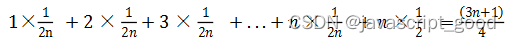MIT 6.830 Lab One
- 项目拉取
- SimpleDB存储结构一览
- SimpleDB特性说明
- Lab One
- 练习一
- 练习二
- 练习三
- 练习四
- 练习五
- 练习六
- 练习七
项目拉取
原项目使用ant进行项目构建,我已经更改为Maven构建,大家直接拉取我改好后的项目即可:
- https://gitee.com/DaHuYuXiXi/simple-db-hw-2021
然后就是正常的maven项目配置,启动即可。各个lab的实现,会放在lab/分支下。
SimpleDB存储结构一览
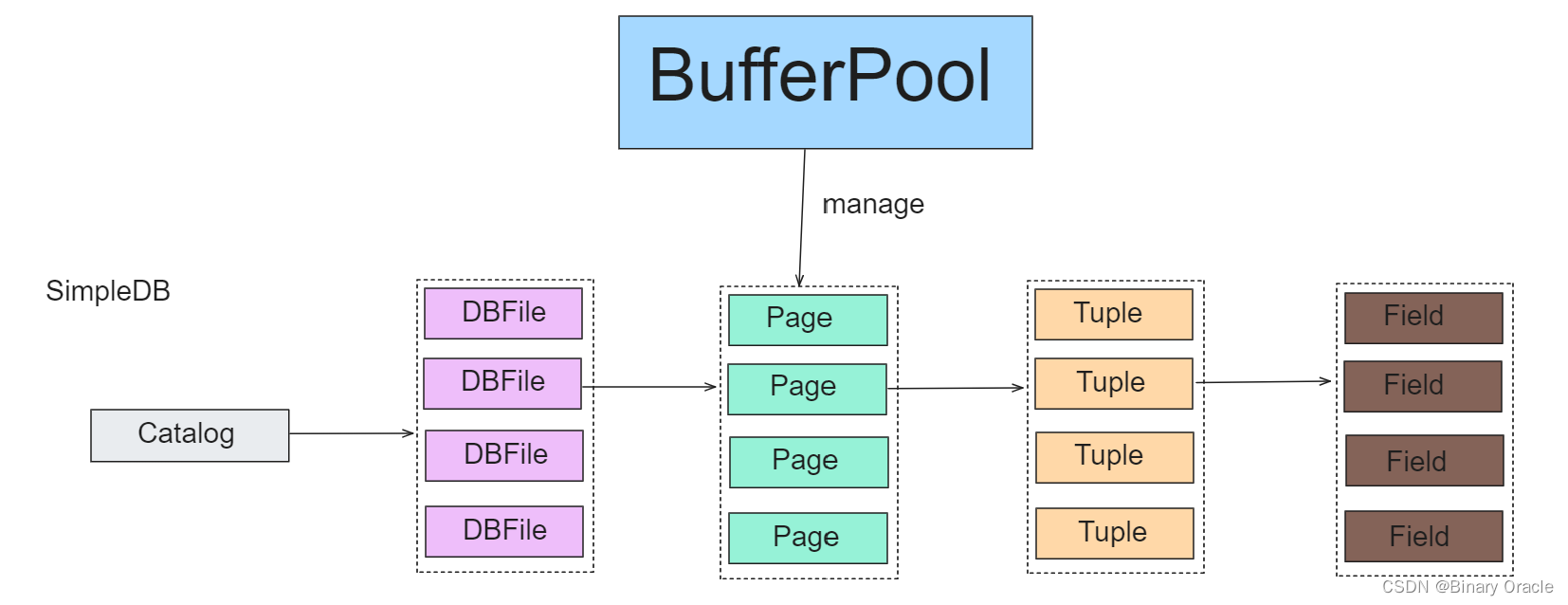
simpledb.common.Catalog 这个类中保存了当前数据库中所有的表 (Table):
/**
* The Catalog keeps track of all available tables in the database and their
* associated schemas.
* For now, this is a stub catalog that must be populated with tables by a
* user program before it can be used -- eventually, this should be converted
* to a catalog that reads a catalog table from disk.
*
* Catalog负责管理数据库中所有的table和其对应的schema
*
* @Threadsafe
*/
public class Catalog {
. . .
}
在 SimpleDB 中,每个 Table 对应着 DBFile 这个接口的实现类:
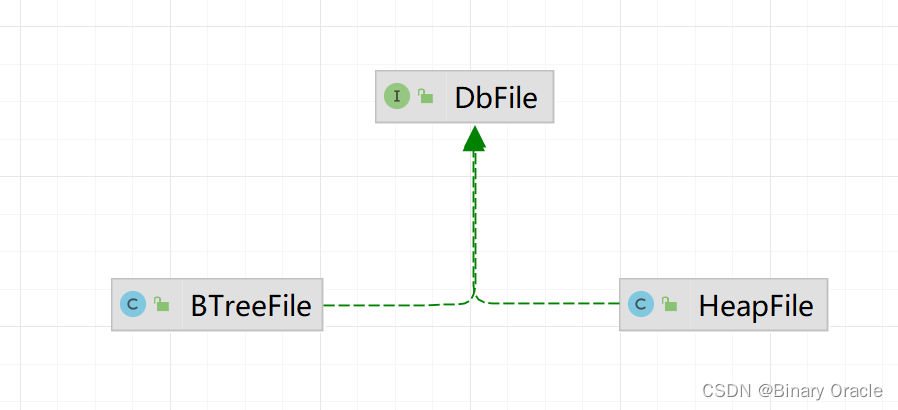
本次实验中就要实现 HeapFile 这个类。HeapFile 实现了 DBFile 接口,将逻辑上的 Table 与物理上的磁盘文件建立了映射。后面的描述中将 Table 等价于 DBFile:
/**
* HeapFile is an implementation of a DbFile that stores a collection of tuples
* in no particular order. Tuples are stored on pages, each of which is a fixed
* size, and the file is simply a collection of those pages. HeapFile works
* closely with HeapPage. The format of HeapPages is described in the HeapPage
* constructor.
*
* @see HeapPage#HeapPage
* @author Sam Madden
*/
public class HeapFile implements DbFile {
. . .
}
但在数据库中,Table 并不是数据库的操作单位。数据库进行操作的操作单位是 Page. 每个 DBFile 会被划分为多个 Page. 数据库每次查询也是查询某个 DBFile 的某个 Page. 因为当单个 Table 很大的时候,不一定有足够的内存来读入整个 DBFile.
