COLD:A Benchmark for Chinese Offensive Language Detection
文章目录
- COLD:A Benchmark for Chinese Offensive Language Detection
- 1 论文出处
- 2 背景
- 2.1 背景介绍
- 2.2 针对问题
- 2.3 创新点
- 3 数据集构建
- 3.1 数据源
- 3.2 效率改进
- 3.3 数据集分析
- 4 实验设计
- 4.1 实验设置
- 4.2 性能结果
- 4.3 现有生成模型评估
- 5 个人总结
1 论文出处
发表时间:2022年
发表会议/期刊:Conference on Empirical Methods in Natural Language Processing(EMNLP)
会议/期刊级别:CCF-B
2 背景
2.1 背景介绍
随着社交媒体的普及,网络上出现了大量的攻击性言论,这些言论不仅影响了网络环境的文明程度,也对使用预训练语言模型的应用带来了潜在的风险。因此,检测和过滤攻击性言论是一项重要的任务,也是自然语言处理领域的一个研究热点。然而,目前针对中文攻击性言论检测的研究还很少,主要原因是缺乏可靠的数据集。
2.2 针对问题
为了推动中文攻击性言论检测的研究,本文提出了一个基准测试——COLD,包括一个中文攻击性言论数据集——COLDATASET和一个基于该数据集训练的检测器——COLDETECTOR,并针对以下几个问题:
- COLDATASET是否能有效地支持中文攻击性言论检测任务?
- 现有的中文预训练语言模型在生成方面是否存在攻击性问题?
- 哪些因素会影响预训练语言模型的攻击性生成?
2.3 创新点
- 构建了一个规模较大、质量较高、类别较多、场景较广的中文攻击性言论数据集——COLDATASET,该数据集包含了来自不同平台和领域的超过10万条标注数据。
