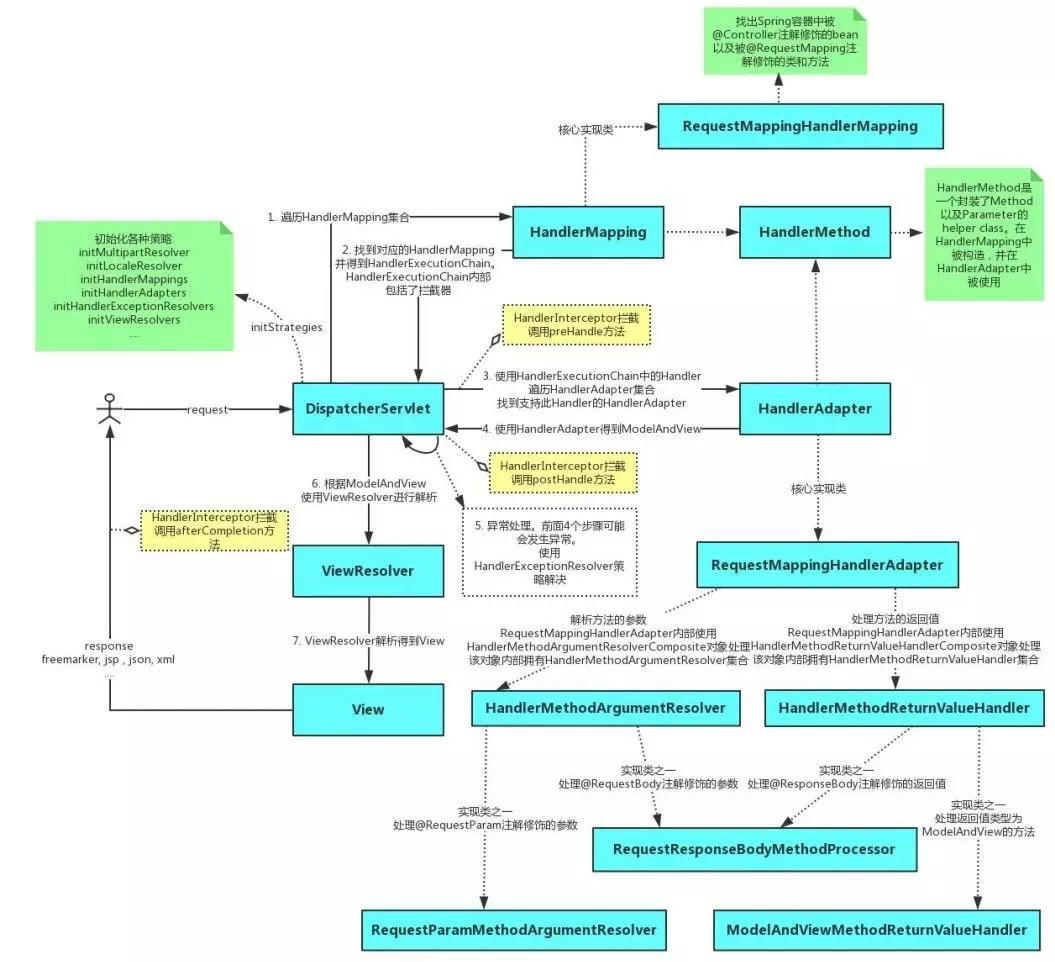
周赛链接:竞赛 - 力扣(LeetCode)全球极客挚爱的技术成长平台
1. 二进制矩阵中的特殊位置
给定一个
m x n的二进制矩阵mat,返回矩阵mat中特殊位置的数量。如果位置
(i, j)满足mat[i][j] == 1并且行i与列j中的所有其他元素都是0(行和列的下标从 0 开始计数),那么它被称为 特殊 位置。输入:mat = [[1,0,0],[0,0,1],[1,0,0]] 输出:1 解释:位置 (1, 2) 是一个特殊位置,因为 mat[1][2] == 1 且第 1 行和第 2 列的其他所有元素都是 0。输入:mat = [[1,0,0],[0,1,0],[0,0,1]] 输出:3 解释:位置 (0, 0),(1, 1) 和 (2, 2) 都是特殊位置。提示:
m == mat.lengthn == mat[i].length1 <= m, n <= 100mat[i][j]是0或1。
数据范围很小, 直接简单模拟, 定位到(i,j), 累加第i行和第j列的和是否为0
class Solution {
public:
int m,n;
int judge(int i,int j,vector<vector<int>>& mat){
int row=0,col=0;
for(int a=0;a<n;a++){
row+=mat[i][a];
}
for(int b=0;b<m;b++){
col+=mat[b][j];
}
if(row+col==2){
return 1;
}
return 0;
}
int numSpecial(vector<vector<int>>& mat) {
int ct=0; m=mat.size(); n=mat[0].size();
for(int i=0;i<m;i++){
for(int j=0;j<n;j++){
if(mat[i][j]==1){
ct+=judge(i,j,mat);
}
}
}
return ct;
}
};2. 统计不开心的朋友
给你一份
n位朋友的亲近程度列表,其中n总是 偶数 。对每位朋友
i,preferences[i]包含一份 按亲近程度从高到低排列 的朋友列表。换句话说,排在列表前面的朋友与i的亲近程度比排在列表后面的朋友更高。每个列表中的朋友均以0到n-1之间的整数表示。所有的朋友被分成几对,配对情况以列表
pairs给出,其中pairs[i] = [xi, yi]表示xi与yi配对,且yi与xi配对。但是,这样的配对情况可能会使其中部分朋友感到不开心。在
x与y配对且u与v配对的情况下,如果同时满足下述两个条件,x就会不开心:
x与u的亲近程度胜过x与y,且u与x的亲近程度胜过u与v返回 不开心的朋友的数目 。
示例 1:
输入:n = 4, preferences = [[1, 2, 3], [3, 2, 0], [3, 1, 0], [1, 2, 0]], pairs = [[0, 1], [2, 3]] 输出:2 解释: 朋友 1 不开心,因为: - 1 与 0 配对,但 1 与 3 的亲近程度比 1 与 0 高,且 - 3 与 1 的亲近程度比 3 与 2 高。 朋友 3 不开心,因为: - 3 与 2 配对,但 3 与 1 的亲近程度比 3 与 2 高,且 - 1 与 3 的亲近程度比 1 与 0 高。 朋友 0 和 2 都是开心的。示例 2:
输入:n = 2, preferences = [[1], [0]], pairs = [[1, 0]] 输出:0 解释:朋友 0 和 1 都开心。示例 3:
输入:n = 4, preferences = [[1, 3, 2], [2, 3, 0], [1, 3, 0], [0, 2, 1]], pairs = [[1, 3], [0, 2]] 输出:4提示:
2 <= n <= 500n是偶数preferences.length == npreferences[i].length == n - 10 <= preferences[i][j] <= n - 1preferences[i]不包含ipreferences[i]中的所有值都是独一无二的pairs.length == n/2pairs[i].length == 2xi != yi0 <= xi, yi <= n - 1- 每位朋友都 恰好 被包含在一对中
解题思路:根据题意我们知道, (i,j),(u,v), i与u的比i与j更亲近, u与i比u与v更亲近, 此时i就会不开心, pairs数组提供了配对, 我们要判断在这种配对下, 是否存在有人不开心。 代码实现上, 遍历preferences, 对preferences[i]中的按亲近程度分别用0,1,2...进行标记(数字越小越亲近)。然后遍历判断即可
class Solution {
public:
int unhappyFriends(int n, vector<vector<int>>& preferences, vector<vector<int>>& pairs) {