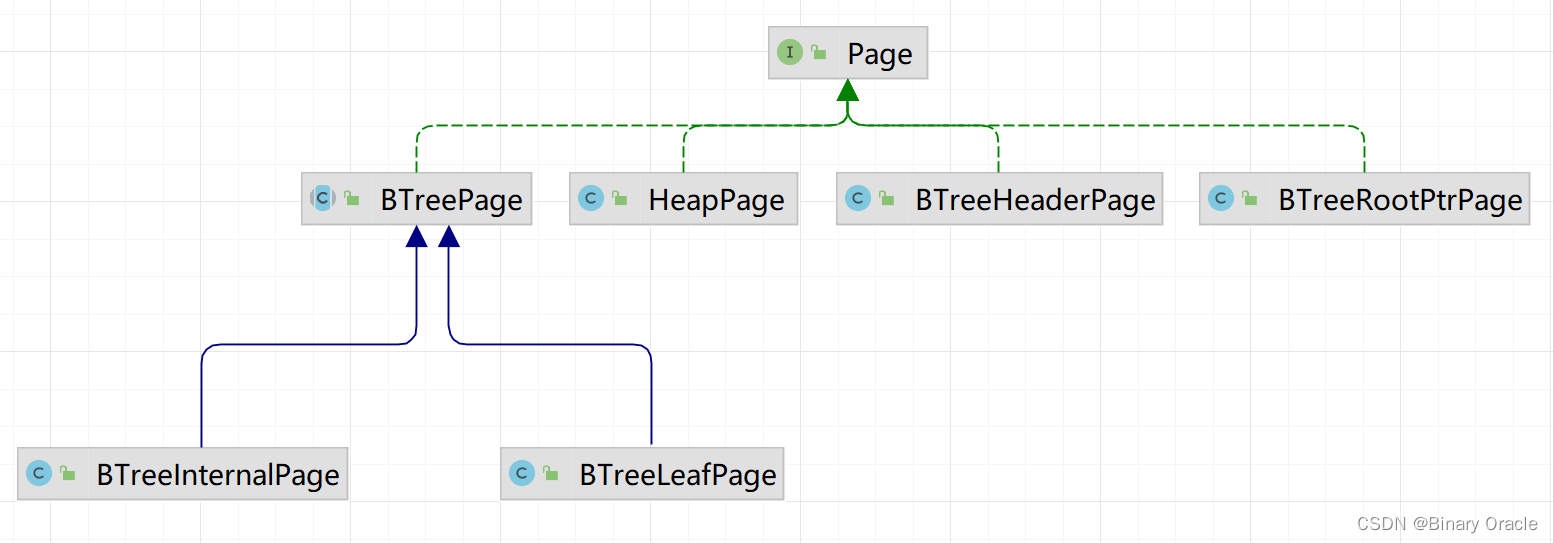
Page 是 Table 的一部分,或者说是它的子集。所以每个 Page 中有若干个 Tuple. Tuple 是 Table 中的一行数据。所以为了表明每个数据的意义及大小,Tuple 中还保存了一个类 TupleDesc,也就是表头。
Tuple 中的每一列叫做 Field. Field 中保存了这个字段的类型和值。
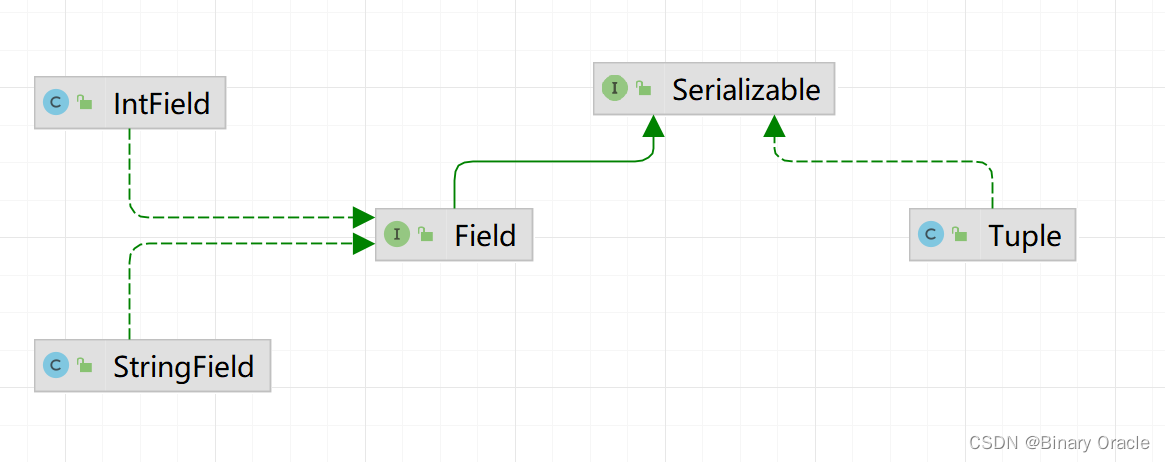
SimpleDB 读取 Page 并不会直接通过 DBFile 来读。而是加了一层缓存,称为 BufferPool. BufferPool 中会缓存 Page,当缓存未命中时才会通过 DBFile.readPage(PageId id) 去磁盘中拿。
/**
* BufferPool manages the reading and writing of pages into memory from
* disk. Access methods call into it to retrieve pages, and it fetches
* pages from the appropriate location.
*
* The BufferPool is also responsible for locking; when a transaction fetches
* a page, BufferPool checks that the transaction has the appropriate
* locks to read/write the page.
*
* @Threadsafe, all fields are final
*/
public class BufferPool {
/** Bytes per page, including header. */
private static final int DEFAULT_PAGE_SIZE = 4096;
private static int pageSize = DEFAULT_PAGE_SIZE;
/** Default number of pages passed to the constructor. This is used by
other classes. BufferPool should use the numPages argument to the
constructor instead. */
public static final int DEFAULT_PAGES = 50;
. . .
simpledb.common.Database 类初始化了 Catalog 与 BufferPool 等必要的组件,且提供了一系列的单例方法来供其他类调用,获取这些组件。
/**
* Database is a class that initializes several static variables used by the
* database system (the catalog, the buffer pool, and the log files, in
* particular.)
*
* Provides a set of methods that can be used to access these variables from
* anywhere.
*
* @Threadsafe
*/
public class Database {
private static final AtomicReference<Database> _instance = new AtomicReference<>(new Database());
private final Catalog _catalog;
private final BufferPool _bufferpool;
private final LogFile _logfile;
...
SimpleDB特性说明
SimpleDB包括:
- 代表域、元组以及tuple schema的类
- 将谓词和条件应用到元组的类
- 一个或多个访问存储在磁盘上的关系的方法(heap file),并提供通过元组的形式迭代遍历这些关系的方法
- 一些列操作元组的类(例如select、join、insert、delete等)
- 一个缓冲池,用于在内存中缓存活动元组和页面,并处理并发控制和事务(在本实验中,这两个都不需要担心)
- 一个存储表信息以及表schema的Catalog类
SimpleDB不包含许多你认为数据库应该包含的概念,例如:
- 这里并不提供SQL语言,而是通过一系列的查询操作来组成查询计划,在后续的实验中将会提供简单的解析器
- 视图
- 除了整数和定长字符串以外的数据类型
- 查询优化(后续实验提供)
Lab One
Lab对应的中文文档已上传至仓库,大家请自行查阅:
下面是SimpleDB实现的一个大致框架:
- 实现管理tuples的类Tuple、TupleDesc,项目中已经提供了Field、IntField、StringField以及Type,我们只需要支持整数和(定长)字符串和固定长度的元组即可
- 实现Catalog
- 实现BufferPool的构造方法以及getPage()方法
- 实现HeapPage、HeapFile以及PageId类中的方法,这些文件中有很大一部分已经写好了
- 实现SeqScan方法
- 本次实验的目标是通过ScanTest系统测试
项目中提供的接口,可能会包含锁、事务和恢复的references,在本次实验我们不用关心这些特性,但是我们需要保持方法中的这些参数,因为在接下来的几次实验中我们会用到,这些不会影响单元测试
练习一
Database类
- Database类提供了访问数据库全局静态对象的方法;
- 包括:访问Catalog、BufferPool以及日志文件(本次实验无需关心日志文件)的方法;
- Database已经实现好了,我们需要阅读该类的源码,因为我们需要访问这些对象
域和元组
- SimpleDB中元组非常基础。它们由Field对象集合组成,Field对象集合用于存储元组的数据。
- Field是不同数据类型实现的接口(项目提供了IntField&StringField)。
- Tuple对象将会通过下一节的访问方法(heap file、B-tree)创建。
- Tuple也包括TupleDesc类,用于描述元组的列名及数据类型。
实现两个类:
- src/java/simpledb/storage/TupleDesc.java
- src/java/simpledb/storage/Tuple.java
实现上述两个类以通过TupleTest和TupleDescTest单元测试;其中关于RecoreId的方法可能会失败,因为我们还没有实现。
我们先来回顾一下数据库中相关基本概念:
- 关系是一张表,表中的每行(即数据库中的每条记录)就是一个元组,每列就是一个属性。 在二维表里,元组也称为记录。
TupleDesc:
- TupleDesc是对元组组成模式的一个描述,也就是当前表的元数据信息,用于记录当前表中每一列的类型,名称,约束等信息。
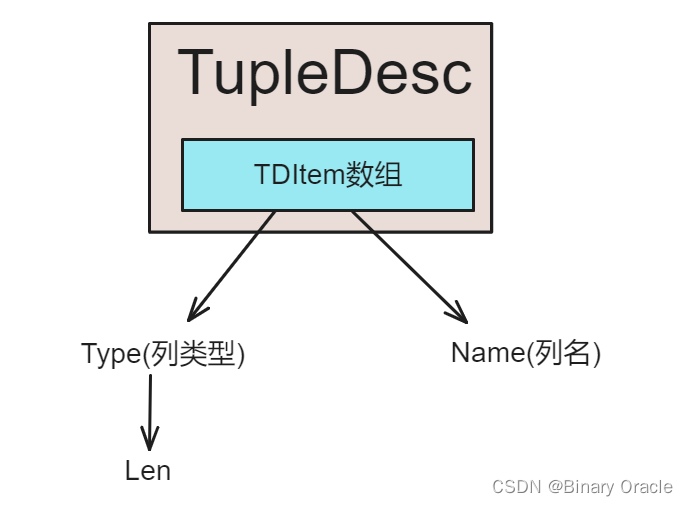
- TupleDesc类核心源码如下:
/**
* TupleDesc describes the schema of a tuple.
*/
public class TupleDesc implements Serializable {
private final List<TDItem> items;
public Iterator<TDItem> iterator() {
return items.iterator();
}
public TupleDesc(Type[] typeAr, String[] fieldAr) {
//typeAr是列类型数组,fieldAr是列名数组
items = new ArrayList<>(typeAr.length);
for (int i = 0; i < typeAr.length; i++) {
TDItem tdItem = new TDItem(typeAr[i], fieldAr[i]);
items.add(tdItem);
}
}
/**
* Constructor. Create a new tuple desc with typeAr.length fields with
* fields of the specified types, with anonymous (unnamed) fields.
