分必要不要分库分表(通过优化之后还明显影响业务再分,可以通过监控慢查询确定)
分库分表的一般条件:单表数据量超过1000w(阿里应该是说5000w)或者单表数据文件(.ibd)超过20GB,这个很重要,(很多年前我没怎么用过数据库的时候面试某著名大厂,让我等最后的谈钱不伤感情(他们hr不挂人),大领导对我非常满意,就跟我闲聊技术,就因为瞎XX聊天的时候说了一个过200w要分库分表的笑话,就从等待谈钱不伤感情到回去等通知吧,到手的offer没了,所以没事不要开玩笑。。。。。。)
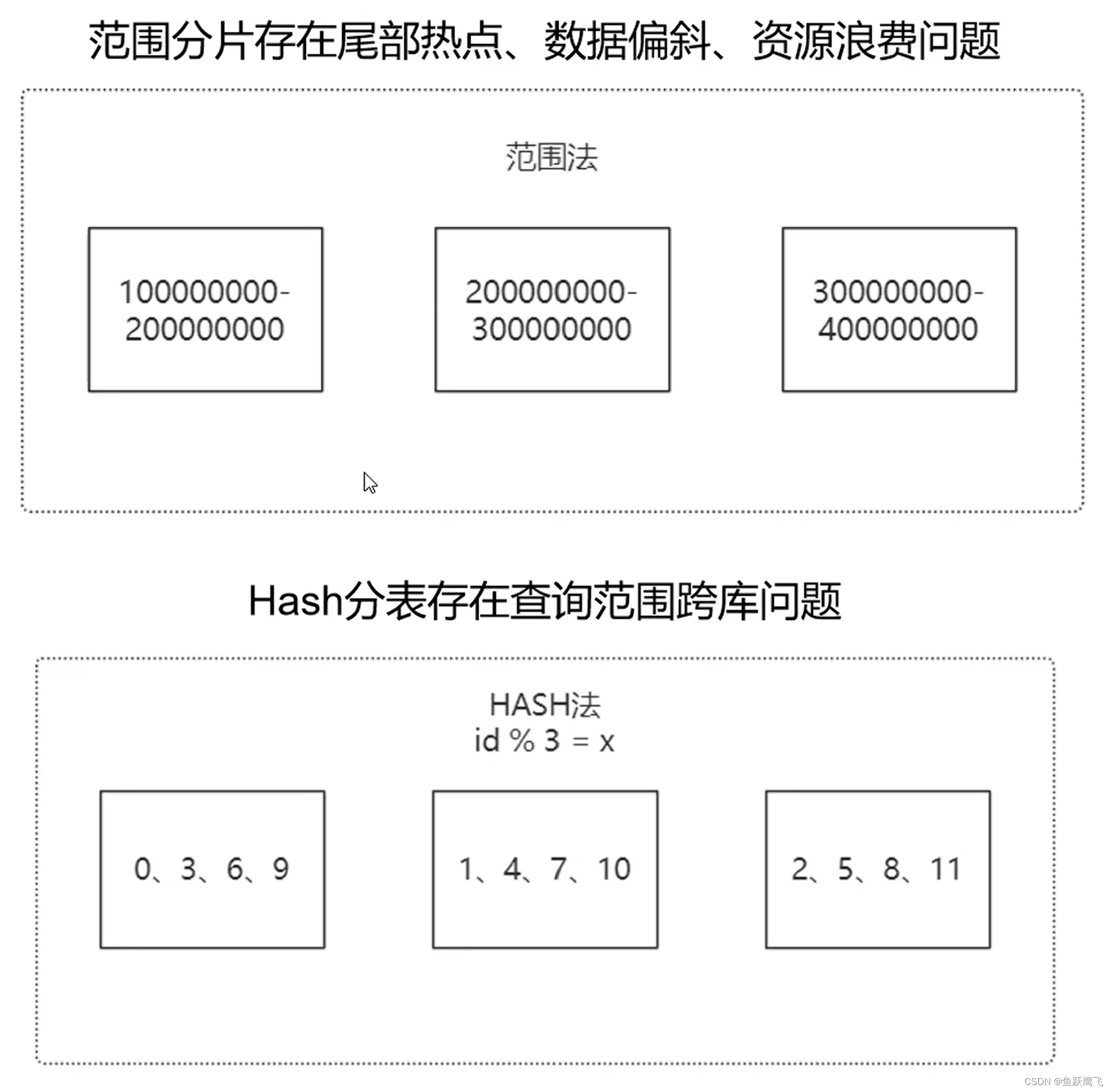
范围分片存在的问题:
(1)尾部热点:根据表自增的测量,可能之后的数据都会插入到最后一个分片上,而且因为最后一个分片都是最新的数据,最可能被查询(正常的话今年的数据被查询的可能性较大,而去年前年的数据被查询的可能性就较小)
(2)数据倾斜,因为是按照主键自增的策略,所以前面两个库的数据都放满的情况下才会放第三个库,而第三个库可能刚放了200w的数据,这个时候数据就出现了倾斜,每个库处理的压力不一样。
(3)资源浪费,如果是范围分片的话,我们可能提前规划了某个分片需要存储5000w的数据,但是我们的硬件足够强大,可以处理1亿的数据,那这多出来的5000w的硬件能力就浪费了
与之对应的Hash分表基本能保证数据的总量基本一致(不倾斜、无资源浪费)数据分布均匀(无尾部热点问题),那Hash分别有什么问题呢,我们举个例子,对于上面图中,如果我们要查询的是id>8,则需要在每一个分片执行这个语句,然后再进行综合,也就是存在跨库查询问题。
那什么时候使用范围什么时候使用Hash分片呢?
如果表中存储的是类似日志数据这种的话,可能只会关心最近产生的,所以采用范围分片是个比较好的选择。
如果开发的是类似于档案系统,需要根据档案编号来进行查找指定的数据,那采用hash就可以快速定位到对应的分片进行数据提取且每个分片比较平均,采用hash就是一个比较好的选择
对于最开始的系统,我们数据量不大的时候基本上单独单表的