vector<vector<int>> a(n,vector<int>(n,0));
for(int i=0;i<n;i++){
for(int j=0;j<n-1;j++){
a[i][preferences[i][j]]=j;
}
}
//(i,j),(u,v), i与u的比i与j更亲近, u与i比u与v更亲近
vector<int> b(n,0);
for(int i=0;i<pairs.size();i++){
b[pairs[i][0]]=pairs[i][1]; b[pairs[i][1]]=pairs[i][0];
}
int ans=0;
for(int i=0;i<n;i++){
for(int j=0;j<n;j++){
// if(i!=j&&b[i]!=j){
if(i!=j){
int curI=b[i];
int curJ=b[j];
if(a[i][j]<a[i][curI]&&a[j][i]<a[j][curJ]){
ans++;
break;
}
// }
}
}
}
return ans;
}
};3. 连接所有点的最小费用
给你一个
points数组,表示 2D 平面上的一些点,其中points[i] = [xi, yi]。连接点
[xi, yi]和点[xj, yj]的费用为它们之间的 曼哈顿距离 :|xi - xj| + |yi - yj|,其中|val|表示val的绝对值。请你返回将所有点连接的最小总费用。只有任意两点之间 有且仅有 一条简单路径时,才认为所有点都已连接。
示例1:
输入:points = [[0,0],[2,2],[3,10],[5,2],[7,0]]
输出:20
示例2:
输入:points = [[3,12],[-2,5],[-4,1]]
输出:18
提示:
1 <= points.length <= 1000-106 <= xi, yi <= 106- 所有点
(xi, yi)两两不同。
解题思路: 题目就是让你构建一个最小生成树,返回最小总费用。构建最小生成树, 我们可以使用Prim 算法, 时间复杂度为O(n^2)
简单解释一下, Prim算法是图论中在构建最小生成树时用到的方法
Prim 算法
设N={V,E} 是连通网, TE是N上最小生成树中边的集合 {a,b} a 代表点, b代表边 -> 属于
1. 初始令U={u0},{u0->V},TE={ }
2. 在所有u->U, v->V-U的边(u,v)->E中,找一条代价最小的边(u0,v0). 注: 就是权值最小的边
3. 将(u0,v0) 这条边并入集合 TE, 同时 v0这个点并入U
4. 重复上述操作直至U=V为止, 则T=(V,TE) 为N 的最小生成树 (意思就是把所有的点都选进集合U, 所以前面写的是U=V)通俗解释:在U集合中选一个点和在U-V集合中选一个点, 使得这个权值的最小, 然后把弧上的顶点加入到集合U中, 直到U=T集合,得到的连通图就是最小生成树,前提是不能成环
class Solution {
struct Close {
int date;
int wed;
};
public:
void Prim(vector<vector<int>>& graph, int v, vector<Close>& clos, int& totalCost) {
int n = graph.size();
for (int i = 0; i < n; i++) {
clos[i].date = v;
clos[i].wed = graph[v][i];
}
clos[v].wed = 0;
for (int i = 1; i < n; i++) {
int k = -1;
int minW = INT_MAX;
for (int j = 0; j < n; j++) {
if (clos[j].wed != 0 && clos[j].wed < minW) {
minW = clos[j].wed;
k = j;
}
}
//if (k == -1) break; // 图不连通
totalCost += clos[k].wed;
clos[k].wed = 0;
for (int j = 0; j < n; j++) {
if (graph[k][j] < clos[j].wed) {
clos[j].date = k;
clos[j].wed = graph[k][j];
}
}
}
}
int minCostConnectPoints(vector<vector<int>>& points) {
int n = points.size();
vector<vector<int>> graph(n, vector<int>(n, INT_MAX)); //构建邻接矩阵
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