*/
public TupleDesc(Type[] typeAr) {
// 匿名字段
items = new ArrayList<>(typeAr.length);
for (Type type : typeAr) {
TDItem item = new TDItem(type, null);
items.add(item);
}
}
public TupleDesc(List<TDItem> items) {
this.items = items;
}
/**
* @return the number of fields in this TupleDesc
*/
public int numFields() {
return items.size();
}
/**
* Gets the (possibly null) field name of the ith field of this TupleDesc.
*/
public String getFieldName(int i) throws NoSuchElementException {
if (i < 0 || i >= items.size()) {
throw new NoSuchElementException("position " + i + " is not a valid index");
}
return items.get(i).fieldName;
}
/**
* Gets the type of the ith field of this TupleDesc.
*/
public Type getFieldType(int i) throws NoSuchElementException {
if (i < 0 || i >= items.size()) {
throw new NoSuchElementException("position " + i + " is not a valid index");
}
return items.get(i).fieldType;
}
/**
* Find the index of the field with a given name.
*/
public int fieldNameToIndex(String name) throws NoSuchElementException {
if (name == null) {
throw new NoSuchElementException("fieldName " + name + " is not founded");
}
for (int i = 0; i < items.size(); i++) {
if (name.equals(items.get(i).fieldName)) {
return i;
}
}
throw new NoSuchElementException("fieldName " + name + " is not founded");
}
/**
* @return The size (in bytes) of tuples corresponding to this TupleDesc.
* Note that tuples from a given TupleDesc are of a fixed size.
*/
public int getSize() {
// 返回一行数据占的总字节数
int bytes = 0;
for (TDItem item : items) {
bytes += item.fieldType.getLen();
}
return bytes;
}
/**
* Merge two TupleDescs into one, with td1.numFields + td2.numFields fields,
* with the first td1.numFields coming from td1 and the remaining from td2.
*/
public static TupleDesc merge(TupleDesc td1, TupleDesc td2) {
final Set<TDItem> items = new HashSet<>(td1.items.size() + td2.items.size());
items.addAll(td1.getItems());
items.addAll(td2.getItems());
return new TupleDesc(new ArrayList<>(items));
}
public List<TDItem> getItems() {
return items;
}
...
/**
* A help class to facilitate organizing the information of each field
*/
public static class TDItem implements Serializable {
private static final long serialVersionUID = 1L;
/**
* The type of the field
*/
public final Type fieldType;
/**
* The name of the field
*/
public final String fieldName;
public TDItem(Type t, String n) {
this.fieldName = n;
this.fieldType = t;
}
public String toString() {
return fieldName + "(" + fieldType + ")";
}
}
}
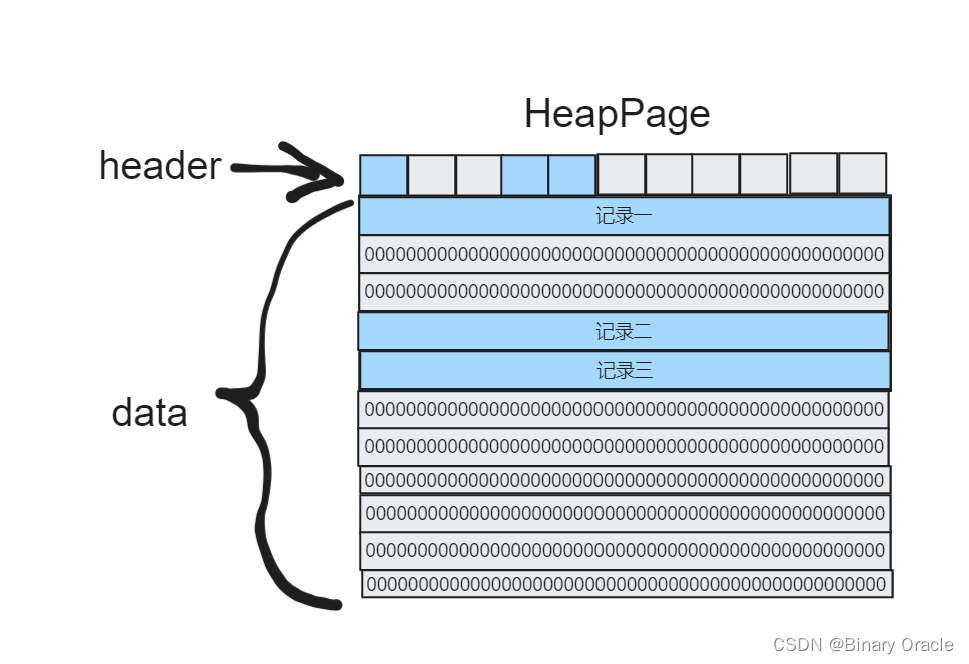
这里需要注意一点:
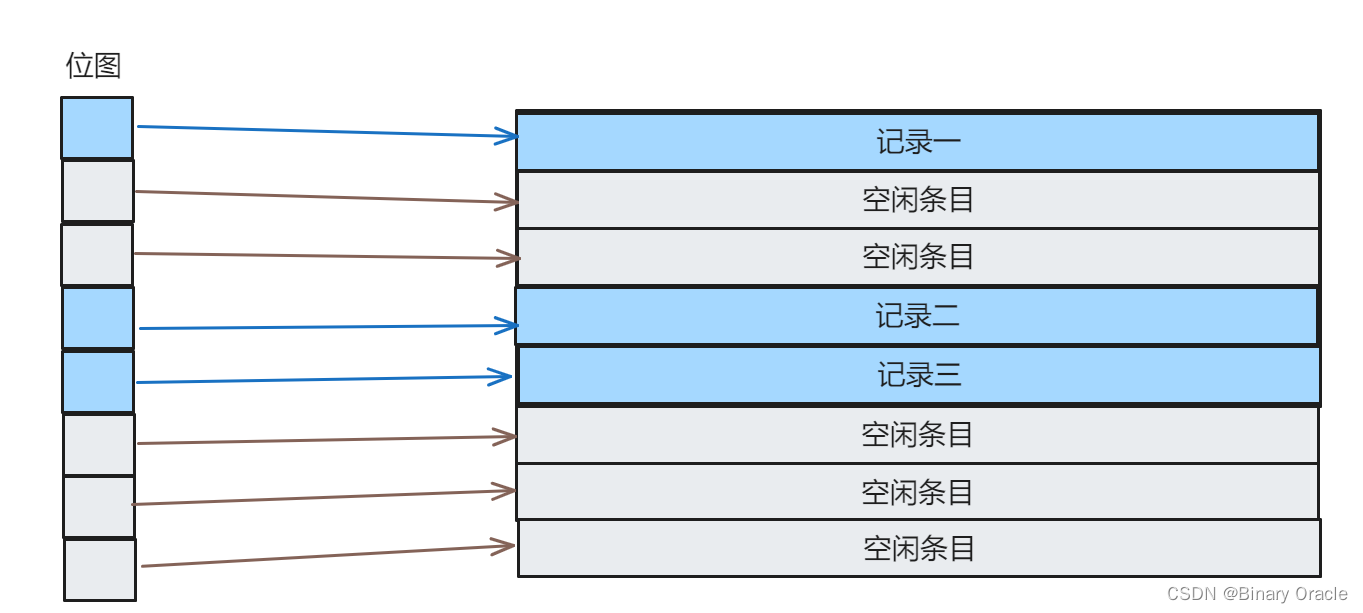
- simpleDB目前只支持整数和固定长度字符串,这意味每一行记录的大小都是固定的,因此实现非常简单,缺点就是不灵活,变长字段处理可以参考innodb存储引擎思考如何实现。
- 因为每一行大小固定,所以我们可以考虑采用位图记录当前Page中的空闲情况,每一位对应一个条目,simpleDB就是这样做的,在SimpleDB中位图中每一位被称为一个Slot槽
Tuple:
- Tuple作为表的行数据实际载体,需要保存表的Schema用于解释字段的含义,以及各个字段实际的数据和当前行记录ID
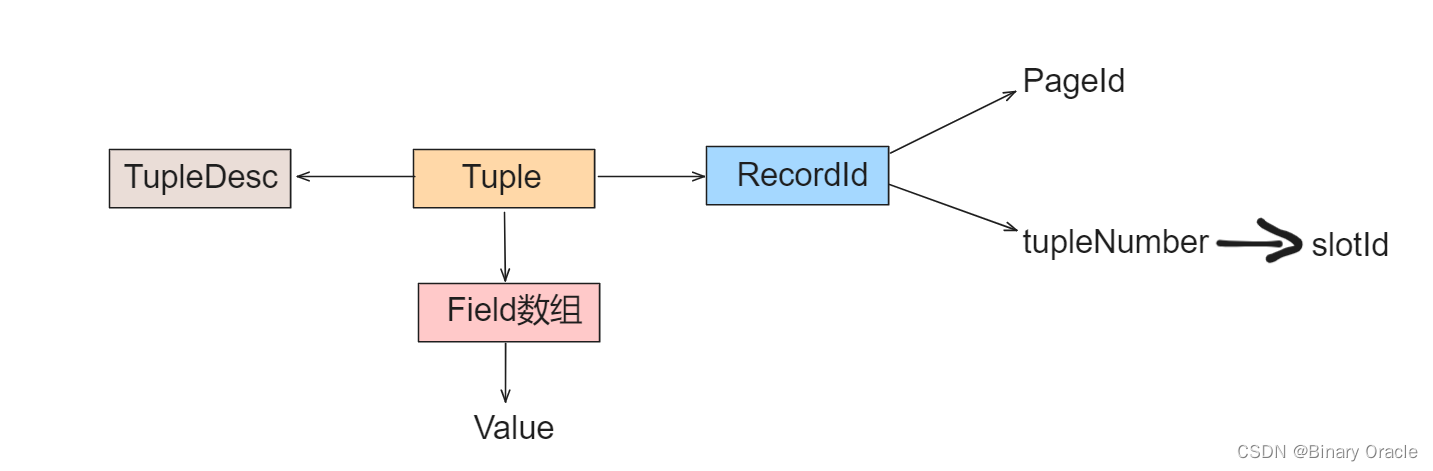
- Tuple类核心源码如下:
/**
* Tuple maintains information about the contents of a tuple. Tuples have a
* specified schema specified by a TupleDesc object and contain Field objects
* with the data for each field.
