目录
一、支持向量机基本型(线性可分)
1.1 问题描述
1.2 参考资料
二、KKT条件
2.1 KKT条件的几个部分
2.1.1 原始条件
2.1.2 梯度条件
2.1.3 松弛互补条件
2.1.4 KKT条件小结
2.2 参考资料
三、对偶形式
3.1 由原始问题到对偶问题
3.2 对偶问题的具体形式
3.3 为什么可以将求解极小极打问题转化为求解极大极小问题?(具体证明我也没看)
3.4 参考资料
四、对偶问题的求解
4.1 SMO算法理论推导(仅考虑线性可分时)
4.2 SMO算法代码实现
4.3 编写程序的过程中的一点点收获
4.3.1 关于选点与优化结果
4.3.2 不同的选点方式带来的损失值变化的不同
4.4 参考资料
五、线性不可分情形
六、核函数
一、支持向量机基本型(线性可分)
1.1 问题描述
在PLA感知机算法中我们求取超平面是保证所有目标分类正确即可,但是我们为了增加我们学习到的算法的鲁棒性,泛化能力更强,我们可以使超平面到样本的间隔距离最大,这里我们定义间隔为“样本到超平面的最近距离”,也就是说我们的超平面就是对应间隔最大的平面。下面我们用数学语言来描述。
假设样本集,设超平面为
,点到超平面的距离
,最小间隔则为
,当
达到最大时的
就对应我们的超平面。即:
现在的问题转变成了优化问题。
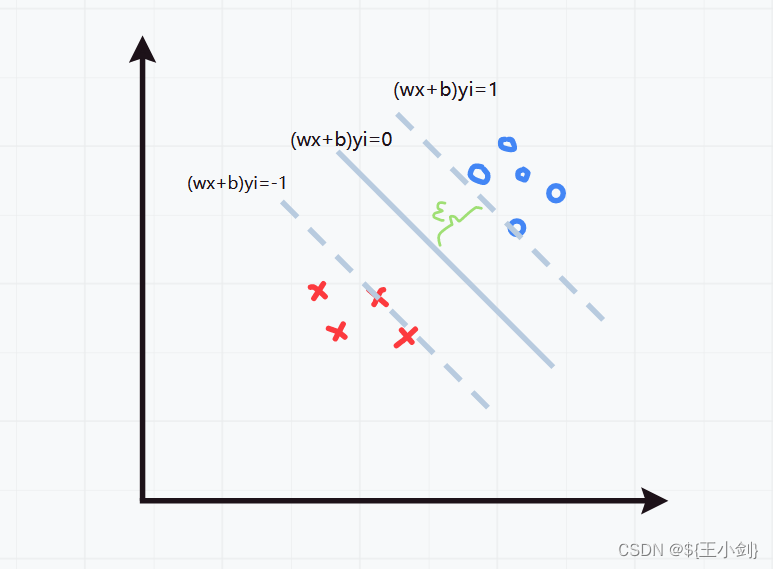
对于这样确定的,必然存在
,
,即:
对进行缩放是不影响超平面的,所以可以必然存在这样的
,使得:
//这个式子隐含了
这个条件了
所以:
要使达到最大,则使
最小即可。所以上述优化问题可以写成下列形式:
1.2 参考资料
以上就是支持向量机的基本型。详细内容可参见李航《机器学习方法》第七章支持向量机。网上其他参考资料可参见:
文档资料:
机器学习:支持向量机(SVM)_燕双嘤的博客-CSDN博客_支持向量机
支持向量机通俗导论(理解SVM的三层境界)_v_JULY_v的博客-CSDN博客_支持向量机
视频资料:
推导SVM基本形式_哔哩哔哩_bilibili
【数之道25】机器学习必经之路-SVM支持向量机的数学精华_哔哩哔哩_bilibili
1. 支持向量机(线性模型)问题_哔哩哔哩_bilibili
svm原理推导:1-支持向量机要解决的问题_哔哩哔哩_bilibili
二、KKT条件
我把KKT条件放到第二节来讲,我觉得更加符合我们的思维方式,在第一节中我们给出了SVM的基本型,那么接下来我们来试图求解这个优化问题,由此引出KKT条件,很多写法将KKT条件直接上来就构建拉格朗日辅助函数,然后就给读者说就是这么回事,这种逻辑其实不合理,应当直接从梯度角度来讲这个事情。
2.1 KKT条件的几个部分
上述优化问题:
2.1.1 原始条件
2.1.2 梯度条件
在求解带不等式约束的优化问题时,考虑两种情况一种是不等式约束有效,一种是不等式约束无效。我们把要优化的函数称为目标函数(这个地方只考虑凸函数的情况)。
(1)当约束条件无效时,目标函数最优值为其梯度为0时的值。
(2)当约束条件有效时(目标函数不在约束范围内),那么目标函数取得最优值是应当与约束条件“相切”,也就是梯度方向成平行关系,具体可分为以下4种情况,我们假设目标函数为,约束函数为
:
1.

此时有:
2.
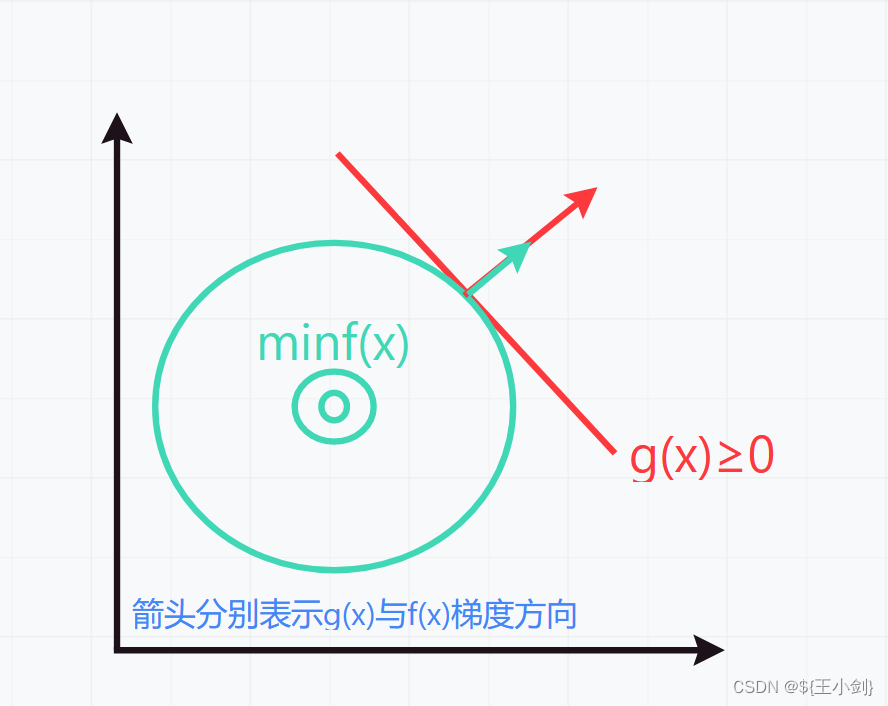
此时有:
3.