int w = abs(points[i][0] - points[j][0]) + abs(points[i][1] - points[j][1]);
graph[i][j] = w;
graph[j][i] = w;
}
}
vector<Close> clos(n);
int totalCost = 0;
Prim(graph, 0, clos, totalCost);
return totalCost;
}
};
//points[i]=[Xi,Yi] 表示一个坐标
//连接点 [xi, yi] 和点 [xj, yj] 的费用为|xi - xj| + |yi - yj|
//返回构建最小生成树所需要的最小费用4.检查字符串是否可以通过排序子字符串得到另一个字符串
给你两个字符串
s和t,请你通过若干次以下操作将字符串s转化成字符串t:
- 选择
s中一个 非空 子字符串并将它包含的字符就地 升序 排序。比方说,对下划线所示的子字符串进行操作可以由
"14234"得到"12344"。如果可以将字符串
s变成t,返回true。否则,返回false。一个 子字符串 定义为一个字符串中连续的若干字符。
示例 1:
输入:s = "84532", t = "34852" 输出:true 解释:你可以按以下操作将 s 转变为 t : "84532" (从下标 2 到下标 3)-> "84352" "84352" (从下标 0 到下标 2) -> "34852"示例 2:
输入:s = "34521", t = "23415" 输出:true 解释:你可以按以下操作将 s 转变为 t : "34521" -> "23451" "23451" -> "23415"示例 3:
输入:s = "12345", t = "12435" 输出:false示例 4:
输入:s = "1", t = "2" 输出:false提示:
s.length == t.length1 <= s.length <= 105s和t都只包含数字字符,即'0'到'9'。
解题思路: 看示例3, 34 是不能通过排序得到43的,本题是一个贪心, 在实现上我们用一个前缀数组perfix去维护前j个元素中各个字符['0'-'9']出现的次数, 然后依次取出t中的各个字符, 对应到s中, 如果 S 中某个字符 c 前面有比 c(t中) 小的字符尚未被处理,则无法通过排序操作得到 t
// s = "84532", t = "34852"
s = "12345", t = "12435"
//t中某个字符t[i], 在s中的位置pos, 前面有字符c没有被处理(cnt_current[c]==0),
//如果 S 中某个字符 c 前面有比 c 小的字符尚未被处理,则无法通过排序操作得到 t
class Solution {
public:
bool isTransformable(string s, string t) {
int n = s.size();
vector<int> cnt_s(10, 0), cnt_t(10, 0); //统计每个字符出现的频率
for (char c : s) cnt_s[c - '0']++;
for (char c : t) cnt_t[c - '0']++;
if (cnt_s != cnt_t) return false; //没有继续判断的必要了
vector<vector<int>> prefix(n + 1, vector<int>(10, 0)); //统计任意前 j 个字符中各字符的出现次数
//prefix[i+1][d]/prefix[i][d]
for (int i = 0; i < n; i++) {
int c = s[i] - '0';
for (int d = 0; d < 10; d++) {
prefix[i + 1][d] = prefix[i][d];
}
prefix[i + 1][c]++;
}
vector<queue<int>> pos(10); //每个字符维护一个队列, 记录(每个字符)在s中出现的位置
for (int i = 0; i < n; i++) {
int c = s[i] - '0';
pos[c].push(i);
}
vector<int> cnt_current(10, 0);
for (int i = 0; i < n; i++) {
int c = t[i] - '0';
if (pos[c].empty()) return false;
int j = pos[c].front(); //对于 t 中的每个字符 c,从 pos[c] 中取出它在 s 中的最早出现位置 j
pos[c].pop();
for (int d = 0; d < c; d++) {
if (prefix[j][d] > cnt_current[d]) {
return false;
}
}
cnt_current[c]++;
}
return true;
}
};对比现在的周赛, 题目的难度确实提升了不少, 对题目/代码有疑问, 可以发布到评论区, 感谢!