*/
public class Tuple implements Serializable {
private TupleDesc tupleDesc;
private final Field[] fields;
private RecordId recordId;
/**
* Create a new tuple with the specified schema (type).
*/
public Tuple(TupleDesc td) {
this.tupleDesc = td;
this.fields = new Field[td.numFields()];
}
/**
* Set the RecordId information for this tuple.
*/
public void setRecordId(RecordId rid) {
recordId = rid;
}
/**
* Change the value of the ith field of this tuple.
*/
public void setField(int i, Field f) {
fields[i] = f;
}
/**
* @param i field index to return. Must be a valid index.
* @return the value of the ith field, or null if it has not been set.
*/
public Field getField(int i) {
return fields[i];
}
/**
* @return An iterator which iterates over all the fields of this tuple
*/
public Iterator<Field> fields() {
return Arrays.asList(this.fields).iterator();
}
/**
* reset the TupleDesc of this tuple (only affecting the TupleDesc)
*/
public void resetTupleDesc(TupleDesc td) {
this.tupleDesc = td;
}
...
}
练习二
Catalog:
- catalog由数据库中现存的表的列表和表对应的schema数据组成,我们将实现向catalog中添加table以及获取table信息的功能。与table关联的是一个TupleDesc对象,通过该对象可以确定表字段个数和类型
- SimpleDB含有一个Catalog的单例,我们可以通过Database.getCatalog()方法获取到该单例对象,可以通Database.getBufferPool()获取到单例BufferPool对象
实现下面类的方法:
- src/java/simpledb/common/Catalog.java
我们实现的代码应该通过CatalogTest单元测试。
Catalog:
- simpleDB只有一个全局单例的数据库,其中Catalog作为目录管理数据库下所有表
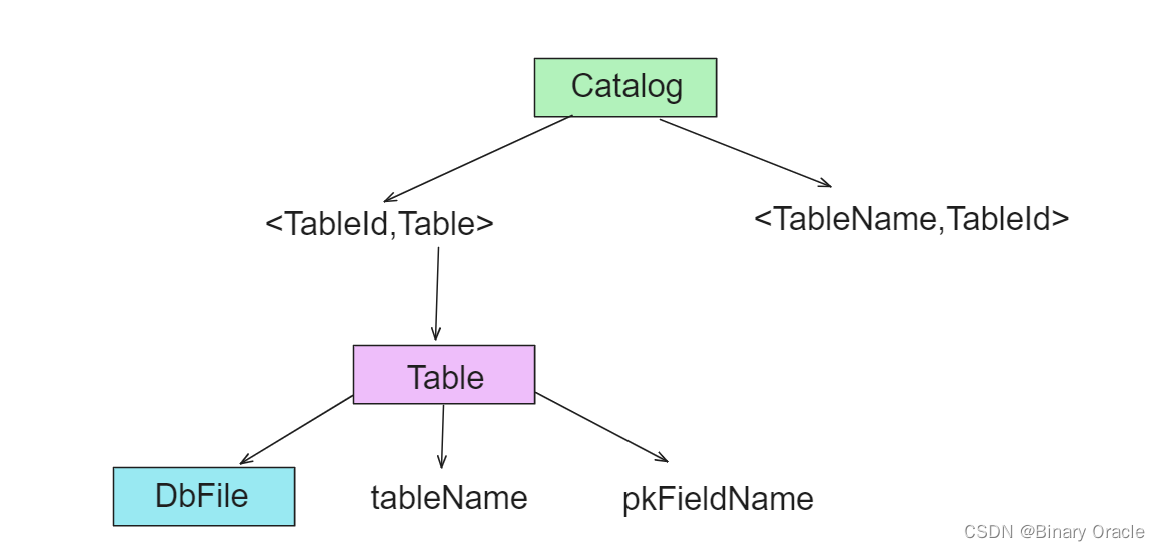
- Catalog核心源码如下:
/**
* The Catalog keeps track of all available tables in the database and their
* associated schemas.
* For now, this is a stub catalog that must be populated with tables by a
* user program before it can be used -- eventually, this should be converted
* to a catalog that reads a catalog table from disk.
*
* Catalog负责管理数据库中所有的table和其对应的schema
* @Threadsafe
*/
public class Catalog {
/**
* 通过Table类存储表的相关信息
*/
public class Table {
private DbFile file;
private String name;
private String pkeyField;
public Table(DbFile file, String name, String pkeyField) {
this.file = file;
this.name = name;
this.pkeyField = pkeyField;
}
}
/**
* key:DbFile#getId()
* value:Table Info
*/
private Map<Integer, Table> tables;
/**
* key:table name
* value:table id
*/
private Map<String, Integer> nameToId;
/**
* Constructor.
* Creates a new, empty catalog.
*/
public Catalog() {
tables = new ConcurrentHashMap<>();
nameToId = new ConcurrentHashMap<>();
}
/**
* Add a new table to the catalog.
* This table's contents are stored in the specified DbFile.
*/
public void addTable(DbFile file, String name, String pkeyField) {
Table table = new Table(file, name, pkeyField);
tables.put(file.getId(), table);
nameToId.put(name, file.getId());
}
public void addTable(DbFile file, String name) {
addTable(file, name, "");
}
/**
* Add a new table to the catalog.
* This table has tuples formatted using the specified TupleDesc and its
* contents are stored in the specified DbFile.
*/
public void addTable(DbFile file) {
addTable(file, (UUID.randomUUID()).toString());
}
/**
* Return the id of the table with a specified name,
*/
public int getTableId(String name) throws NoSuchElementException {
if (null == name || !nameToId.containsKey(name)) {
throw new NoSuchElementException("A table named " + name + " does not exist");
}
return nameToId.get(name);
}
/**
* Returns the tuple descriptor (schema) of the specified table
*/
public TupleDesc getTupleDesc(int tableid) throws NoSuchElementException {
if (tables.containsKey(tableid)) {
Table table = tables.get(tableid);
return table.file.getTupleDesc();
}
throw new NoSuchElementException("Table " + tableid + " does not exist");
}
/**
* Returns the DbFile that can be used to read the contents of the
* specified table.
*/
public DbFile getDatabaseFile(int tableid) throws NoSuchElementException {
if (tables.containsKey(tableid)) {
return tables.get(tableid).file;
}
throw new NoSuchElementException("Table " + tableid + " does not exist");
}
public String getPrimaryKey(int tableid) {
if (tables.containsKey(tableid)) {
return tables.get(tableid).pkeyField;
}
return null;
}
public Iterator<Integer> tableIdIterator() {
return tables.keySet().iterator();
}
public String getTableName(int id) {
if (tables.containsKey(id)) {
Table table = tables.get(id);
return table.name;
}
return null;
}
/**
* Delete all tables from the catalog
*/
public void clear() {
tables.clear();
nameToId.clear();
}
...
