文章目录
- 前言
- 一、uc不感兴趣标签过滤测试
- 1.uc不感兴趣标签获取(uc_unlike_tag_list)
- 1.1个人中心界面
- 1.2从标签中可以发现什么?
- 1.3与研发确认点
- 1.4设计开发
- 1.5接口获取结果
- 2.推荐流文章标签获取(tag_list)
- 2.1部分代码
- 2.2基本标签校验
- 2.3基本标签校验结果
- 3.推荐流uc不感兴趣标签过滤验证
- 3.1校验方法
- 3.2部分代码
- 3.3校验结果
- 3.4结果分析
- 4.用户场景回归
- 二、用户推荐流负反馈过滤测试
- 1.内容负反馈
- 1.1提交API校验
- 1.2获取API校验
- 1.3过滤验证
- 1.3.1获取内容负反馈资源列表(negative_item_list)
- 1.3.2获取推荐流资源列表(item_list)
- 1.3.3求item_list和negative_item_list交集
- 1.3.4交集结果
- 1.3.5结果分析
- 2.标签负反馈
- 2.1提交API校验
- 2.2获取API校验
- 2.3过滤验证
- 2.3.1获取标签负反馈标签列表(negative_tag_list)
- 2.3.2获取推荐流标签列表(tag_list)
- 2.3.3求tag_list和negative_tag_list交集
- 2.3.4交集结果
- 2.3.5结果分析
- 3.作者负反馈
- 3.1提交API校验
- 3.2获取API校验
- 3.3过滤验证
- 3.3.1获取作者负反馈作者列表(negative_user_list)
- 3.3.2获取推荐流作者列表(user_list)
- 3.3.3求user_list和negative_user_list交集
- 3.3.4交集结果
- 3.3.5结果分析
- 三、未登录用户负反馈过滤测试
- 1.提交API校验
- 2.获取API校验
- 3.过滤验证
- 四、整体回归
- 五、新老负反馈写入hbase对比
前言
大家好,我是空空star,本篇给大家分享一下
《CSDN个性化推荐系统-负反馈测试》。
一、uc不感兴趣标签过滤测试
用户:weixin_38093452
1.uc不感兴趣标签获取(uc_unlike_tag_list)
1.1个人中心界面
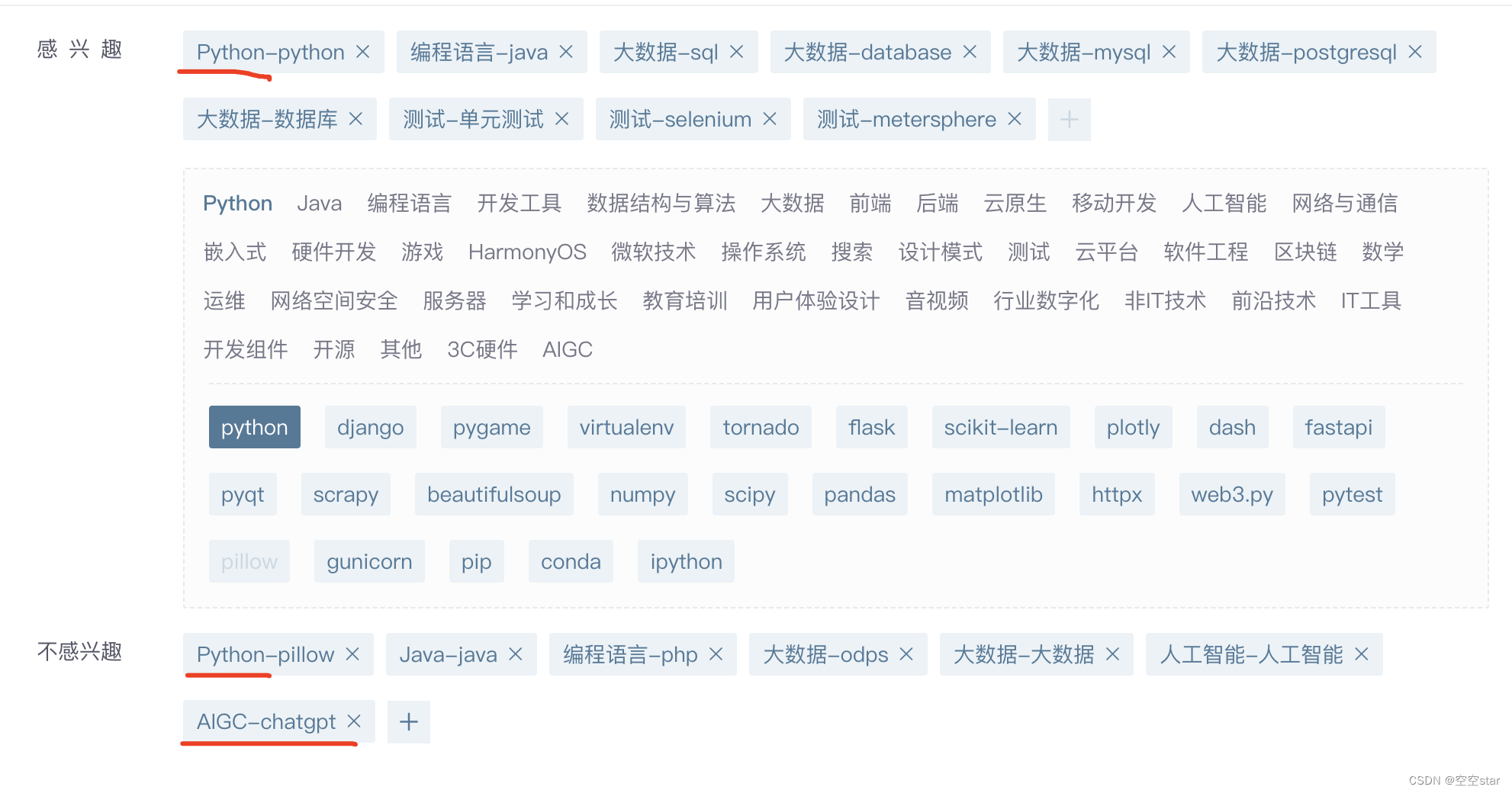
1.2从标签中可以发现什么?
- 标签有一级标签、二级标签
- 标签并不都是全小写,也有一些字母大写
- 同一个标签在感兴趣和不感兴趣里都出现
1.3与研发确认点
- 一级标签和二级标签在过滤侧会拆开用到还是只用了二级标签?
- 获取到的uc标签与推荐流文章标签匹配时有无统一转小写或大写后才去匹配?
- 当同一个标签在感兴趣和不感兴趣里都出现时,屏蔽的优先级是不是高于增强的优先级?
- uc标签维护好后,在推荐流的生效时间?
1.4设计开发
def get_uc_tag_list(username, interest_type):
uc_tag_list = []
# 获取uc不感兴趣标签
url = f'http://xxx.csdn.net/user_csdn_tag/get_tag_list?username={username}&type={interest_type}'
response = requests.get(url)
res = response.json()
for i in res['data']:
name = i['name']
for tag in i['tags']:
if tag['select']:
# 添加小写后的一级标签
uc_tag_list.append(name.lower())
# 添加小写后的二级标签
uc_tag_list.append(tag['name'].lower())
return uc_tag_list
1.5接口获取结果
unlike_uc_tag_list = get_uc_tag_list('weixin_38093452', 1)
print(unlike_uc_tag_list)