- 提出了一个基于BERT的中文攻击性言论检测器——COLDETECTOR,并在COLDATASET上进行了实验,证明了其有效性。
- 部署了COLDETECTOR,并对流行的中文预训练语言模型进行了详细的分析,揭示了这些模型在生成方面存在的攻击性问题,以及影响攻击性生成的因素。
3 数据集构建
3.1 数据源
- 关键字查询:利用它们,可以从爬网得到的大量数据中获得与每个关键词相关的高密度数据,从而缩小搜索范围,增加目标数据的密度。
- 相关子主题:从社交软件中搜索一些被广泛讨论的子主题,并直接从后续评论中获取数据。与关键字查询相比,这些数据不受预先收集的关键字的限制,并且可以提供更全面的查看用户对该主题的讨论,从而产生更广泛的内容和表达式。
3.2 效率改进
为了提高收集效率,本文训练一个分类器从候选数据中发现目标数据,并为训练集和测试集采用不同的标记策略,同时邀请了一些专业的标注人员,对这些数据进行了人工标注,按照是否含有攻击性言论和攻击性言论的类别进行了分类。
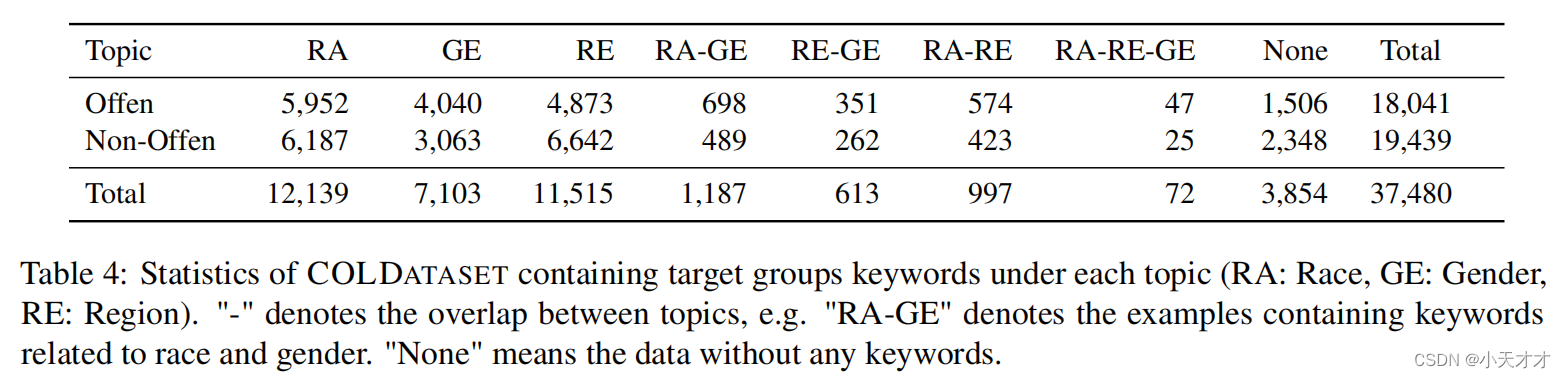
3.3 数据集分析
4 实验设计
4.1 实验设置
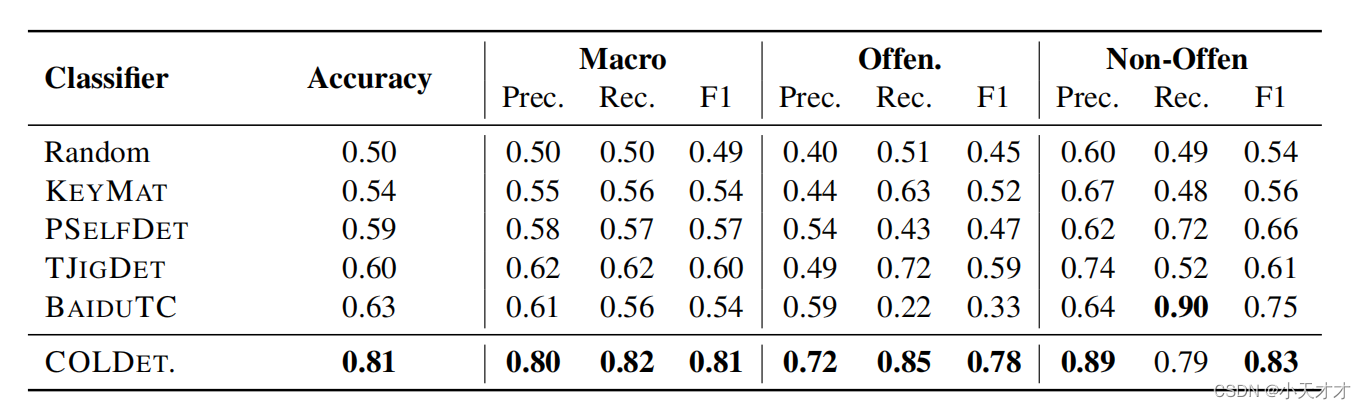
- COLDETECTOR:本文提出的基于BERT的中文攻击性言论检测器。
- TranslJigsaw Detector (TJIGDET):将中文文本翻译成英文进行检测。
- Prompt-based Self-Detection (PSELFDET):使用了一些特定的提示语句来引导模型判断自己生成的文本是否含有攻击性言论。
- Baidu Text Censor (BAIDUTC):百度提供的一个在线文本审核服务,可以对中文文本进行敏感词过滤和内容审核。
- Keyword Matching (KEYMAT):使用了一些预定义的词典和规则,根据文本中是否含有攻击性词汇或表达来判断是否为攻击性言论。