单库多表:有效缩小磁盘扫描的范围(按范围或者hash),可以很快的提取对应的数据,必须上面的图中查询id为300000001的那条数据,但是瓶颈是物理机的磁盘、网络IO、CPU的上限
多库多表:不同的数据库部署到不同的物理机上,提供数据库的并行处理能力,在复杂的系统中基本上都采用这种方案。
分库分表可能产生的问题:
1.分布式事务问题,引入XA、TCC、SAGA等分布式事务解决方案,原来数据都在一张表里,我们使用一个事务就可以保证事务的完整性一致性,但是现在数据可能分布在多个表甚至多个库里,那就需要引入额外的事务协调者,如引入XA、TCC、SAGA等分布式事务解决方案。
2.跨库join关联查询
解决方案:(1)程序先查A表,再查询B表(程序自己来实现)
(2) 使用MyCat、ShardingSphere等组件来支持两个表的跨度join(注意目前应该只支持两个表的,或许是我的知识局限了),跟第一个方案差不多,逻辑被组件封装了
3. 跨节点分页查询问题
比如top n问题,我们的解决方案目前是每个节点取top n,然后在程序合并运算取这些所有取到的数据里的topn,Mysql目前没有找到更好的方案。
4.全局主键ID问题
因为每一条数据的ID都是不能重复的。
采用分布式主键生成器,例如推特的SnowFlake(国内叫雪花,存在著名的服务器时钟回拨的问题:时钟回拨是与硬件时钟和ntp服务相关的。硬件时钟可能会因为各种原因发生不准的情况,网络中提供了ntp服务来做时间校准,做校准的时候就会发生时钟的跳跃或者回拨的问题)、美团的Leaf,不建议使用UUID,原因是:1.UUID是字符串,处理字符串比处理数字的效率要明显偏低 2.
UUID是无序的,无序的主键可能发生页分裂问题进而影响程序的执行效率
5.扩容问题
范围分表容易扩容,最后的数据存在于最后的节点上,如果 容量不够只需要在最后再添加服务器即可,但是存在尾部热点问题,最后的服务器读写压力可能最大
Hash分表极难扩容(涉及大规模的数据迁移,例如某条数据原来对4取模放在3号分片,而现在改成对于5取模可能就放在2号分片了),可能的策略是改为一致性的Hash,但是迁移难度也是比较大的。