制作的特征。与其他基于神经网络的方法相比,我们的方法考虑了实体标签之间的长距离关系。为了说明我们方法的有效性,我们在公共数据集 ACE05(自动内容提取程序)上进行了实验。在公共数据集ACE05上的实验结果验证了我们方法的有效性。未来我们将探索如何基于神经网络更好地链接这两个模块,使其能够更好地发挥作用。此外,我们还需要解决忽略某些关系的问题,并努力提升召回值。