}
练习三
BufferPool:
- buffer pool代码是最近从磁盘读取的页在内存的缓存,所有从磁盘文件读取或写入页的操作都通过buffer pool实现。
- 它由固定数量的页组成,我们可以通过BufferPool的构造函数参数numPages指定页的数量。
- 在后续的实验中,我们需要实现驱逐策略。
- 在本次实验中,我们只需要实现构造函数和BufferPool.getPage()方法。
- BufferPool应该存储numPages,使用numPages的目的是为了当不同的页的数量超过numPages时,我们需要通过拒绝策略丢弃部分页。
实现BufferPool类中的getPage()方法:
- src/java/simpledb/storage/BufferPool.java
项目中并没有提供BufferPool的单元测试,但是我们实现的功能将会被HeapFile测试,我们需要通过DbFile.readPage方法访问DbFile的页
当在BufferPool中超过numPages数量的页时,我们应当在下一个页加载时丢弃一个页,丢弃策略由我们自己实现。
BufferPool:
- BufferPool作为数据库的页缓存池,负责Page的管理和淘汰
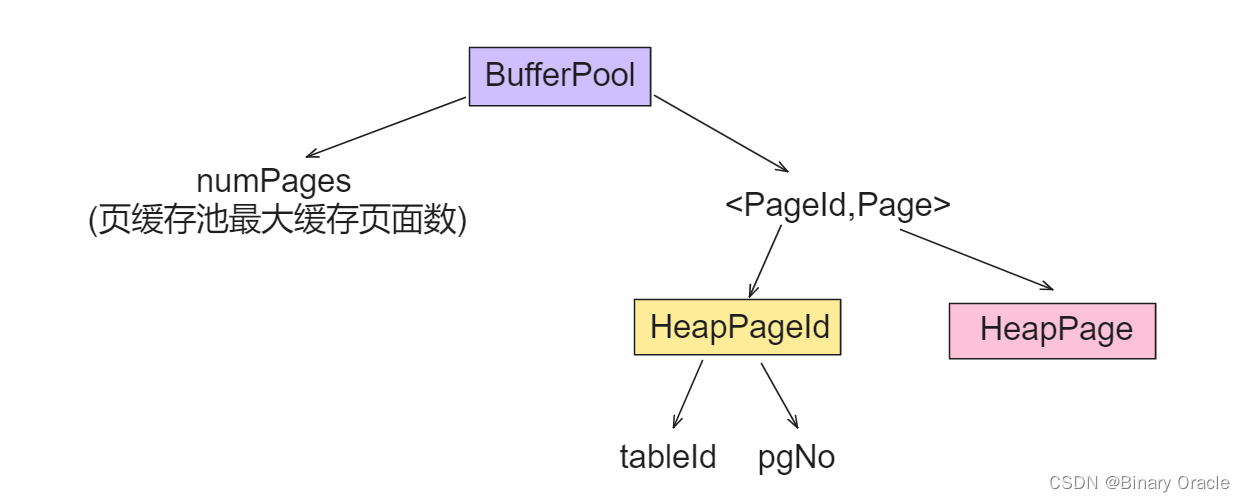
- BufferPool类核心源码如下:
/**
* BufferPool manages the reading and writing of pages into memory from
* disk. Access methods call into it to retrieve pages, and it fetches
* pages from the appropriate location.
*
* The BufferPool is also responsible for locking; when a transaction fetches
* a page, BufferPool checks that the transaction has the appropriate
* locks to read/write the page.
*
* @Threadsafe, all fields are final
*/
public class BufferPool {
/**
* Bytes per page, including header.
*/
private static final int DEFAULT_PAGE_SIZE = 4096;
private static int pageSize = DEFAULT_PAGE_SIZE;
/**
* Default number of pages passed to the constructor. This is used by
* other classes. BufferPool should use the numPages argument to the
* constructor instead.
*/
public static final int DEFAULT_PAGES = 50;
private final Integer numPages;
private final Map<PageId, Page> pageCache;
/**
* Creates a BufferPool that caches up to numPages pages.
*
* @param numPages maximum number of pages in this buffer pool.
*/
public BufferPool(int numPages) {
this.numPages = numPages;
pageCache = new ConcurrentHashMap<>();
}
public static int getPageSize() {
return pageSize;
}
// THIS FUNCTION SHOULD ONLY BE USED FOR TESTING!!
public static void setPageSize(int pageSize) {
BufferPool.pageSize = pageSize;
}
// THIS FUNCTION SHOULD ONLY BE USED FOR TESTING!!
public static void resetPageSize() {
BufferPool.pageSize = DEFAULT_PAGE_SIZE;
}
/**
* Retrieve the specified page with the associated permissions.
* Will acquire a lock and may block if that lock is held by another
* transaction.
*
* The retrieved page should be looked up in the buffer pool. If it
* is present, it should be returned. If it is not present, it should
* be added to the buffer pool and returned. If there is insufficient
* space in the buffer pool, a page should be evicted and the new page
* should be added in its place.
*/
public Page getPage(TransactionId tid, PageId pid, Permissions perm)
throws TransactionAbortedException, DbException {
if (!pageCache.containsKey(pid)) {
DbFile dbFile = Database.getCatalog().getDatabaseFile(pid.getTableId());
Page page = dbFile.readPage(pid);
pageCache.put(pid, page);
}
return pageCache.get(pid);
}
...
}
注意: 各个练习中只会列举出与当前Lab相关的核心代码。
练习四
HeapFile访问方法:
-
访问方法提供一种(以指定方式排列在磁盘上的文件)读取或写入数据的方式。通用访问方法包括heap files和B-tree,本次实验我们将会实现heap file访问方法
-
HeapFile对象被排列在一系列页中,每个页包含固定数量(
BufferPool.DEFAULT_PAGE_SIZE)的字节用于存储元组,以及header(以bitmap的形式描述tuple的可用性)。 -
在SimpleDB中,每个表都对应一个HeapFile对象。HeapFile中的每个页以一系列的槽表示,每个槽表示一个元组,除了这些槽之外,每个页还包含一个header;
-
header由一个bitmap组成,每个bit代表对应的槽,如果bit为1代表槽中元组可用,bit为0代表槽中元组不可用(被删除了、或者未初始化)。
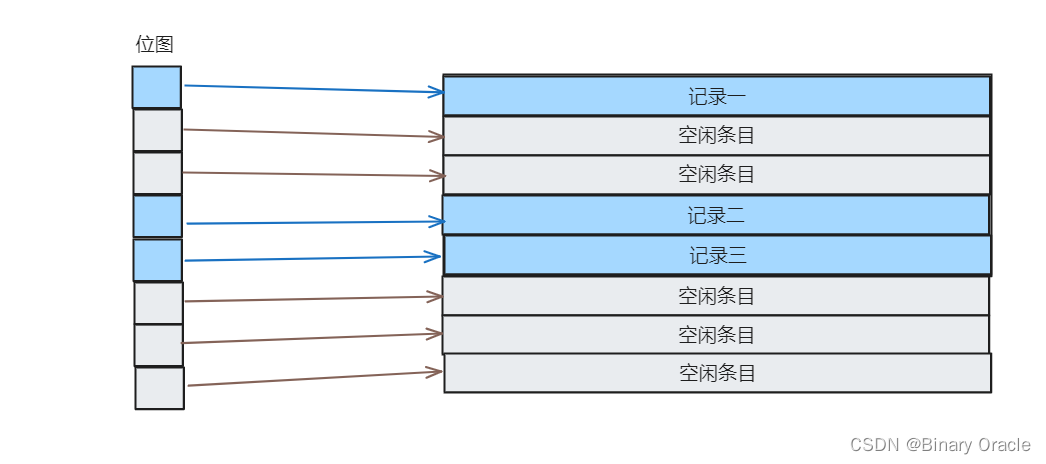
-
HeapFile中的页是实现了Page接口HeapPage类。页存储在buffer pool中但是通过HeapFile类进行读取或者写入
SimpleDB存储在磁盘上的heap file与存储在内存上的数据格式一样,每个文件由在磁盘上连续排列的页数据组成。每个页由代表header的字节以及实际的页内容的字节组成。每个元组所占大小为tuple_size * 8 bits+1 header bit;因此,每个页包含的tuple数量可通过如下公式计算:
// 将页大小单位转换为bit / (每行数据固定大小转换为bit + 对应位图中一个bit) = 页中行数量
tuples_per_page = floor((page_size * 8) / (tuple_size * 8 + 1))
tuple_size为每个tuple在页中所占字节数,因为每个tuple除了自身内容占用的字节数外,还有1bit的头部数据来表示tuple的可用性,所以每页包含的元组个数需要通过上式计算。
当我们知道一页的元组数时,我们可以计算头部所需字节数:
// 位图大小(需要多少bit) = 一页中所能存放的tuple数量
// 位图大小(需要多少字节) = 位图大小(需要多少bit) / 8
headerBytes = ceiling(tuplesPerPage * 1.0 / 8)
ceiling操作直接进位,求大于某数的最小整数。
每个字节的低位bit代表文件中出现在前的槽的状态,因此,最低为代表第一个槽是否使用,第二低位代表第二个槽是否使用,依此类推。
这是因为Java二进制文件中的所有东西都以big-endian形式存在,高字节优先,可以参考博文:Big Endian 和 Little Endian 详解
实现下面类的方法:
- src/java/simpledb/storage/HeapPageId.java
- src/java/simpledb/storage/RecordId.java
- src/java/simpledb/storage/HeapPage.java
此时,我们的代码应该通过HeapPageIdTest, RecordIdTest, and HeapPageReadTest单元测试。
HeapPageId:
- 描述HeadPage的页号信息
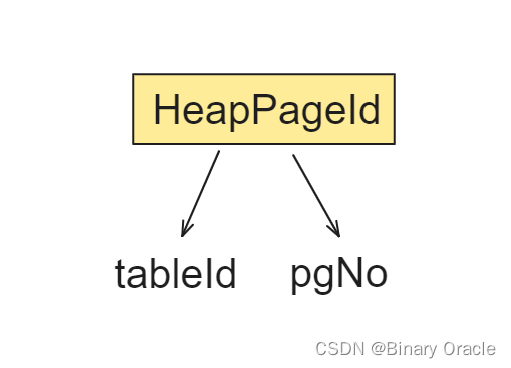
- HeapPageId核心源码如下:
/**
* Unique identifier for HeapPage objects.