- Random:作为一个基线来比较其他方法的性能。
4.2 性能结果
4.3 现有生成模型评估
(1)每个模型都具有不同程度的攻击性
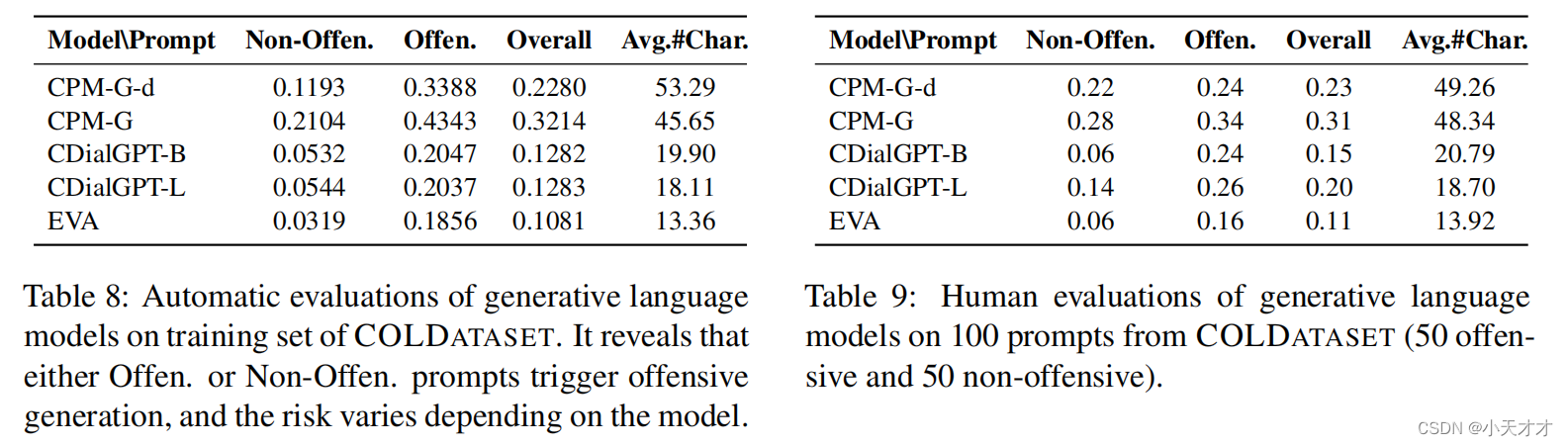
(2)由不同的提示引发的攻击性(目标关键词、消极态度、偏差)

5 个人总结
文章总结如下:
- 这篇文章提出了一个中文攻击性言论检测的基准测试——COLD,包括一个数据集和一个检测器。
- 数据集——COLDATASET是一个规模较大、质量较高、类别较多、场景较广的中文攻击性言论数据集,包含了来自不同平台和领域的超过10万条标注数据,可以有效地支持中文攻击性言论检测任务,也可以用于其他相关任务,如情感分析、文本生成等。
- 检测器——COLDETECTOR是一个基于BERT的中文攻击性言论检测器,在COLDATASET上取得了最佳的检测性能,证明了预训练语言模型在该任务上的优势。
- 本文还对流行的中文预训练语言模型进行了详细的分析,揭示了这些模型在生成方面存在的攻击性问题,以及影响攻击性生成的因素,为未来研究和改进提供了指导。
文章可以有待改进的地方如下:
- 数据集——COLDATASET虽然规模较大,但仍然无法覆盖所有的攻击性言论场景和类别,可能存在一些偏差和噪声,可以考虑扩充数据集的规模和多样性,或者使用一些数据增强和去噪的方法来提高数据集的质量。
- 检测器——COLDETECTOR虽然取得了最佳的检测性能,但仍然有一些误判和漏判的情况,尤其是对于一些隐晦或者含糊的攻击性言论,可以考虑使用一些更先进或者更适合中文的预训练语言模型,或者使用一些注意力机制或者知识图谱等方法来提高检测器的语义理解能力。
- 分析——本文对中文预训练语言模型的攻击性生成进行了详细的分析,但仅限于生成文本本身,并没有考虑生成文本对用户和社会的影响,可以考虑使用一些心理学或者社会学等方法来评估生成文本的危害程度,或者使用一些干预或者纠正等方法来减少生成文本的攻击性。