随着互联网垂直电商、消费金融等领域的快速崛起,用户及互联网、金融平台受到欺诈的风险也急剧增加。网络黑灰产已形成完整的、成熟的产业链,每年千亿级别的投入规模,超过1000万的“从业者”,其专业度也高于大多数技术人员,给互联网及金融平台的攻防对抗带来严峻的挑战。因此,我们需要一款风控引擎系统为互联网、银行及金融场景下的业务反欺诈和信用风控管理,提供一站式全流程的自动化决策服务。

而数据是风控决策引擎中不可或缺的组成部分,包括历史数据、实时风险数据、行为数据等等,不仅提供关键的信息和指示,更有助于做出明智的决策。通过不断地收集、分析和利用数据,风控引擎可以更好地理解市场变化和顾客需求的变化,分析和识别潜在的风险因素,实现更准确的预测和预警,进而及时调整风险控制策略。
因此,数据的质量和准确性是非常重要,风控引擎的数据聚合产品支持不同类型、不同调用方式的外部渠道数据,不仅使用到大量的政务、业务数据,并在多渠道引入数据,然后进行统一管理和数据的规范处理,解决从数据源接入至数据应用的问题,全面支撑风控引擎对数据应用的需求。
什么时候需要接入不同的数据源
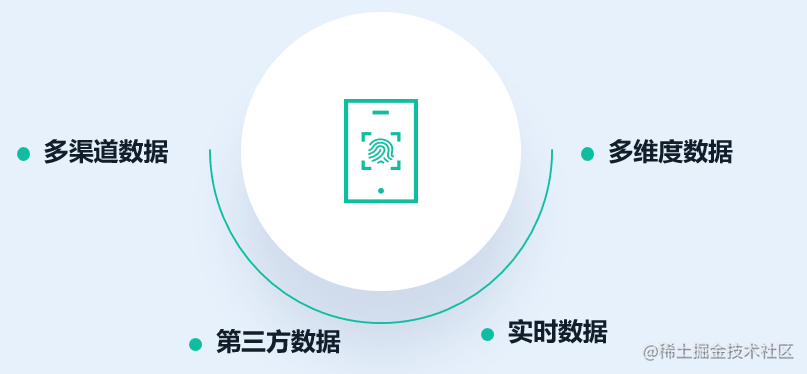
- 多渠道数据: 风控引擎可能需要从多个渠道获取数据,如在线交易平台、移动应用程序、电子支付系统等。每个渠道可能提供不同格式和类型的数据,因此需要接入不同的数据源来获取所需的信息。
- 第三方数据: 为了更全面地评估风险,风控引擎可能需要使用第三方数据源,如信用机构、反欺诈服务提供商、黑名单数据库等。这些数据源通常具有独立的接口和访问方式,需要与风控引擎集成以获取相关数据。
- 实时数据: 对于需要进行实时决策的风控场景,风控引擎需要接入实时数据源。例如,实时交易风控需要接收实时交易数据以进行即时风险评估和决策。
- 多维度数据: 风控引擎可能需要从不同的数据源获取多维度的数据来进行综合分析和风险评估。例如,除了交易数据,可能还需要获取用户行为数据、设备信息、地理位置数据等来综合判断风险。
数据源接入
我们先展示一个使用Python和pandas库接入CSV文件作为数据源的简单代码:
import pandas as pd
# 从CSV文件读取数据
def read_csv_data(csv_file_path):
data = pd.read_csv(csv_file_path)
# 执行其他必要的数据预处理操作
# ...
return data
# 接入不同的数据源示例
def integrate_data_from_multiple_sources():
# 数据源1:CSV文件
csv_file_path = 'path/to/your/csv/file.csv'
data_from_csv = read_csv_data(csv_file_path)
# 数据源2:其他数据源(根据具体情况处理)
# ...
# 执行数据集成和分析
# ...
# 返回结果或执行其他操作
# ...
# 调用示例函数
integrate_data_from_multiple_sources()
在这个示例中,read_csv_data()函数用于读取CSV文件,并可以根据需要进行数据预处理。integrate_data_from_multiple_sources()函数展示了如何从不同的数据源获取数据,并进行进一步的数据集成和分析。
那在此基础之上,我们再来介绍几种工具来帮我们快速接入不同的数据源。
1.Apache Kafka
当使用Apache Kafka时,它可以作为一个高可靠、高吞吐量的消息传递系统,帮助我们接入不同的数据源。
具体的过程可以看下面(简单的示例,仅供参考):
1)安装confluent-kafka库。可以使用以下命令安装:
pip install confluent-kafka
2)接入过程说明:我们可以使用confluent-kafka库连接到本地的Kafka集群。然后,使用Producer类将数据发送到指定的Kafka主题。不过,我们需要替换示例代码中的数据和主题名称,以符合实际情况。
接入示例:
from confluent_kafka import Producer
# Kafka配置
kafka_config = {
'bootstrap.servers': 'localhost:9092', # Kafka集群地址
'client.id': 'my-client-id' # 客户端ID
}
# 发送数据到Kafka主题
def send_data_to_kafka_topic(data, topic):
p = Producer(kafka_config)
try:
# 发送数据到指定主题
p.produce(topic, value=data)
p.flush() # 确保所有消息都发送完毕
print("数据已成功发送到Kafka主题")
except Exception as e:
print(f"发送数据失败: {str(e)}")
finally:
p.close()
# 示例函数
def integrate_data_using_kafka():
# 从数据源获取数据
data = "your_data_here" # 替换为你的数据
# Kafka主题名称
kafka_topic = "your_topic_here" # 替换为你的Kafka主题
# 发送数据到Kafka主题
send_data_to_kafka_topic(data, kafka_topic)
# 调用示例函数
integrate_data_using_kafka()
2.Apache Flink
使用Apache Flink时,它可以作为一个流处理引擎,帮助我们接入不同的数据源并进行实时数据处理。
具体的过程可以看下面(简单的示例,仅供参考):
1)安装pyflink库。
安装命令:
pip install apache-flink
2)使用pyflink库创建一个Flink流处理环境。然后,使用FlinkKafkaConsumer类创建一个Kafka消费者,它可以连接到指定的Kafka主题并接收数据流。同样,我们自己使用的时候需要替换下面代码中的Kafka主题名称。
直接上代码
from pyflink.common.serialization import SimpleStringSchema
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors import FlinkKafkaConsumer
# Kafka配置
kafka_config = {
'bootstrap.servers': 'localhost:9092', # Kafka集群地址
'group.id': 'my-consumer-group' # 消费者组ID
}
# 示例函数
def integrate_data_using_flink():
# 创建Flink流处理环境
env = StreamExecutionEnvironment.get_execution_environment()
# 创建Kafka消费者
kafka_consumer = FlinkKafkaConsumer(
'your_topic_here', # 替换为你的Kafka主题
SimpleStringSchema(),
kafka_config
)
# 从Kafka消费者接收数据流
kafka_data_stream = env.add_source(kafka_consumer)
# 定义数据处理逻辑(示例:打印接收到的数据)
kafka_data_stream.print()
# 执行流处理作业
env.execute("Data Integration Job")
# 调用示例函数
integrate_data_using_flink()
结语
除了上面展示的两种方式,还可以试试ETL工具。而Nifi除了提供接入功能之外,还提供了数据流程的监控、错误处理、容错机制等功能,以及可视化的界面来管理和监控数据流程。
整体来说,数据源是风控引擎的本质所在,所以在数据源的接入方式上可以多选择多参考,最终的数据才能为决策作参考。
以上。
如果需要现成的风控引擎,可以戳这里>>>免费体验