*/
public class HeapPageId implements PageId {
private final int tableId;
private final int pgNo;
/**
* Constructor. Create a page id structure for a specific page of a
* specific table.
*/
public HeapPageId(int tableId, int pgNo) {
this.tableId = tableId;
this.pgNo = pgNo;
}
/**
* Return a representation of this object as an array of
* integers, for writing to disk. Size of returned array must contain
* number of integers that corresponds to number of args to one of the
* constructors.
*/
public int[] serialize() {
int[] data = new int[2];
data[0] = getTableId();
data[1] = getPageNumber();
return data;
}
....
}
RecordId:
- 描述记录ID的信息
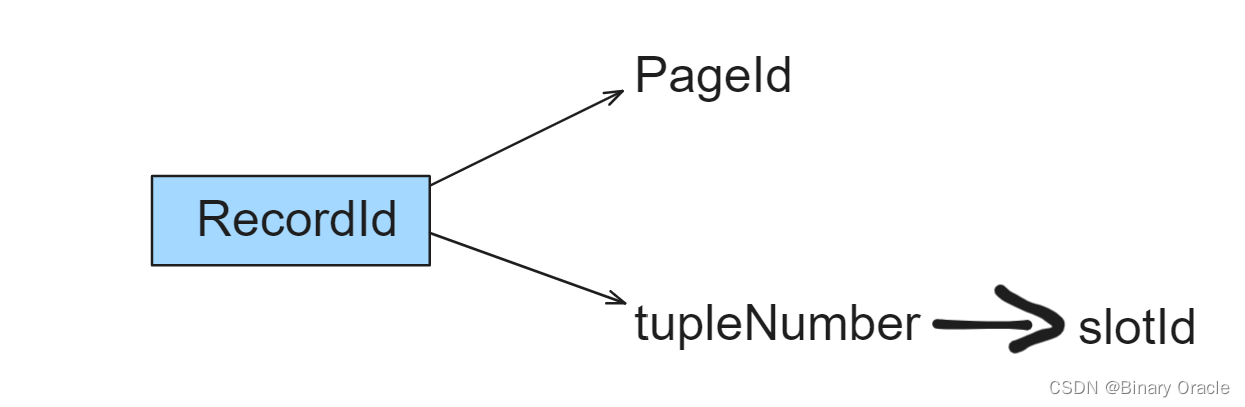
- RecordId核心源码如下:
/**
* A RecordId is a reference to a specific tuple on a specific page of a
* specific table.
*/
public class RecordId implements Serializable {
private final PageId pageId;
private final int tupleNumber;
/**
* Creates a new RecordId referring to the specified PageId and tuple
* number.
*/
public RecordId(PageId pid, int tupleno) {
this.pageId = pid;
this.tupleNumber = tupleno;
}
...
}
HeapPage:
- HeapPage负责维护当前数据页,包括数据页的布局,页号,数据的组织方式等
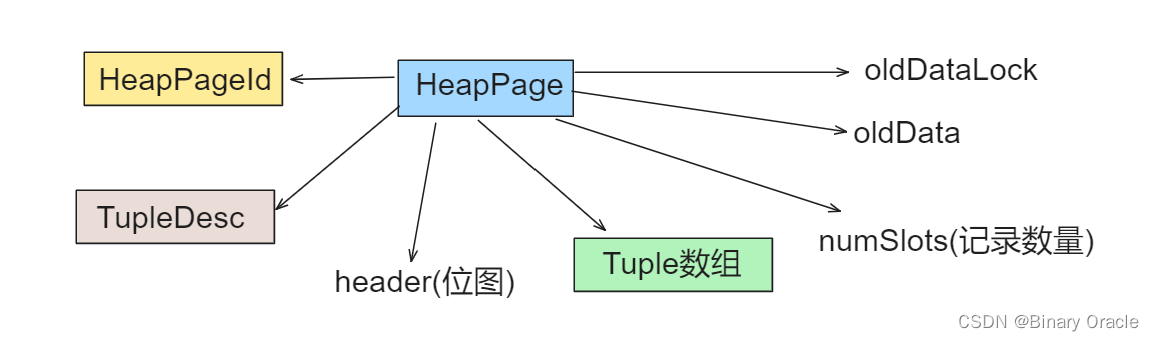
- HeapPage类核心源码如下:
/**
* Each instance of HeapPage stores data for one page of HeapFiles and
* implements the Page interface that is used by BufferPool.
*/
public class HeapPage implements Page {
final HeapPageId pid;
final TupleDesc td;
final byte[] header;
final Tuple[] tuples;
final int numSlots;
byte[] oldData;
private final Byte oldDataLock = (byte) 0;
/**
* Create a HeapPage from a set of bytes of data read from disk.
* The format of a HeapPage is a set of header bytes indicating
* the slots of the page that are in use, some number of tuple slots.
* Specifically, the number of tuples is equal to: <p>
* floor((BufferPool.getPageSize()*8) / (tuple size * 8 + 1))
* <p> where tuple size is the size of tuples in this
* database table, which can be determined via {@link Catalog#getTupleDesc}.
* The number of 8-bit header words is equal to:
* ceiling(no. tuple slots / 8)
*/
public HeapPage(HeapPageId id, byte[] data) throws IOException {
this.pid = id;
this.td = Database.getCatalog().getTupleDesc(id.getTableId());
this.numSlots = getNumTuples();
DataInputStream dis = new DataInputStream(new ByteArrayInputStream(data));
// allocate and read the header slots of this page
header = new byte[getHeaderSize()];
for (int i = 0; i < header.length; i++)
header[i] = dis.readByte();
tuples = new Tuple[numSlots];
try {
// allocate and read the actual records of this page
for (int i = 0; i < tuples.length; i++)
tuples[i] = readNextTuple(dis, i);
} catch (NoSuchElementException e) {
e.printStackTrace();
}
dis.close();
//暂时不关心
setBeforeImage();
}
/**
* Retrieve the number of tuples on this page.
*/
private int getNumTuples() {
// Bytes per page, including header
int pageSize = BufferPool.getPageSize();
return ((int) Math.floor((pageSize * 8 * 1.0) / (td.getSize() * 8 + 1)));
}
/**
* Computes the number of bytes in the header of a page in a HeapFile with each tuple occupying tupleSize bytes
*/
private int getHeaderSize() {
// 注意 * 1.0,否则无法满足要求,因为getNumTuples是整数,直接getNumTuples() / 8得到的是整数
// 除8是将单位从bit转换为Byte
return (int) Math.ceil(getNumTuples() * 1.0 / 8);
}
public HeapPageId getId() {
return pid;
}
/**
* Suck up tuples from the source file.
*/
private Tuple readNextTuple(DataInputStream dis, int slotId) throws NoSuchElementException {
// if associated bit is not set, read forward to the next tuple, and
// return null.
if (!isSlotUsed(slotId)) {
for (int i = 0; i < td.getSize(); i++) {
try {
dis.readByte();
} catch (IOException e) {
throw new NoSuchElementException("error reading empty tuple");
}
}
return null;
}
// read fields in the tuple
Tuple t = new Tuple(td);
// 记录ID就是SlotId
RecordId rid = new RecordId(pid, slotId);
t.setRecordId(rid);
try {
for (int j = 0; j < td.numFields(); j++) {
Field f = td.getFieldType(j).parse(dis);
t.setField(j, f);
}
} catch (java.text.ParseException e) {
e.printStackTrace();
throw new NoSuchElementException("parsing error!");
}
return t;
}
/**
* Generates a byte array representing the contents of this page.