[‘python’, ‘pillow’, ‘java’, ‘java’, ‘编程语言’, ‘php’, ‘大数据’, ‘odps’, ‘大数据’, ‘大数据’, ‘人工智能’, ‘人工智能’, ‘aigc’, ‘chatgpt’]
2.推荐流文章标签获取(tag_list)
用户:weixin_38093452
请求推荐接口50次
2.1部分代码
items = result['data']['items']
for data in items:
# 过滤掉nps
if 'username' in data:
tags = data["tags"]
temp_tag = []
for tag in tags:
# 用来判断一个item中返回的标签是否重复(ml和title合并,只保留ml)
temp_tag.append(tag['name'])
# 多次请求后,用来跟uc的不感兴趣标签/负反馈标签做对比
tag_list.append(tag['name'])
# 多次请求后,用来判断ml标签和title标签是否有返回
tag_type_list.append(tag['type'])
if tag['name'] == '':
print(f"存在空标签,博客:{data['product_id']},标签类型:{tag['type']},标签名称:{tag['name']}")
if len(temp_tag) != len(set(temp_tag)):
print(f"同一篇博客{data['product_id']}存在重复标签:{temp_tag}")
if len(set(tag_type_list)) == 2:
print(f'返回文章标签类型:{set(tag_type_list)}')
2.2基本标签校验
- ml标签和title标签是否都有返回;
- 是否有空标签结构返回;
- 同一篇博客是否返回重复标签;
2.3基本标签校验结果
返回文章标签类型:{‘ml’, ‘title’}
3.推荐流uc不感兴趣标签过滤验证
3.1校验方法
- 获取用户的uc不感兴趣标签列表(uc_unlike_tag_list);
- 获取用户50次请求推荐流返回文章的标签列表(tag_list);
- 求uc_unlike_tag_list和tag_list的交集。
3.2部分代码
print(f'【推荐返回的标签】:{set(tag_list)}')
unlike_uc_tag_list = get_uc_tag_list(username, '1')
print(f'【uc-不感兴趣标签】:{set(unlike_uc_tag_list)}')
intersection_tag = list(set(tag_list).intersection(set(unlike_uc_tag_list)))
print(f'【uc-不感兴趣标签过滤】验证结果,标签交集:{intersection_tag}')
3.3校验结果

3.4结果分析
标签交集为空,说明没有badcase;
将【推荐返回的标签】中的高频标签维护到uc不感兴趣标签中,再次执行我们的脚本观察校验结果,结合服务端uc不感兴趣过滤日志,多次执行标签交集仍为空,说明uc不感兴趣标签在推荐流过滤生效。
4.用户场景回归
确保推荐接口有返回数据和返回数据正常。
- 登录用户(未维护uc不感兴趣标签)
- 未登录用户
二、用户推荐流负反馈过滤测试
1.内容负反馈
1.1提交API校验
负反馈项(directive):
- duplicate:内容重复推荐
- content poor quality:内容质量较低
- advertising:内容夸张、涉及广告等
资源类型(type):
- blog
- ask
- blink
- live
- …
1.2获取API校验
- last_unlike_time:负反馈操作时间戳记录是否正确;
- num:负反馈提交次数记录是否正确;
- directive:负反馈项记录是否正确;
- 是否以type和item_id两个字段作为唯一键。
1.3过滤验证
1.3.1获取内容负反馈资源列表(negative_item_list)
def get_negative_item_list(username):
negative_item_list = []
url = f'http://xxx.csdn.net/api/v2/recommend/insight/negative/items/by/{username}'
response = requests.get(url)
res = response.json()
pprint.pprint(res)
for i in res['result']['duplicate']:
if 'object_id' in i.keys():
negative_item_list.append(i['type']+':'+i['object_id'])
for j in res['result']['content poor quality']:
if 'object_id' in j.keys():
negative_item_list.append(j['type']+':'+j['object_id'])
for k in res['result']['advertising']:
if 'object_id' in k.keys():
negative_item_list.append(k['type']+':'+k['object_id'])
return negative_item_list
1.3.2获取推荐流资源列表(item_list)
item_list.append(data['product_type']+':'+data['product_id'])
1.3.3求item_list和negative_item_list交集
print(f'【推荐返回的item】:{set(item_list)}')
negative_item_list = get_negative_item_list(username)
print(f'【内容负反馈】:{set(negative_item_list)}')
negative_intersection_item = list(set(item_list).intersection(set(negative_item_list)))
print(f'【内容负反馈过滤】验证结果,item交集:{negative_intersection_item}')
1.3.4交集结果

1.3.5结果分析
交集为空,说明没有badcase;
将推荐结果返回的部分资源列表通过提交API写入内容负反馈,再求交集,多次执行交集为空,说明内容负反馈在推荐流过滤生效。
2.标签负反馈
2.1提交API校验
directive:
- reduce:减少
- block:屏蔽
2.2获取API校验
- tag:标签是否统一转小写;
- last_unlike_time:负反馈操作时间戳记录是否正确;
- num:负反馈提交次数记录是否正确。
2.3过滤验证
2.3.1获取标签负反馈标签列表(negative_tag_list)
def get_negative_tag_list(username):
negative_tag_list = []
url = f'http://xxx.csdn.net/api/v2/recommend/insight/negative/tags/by/{username}'
response = requests.get(url)
res = response.json()
for i in res['result']:
negative_tag_list.append(i['tag'].lower())
return negative_tag_list
2.3.2获取推荐流标签列表(tag_list)
tag_list.append(tag['name'])
2.3.3求tag_list和negative_tag_list交集
negative_tag_list = get_negative_tag_list(username)
print(f'【减少xx相似内容推荐】:{set(negative_tag_list)}')
negative_intersection_tag = list(set(tag_list).intersection(set(negative_tag_list)))