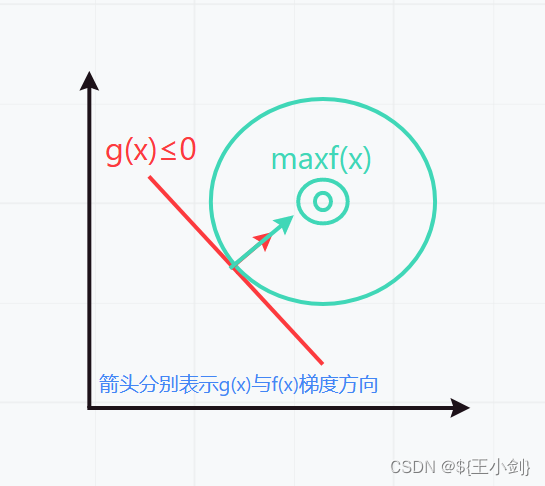
此时有:
4.
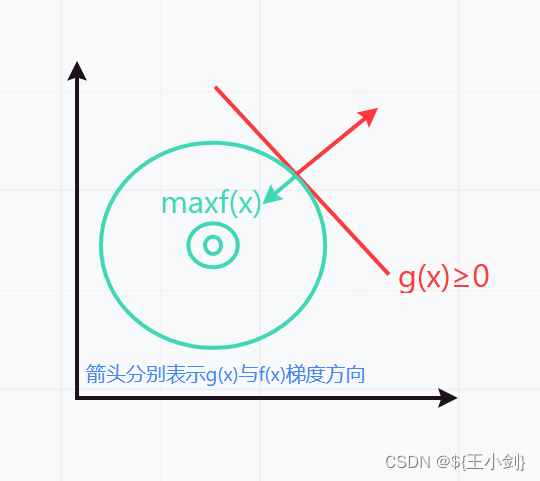
此时有:
注意的梯度方向与
具体函数相关,这里为了举例方便仅画出示意图默认了梯度方向。
在SVM基本型的优化问题中,其情形属于第二种情况,即:
综上两种情况可知:
或
由于原优化问题是多约束条件,我们画出示意图如下:
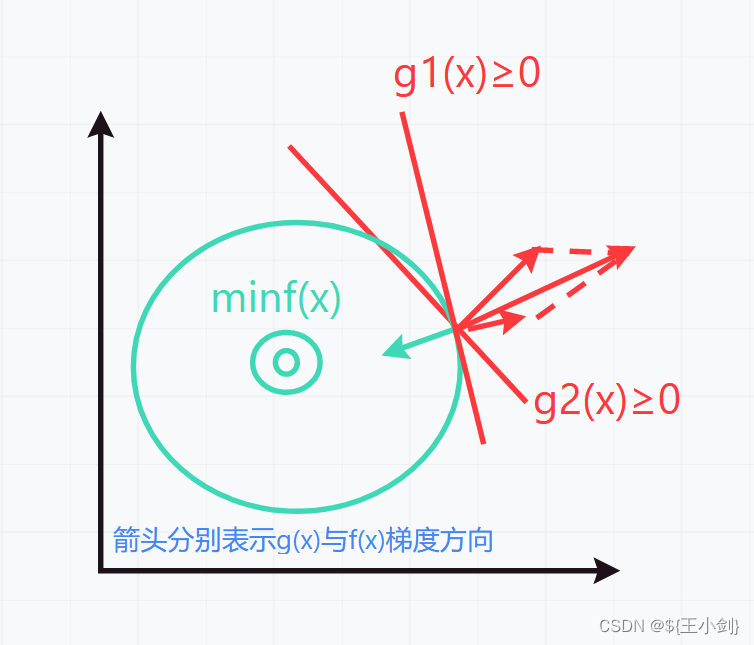
此时有:
综上所述,代入原式子,即:
或
为了将两种情况综合到一起,我们引入了互补松弛条件。
2.1.3 松弛互补条件
我们把约束条件有效和约束条件无效两种情况综合打一起,实际上对于第二种情况,当约束条件无效时,可令对应的乘子
=0,此时第二种情况也就变成了第一种情况,当约束条件有效时则约束条件
=0,所有始终有:
我们称之为互补松弛条件。对于原始问题来讲,互补松弛条件就是:
2.1.4 KKT条件小结
综上所述我们引出了KKT条件,对于凸优化问题因为只存在唯一解KKT条件等价于原始优化问题,解KKT条件就是解原始优化问题,原始优化问题的解一定满足KKT条件。
上述就是我们所说的KKT条件,KKT条件主要用来求解,但是实际上我们发现KKT条件中的参数还是很多,求解并不容易,为此我们又引入了拉格朗日对偶性,降低要求解的维度。
2.2 参考资料
文档资料:
Qoo-凸二次规划与KTT条件-支持向量机SVM(二) - 知乎
KKT条件,原来如此简单 | 理论+算例实践 - 知乎
Karush-Kuhn-Tucker (KKT)条件 - 知乎
视频资料:
“拉格朗日对偶问题”如何直观理解?“KKT条件” “Slater条件” “凸优化”打包理解_哔哩哔哩_bilibili
拉格朗日对偶性_哔哩哔哩_bilibili
三、对偶形式
3.1 由原始问题到对偶问题
上面我们已经说到,原问题转化为对偶问题主要原因是对偶问题会好计算一些,对偶问题其实就是拉格朗日极大极小和极小极大问题。我们的原始问题是不等式约束问题,现在我们要将不等式约束问题转化为极大极小或者极小极大问题。我们这里写出原问题:
首先构建拉格朗日辅助函数,注意该辅助函数约束条件部分前的符号是减号,不明白的话可以倒回去看梯度条件,就明白这个地方为什么是减号了。
求的值,考虑以下两种情况:
(1)不满足原约束条件,即存在某个
使得:
,要想值最大则有满足条件的部分
,不满足的部分
,那么有:
(2)满足原约束条件,则当
时,值取到最大,即:
综上所述:
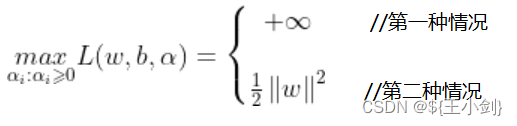
这里的是无约束的,可以取任意值,实际上就是当取到最优值的时候,对应的
必然满足原约束条件,所以可以不管约束条件只管放心大胆的去求极值就行。综上所述,可得极小极大问题
等同于下:
该极小极大问题的解与原始问题的解是一致的。到此为止我们完成了将原始问题转化为拉格朗日极小极大问题。我们顺理成章的可以引出他的对偶问题,极大极小问题:
3.2 对偶问题的具体形式
对于我们可以先求
,该拉格朗日辅助函数可以看出也是一个凸函数,或者说是凹函数(凸函数就是极小值点在最下面,凹函数就是极大值点在最上面,凸的“拱”往下,凹的“拱”往上,这个地方不要太过纠结,毕竟加个负号就相互转换了)。另外,实际上对偶问题一定是一个凹函数,因为对偶函数是一族关于拉格朗日乘子(对应这里就是
)的仿射函数的逐点下确界,所以即使原问题不是凸的,对偶问题也是凹的,他的最优值只有一个,即梯度为0的点。因此可以得到条件如下:
将该结论代入拉格朗日辅助函数可得:
所以对偶问题可以转变为:
s.t.
进一步写成如下形式:
s.t.
这就是对偶问题的具体形式了。
3.3 为什么可以将求解极小极打问题转化为求解极大极小问题?(具体证明我也没看)
这个地方我只能给出个定理李航《机器学习方法》附录C里面这么说的,对偶问题是强对偶的情况下(目标函数是凸函数,约束集是凸集或者说这里的约束条件全是仿射函数,满足Slater条件),原问题的解,与对偶问题的解
,这一对解能够满足KKT条件。前面我们已经说了,对于凸优化问题KKT条件解是唯一的,也就是说我们通过
和KKT条件求得的
,必然就是
也就是原问题的解。
3.4 参考资料
文档资料:
李航《机器学习方法》第七章、附录C
王书宁《凸优化》第五章
拉格朗日对偶问题_VelvetQuilt的博客-CSDN博客
机器学习中的数学——拉格朗日乘子法(二):不等式约束与KKT条件_von Neumann的博客-CSDN博客_拉格朗日乘子法 不等式约束
视频资料:
【数之道25】机器学习必经之路-SVM支持向量机的数学精华_哔哩哔哩_bilibili
拉格朗日对偶性_哔哩哔哩_bilibili
“拉格朗日对偶问题”如何直观理解?“KKT条件” “Slater条件” “凸优化”打包理解_哔哩哔哩_bilibili
四、对偶问题的求解
4.1 SMO算法理论推导(仅考虑线性可分时)
(这个地方我先只考虑可分的情形,到不可分情形时我们再逐步深入。)
经过上文的探讨,我们得到了SVM优化问题的对偶问题,如下:
s.t.
该对偶问题也是凸优化问题,针对该类问题我们可以使用梯度下降的方式求解,但是上述优化问题由于有约束条件的存在,我们在使用梯度下降计算最优解时,不能够单变量下降,应当多个变量组合下降,保证满足约束条件。我们不在这里对使用梯度下降做过多探讨,针对SVM学术界已经提出了更高效的计算方法,即序列最小最优化算法(SMO)该算法于1998年由Platt提出,其论文见参考资料。
SMO算法思想就是选取两个变量,
作为优化对象,其他
当做已知量。为啥不是选一个变量来优化?由约束条件决定的没办法单独对一个变量做优化。或者为啥不是选三个变量来优化?选三个就不叫“最小序列”优化算法了,主要是3个变量计算起来也不简单。将
,
单独拎出来,所以有以下式子(为方便书写,我们假设
、
就是1、2,1、2也具有一般性并不会影响结果,
表示
点积):
原问题的对偶问题实际上是一个二次规划问题,这个二次规划问题为什么能够分解为二次规划子问题来求解,以及关于为什么每次优化两个值
,能够使原目标函数值减少,并且最终收敛的理论保证作者在原论文中提到过。感兴趣的请自行查看原文,部分原文内容如下:
实际对应的理论是在Osuna, E的论文《An improved training algorithm for support vector machines》中提到的。

我们把单独提出来得下式:
s.t. //
为某一确定值
,
有上述可知:
代入要优化的目标函数,可得:
要想使得值最小,也就是其梯度等于0时为最小值,我们对
求梯度,如下:
得:
又:,和上式放到一起可以得含两个变量的方程组:
这样我们就把求解二次规划子问题的解,变成了求解方程组。这个方程组看起来也不好求,但是我们有方法。求解线性方程组我们可以使用迭代法,只要在当前方程形式下解是逐步收敛的,那么就可以使用这种方法。相关知识请参考李庆扬《数值分析》第五版第6章——解线性方程组的迭代法。我们对和
赋满足条件(也就是前面说的对偶问题里面的两个约束,
和
)的初值,这里我们可以赋初值
。迭代方程如下:
表示上一次结果,
表示下一次结果。
那么新的问题来了,我们该怎么去选取和
来进行迭代,前面说了
和
是泛指,可能是
、
、
等。我们接下来对上述方程进行变形,然后告诉你该怎么去选(这个地方要是去遍历所有组合是不是也能求得解呢?我理解应该也是可以的就是效率低了点,后面实验一下)。
设:
根据KKT条件(前面说了对偶问题的解和原问题的解,放到一起满足KKT条件),,所以
。
所以:
将上式代入迭代方程(这里是代入迭代方程的前一步,即和
)化简后可得:
接下来我们再把前面的KKT条件放这里,并进行新的分析:
我们要注意我们通过迭代去求得的(注意这里的
是(
)向量),什么时候就是我们想要的
呢?意思就是什么时候得到的
就是是目标函数取得最优值的
。回忆前面的内容,满足KKT条件的
就是最优的
。那么我们就知道该如何去选取
和
,选取违背KKT条件的,又根据Osuna, E的理论对含有违背KKT条件的QP子问题进行优化,一定能够使原问题得到下降,在没有达到最优前那么一定会有对应的
对应的样本违背KKT条件。
接下来如何快速的选取对应违背KKT条件的呢?再次回到KKT条件。我们以
为关注点,来分情况判断。
对于无效的约束条件,其对应的拉格朗日乘子为0,当约束条件有效时,其对应的拉格朗日乘子
大于0。
代表的就是软间隔距离。利用上式我们可以简化KKT条件的判断。另外由于对偶问题实际上是一个凸优化问题,要想使优化值下降的足够多,那么我们就要想使
和
之间变化足够大。结合前面的迭代式:
也就是,变化足够大。在SMO原论文中,这个地方分母是核函数,由于核函数计算比较困难,原论文实际上忽略了分母,只考虑分子的变化足够大,即
变化足够大,这个就实际上可能会导致优化值降低的不够。那么现在我们就可以在外层循环中先找到一个违背KKT条件的
以及其对应的样本(这个地方说是违背越严重的点带来的优化越多,怎么判断严重程度呢?就是用到上面说的简化版的判断是否违背KKT的式子,比如说
时,那么
值越大则说明违背越严重),然后在内层循环中找到一个与
能够产生足够大差的
以及其对应的样本。接下来我们再考虑一个问题。
这个求解实际上对于是一个无约束求解,但实际上在KKT条件中,
。因此我们需要对求得的
进行裁剪。注意要保证
和
同时满足条件。通过上述迭代式我们求得了
,我们怎么求
呢?
又有:
所以:
考虑:,
得:
接下来更新阈值b,我们分情况讨论:
①当,
时,则
。
②当,
时,则
。
③当,
时,则
,此时
③当,
时,则
,即软间隔均大于1。这种情况又要细分讨论。(实际上通过后面的实验我发现,在优化后
或
其中至少一个会变成支撑向量,所有根本不会出现两者都等于0的情况,所以下面的讨论可以忽略掉,我会在文章结尾部分贴出选点以及每次迭代的优化效果,你就会发现必然会有至少一个优化变量变成了支撑向量)
(1)当时,我们可以得到:
或
,总之获得的是一个区间。这个区间范围内的值都可以取,都可以使KKT条件成立;
(2)当时,我们可以得到:
或
,这种情况在原论文中实际上被忽略掉了,但是按照前面选取
和
的策略来讲这种情况实际上是不会出现的,因为要使
变化足够大,那么
一定不等于
。假设遇到了这种情况,一定要更新b的话,可以让
,
或
,
(这个时候其实就是原文中说的
时候,这个时候作者直接return 0了放弃本次优化了,实际上也是这么个情况,没有限制到b的范围,和我最初随机给的b实际上没什么本质区别,因为我最初给的b必然能够使至少一个样本满足KKT条件,而现在这个优化后也就使至少两个样本满足KKT条件,没太大意义);
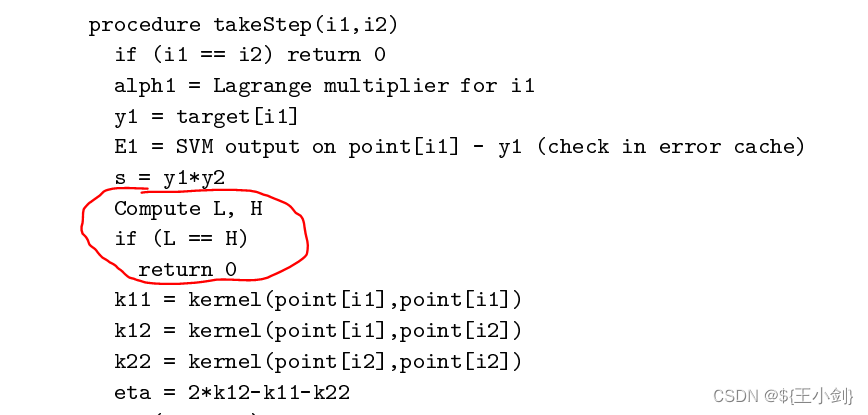
为了方便理解我画个图来表示上面说的的情况优化前和优化后的区别。


左侧就是我随便初始化了一个超平面,右侧两个绿色圈出来的样本就是我们选的同号的样本,然后为了让这两个样本满足KKT条件,我们计算出了右侧这个新的超平面。但是我们看结果,新的超平面对于原来有什么大的优化吗?没有。所以这种情况实际上是没什么意义的,上图只是一个示意,想表达的意思就是这种优化和之前的随机初始化没什么区别,运气好你能优化,运气不好越来越差,而且这种情况是不可能出现的,所以作者也直接放弃了这种情况下的优化。所以就得两个异号的样本来做优化才是有意义的,最后优化的超平面会在两个异号的样本之间。
为了方便计算,我们令,并将每个样本的
保存在一个列表中。那么计算
的迭代式可以写成:
对b的更新:
两式联立可得:
同理:
对的更新:
在一定精度条件下满足KKT,则停止算法,否则进行循环。算法流程图如下:
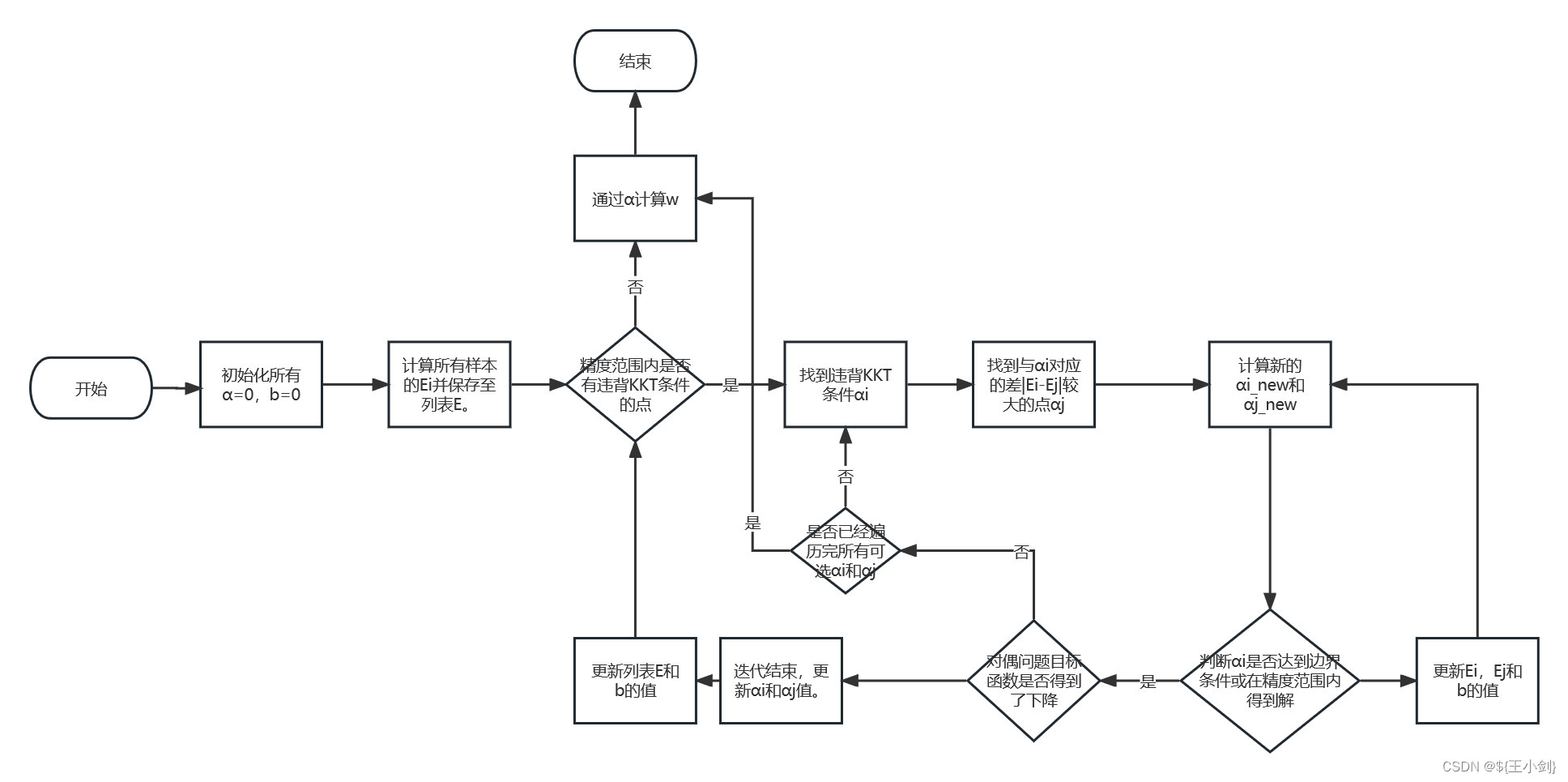
至此我们完成了线性可分情况下的支持向量机的整个流程推导计算流程,有什么问题欢迎交流。
4.2 SMO算法代码实现
在实际代码实现的过程中,为了方便计算。我们把KKT的条件判断可以改一下,原KKT条件的判断如下:
因为,
,所以
改后如下:
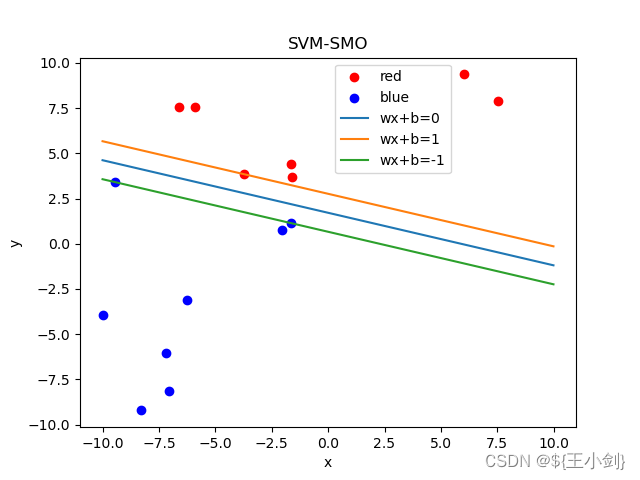
详细代码如下(作者时间有限,代码可能比较粗糙还请见谅,下面的代码可直接运行出结果),先贴运行结果如下,这是15个样本的列子:
# 作者: wxj233
# 开发时间: 2023/6/12 8:28
import numpy as np
import matplotlib.pyplot as plt
class SMO:
def __init__(self, X, t):
"""
初始化
:param X: 样本,X每一行为一个样本,列为样本维度。列如:
[[1,2,3],
[4,5,6]]
就是一个两个样本,每个样本有三个维度的数据集。
:param t: 样本标签,为一维数组,长度应当和样本数量一致。
:return:
"""
assert X.shape[0] == t.size, "样本维度与标签维度不一致"
self.X = X
self.t = t
self.a = np.zeros_like(t) # 初始化α为0,因为没有α这个字母,所以用a代替
self.b = 0 # 初始化b为0
self.E = -t
self.d = 1e-3 # KKT条件的精度范围,因为没有ε,就用字母d代替
self.w = np.zeros(X.shape[1])
self.error = np.zeros_like(t) # 用于记录违背KKT条件的情况
def KKT_error(self):
"""
计算精度范围内的KKT的违背情况,没有违背则对应的值为0
:return:
"""
for i in range(self.a.size):
if (self.a[i] == 0 and self.E[i] * self.t[i] > 0) or \
(self.a[i] > 0 and np.abs(self.E[i] * self.t[i]) < self.d): # 精度范围内满足KKT条件
self.error[i] = 0
else:
self.error[i] = self.E[i] * self.t[i]
return self.error
def cal_b(self, i_a1, i_a2, a1_new, a2_new, E, a, b):
"""
计算新的b值
:param i_a1: 第一个优化值的索引
:param i_a2: 第二个优化值的索引
:param a1_new: 第一个拉格朗日乘子的新值
:param a2_new: 第二个拉格朗日乘子的新值
:param E: 列表E
:param a: α列表
:param b: 阈值
:return: 新的b
"""
b1 = -E[i_a1] - self.t[i_a1] * np.dot(self.X[i_a1], self.X[i_a1])*(a1_new - a[i_a1]) \
- self.t[i_a2] * np.dot(self.X[i_a2], self.X[i_a1])*(a2_new - a[i_a2]) + b
b2 = -E[i_a2] - self.t[i_a1] * np.dot(self.X[i_a1], self.X[i_a2])*(a1_new - a[i_a1]) \
- self.t[i_a2] * np.dot(self.X[i_a2], self.X[i_a2])*(a2_new - a[i_a2]) + b
if a1_new > 0:
b = b1
return b
if a2_new > 0:
b = b2
return b
return (b1 + b2) / 2
def cal_Ei(self, i_a1, i_a2, a, b):
"""
计算E1和E2
:param i_a1: 第一个优化值的索引
:param i_a2: 第二个优化值的索引
:param a: α列表
:param b: 阈值
:return: E1, E2
"""
a = a.reshape(-1, 1)
t = self.t.reshape(-1, 1)
E1 = np.dot(self.X[i_a1], np.sum(self.X * a * t, axis=0)) + b - t[i_a1]
E2 = np.dot(self.X[i_a2], np.sum(self.X * a * t, axis=0)) + b - t[i_a2]
return E1, E2
def update_w(self):
"""
更新w
:return:
"""
a = self.a.reshape(-1, 1)
t = self.t.reshape(-1, 1)
self.w = np.sum(self.X * a * t, axis=0)
def update_E(self):
"""
更新列表E
:return:
"""
self.update_w()
self.E = np.dot(self.X, self.w) + self.b - self.t
def calculate_loss(self, i_a1, i_a2):
"""
计算拉格朗日乘子对应的损失值,同时会顺带一起返回新的a, b, E, w
:param i_a1: 第一个优化值的索引
:param i_a2: 第二个优化值的索引
:return: loss, a, b, E, w
"""
b = self.b
a = np.copy(self.a)
E = np.copy(self.E)
t = self.t
e = np.dot(self.X[i_a1], self.X[i_a1]) + np.dot(self.X[i_a2], self.X[i_a2]) - 2*np.dot(self.X[i_a1], self.X[i_a2])
while True:
a2_new = a[i_a2] + t[i_a2] * (E[i_a1] - E[i_a2]) / e
if t[i_a1] == t[i_a2]: # 裁剪
if a2_new < 0 or a2_new > a[i_a1] + a[i_a2]: # 碰到边界,说明被裁剪了,计算可以停止了。
a2_new = np.median(np.array([0, a2_new, a[i_a1] + a[i_a2]]))
a1_new = a[i_a1] + t[i_a1] * t[i_a2] * (a[i_a2] - a2_new)
b = self.cal_b(i_a1, i_a2, a1_new, a2_new, E, a, b) # 更新b
a[i_a1] = a1_new
a[i_a2] = a2_new
E[i_a1], E[i_a2] = self.cal_Ei(i_a1, i_a2, a, b) # 更新E1,E2
break
else:
if a2_new < 0 or a2_new < a[i_a2] - a[i_a1]: # 碰到边界,说明被裁剪了,计算可以停止了。
a2_new = np.max(np.array([0, a[i_a2] - a[i_a1], a2_new]))
a1_new = a[i_a1] + t[i_a1] * t[i_a2] * (a[i_a2] - a2_new)
b = self.cal_b(i_a1, i_a2, a1_new, a2_new, E, a, b) # 更新b
a[i_a1] = a1_new
a[i_a2] = a2_new
E[i_a1], E[i_a2] = self.cal_Ei(i_a1, i_a2, a, b) # 更新E1,E2
break
if np.abs(a2_new - a[i_a2]) < 1e-5: # 满足计算精度也可以停止计算了
a1_new = a[i_a1] + t[i_a1] * t[i_a2] * (a[i_a2] - a2_new)
b = self.cal_b(i_a1, i_a2, a1_new, a2_new, E, a, b) # 更新b
a[i_a1] = a1_new
a[i_a2] = a2_new
E[i_a1], E[i_a2] = self.cal_Ei(i_a1, i_a2, a, b) # 更新E1,E2
break
a1_new = a[i_a1] + t[i_a1] * t[i_a2]*(a[i_a2] - a2_new)
b = self.cal_b(i_a1, i_a2, a1_new, a2_new, E, a, b) # 更新b
a[i_a1] = a1_new
a[i_a2] = a2_new
E[i_a1], E[i_a2] = self.cal_Ei(i_a1, i_a2, a, b) # 更新E1,E2
a1 = a.reshape(-1, 1)
t1 = t.reshape(-1, 1)
w = np.sum(self.X * a1 * t1, axis=0)
loss = 1/2*np.dot(w, w)-np.sum(a1)
return a, b, E, w, loss
def plotW(self, *point):
"""
绘图
:param point: 选择的点
:return:
"""
fig, ax = plt.subplots() # 绘图
# 绘制样本点
samples_x_r = []
samples_y_r = []
samples_x_b = []
samples_y_b = []
for i in range(self.t.size):
if self.t[i] == 1:
samples_x_r.append(self.X[i, 0])
samples_y_r.append(self.X[i, 1])
elif self.t[i] == -1:
samples_x_b.append(self.X[i, 0])
samples_y_b.append(self.X[i, 1])
ax.scatter(samples_x_r, samples_y_r, color="r", label="red")
ax.scatter(samples_x_b, samples_y_b, color="b", label="blue")
if len(point) == 2:
i_a1 = point[0]
i_a2 = point[1]
ax.scatter(X[i_a1, 0], X[i_a1, 1], color="g", alpha=1, marker="*", label="point1")
ax.scatter(X[i_a2, 0], X[i_a2, 1], color="y", alpha=1, marker="*", label="point2")
x = np.arange(-10, 10, 0.01) # 规定点间隔,依据间隔来画图
y = (-self.w[0] * x - self.b) / self.w[1]
ax.plot(x, y, label="wx+b=0")
y1 = (1-self.w[0] * x - self.b) / self.w[1]
ax.plot(x, y1, label="wx+b=1")
y2 = (-1 - self.w[0] * x - self.b) / self.w[1]
ax.plot(x, y2, label="wx+b=-1")
ax.set_title("SVM-SMO")
ax.legend(loc='upper left', bbox_to_anchor=(0.5, 1)) # 图列左上方位置相对于坐标的位置
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
def getI_a1(self, i_a2):
"""
按照与E[i_a2]违背程度排序,越违背的排越前面
:param i_a2: 第一个选点
:return: 第二个选点的一个列表(这个列表按违背程度排序)
"""
NKKT_list = [] # 不满足KKT条件的索引列表
KKT_list = [] # 满足KKT条件的索引列表
list = []
if self.a[i_a2] == 0:
if self.t[i_a2] == -1:
E = self.E
min_max_list = np.argsort(E) # 从小到大排序,选出(E1 - E2)差值最大的点,就是E2尽可能的小
for i in range(E.size):
if min_max_list[i] != i_a2: # 确保i_a1 != i_a2
list.append(min_max_list[i])
if self.error[min_max_list[i]] != 0:
NKKT_list.append(min_max_list[i])
else:
KKT_list.append(min_max_list[i])
NKKT_list.extend(KKT_list)
return NKKT_list, list
else:
E = self.E
min_max_list = np.argsort(E) # 从小到大排序,选出(E1 - E2)差值最小的点,就是E2尽可能的大
for i in range(E.size):
if min_max_list[-(i+1)] != i_a2: # 确保i_a1 != i_a2
list.append(min_max_list[-(i+1)])
if self.error[min_max_list[-(i+1)]] != 0:
NKKT_list.append(min_max_list[-(i+1)])
else:
KKT_list.append(min_max_list[-(i+1)])
NKKT_list.extend(KKT_list)
return NKKT_list, list
else:
if self.E[i_a2] > 0:
E = self.E
min_max_list = np.argsort(E) # 从小到大排序,选出(E1 - E2)差值最大的点,就是E2尽可能的小
for i in range(E.size):
if min_max_list[i] != i_a2: # 确保i_a1 != i_a2
list.append(min_max_list[i])
if self.error[min_max_list[i]] != 0:
NKKT_list.append(min_max_list[i])
else:
KKT_list.append(min_max_list[i])
NKKT_list.extend(KKT_list)
return NKKT_list, list
else:
E = self.E
min_max_list = np.argsort(E) # 从小到大排序,选出(E1 - E2)差值最小的点,就是E2尽可能的大
for i in range(E.size):
if min_max_list[-(i+1)] != i_a2: # 确保i_a1 != i_a2
list.append(min_max_list[-(i+1)])
if self.error[min_max_list[-(i+1)]] != 0:
NKKT_list.append(min_max_list[-(i+1)])
else:
KKT_list.append(min_max_list[-(i+1)])
NKKT_list.extend(KKT_list)
return NKKT_list, list
def loss(self):
"""
计算当前损失值
:return:
"""
return 1/2*np.dot(self.w, self.w)-np.sum(self.a)
def train(self):
"""
训练函数
:return:
"""
self.update_E() # 更新列表E,计算一次w
self.KKT_error()
last_loss = self.loss()
loss_y = [last_loss]
while np.max(np.abs(self.error)) > 0: # 如果所有点都满足KKT条件了(即误差全部为0),那么说明达到最优训练结束,循环停止。
issatloss = False # 是否还能够产生足够的下降
min_max_sort = np.argsort(np.abs(self.error))
isValid = False
for s in range(1, min_max_sort.size+1):
if isValid:
break
i_a2 = min_max_sort[-s]
if self.error[i_a2] == 0: # 说明已经无法满足下降了,因为前面违背KKT条件的点都已经试过了
break
NKKT_list, list = self.getI_a1(i_a2)
# for i_a1 in NKKT_list:
for i_a1 in list:
a, b, E, w, loss = self.calculate_loss(i_a1, i_a2)
if -(loss - last_loss) > 1e-4:
# self.plotW(i_a1, i_a2)
self.a = a
self.b = b
self.E = E
self.w = w
last_loss = loss
loss_y.append(last_loss)
isValid = True
issatloss = True
# self.plotW(i_a1, i_a2)
break
if not issatloss:
print("无法产生足够的下降")
break
self.update_E() # 更新列表E
self.KKT_error() # 重新计算KKT的违背情况
# np.save("NKKT_loss", np.array(loss_y))
# np.save("list_loss", np.array(loss_y))
print("α", self.a)
print("error", np.abs(self.error))
print(self.loss())
self.plotW()
if __name__ == '__main__':
np.random.seed(1)
X = np.random.rand(15, 2) * 20 - 10 # 产生随机样本
t = np.sign(X.sum(axis=1)) # 为样本打标记
smo = SMO(X, t)
smo.train()
4.3 编写程序的过程中的一点点收获
4.3.1 关于选点与优化结果
下面我用几幅图来表名选点及其优化效果(左侧为在当前情况下的选点,右侧为优化后的结果):
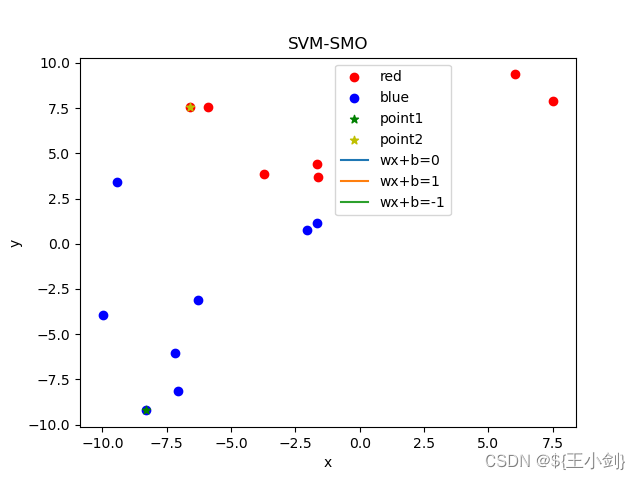
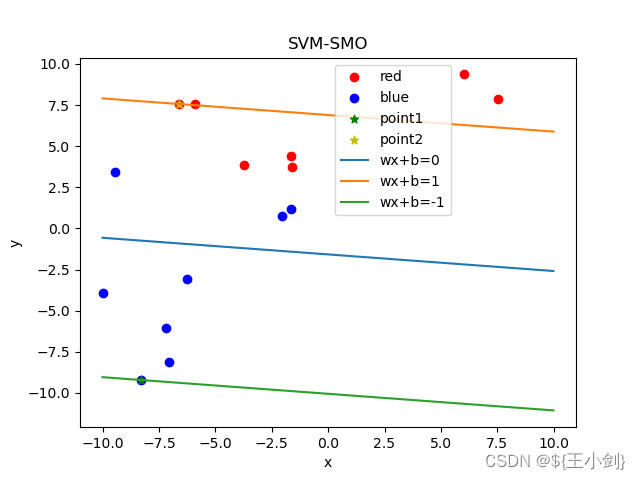
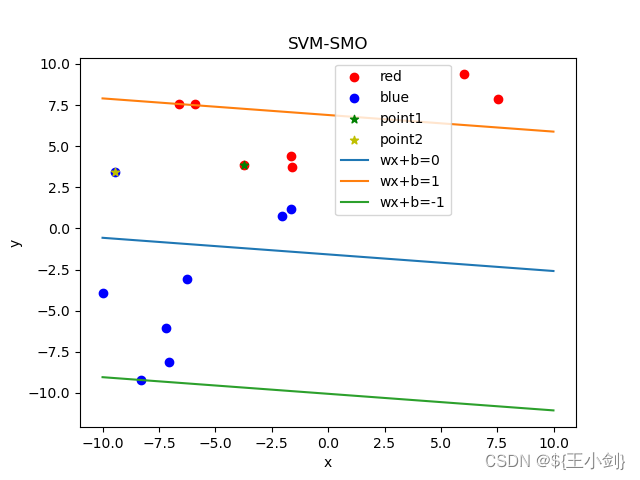
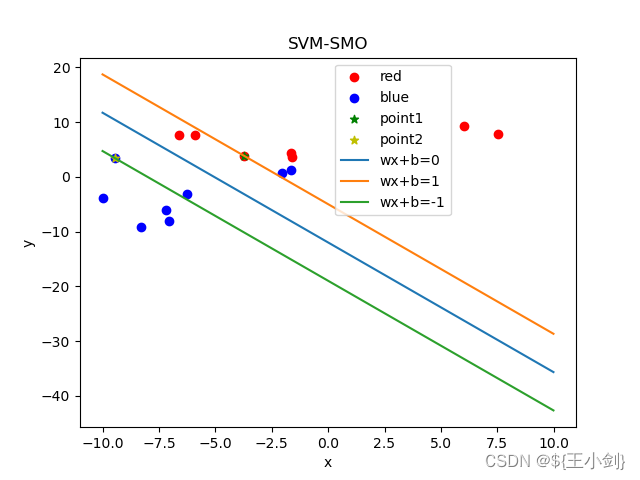

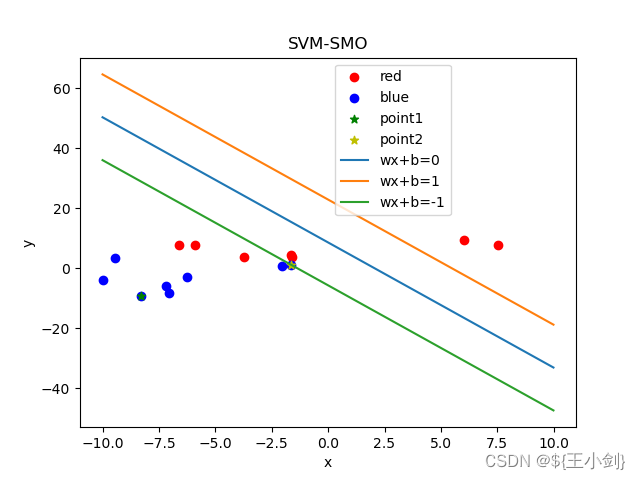
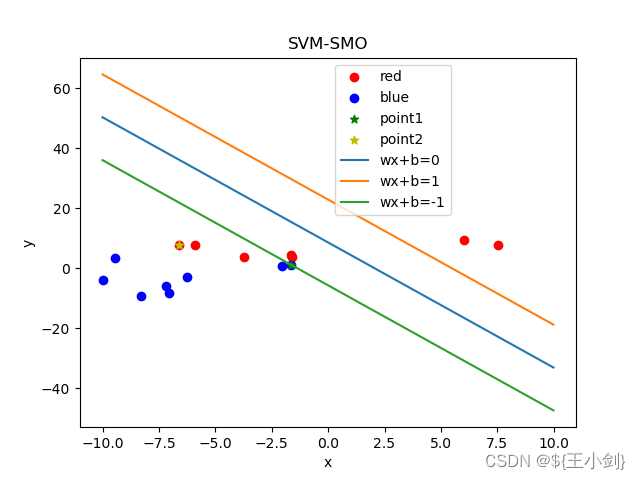
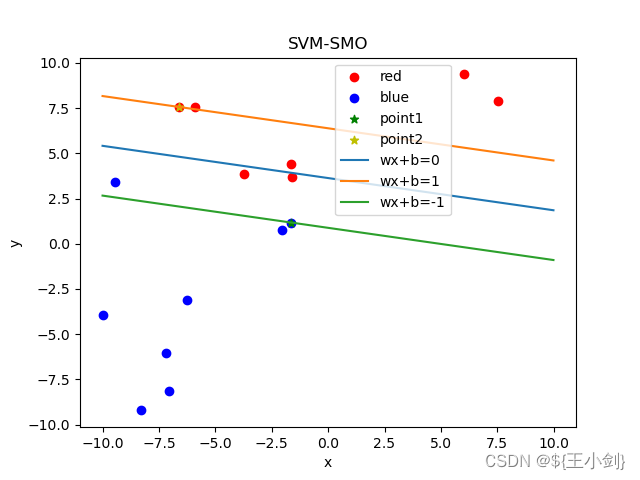

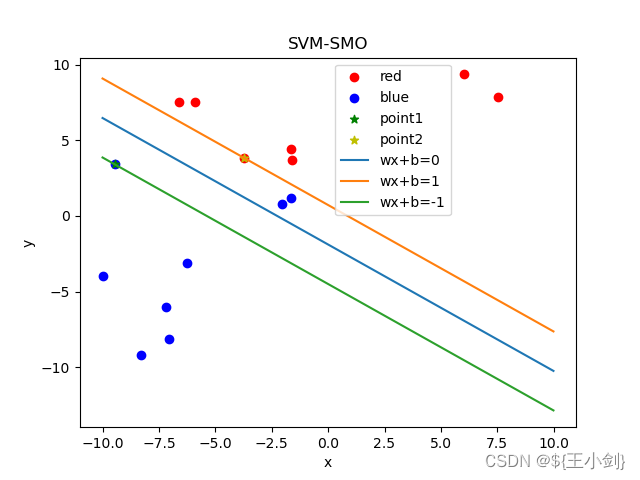
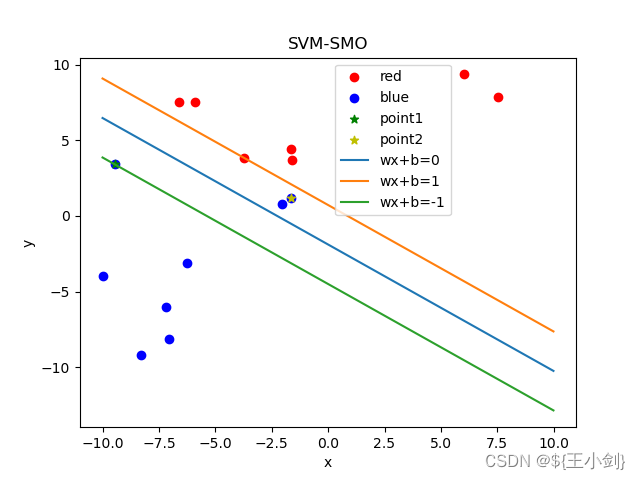
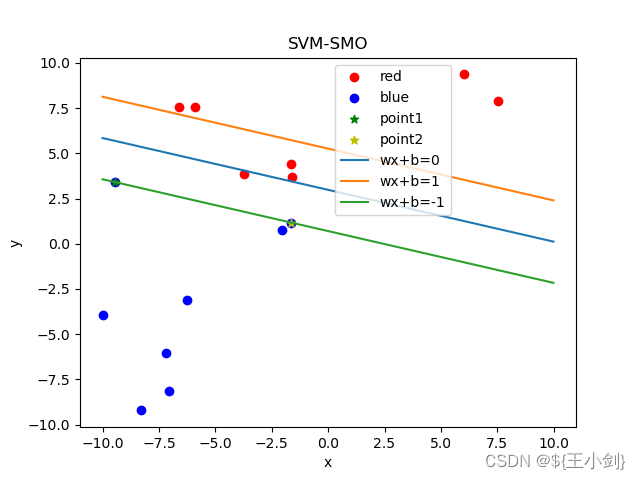
从结果可以看出,如果选择的两个优化点不是同一类,则在优化后这两个点都会变成支撑向量,如果两个点是同一类,则其中至少一个(这一个是靠近另一个分类的)会变成支撑向量。
4.3.2 不同的选点方式带来的损失值变化的不同
我在选择第二个点的时候用了两种方式,第一种就是按照差足够大来选的,我给这种选点方式取名“list_loss”,第二种是优先选在满足违背KKT条件的然后选
差足够大的,我给这种方式取名"NKKT_loss",两种选点方式下的loss值变化如下图(这是20个样本的列子)。
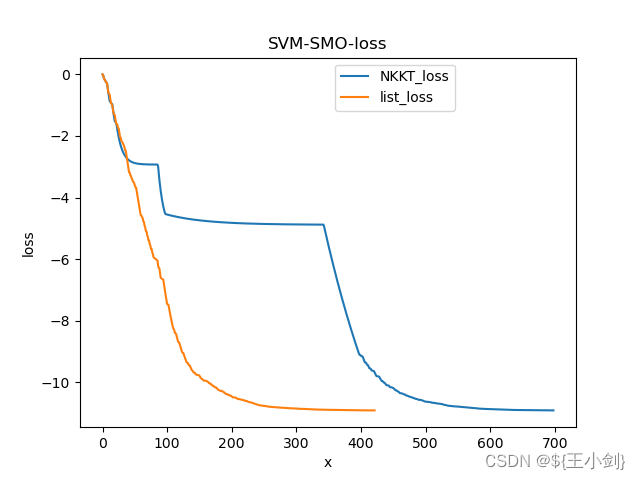
从上图可知list_loss的下降速度显然更快,400多次迭代就可得到解,而NKKT_loss需要700次的迭代才能达到同样的效果,这个内容不重要啊,这是我自己随便尝试的,为了加深理解而已。
4.4 参考资料
文档资料:
Sequential Minimal Optimization : A Fast Algorithm for Training Support Vector Machines-学术范
Fast Training of Support Vector Machines Using Sequential Minimal Optimization - 百度学术
[1]Osuna, E.;Freund, R.;Institute of Electric and Electronic Engineer.An improved training algorithm for support vector machines[A].Neural Networks for Signal Processing VII. Proceedings of the 1997 IEEE Signal Processing Society Workshop[C],1997
李庆扬《数值分析》第五版第6章——解线性方程组的迭代法
支持向量机原理详解(六): 序列最小最优化(SMO)算法(Part I) - 知乎
支持向量机原理详解(七): 序列最小最优化(SMO)算法(Part II) - 知乎
五、线性不可分情形
作者最近没时间写,空了再说。
六、核函数
作者最近没时间写,空了再说。
以上内容花费了我将近一个月时间来理解吸收,作者也是一点点的理解,有不足之处敬请批评指正。