* Used to serialize this page to disk.
*
* The invariant here is that it should be possible to pass the byte
* array generated by getPageData to the HeapPage constructor and
* have it produce an identical HeapPage object.
*/
public byte[] getPageData() {
int len = BufferPool.getPageSize();
ByteArrayOutputStream baos = new ByteArrayOutputStream(len);
DataOutputStream dos = new DataOutputStream(baos);
// create the header of the page
for (byte b : header) {
try {
dos.writeByte(b);
} catch (IOException e) {
// this really shouldn't happen
e.printStackTrace();
}
}
// create the tuples
for (int i = 0; i < tuples.length; i++) {
// empty slot
if (!isSlotUsed(i)) {
for (int j = 0; j < td.getSize(); j++) {
try {
dos.writeByte(0);
} catch (IOException e) {
e.printStackTrace();
}
}
continue;
}
// non-empty slot
for (int j = 0; j < td.numFields(); j++) {
Field f = tuples[i].getField(j);
try {
f.serialize(dos);
} catch (IOException e) {
e.printStackTrace();
}
}
}
// padding
int zerolen = BufferPool.getPageSize() - (header.length + td.getSize() * tuples.length); //- numSlots * td.getSize();
byte[] zeroes = new byte[zerolen];
try {
dos.write(zeroes, 0, zerolen);
} catch (IOException e) {
e.printStackTrace();
}
try {
dos.flush();
} catch (IOException e) {
e.printStackTrace();
}
return baos.toByteArray();
}
/**
* Static method to generate a byte array corresponding to an empty
* HeapPage.
* Used to add new, empty pages to the file. Passing the results of
* this method to the HeapPage constructor will create a HeapPage with
* no valid tuples in it.
*/
public static byte[] createEmptyPageData() {
int len = BufferPool.getPageSize();
return new byte[len]; //all 0
}
/**
* Returns the number of empty slots on this page.
*/
public int getNumEmptySlots() {
int empty = 0;
for (int i = 0; i < numSlots; i++) {
if (!isSlotUsed(i)) {
empty++;
}
}
return empty;
}
/**
* Returns true if associated slot on this page is filled.
*/
public boolean isSlotUsed(int i) {
// header是字节数组,i是位图中第几个槽,所以要限定为到处于哪个字节,再定位位于第几位
// 找到i所处header字节数组的位置
int byteIndex = i / 8;
// i处于字节的第几位
int bitIndex = i % 8;
// 判断该位是否为1
int flag = (header[byteIndex] >> bitIndex) & 1;
return flag == 1;
}
public Iterator<Tuple> iterator() {
List<Tuple> tupleList = new ArrayList<>();
// 将非空的槽的数据加入迭代器中
for (int i = 0; i < numSlots; i++) {
if (isSlotUsed(i)) {
tupleList.add(this.tuples[i]);
}
}
return tupleList.iterator();
}
...
}
练习五
实现下面类中的方法:
- src/java/simpledb/storage/HeapFile.java
为了从磁盘读取页,我们首先需要计算正确的偏移量。
提示:使用RandomAccessFile访问文件即可
我们还需要实现HeapFile.iterator()方法,通过该方法遍历HeapFile中每个页中存储的元组。迭代器需要通过BufferPool.getPage()方法访问HeapFile的页。该方法会将页加载到buffer pool中并且最终被用于实现基于锁的并发访问和恢复,不要在open方法中将整个表加载到内存中,这可能会引发oom。
HeapFile:
- HeapFile可以看做一张表,HeapFile对应磁盘上一个具体的文件,该文件由一堆HeapPage组成,TupleDesc描述表的Schema。
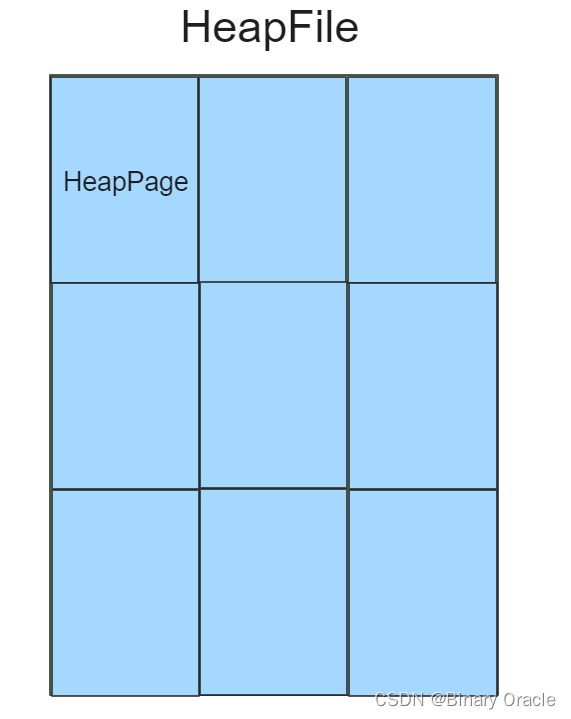
- HeapFile类核心源码如下:
/**
* HeapFile is an implementation of a DbFile that stores a collection of tuples
* in no particular order. Tuples are stored on pages, each of which is a fixed
* size, and the file is simply a collection of those pages. HeapFile works
* closely with HeapPage. The format of HeapPages is described in the HeapPage
* constructor.
*/
public class HeapFile implements DbFile {
private final File file;
private final TupleDesc tupleDesc;
/**
* Constructs a heap file backed by the specified file.
*
* @param f the file that stores the on-disk backing store for this heap
* file.
*/
public HeapFile(File f, TupleDesc td) {
this.file = f;
this.tupleDesc = td;
}
/**
* Returns the File backing this HeapFile on disk.
*
* @return the File backing this HeapFile on disk.
*/
public File getFile() {
return this.file;
}
/**
* Returns an ID uniquely identifying this HeapFile.
* Implementation note:
* you will need to generate this tableid somewhere to ensure that each
* HeapFile has a "unique id," and that you always return the same value for
* a particular HeapFile. We suggest hashing the absolute file name of the
* file underlying the heapfile, i.e. f.getAbsoluteFile().hashCode().
*
* @return an ID uniquely identifying this HeapFile.
*/
public int getId() {
return this.file.getAbsolutePath().hashCode();
}
/**
* Returns the TupleDesc of the table stored in this DbFile.
*
* @return TupleDesc of this DbFile.
*/
public TupleDesc getTupleDesc() {
return tupleDesc;
}
// see DbFile.java for javadocs
public Page readPage(PageId pid) {
// 计算page对应的偏移量
int pageSize = BufferPool.getPageSize();
int pageNumber = pid.getPageNumber();
int offset = pageSize * pageNumber;
//初始化空page
Page page;
try (RandomAccessFile randomAccessFile = new RandomAccessFile(file, "r")) {
byte[] data = new byte[pageSize];
randomAccessFile.seek(offset);
randomAccessFile.read(data);
page = new HeapPage((HeapPageId) pid, data);
} catch (IOException e) {
throw new RuntimeException(e);
}
return page;
}
// see DbFile.java for javadocs
public void writePage(Page page) throws IOException {
// not necessary for lab1
int pageSize = BufferPool.getPageSize();
int pageNumber = page.getId().getPageNumber();
int offset = pageSize * pageNumber;
try (RandomAccessFile randomAccessFile = new RandomAccessFile(file, "rw")) {
randomAccessFile.seek(offset);
randomAccessFile.write(page.getPageData());
}
}
/**
* Returns the number of pages in this HeapFile.