print(f'【减少xx相似内容推荐过滤】验证结果,标签交集:{negative_intersection_tag}')
2.3.4交集结果

2.3.5结果分析
交集为空,说明没有badcase;
将推荐结果返回的标签列表通过提交API写入标签负反馈,再求交集,多次执行交集为空,说明标签负反馈在推荐流过滤生效。
3.作者负反馈
3.1提交API校验
- unlike_user_id大小写场景
3.2获取API校验
- 作者是否转小写处理;
- last_unlike_time:负反馈操作时间戳记录是否正确;
- num:负反馈提交次数记录是否正确。
3.3过滤验证
3.3.1获取作者负反馈作者列表(negative_user_list)
def get_negative_user_list(username):
negative_user_list = []
url = f'http://xxx.csdn.net/api/v2/recommend/insight/negative/users/by/{username}'
response = requests.get(url)
res = response.json()
for i in res['result']:
negative_user_list.append(i.lower())
return negative_user_list
3.3.2获取推荐流作者列表(user_list)
user_list.append(data['username'])
3.3.3求user_list和negative_user_list交集
print(f'【推荐返回的作者】:{set(user_list)}')
negative_user_list = get_negative_user_list(username)
print(f'【不看此作者】:{set(negative_user_list)}')
negative_intersection_user = list(set(user_list).intersection(set(negative_user_list)))
print(f'【不看此作者过滤】验证结果,作者交集:{negative_intersection_user}')
3.3.4交集结果

3.3.5结果分析
交集为空,说明没有badcase;
将推荐结果返回的作者列表通过提交API写入作者负反馈,再求交集,多次执行交集为空,说明作者负反馈在推荐流过滤生效。
三、未登录用户负反馈过滤测试
1.提交API校验
pc传uuid,app传device_id
2.获取API校验
- imei字段值不做大小写处理;
- 根据imei字段值可以正确获取到负反馈的数据。
3.过滤验证
类似登录用户的校验流程,只是请求推荐接口的入参有调整。
四、整体回归
- 召回策略验证;
- 召回资源类型验证;
- 未登录用户/登录用户(是否维护uc兴趣标签/是否维护身份标签)场景验证;
- 单次请求结果中资源类型分布情况验证;
- 单次请求结果中出现重复作者占比验证;
- 单次请求结果中出现重复资源验证;
- 单次请求结果中连续出现同作者资源验证;
- 其他渠道数据验证(关注流、同城流、blink热门流、推荐用户列表等)
- 多端验证(app/wap/pc/小程序等)
五、新老负反馈写入hbase对比
| 旧负反馈 | 新负反馈 | |
|---|---|---|
| 流程 | 用户提交负反馈->上报到sls->flink消费sls->udf处理写入hbase | 用户提交负反馈->通过API直接写入hbase |
| 响应 | flink任务时常延迟/迁移华为云等因素,需要重构 | 实时 |
| 文案 | 文案不统一,如wap端【内容重复推荐】叫【旧闻,重复】,【内容质量较低】叫【内容质量差】,【不看此作者】叫【不喜欢该作者】 | 各端文案已统一 |
| 数据 | 非blog资源的负反馈数据未正常解析,导致没有正确写入hbase | 已兼容不同资源类型 |
引用
[1] 《如何支持研发对CSDN个性化推荐系统重构》
[2] 《CSDN 个性化推荐系统的设计和演进》
[3] 《CSDN 个性化推荐的数据治理》