*/
public int numPages() {
long length = this.file.length();
return ((int) Math.ceil(length * 1.0 / BufferPool.getPageSize()));
}
// see DbFile.java for javadocs
public DbFileIterator iterator(TransactionId tid) {
return new HeapFileIterator(this, tid);
}
public static final class HeapFileIterator implements DbFileIterator {
private final HeapFile heapFile;
private final TransactionId tid;
private Iterator<Tuple> iterator;
private int pageNumber;
public HeapFileIterator(HeapFile file, TransactionId tid) {
this.heapFile = file;
this.tid = tid;
}
@Override
public void open() throws DbException, TransactionAbortedException {
this.pageNumber = 0;
this.iterator = getPageTuples(pageNumber);
}
private Iterator<Tuple> getPageTuples(int pageNo) throws TransactionAbortedException, DbException {
if (pageNo >= 0 && pageNo < heapFile.numPages()) {
HeapPageId heapPageId = new HeapPageId(heapFile.getId(), pageNo);
HeapPage page = (HeapPage) Database.getBufferPool().getPage(tid, heapPageId, Permissions.READ_ONLY);
return page.iterator();
} else {
throw new DbException(String.format("heapfile %d does not contain page %d", pageNo, heapFile.getId()));
}
}
@Override
public boolean hasNext() throws DbException, TransactionAbortedException {
if (iterator == null) {
return false;
}
while (iterator != null && !iterator.hasNext()) {
if (pageNumber < (heapFile.numPages() - 1)) {
pageNumber++;
iterator = getPageTuples(pageNumber);
} else {
iterator = null;
}
}
if (iterator == null) {
return false;
}
return iterator.hasNext();
}
@Override
public Tuple next() throws DbException, TransactionAbortedException, NoSuchElementException {
if (iterator == null || !iterator.hasNext()) {
throw new NoSuchElementException();
}
return iterator.next();
}
@Override
public void rewind() throws DbException, TransactionAbortedException {
close();
open();
}
@Override
public void close() {
iterator = null;
}
}
}
迭代器的实现参考:6.830 Lab 1: SimpleDB
此时,我们的代码应该通过HeapFileReadTest单元测试
练习六
Operators负责查询计划的实际执行,它们实现了关系代数的操作。在SimpleDB中,operators是基于迭代器的,每个操作都实现了DBIterator接口
Operators通过将低层次的操作传递给高层次操作的构造函数来连接整个执行计划;最低层次操作的访问方法负责从磁盘读取数据
在执行计划的顶端,程序通过调用根操作的getNext方法与SimpleDB进行交互;该操作将会调用子节点的getNext方法,依此类推,直接叶子结点的操作被调用。它们从磁盘读取元组数据
本次实验,我们将会实现一个简单的操作,实现下面类中的方法:
- src/java/simpledb/execution/SeqScan.java
该操作通过构造函数的tableid扫描指定表的页获取元组数据,需要通过DbFile.iterator()方法访问元组。
seqScan提供了一种顺序扫描的访问方法,通过对迭代器的封装完成这一操作:
/**
* SeqScan is an implementation of a sequential scan access method that reads
* each tuple of a table in no particular order (e.g., as they are laid out on
* disk).
*/
public class SeqScan implements OpIterator {
private static final long serialVersionUID = 1L;
private final Catalog catalog;
private final TransactionId tid;
private int tableId;
private TupleDesc tupleDesc;
private String tableName;
private String tableAlias;
private DbFileIterator iterator;
private DbFile file;
/**
* Creates a sequential scan over the specified table as a part of the
* specified transaction.
*/
public SeqScan(TransactionId tid, int tableid, String tableAlias) {
this.catalog = Database.getCatalog();
this.tid = tid;
this.tableId = tableid;
this.tupleDesc = changeTupleDesc(catalog.getTupleDesc(tableid), tableAlias);
this.tableName = catalog.getTableName(tableid);
this.tableAlias = tableAlias;
this.file = catalog.getDatabaseFile(tableid);
}
/**
* select * from testTable AS tt where tt.a=1 and tt.b=2 ;
*/
private TupleDesc changeTupleDesc(TupleDesc desc, String alias) {
List<TupleDesc.TDItem> items = new ArrayList<>();
List<TupleDesc.TDItem> tdItems = desc.getItems();
for (TupleDesc.TDItem tdItem : tdItems) {
TupleDesc.TDItem item = new TupleDesc.TDItem(tdItem.fieldType, alias + "." + tdItem.fieldName);
items.add(item);
}
return new TupleDesc(items);
}
/**
* @return return the table name of the table the operator scans. This should
* be the actual name of the table in the catalog of the database
*/
public String getTableName() {
return tableName;
}
/**
* @return Return the alias of the table this operator scans.
*/
public String getAlias() {
return tableAlias;
}
/**
* Reset the tableid, and tableAlias of this operator.
*/
public void reset(int tableid, String tableAlias) {
this.tableId = tableid;
this.tableAlias = tableAlias;
this.tupleDesc = changeTupleDesc(catalog.getTupleDesc(tableid), tableAlias);
this.tableName = catalog.getTableName(tableid);
this.file = catalog.getDatabaseFile(tableid);
try {
open();
} catch (DbException | TransactionAbortedException e) {
e.printStackTrace();
}
}
public SeqScan(TransactionId tid, int tableId) {
this(tid, tableId, Database.getCatalog().getTableName(tableId));
}
public void open() throws DbException, TransactionAbortedException {
this.iterator = this.file.iterator(this.tid);
iterator.open();
}
/**
* Returns the TupleDesc with field names from the underlying HeapFile,
* prefixed with the tableAlias string from the constructor. This prefix
* becomes useful when joining tables containing a field(s) with the same
* name. The alias and name should be separated with a "." character
* (e.g., "alias.fieldName"). */
public TupleDesc getTupleDesc() {
return this.tupleDesc;
}
public boolean hasNext() throws TransactionAbortedException, DbException {
if (iterator == null) {
return false;
}
return iterator.hasNext();
}
public Tuple next() throws NoSuchElementException,
TransactionAbortedException, DbException {
if (iterator == null) {
throw new NoSuchElementException("No next tuple");
}
Tuple tuple = iterator.next();
if (tuple == null) {
throw new NoSuchElementException("No next tuple");
}
return tuple;
}
public void close() {
iterator = null;
}
public void rewind() throws DbException, NoSuchElementException,
TransactionAbortedException {
iterator.rewind();
}
}
此时,我们的代码应该通过ScanTest系统测试
在后续的实验中我们会实现其他操作
练习七
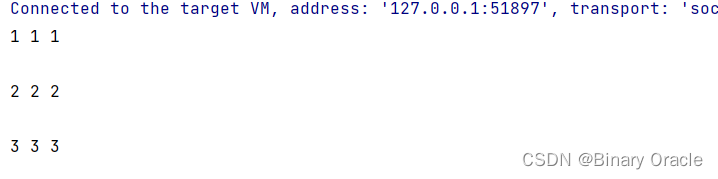
我们可以通过一个简单的文件来测试我们的SeqScan方法
我们需要自定义一个数据库文件some_data_file.txt,文件格式如下:
1,1,1
2,2,2
3,3,3
我们在构造txt文件时,需要在数据下面再空出一行,否则通过SimpleDB生成的文件无法读取到最后一行数据;可以通过阅读HeapFileEncoder.java中的convert方法找到原因所在。
接下来我们可以通过运行SimpleDb.java的main方法将.txt文件转换为.dat文件,我们可以通过idea来设置运行参数,或者将项目打包生成jar文件,通过命令行运行。
idea运行参数设置:
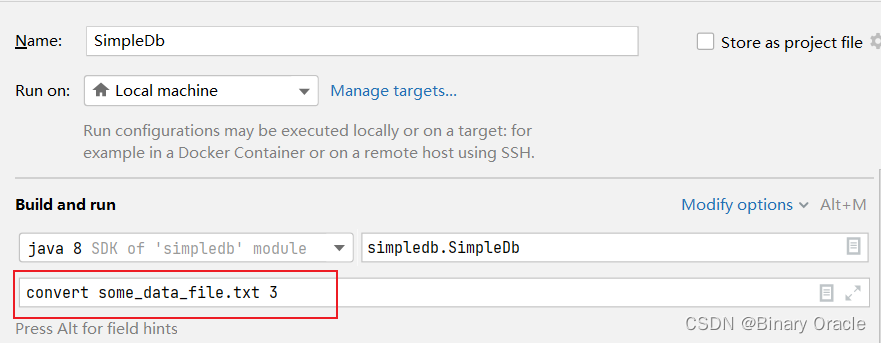
或者通过如下命令运行jar文件:
java -jar simpledb.jar convert some_data_file.txt 3
运行完成后会自动生成some_data_file.dat文件,接下来通过如下方法进行测试:
public class TestReadDatFile {
public static void main(String[] argv) {
// construct a 3-column table schema
Type types[] = new Type[]{Type.INT_TYPE, Type.INT_TYPE, Type.INT_TYPE};
String names[] = new String[]{"field0", "field1", "field2"};
TupleDesc descriptor = new TupleDesc(types, names);
// create the table, associate it with some_data_file.dat
// and tell the catalog about the schema of this table.
HeapFile table1 = new HeapFile(new File("some_data_file.dat"), descriptor);
Database.getCatalog().addTable(table1, "test");
// construct the query: we use a simple SeqScan, which spoonfeeds
// tuples via its iterator.
TransactionId tid = new TransactionId();
SeqScan f = new SeqScan(tid, table1.getId());
try {
// and run it
f.open();
while (f.hasNext()) {
Tuple tup = f.next();
System.out.println(tup);
}
f.close();
Database.getBufferPool().transactionComplete(tid);
} catch (Exception e) {
System.out.println("Exception : " + e);
}
}
}
最终输出结果如下: